En Retrieval-Augmented Generation (RAG) pipeline er et workflow, der gør det muligt for AI-systemer at finde, rangere og citere eksterne kilder, når de genererer svar. Den kombinerer dokumenthentning, semantisk rangering og LLM-generering for at levere præcise, kontekstuelle svar, der er forankret i virkelige data. RAG-systemer reducerer hallucinationer ved at konsultere eksterne vidensbaser, før svarene genereres, hvilket gør dem essentielle for applikationer, der kræver faktuel nøjagtighed og kildeangivelse.
RAG-pipeline
En Retrieval-Augmented Generation (RAG) pipeline er et workflow, der gør det muligt for AI-systemer at finde, rangere og citere eksterne kilder, når de genererer svar. Den kombinerer dokumenthentning, semantisk rangering og LLM-generering for at levere præcise, kontekstuelle svar, der er forankret i virkelige data. RAG-systemer reducerer hallucinationer ved at konsultere eksterne vidensbaser, før svarene genereres, hvilket gør dem essentielle for applikationer, der kræver faktuel nøjagtighed og kildeangivelse.
Hvad er en RAG-pipeline?
En Retrieval-Augmented Generation (RAG) pipeline er en AI-arkitektur, der kombinerer informationshentning med generering fra store sprogmodeller (LLM) for at producere mere præcise, kontekstuelle og verificerbare svar. I stedet for udelukkende at basere sig på en LLM’s træningsdata, henter RAG-systemer dynamisk relevante dokumenter eller data fra eksterne vidensbaser, før de genererer svar. Det reducerer markant hallucinationer og forbedrer den faktuelle nøjagtighed. Pipen fungerer som en bro mellem statiske træningsdata og realtidsinformation, hvilket gør det muligt for AI-systemer at referere til aktuelle, domænespecifikke eller proprietære indhold. Denne tilgang er blevet afgørende for organisationer, der kræver svar med kildeangivelser, overholdelse af nøjagtighedsstandarder og gennemsigtighed i AI-genereret indhold. RAG-pipelines er især værdifulde i overvågning af AI-systemer, hvor sporbarhed og kildeangivelse er kritiske krav.
Kernekomponenter
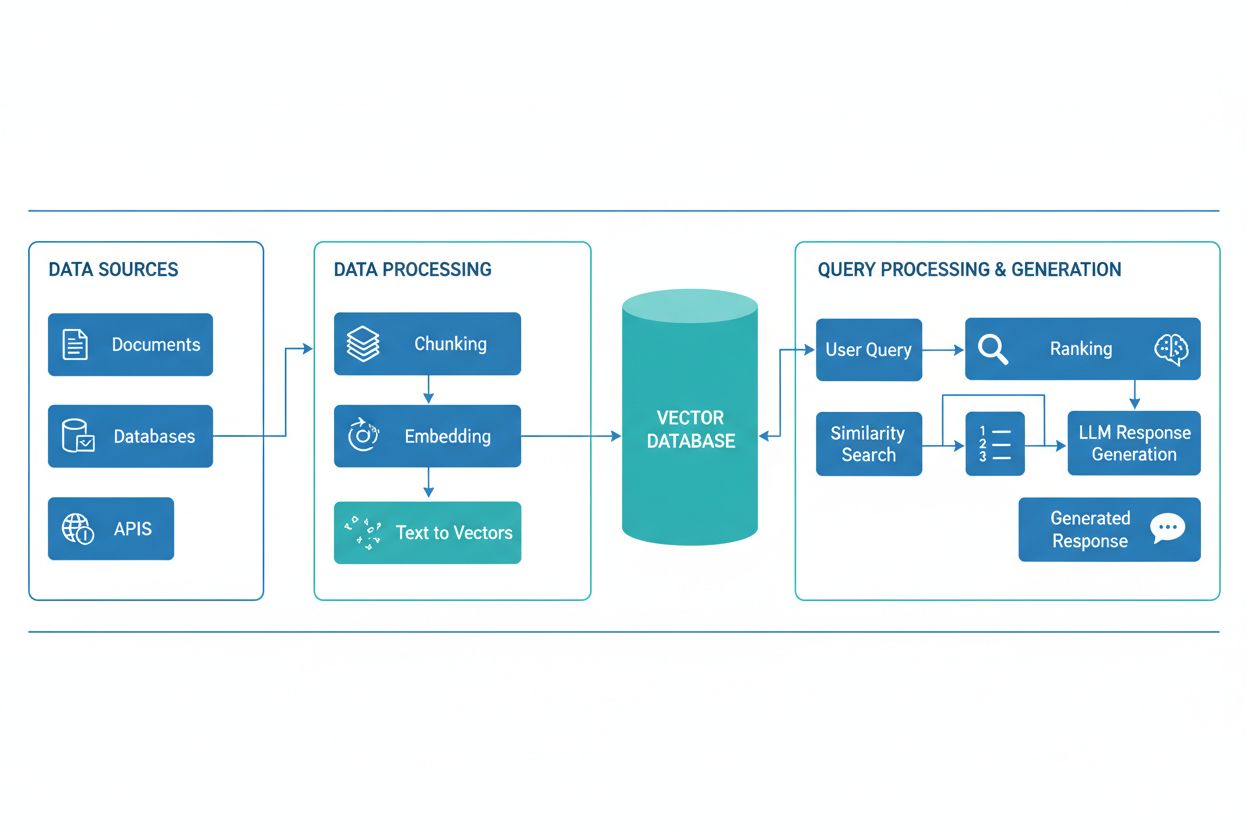
En RAG-pipeline består af flere sammenkoblede komponenter, der arbejder sammen om at hente relevante oplysninger og generere forankrede svar. Arkitekturen inkluderer typisk et dokumentindtagelseslag, der behandler og forbereder rå data, en vektordatabase eller vidensbase, der lagrer embeddings og indekseret indhold, en hentningsmekanisme, der identificerer relevante dokumenter på baggrund af brugerforespørgsler, et rangeringssystem, der prioriterer de mest relevante resultater, og et genereringsmodul drevet af en LLM, der sammenfatter de hentede oplysninger til sammenhængende svar. Yderligere komponenter omfatter forespørgselsbehandling og præprocesseringsmoduler, der normaliserer brugerinput, embedding-modeller, der omdanner tekst til numeriske repræsentationer, og et feedback-loop, der løbende forbedrer hentningsnøjagtigheden. Orkestreringen af disse komponenter bestemmer RAG-systemets samlede effektivitet og ydeevne.
RAG-pipelinen arbejder i to adskilte faser: hentningsfasen og genereringsfasen. Under hentningsfasen omdanner systemet brugerens forespørgsel til en embedding ved hjælp af den samme embedding-model, som har behandlet vidensbasedokumenterne, og søger derefter i vektordatabasen for at identificere de mest semantisk lignende dokumenter eller passager. Denne fase returnerer typisk en rangeret liste af kandidater, som kan blive yderligere forfinet gennem reranking-algoritmer, der benytter cross-encoders eller LLM-baseret score for at sikre relevansen. I genereringsfasen bliver de højest rangerede, hentede dokumenter formateret ind i et kontekstvindue og sendt til LLM’en sammen med den oprindelige forespørgsel, hvilket gør det muligt for modellen at generere svar, der er forankret i faktisk kildemateriale. Denne to-fasede tilgang sikrer, at svarene både er kontekstuelt passende og sporbare til specifikke kilder, hvilket gør den ideel til applikationer, hvor citation og ansvarlighed er nødvendige. Kvaliteten af output afhænger kritisk af både relevansen af de hentede dokumenter og LLM’ens evne til at sammenfatte informationen meningsfuldt.
Nøgleteknologier & Værktøjer
RAG-økosystemet dækker et bredt udvalg af specialiserede værktøjer og rammer designet til at forenkle pipelinekonstruktion og -implementering. Moderne RAG-implementeringer gør brug af flere teknologikategorier:
Orkestreringsrammer: LangChain, LlamaIndex (tidligere GPT Index) og Haystack tilbyder abstraktionslag til at bygge RAG-workflows uden at håndtere hver enkelt komponent
Vektordatabaser: Pinecone, Weaviate, Milvus, Qdrant og Chroma giver skalerbar lagring og hentning af højdimensionelle embeddings med forespørgsler på under et millisekund
Embedding-modeller: OpenAI’s text-embedding-3, Cohere’s Embed API og open source-modeller som all-MiniLM-L6-v2 omdanner tekst til semantiske repræsentationer
LLM-udbydere: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) og Mistral tilbyder forskellige modelstørrelser og -funktioner til genereringsopgaver
Reranking-løsninger: Cohere’s Rerank API, cross-encoder-modeller fra Hugging Face og proprietære LLM-baserede rerankere forbedrer hentningspræcisionen
Dataklargøringsværktøjer: Unstructured, Apache Kafka og tilpassede ETL-pipelines håndterer dokumentindtagelse, fragmentering og præprocessering
Overvågning og evaluering: Værktøjer som Ragas, TruLens og tilpassede evalueringsrammer vurderer RAG-systemets ydeevne og identificerer fejlkilder
Disse værktøjer kan kombineres modulært, så organisationer kan bygge RAG-systemer tilpasset deres specifikke behov og infrastrukturelle begrænsninger.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hentningsmekanismer
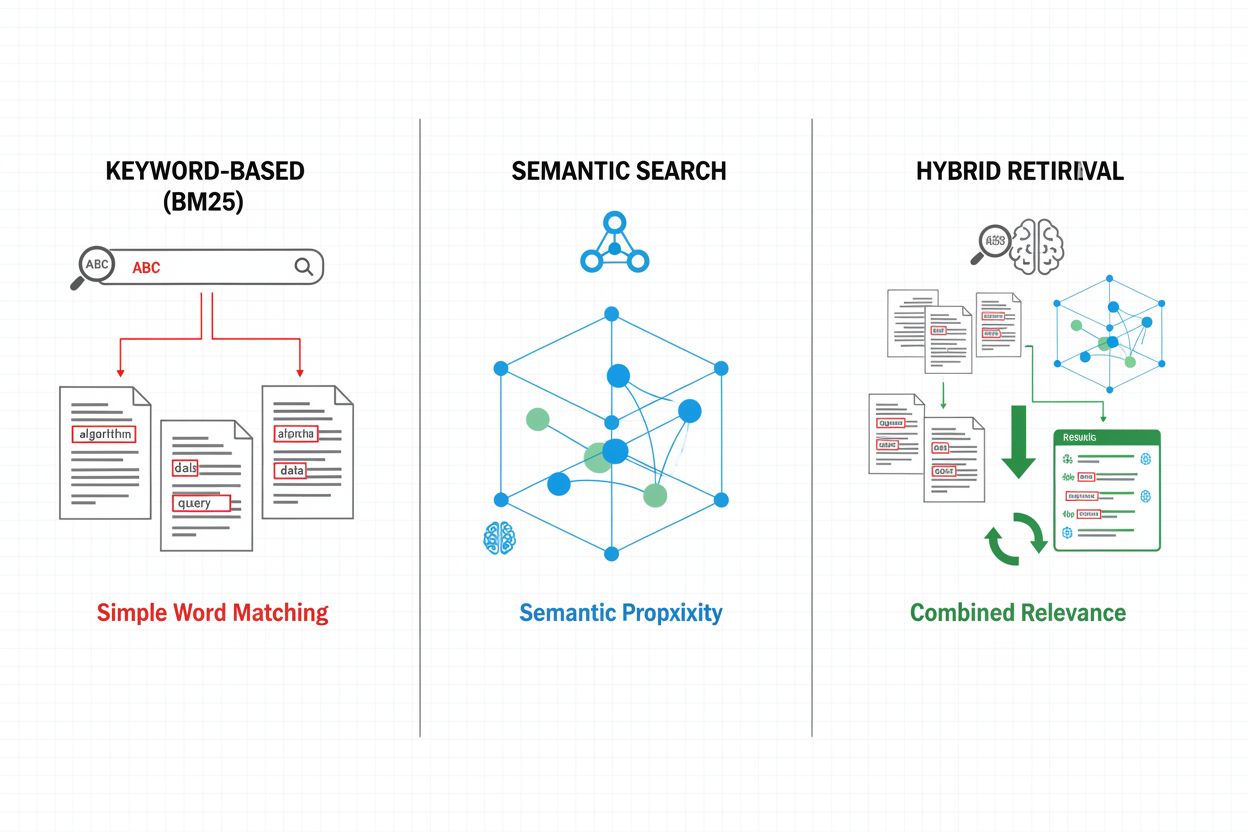
Hentningsmekanismer udgør fundamentet for RAG-pipeline-effektivitet og har udviklet sig fra simple nøgleordsbaserede tilgange til avancerede semantiske søgemetoder. Traditionel nøgleordsbaseret hentning med BM25-algoritmer er fortsat beregningsmæssigt effektiv og velegnet til eksakt match, men har svært ved at håndtere semantisk forståelse og synonymer. Dense Passage Retrieval (DPR) og andre neurale hentemetoder løser disse begrænsninger ved at kode både forespørgsler og dokumenter til tætte vektorembeddings, hvilket muliggør semantisk lighedsmatching, der fanger betydning ud over overfladiske nøgleord. Hybride hentningsmetoder kombinerer nøgleordsbaseret og semantisk søgning og udnytter styrkerne fra begge til at forbedre recall og præcision på tværs af forskellige forespørgselstyper. Avancerede hentningsmekanismer inkluderer forespørgselsudvidelse, hvor den oprindelige forespørgsel suppleres med relaterede udtryk eller omformuleringer for at fange flere relevante dokumenter. Reranking-lag forfiner yderligere resultaterne ved at anvende mere beregningstunge modeller, der scorer kandidater baseret på dybere semantisk forståelse eller opgavespecifik relevans. Valget af hentningsmekanisme har stor betydning for både nøjagtigheden af den hentede kontekst og RAG-pipeline’ens beregningsmæssige omkostninger og kræver nøje overvejelse af balancen mellem hastighed og kvalitet.
Fordele ved RAG-pipelines
RAG-pipelines giver væsentlige fordele frem for traditionelle LLM-baserede tilgange, især til applikationer med krav om nøjagtighed, aktualitet og sporbarhed. Ved at forankre svar i hentede dokumenter reducerer RAG-systemer markant hallucinationer – situationer, hvor LLM’er genererer plausible, men faktuelt forkerte oplysninger – og gør dem velegnede til højrisko-domæner som sundhed, jura og finansielle tjenester. Evnen til at referere til eksterne vidensbaser gør det muligt for RAG-systemer at levere aktuelle oplysninger uden at genoplære modeller, så organisationer kan opretholde opdaterede svar, når ny information tilføjes. RAG-pipelines understøtter domænespecifik tilpasning ved at inkorporere proprietære dokumenter, interne vidensbaser og specialiseret terminologi, hvilket giver mere relevante og kontekstpassende svar. Hentningskomponenten giver gennemsigtighed og mulighed for revision ved eksplicit at vise, hvilke kilder der har informeret hvert svar, hvilket er kritisk for compliance og brugerens tillid. Omkostningseffektiviteten forbedres gennem brug af mindre, mere effektive LLM’er, der kan generere svar af høj kvalitet, når de får relevant kontekst, hvilket reducerer det beregningsmæssige overhead sammenlignet med større modeller. Disse fordele gør RAG særlig værdifuld for organisationer, der implementerer AI-overvågningssystemer, hvor nøjagtighed i citation og indholdsvisibilitet er altafgørende.
Udfordringer og begrænsninger
På trods af fordelene står RAG-pipelines over for flere tekniske og operationelle udfordringer, der kræver omhyggelig håndtering. Kvaliteten af de hentede dokumenter bestemmer direkte svarenes kvalitet, hvilket gør det svært at rette fejl i hentningen – kendt som “garbage in, garbage out”, hvor irrelevante eller forældede dokumenter i vidensbasen forplanter sig til de endelige svar. Embedding-modeller kan have svært ved domænespecifikke termer, sjældne sprog eller meget teknisk indhold, hvilket fører til dårlig semantisk matching og oversete relevante dokumenter. De beregningsmæssige omkostninger ved hentning, embedding-generering og reranking kan være betydelige i stor skala, især ved store vidensbaser eller mange forespørgsler. Kontekstvinduesbegrænsninger i LLM’er begrænser mængden af hentet information, der kan indgå i prompten, og kræver omhyggelig udvælgelse og sammenfatning af relevante passager. At opretholde vidensbasens aktualitet og konsistens giver operationelle udfordringer, især i dynamiske miljøer med hyppige eller mangeartede informationskilder. Evaluering af RAG-systemets ydeevne kræver omfattende målinger ud over traditionel nøjagtighed, herunder præcision i hentning, svarrelevans og korrekthed af citation, hvilket kan være vanskeligt at vurdere automatisk.
RAG vs. andre tilgange
RAG repræsenterer én tilgang blandt flere strategier til at forbedre LLM’ers nøjagtighed og relevans, hver med deres egne kompromiser. Finjustering indebærer genoplæring af LLM’er på domænespecifikke data og giver dyb modeltilpasning, men kræver betydelige computerevner, annoterede træningsdata og løbende vedligeholdelse, efterhånden som information ændres. Prompt engineering optimerer instruktioner og kontekst til LLM’er uden at ændre modelvægte og giver fleksibilitet og lave omkostninger, men er begrænset af modellens træningsdata og kontekstvindue. In-context learning udnytter få-skuds-eksempler i prompts til at styre modeladfærd, hvilket giver hurtig tilpasning, men bruger værdifulde konteksttokens og kræver nøje valg af eksempler. Sammenlignet med disse tilgange tilbyder RAG et kompromis: den giver dynamisk adgang til aktuelle oplysninger uden genoplæring, opretholder gennemsigtighed gennem eksplicit kildeangivelse og skalerer effektivt på tværs af forskellige vidensdomæner. Dog introducerer RAG ekstra kompleksitet via hentningsinfrastruktur og potentielle fejl i hentningen, mens finjustering giver tættere integration af domæneviden i modeladfærden. Den optimale tilgang indebærer ofte en kombination – fx ved at bruge RAG sammen med finjusterede modeller og nøje konstruerede prompts – for at maksimere nøjagtighed og relevans til specifikke anvendelser.
Opbygning og implementering af RAG
Implementering af en produktionsklar RAG-pipeline kræver systematisk planlægning på tværs af dataklargøring, arkitekturdesign og operationelle overvejelser. Processen starter med forberedelse af vidensbasen: indsamling af relevante dokumenter, oprensning og standardisering af formater samt opdeling af indholdet i passende størrelser, der balancerer kontekstbevarelse og præcision i hentningen. Dernæst vælger organisationen embedding-modeller og vektordatabaser ud fra ydelsesbehov, latenstolerance og skalerbarhed, med hensyn til embedding-dimensioner, forespørgselshastighed og lagringskapacitet. Hentningssystemet konfigureres herefter – herunder valg af algoritmer (nøgleord, semantisk, hybrid), reranking-strategier og filtreringskriterier for resultater. Integration med LLM-udbydere følger, hvor forbindelser til genereringsmodeller etableres og promptskabeloner, der effektivt inkorporerer hentet kontekst, defineres. Test og evaluering er kritiske og kræver målinger af kvalitet i hentning (præcision, recall, MRR), generering (relevans, sammenhæng, faktualitet) og end-to-end-systemets ydeevne. Implementeringsmæssigt skal der opsættes overvågning af hentningsnøjagtighed og genereringskvalitet, feedback-loops til at identificere og adressere fejlkilder samt processer for opdatering og vedligeholdelse af vidensbasen. Endelig kræver kontinuerlig optimering analyse af brugerinteraktioner, identificering af fejlkilder og løbende forbedring af hentningsmekanismer, reranking-strategier og prompt engineering for at hæve systemets samlede ydeevne.
RAG i AI-overvågning og citation
RAG-pipelines er fundamentale for moderne AI-overvågningsplatforme som AmICited.com, hvor det er afgørende at spore kilder og nøjagtigheden af AI-genereret indhold. Ved eksplicit at hente og citere kildedokumenter skaber RAG-systemer et reviderbart spor, der gør det muligt for overvågningsplatforme at verificere påstande, vurdere faktualitet og identificere potentielle hallucinationer eller fejlhenvisninger. Denne citationsfunktion løser en kritisk mangel i AI-gennemsigtighed: brugere og revisorer kan spore svar tilbage til de oprindelige kilder, hvilket muliggør uafhængig verificering og opbygning af tillid til AI-genereret indhold. For indholdsproducenter og organisationer, der anvender AI-værktøjer, giver RAG-baseret overvågning indsigt i, hvilke kilder der har informeret specifikke svar, hvilket understøtter overholdelse af krav om attribution og indholdsstyring. Hentningskomponenten i RAG-pipelines genererer rige metadata – herunder relevansscore, dokumentsrangeringer og tillidsmålinger – som overvågningssystemer kan analysere for at vurdere svarenes pålidelighed og identificere, når AI-systemer bevæger sig uden for deres vidensdomæner. Integration af RAG med overvågningsplatforme muliggør detektion af citationsforskydning, hvor AI-systemer gradvist bevæger sig væk fra autoritative kilder mod mindre pålidelige, og understøtter håndhævelse af politikker for kildekvalitet og diversitet. Efterhånden som AI-systemer bliver integreret i kritiske arbejdsgange, skaber kombinationen af RAG-pipelines og omfattende overvågning ansvarlighedsmekanismer, der beskytter brugere, organisationer og det bredere informationsøkosystem mod AI-genereret misinformation.
Ofte stillede spørgsmål
Hvad er forskellen mellem RAG og finjustering?
RAG og finjustering er komplementære tilgange til at forbedre LLM-ydeevne. RAG henter eksterne dokumenter ved forespørgsler uden at ændre modellen, hvilket giver adgang til data i realtid og nemme opdateringer. Finjustering genoplærer modellen på domænespecifikke data, hvilket giver dybere tilpasning, men kræver betydelige computerressourcer og manuelle opdateringer, når oplysninger ændres. Mange organisationer bruger begge teknikker sammen for optimale resultater.
Hvordan reducerer RAG hallucinationer i AI-svar?
RAG reducerer hallucinationer ved at forankre LLM-svar i hentede faktuelle dokumenter. I stedet for kun at stole på træningsdata, henter systemet relevante kilder før generering og giver modellen konkret dokumentation at referere til. Denne tilgang sikrer, at svarene er baseret på faktisk information frem for modellens indlærte mønstre, hvilket forbedrer den faktuelle nøjagtighed og reducerer falske eller vildledende påstande markant.
Hvad er vektorembeddings, og hvorfor er de vigtige i RAG?
Vektorembeddings er numeriske repræsentationer af tekst, der fanger semantisk betydning i et multidimensionelt rum. De gør det muligt for RAG-systemer at udføre semantisk søgning, så de finder dokumenter med lignende betydning, selvom de bruger forskellige ord. Embeddings er afgørende, fordi de giver RAG mulighed for at gå ud over søgning på nøgleord og forstå begrebsmæssige sammenhænge, hvilket forbedrer relevansen af hentningen og muliggør mere præcis svargenerering.
Kan RAG-pipelines arbejde med data i realtid?
Ja, RAG-pipelines kan inkorporere data i realtid gennem kontinuerlig indtagelse og indekseringsprocesser. Organisationer kan opsætte automatiserede pipelines, der regelmæssigt opdaterer vektordatabasen med nye dokumenter, så vidensbasen forbliver opdateret. Denne evne gør RAG ideel til applikationer, der kræver aktuelle oplysninger som nyhedsanalyse, prisovervågning og markedsmonitorering – uden at skulle genoplære den underliggende LLM.
Hvad er forskellen på semantisk søgning og RAG?
Semantisk søgning er en hentningsteknik, der finder dokumenter baseret på meningslighed ved hjælp af vektorembeddings. RAG er en komplet pipeline, der kombinerer semantisk søgning med LLM-generering for at producere svar, der er forankret i hentede dokumenter. Hvor semantisk søgning fokuserer på at finde relevante oplysninger, tilføjer RAG genereringskomponenten, der sammenfatter det hentede indhold til sammenhængende svar med kildeangivelser.
Hvordan beslutter RAG-systemer, hvilke kilder der skal citeres?
RAG-systemer bruger flere mekanismer til at vælge kilder til citation. De anvender hentningsalgoritmer til at finde relevante dokumenter, reranking-modeller til at prioritere de mest relevante resultater og verificeringsprocesser for at sikre, at citaterne faktisk understøtter de fremsatte påstande. Nogle systemer bruger 'citer under skrivning'-tilgange, hvor påstande kun fremsættes, hvis de understøttes af hentede kilder, mens andre verificerer citater efter generering og fjerner ikke-understøttede påstande.
Hvad er de største udfordringer ved at bygge RAG-pipelines?
Væsentlige udfordringer inkluderer at opretholde vidensbasens aktualitet og kvalitet, optimere hentningsnøjagtighed på tværs af forskellige indholdstyper, håndtere computeromkostninger i stor skala, håndtere domænespecifikke termer, som embedding-modeller måske ikke forstår godt, samt evaluere systemets ydeevne med omfattende målinger. Organisationer skal også håndtere kontekstvinduesbegrænsninger i LLM'er og sikre, at de hentede dokumenter forbliver relevante, efterhånden som informationen udvikler sig.
Hvordan overvåger AmICited RAG-citater i AI-systemer?
AmICited sporer, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews henter og citerer indhold gennem RAG-pipelines. Platformen overvåger, hvilke kilder der udvælges til citation, hvor ofte dit brand optræder i AI-svar, og om citaterne er korrekte. Denne indsigt hjælper organisationer med at forstå deres tilstedeværelse i AI-formidlede søgninger og sikre korrekt kildeangivelse af deres indhold.
Overvåg dit brand i AI-svar
Følg med i, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews refererer til dit indhold. Få indsigt i RAG-citater og overvågning af AI-svar.
Hvad er RAG i AI-søgning: Komplet guide til Retrieval-Augmented Generation
Lær hvad RAG (Retrieval-Augmented Generation) er i AI-søgning. Opdag hvordan RAG forbedrer nøjagtighed, reducerer hallucinationer og driver ChatGPT, Perplexity ...
Sådan fungerer Retrieval-Augmented Generation: Arkitektur og proces
Lær hvordan RAG kombinerer LLM'er med eksterne datakilder for at generere nøjagtige AI-svar. Forstå femtrinsprocessen, komponenterne og hvorfor det er vigtigt f...
Lær hvad Retrieval-Augmented Generation (RAG) er, hvordan det fungerer, og hvorfor det er essentielt for nøjagtige AI-svar. Udforsk RAG-arkitektur, fordele og v...
11 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.