Forskningsindhold - Datadrevet analytisk indhold
Forskningsindhold er evidensbaseret materiale skabt gennem dataanalyse og ekspertindsigter. Lær hvordan datadrevet analytisk indhold opbygger autoritet, påvirke...
11 min læsning
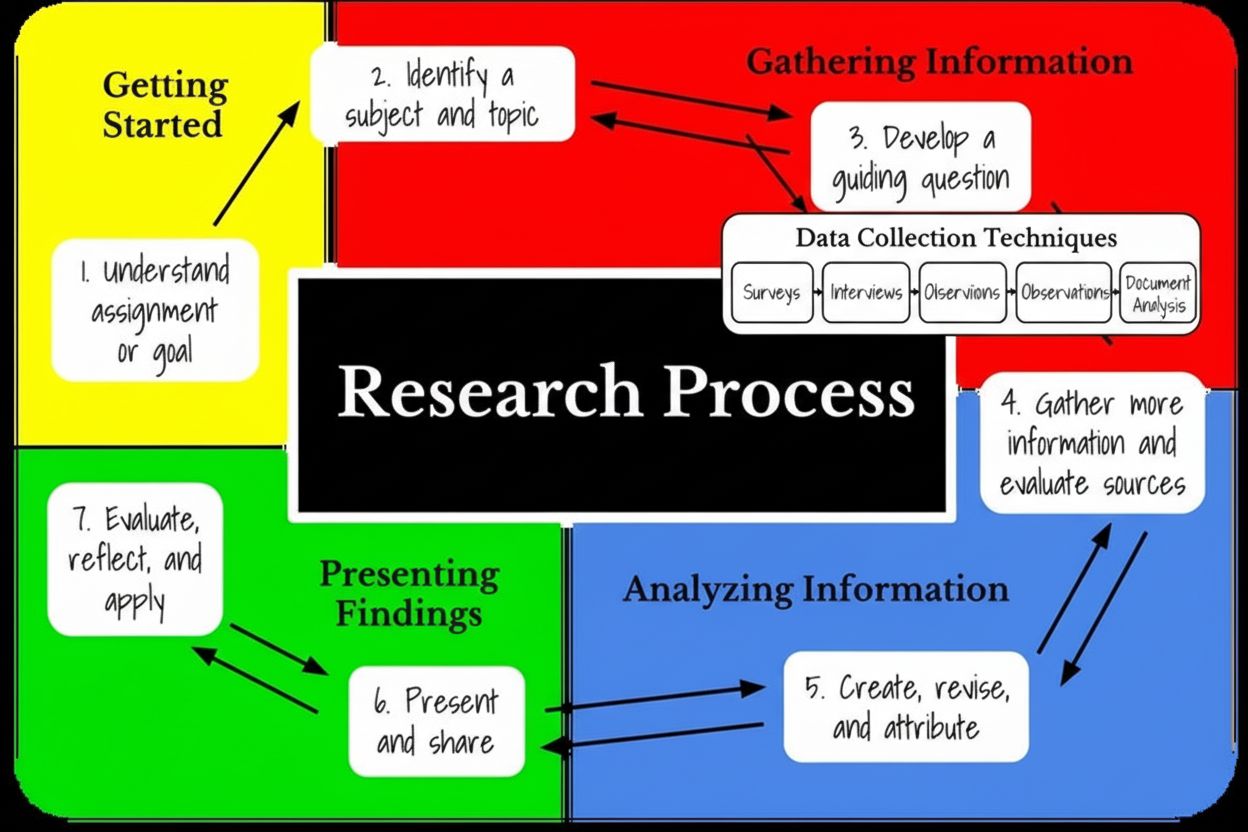
Forskningsfasens informationsindsamlingsstadie er den systematiske proces med at indsamle, organisere og evaluere data, fakta og viden fra forskellige kilder for at besvare specifikke forskningsspørgsmål. Dette grundlæggende stadie indebærer valg af passende metoder til dataindsamling, implementering af kvalitetskontrolforanstaltninger og fastlæggelse af klare mål, inden analyse og fortolkning påbegyndes.
Forskningsfasens informationsindsamlingsstadie er den systematiske proces med at indsamle, organisere og evaluere data, fakta og viden fra forskellige kilder for at besvare specifikke forskningsspørgsmål. Dette grundlæggende stadie indebærer valg af passende metoder til dataindsamling, implementering af kvalitetskontrolforanstaltninger og fastlæggelse af klare mål, inden analyse og fortolkning påbegyndes.
Forskningsfasens informationsindsamlingsstadie er en systematisk og organiseret proces, hvor data, fakta og viden indsamles, arrangeres og vurderes fra forskellige kilder for at besvare specifikke forskningsspørgsmål eller opnå definerede mål. Dette kritiske stadie fungerer som fundament for alle efterfølgende forskningsaktiviteter, herunder analyse, fortolkning og konklusionsudvikling. Informationsindsamling rækker langt ud over simpel dataindsamling; det omfatter omhyggelig planlægning, identifikation af kilder, implementering af kvalitetskontrol og inddragelse af interessenter for at sikre, at den indsamlede information er nøjagtig, relevant og direkte anvendelig på forskningsspørgsmålet. Stadiet er kendetegnet ved metodiske procedurer, der omdanner rå observationer og målinger til organiserede datasæt klar til analyse. Forståelse af dette stadie er essentielt for forskere, akademikere, forretningsanalytikere og professionelle, der arbejder med evidensbaseret beslutningstagning på tværs af alle discipliner.
Formaliseret informationsindsamling opstod med udviklingen af den videnskabelige metode i det 17. og 18. århundrede, hvor systematisk observation og dataindsamling blev anerkendt som væsentlige elementer i grundig undersøgelse. Moderne metoder til informationsindsamling er dog blevet væsentligt forfinet gennem bidrag fra eksperter i forskningsmetodologi, statistikere og organisationsforskere i det forgangne århundrede. Stadiet fik særlig opmærksomhed i midten af det 20. århundrede, da forskere begyndte at understrege forskellen mellem dataindsamling og dataanalyse og erkendte, at kvaliteten af den indsamlede information direkte bestemmer validiteten af forskningskonklusionerne. I dag anerkendes informationsindsamlingsstadiet som hjørnestenen i evidensbaseret praksis på tværs af akademiske, forretningsmæssige, sundhedsfaglige og teknologiske sektorer. Ifølge rammer for forskningsmetodologi kan cirka 78% af forskningsfejl spores til utilstrækkelig informationsindsamling, hvilket understreger dette stadies kritiske betydning. Udviklingen af digitale værktøjer, databaser og automatiserede indsamlingssystemer har ændret forskeres tilgang til informationsindsamling, så større datamængder kan indsamles, mens der samtidig opstår nye udfordringer med hensyn til datakvalitet, bias-håndtering og etiske overvejelser.
| Metodekategori | Primær tilgang | Datatype | Prøvestørrelse | Tidsforbrug | Omkostning | Bedst til |
|---|---|---|---|---|---|---|
| Strukturerede interviews | Forudbestemte spørgsmål | Kvalitativ | Lille til mellem | Høj | Mellem-høj | Konsistens og sammenlignelighed |
| Spørgeskemaer & spørgeundersøgelser | Lukkede svarmuligheder | Kvantitativ | Stor | Lav-mellem | Lav | Brede mønstre og tendenser |
| Fokusgrupper | Gruppens diskussion | Kvalitativ | Lille (6-10) | Mellem | Mellem | Udforskning af holdninger og meninger |
| Observationer | Direkte overvågning | Kvalitativ | Variabel | Høj | Lav-mellem | Analyse af reel adfærd |
| Dokumentanalyse | Eksisterende optegnelser | Kvalitativ/kvantitativ | Variabel | Mellem | Lav | Historisk kontekst og tendenser |
| Eksperimenter | Kontrollerede forhold | Kvantitativ | Mellem | Høj | Høj | Årsagssammenhænge |
| Online/webdata | Digitale platforme | Kvantitativ | Meget stor | Lav | Lav | Skalerbar dataindsamling |
| Biometriske målinger | Fysiologiske data | Kvantitativ | Mellem | Mellem | Høj | Objektive fysiske reaktioner |
Informationsindsamlingsstadiet fungerer gennem en struktureret, flertrinsproces, der begynder med fastsættelse af klare mål og definition af omfanget for dataindsamling. Forskere skal først identificere, hvilken information der er nødvendig, hvorfor den er nødvendig, og hvordan den vil blive brugt til at besvare forskningsspørgsmål. Dette grundlæggende trin indebærer dokumentation af specifikke mål, leverancer og opgaver, mens der sættes grænser, der identificerer nødvendige ressourcer og letter projektplanlægning. Når målene er fastlagt, vælger forskerne passende metoder til dataindsamling baseret på deres forskningsdesign, tilgængelige ressourcer og forskningsspørgsmålets karakter. Udvælgelsesprocessen kræver nøje overvejelse af, om kvalitative metoder (interviews, observationer, fokusgrupper) eller kvantitative metoder (spørgeskemaer, eksperimenter, biometriske målinger) er mest hensigtsmæssige, eller om en mixed-methods tilgang, der kombinerer begge, vil give optimale indsigter. Implementeringen af de valgte metoder kræver træning af dataindsamlere, etablering af standardiserede procedurer og implementering af kvalitetskontrolpunkter for at minimere bias og fejl. Under hele indsamlingsprocessen skal forskere føre detaljerede optegnelser over datakilder, indsamlingsdatoer, anvendte metoder og eventuelle afvigelser fra de planlagte procedurer. Den afsluttende del indebærer organisering og forberedelse af de indsamlede data til analyse gennem kodning, kategorisering og valideringsprocedurer, der sikrer dataintegritet og klarhed til fortolkning.
I nutidens forretningsmiljø har informationsindsamlingsstadiet direkte indflydelse på organisatorisk beslutningstagning, strategisk planlægning og konkurrencepositionering. Virksomheder, der implementerer strenge procedurer for informationsindsamling, rapporterer markant bedre resultater inden for markedsundersøgelser, analyse af kundetilfredshed og produktudviklingsinitiativer. Ifølge brancheundersøgelser opnår organisationer med strukturerede informationsindsamlingsprocesser 40% hurtigere indsigt sammenlignet med dem, der benytter ad hoc-tilgange. Stadiet er særlig kritisk i markedsundersøgelser, hvor virksomheder skal forstå forbrugerpræferencer, konkurrencesituation og nye tendenser for at træffe informerede strategiske beslutninger. I sundheds- og lægemiddelforskning afgør informationsindsamling behandlingers sikkerhed og effektivitet, hvilket gør kvalitetskontrol og systematiske indsamlingsprocedurer bogstaveligt talt livsvigtige. Finansielle institutioner er afhængige af omfattende informationsindsamling til risikovurdering, bedrageridetektion og overholdelse af regulativer. Den praktiske betydning strækker sig til ressourceallokering, idet dårlig informationsindsamling kan føre til spildte investeringer, mistede muligheder og strategiske fejltagelser. Organisationer, der investerer i ordentlig infrastruktur, uddannelse og værktøjer til informationsindsamling, overgår konsekvent konkurrenter i beslutningshastighed og nøjagtighed. Stadiet påvirker også organisationskulturen, idet gennemsigtige, datadrevne informationsindsamlingsprocesser skaber tillid blandt interessenter og understøtter evidensbaseret beslutningstagning på alle niveauer.
I forbindelse med AI-overvågningsplatforme som AmICited har informationsindsamlingsstadiet en særlig betydning, da organisationer sporer, hvordan deres brands, domæner og URL’er optræder i AI-genererede svar på tværs af flere platforme. ChatGPT, Perplexity, Google AI Overviews og Claude genererer hver især svar forskelligt, hvilket kræver systematiske tilgange til informationsindsamling tilpasset den enkelte platforms unikke karakteristika. Informationsindsamlingsstadiet i AI-overvågning indebærer opsætning af klare sporingsmål, såsom overvågning af brandmentions, konkurrenceposition eller faktuel nøjagtighed i AI-svar. Forskere skal vælge passende overvågningsmetoder, hvilket kan inkludere automatiserede sporingssystemer, periodiske manuelle audits eller hybride tilgange, der kombinerer begge dele. Kvalitetskontrol bliver især vigtig i AI-overvågning, idet AI-systemer kan generere inkonsistent eller fejlagtig information, hvilket kræver valideringsprocedurer for at skelne mellem nøjagtige omtaler og falske positiver. Stadiet indebærer også organisering af data fra flere AI-kilder i sammenhængende datasæt, der afslører mønstre i, hvordan de forskellige platforme repræsenterer brands eller information. Denne specialiserede anvendelse af informationsindsamling demonstrerer, hvordan traditionelle forskningsmetoder tilpasses nye teknologier og informationsøkosystemer.
Succesfuld implementering af informationsindsamlingsstadiet kræver overholdelse af etablerede bedste praksisser, der er valideret på tværs af forskningsdiscipliner og organisatoriske kontekster. Først bør forskere fastlægge klare, målbare mål, der direkte relaterer til forskningsspørgsmål, så alle dataindsamlingsaktiviteter tjener et defineret formål. For det andet bør man vælge metoder passende til forskningskonteksten, idet man tager højde for undersøgelsens omfang, tilgængelige ressourcer, påkrævet validitet og hvilke indsigter, der ønskes. For det tredje skal man implementere strenge kvalitetskontrolprocedurer, herunder datavalidering, standardiserede indsamlingsprotokoller og regelmæssige audits for at minimere bias og fejl. For det fjerde skal man føre detaljeret dokumentation over alle indsamlingsaktiviteter, herunder datoer, anvendte metoder, datakilder og eventuelle afvigelser fra de planlagte procedurer, hvilket skaber et revisionsspor, der understøtter forskningens troværdighed. For det femte bør man involvere relevante interessenter i planlægning og udførelse, så informationsindsamlingen adresserer reelle informationsbehov og sikrer organisatorisk opbakning. For det sjette bør man benytte passende værktøjer og teknologier, der matcher forskningsskala og kompleksitet, fra simple regneark til små undersøgelser til avancerede datastyringsplatforme til større projekter. For det syvende bør man uddanne dataindsamlere grundigt for at sikre konsistens, reducere bias og opretholde kvalitetsstandarder under hele processen. For det ottende bør man etablere datasikkerheds- og privatlivsprotokoller, der beskytter følsomme oplysninger og overholder relevante regler som GDPR, CCPA og krav fra etiske komitéer. Samlet sikrer disse bedste praksisser, at den indsamlede information er nøjagtig, pålidelig, relevant og klar til meningsfuld analyse.
Informationsindsamlingsstadiet gennemgår betydelig transformation drevet af teknologiske fremskridt, integration af kunstig intelligens og udviklende organisatoriske behov. Kunstig intelligens og maskinlæring automatiserer i stigende grad processer for dataindsamling og -organisering, så forskere kan indsamle og bearbejde større datasæt mere effektivt end nogensinde før. Automatiserede dataindsamlingssystemer, værktøjer til sprogbehandling og intelligente algoritmer til datavalidering reducerer manuelt arbejde, forbedrer konsistens og mindsker menneskelig bias. Integration af real-time overvågningssystemer gør det muligt for organisationer at indsamle information kontinuerligt frem for i diskrete perioder, hvilket giver mere dynamisk og responsiv indsigt i skiftende forhold. Blockchain og distribuerede hovedbogsteknologier er på vej som værktøjer til at sikre dataintegritet og gennemsigtighed i informationsindsamlingen, især hvor dataproveniens og ægthed er kritisk. Fremkomsten af privatlivsbeskyttende dataindsamlingsmetoder, herunder differentieret privatliv og federeret læring, adresserer voksende bekymringer om datasikkerhed og overholdelse af regler, mens den analytiske værdi bevares. I forbindelse med AI-overvågning og brandsporing udvikler informationsindsamlingsstadiet sig til at håndtere udfordringer fra generative AI-systemer, inklusive hallucinationer, inkonsistente outputs og hurtigt skiftende modeladfærd. Organisationer udvikler specialiserede rammer for informationsindsamling, der er designet til at spore brandmentions på tværs af AI-platforme og kræver nye metoder, der tager højde for AI-specifikke karakteristika. Fremtiden vil sandsynligvis byde på øget fokus på etisk informationsindsamling, hvor organisationer implementerer mere sofistikerede bias-detektion- og minimeringsprocedurer. Derudover vil integration af flere datakilder gennem avancerede datafusionsteknikker gøre det muligt for forskere at skabe mere omfattende, multidimensionelle datasæt, der giver rigere indsigter end enkeltkilde-tilgange. Sammenfaldet af disse tendenser peger på, at informationsindsamlingsstadiet bliver stadig mere sofistikeret, automatiseret og integreret med avancerede analysefunktioner, hvilket grundlæggende ændrer, hvordan organisationer tilegner sig og udnytter information til beslutningstagning.
Det primære formål med informationsindsamlingsstadiet er systematisk at indsamle pålidelige, relevante data fra forskellige kilder, der direkte adresserer forskningsspørgsmålet. Dette stadie danner grundlaget for al efterfølgende analyse og sikrer, at forskere har nøjagtig, høj-kvalitetsinformation til at understøtte deres resultater og konklusioner. Ifølge rammer for forskningsmetodologi afgør effektiv informationsindsamling troværdigheden og validiteten af hele forskningsprojektet.
Informationsindsamling fokuserer på indsamling og organisering af rå data fra forskellige kilder, mens dataanalyse indebærer fortolkning og forståelse af de indsamlede data for at drage konklusioner. Informationsindsamling er inputfasen, hvor forskere erhverver fakta og observationer, mens analyse er behandlingsfasen, hvor mønstre, tendenser og relationer identificeres. Begge stadier er essentielle, men tjener forskellige formål i forskningsprocessen.
De vigtigste metoder til dataindsamling inkluderer kvalitative teknikker (interviews, fokusgrupper, observationer, dokumentanalyse) og kvantitative metoder (spørgeskemaer, spørgeundersøgelser, eksperimenter, biometriske målinger). Forskere bruger også mixed-methods-tilgange, der kombinerer både kvalitative og kvantitative teknikker. Valget af metode afhænger af forskningsmål, tilgængelige ressourcer, undersøgelsens omfang og hvilken type indsigter, der kræves til det specifikke forskningsspørgsmål.
Kvalitetskontrol under informationsindsamlingen sikrer, at de indsamlede data er nøjagtige, pålidelige og fri for bias eller fejl. Dårlig datakvalitet kan føre til ugyldige konklusioner og fejlinformerede beslutninger. Ifølge Forrester Research mister over 25% af organisationer mere end $5 millioner årligt på grund af dårlig datakvalitet. Implementering af strenge kvalitetskontrolforanstaltninger, herunder valideringstjek og standardiserede indsamlingsprocedurer, beskytter integriteten af hele forskningsprojektet.
I AI-overvågningsplatforme som AmICited indebærer informationsindsamlingsstadiet systematisk indsamling af data om, hvordan brands og domæner optræder i AI-genererede svar på tværs af platforme som ChatGPT, Perplexity, Google AI Overviews og Claude. Dette stadie kræver fastlæggelse af klare overvågningsmål, valg af passende sporingsmetoder og organisering af data fra flere AI-kilder for at give omfattende indblik i brandets synlighed.
Primære datakilder indebærer førstehåndsindsamling direkte fra kilden gennem spørgeskemaer, interviews eller eksperimenter og giver data, der er specifikke for forskningsmålene. Sekundære datakilder er allerede eksisterende information fra offentliggjorte rapporter, akademiske studier, offentlige statistikker eller historiske optegnelser. Primære data er typisk mere relevante og aktuelle, men kræver flere ressourcer, mens sekundære data er omkostningseffektive, men måske ikke er lige så specifikke for forskningsbehov.
Varigheden af informationsindsamlingsstadiet varierer betydeligt afhængigt af forskningsomfang, tilgængelige ressourcer og metoder til dataindsamling. Små kvalitative undersøgelser kan tage uger, mens store kvantitative forskningsprojekter kan strække sig over måneder eller år. Ifølge retningslinjer for forskningsmetodologi kan ordentlig planlægning og klare mål reducere indsamlingstiden med 20-30% og samtidig opretholde datakvalitet og validitetsstandarder.
Almindelige udfordringer inkluderer udvalgsbias, svarbias i spørgeskemaer, vanskeligheder ved adgang til visse datakilder, ressourcebegrænsninger og opretholdelse af datakvalitet på tværs af flere indsamlingsmetoder. Forskere står også over for udfordringer med dataorganisering, sikring af deltagerfortrolighed og håndtering af store mængder information. Håndtering af disse udfordringer kræver grundig planlægning, passende værktøjsvalg og implementering af robuste kvalitetskontrolprocedurer under hele indsamlingsprocessen.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Forskningsindhold er evidensbaseret materiale skabt gennem dataanalyse og ekspertindsigter. Lær hvordan datadrevet analytisk indhold opbygger autoritet, påvirke...
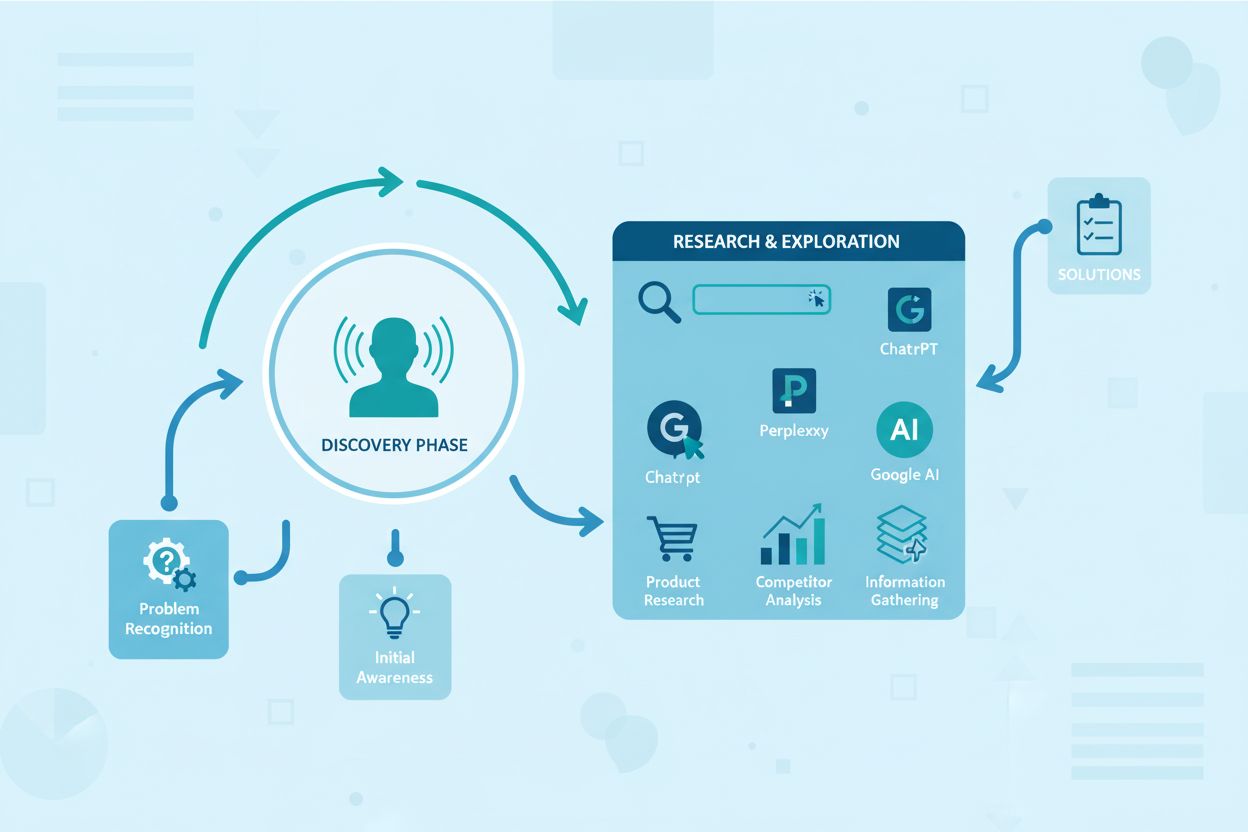
Lær hvad opdagelsesfasen er, hvorfor den er vigtig for AI-synlighed, og hvordan brands kan optimere deres tilstedeværelse under dette kritiske indledende opmærk...

Sekundær forskning analyserer eksisterende data fra flere kilder for at besvare nye spørgsmål. Lær hvordan organisationer bruger skrivebordsforskning til omkost...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.