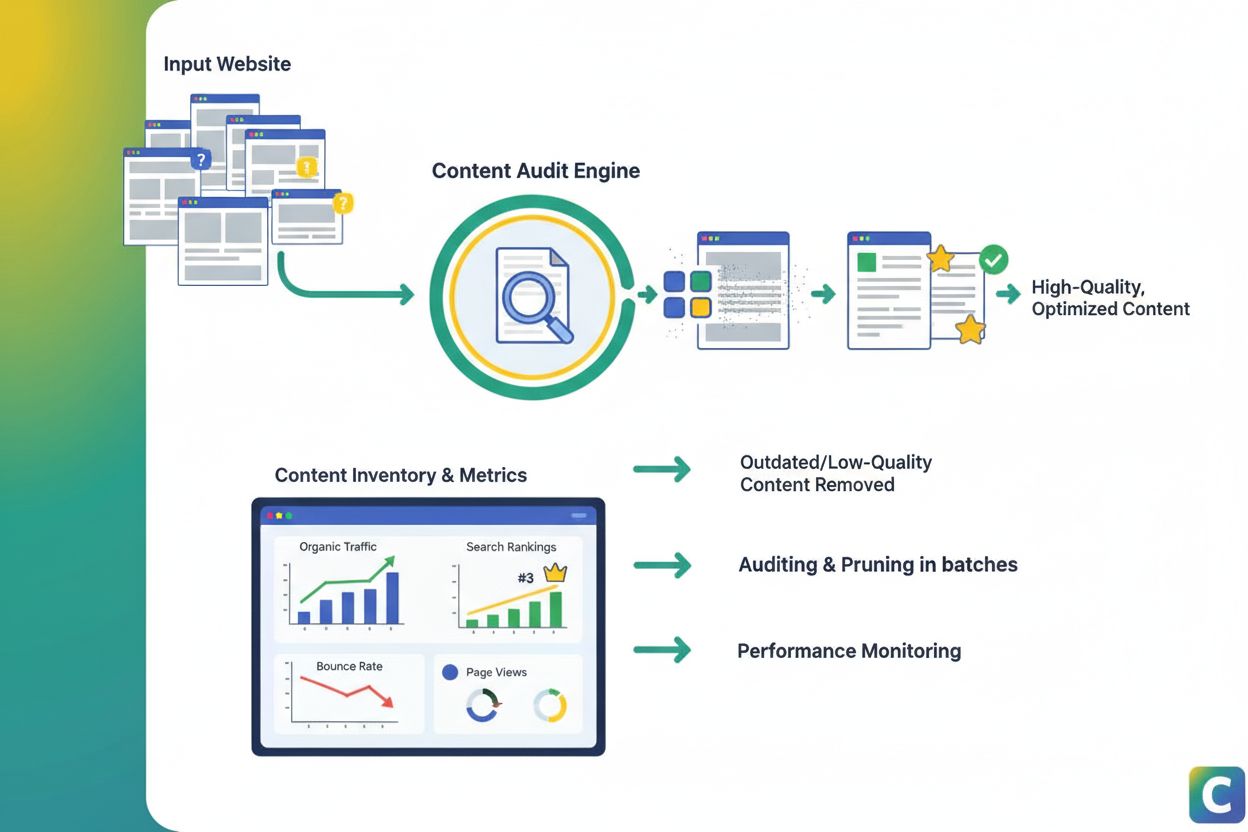
Indholdsbeskæring
Indholdsbeskæring er den strategiske fjernelse eller opdatering af underpræsterende indhold for at forbedre SEO, brugeroplevelse og søgesynlighed. Lær hvordan d...
14 min læsning

Et scraper-site er en hjemmeside, der automatisk kopierer indhold fra andre kilder uden tilladelse og genudgiver det, ofte med minimale ændringer. Disse sider bruger automatiserede bots til at indsamle data, tekst, billeder og andet indhold fra legitime hjemmesider for at fylde deres egne sider, typisk med henblik på bedrageri, plagiat eller for at generere annonceindtægter.
Et scraper-site er en hjemmeside, der automatisk kopierer indhold fra andre kilder uden tilladelse og genudgiver det, ofte med minimale ændringer. Disse sider bruger automatiserede bots til at indsamle data, tekst, billeder og andet indhold fra legitime hjemmesider for at fylde deres egne sider, typisk med henblik på bedrageri, plagiat eller for at generere annonceindtægter.
Et scraper-site er en hjemmeside, der automatisk kopierer indhold fra andre kilder uden tilladelse og genudgiver det, ofte med minimale ændringer eller omskrivninger. Disse sider bruger automatiserede bots til at indsamle data, tekst, billeder, produktbeskrivelser og andet indhold fra legitime hjemmesider for at fylde deres egne sider. Praksissen er teknisk set ulovlig i henhold til ophavsretsloven og krænker servicevilkårene for de fleste hjemmesider. Indholdsskrabning adskiller sig grundlæggende fra legitim web-skrabning, da det involverer uautoriseret kopiering af offentliggjort indhold til ondsindede formål, herunder bedrageri, plagiat, annonceindtægter og tyveri af intellektuel ejendom. Den automatiserede karakter af skrabningen gør det muligt for ondsindede aktører at kopiere tusindvis af sider på få minutter og skabe massive problemer med duplikeret indhold på internettet.
Indholdsskrabning har eksisteret siden internettets tidlige dage, men problemet er eskaleret dramatisk med fremskridt inden for automatiseringsteknologi og kunstig intelligens. I begyndelsen af 2000’erne var scrapers relativt simple og lette at opdage. Moderne scraper-bots er dog blevet stadig mere sofistikerede og bruger teknikker som omskrivningsalgoritmer, roterende IP-adresser og browserautomatisering for at undgå opdagelse. Fremkomsten af AI-drevet indholdsgenerering har gjort problemet værre, da scrapers nu bruger maskinlæring til at omskrive stjålet indhold på måder, der er sværere at identificere som dubletter. Ifølge brancheanalyser udgør scraper-sites en betydelig del af ondsindet bot-trafik, og nogle estimater antyder, at automatiserede bots udgør over 40 % af al internettrafik. Fremkomsten af AI-søgemaskiner som ChatGPT, Perplexity og Google AI Overviews har skabt nye udfordringer, da disse systemer utilsigtet kan citere scraper-sites i stedet for originale indholdsskabere og dermed forstærke problemet yderligere.
Scraper-bots fungerer gennem en flertrins automatiseret proces, der kræver minimal menneskelig indgriben. Først crawler botten udvalgte hjemmesider ved at følge links og få adgang til sider, downloade HTML-koden og alt tilhørende indhold. Botten parser derefter HTML’en for at udtrække relevante data såsom artikeltekst, billeder, metadata og produktinformation. Dette udtrukne indhold gemmes i en database, hvor det eventuelt behandles yderligere med omskrivningsværktøjer eller AI-drevet omskrivningssoftware for at skabe variationer, der fremstår anderledes end originalen. Til sidst genudgives det skrabede indhold på scraper-sitet, ofte med minimal kildeangivelse eller falske forfatteroplysninger. Nogle avancerede scrapers bruger roterende proxyer og user-agent-spoofing for at maskere deres forespørgsler som legitim menneskelig trafik, hvilket gør dem sværere at opdage og blokere. Hele processen kan være fuldt automatiseret og gør det muligt for én scraper-operation at kopiere tusindvis af sider dagligt fra flere hjemmesider på én gang.
| Aspekt | Scraper-site | Originalt indholdssite | Legitim dataaggregator |
|---|---|---|---|
| Indholdsoprindelse | Kopieret uden tilladelse | Oprettet originalt | Kurateret med kildeangivelse og links |
| Juridisk status | Ulovlig (ophavsretskrænkelse) | Beskyttet af ophavsret | Lovlig (med korrekt licens) |
| Kildeangivelse | Minimal eller falsk | Original forfatter krediteret | Kilder citeret og linket |
| Formål | Bedrageri, plagiat, annonceindtægt | Skabe værdi for publikum | Aggregere og organisere information |
| SEO-påvirkning | Negativ (duplikeret indhold) | Positiv (originalt indhold) | Neutral til positiv (med korrekt kanonisering) |
| Brugeroplevelse | Dårlig (indhold af lav kvalitet) | Høj (unikt, værdifuldt indhold) | God (organiseret, kildeangivet indhold) |
| Servicevilkår | Overtræder vilkår | Overholder egne vilkår | Respekterer hjemmesidens vilkår og robots.txt |
| Detektionsmetoder | IP-sporing, botsignaturer | N/A | Gennemsigtige crawl-mønstre |
Scraper-sites opererer ud fra flere forskellige forretningsmodeller, som alle er designet til at generere indtægter fra stjålet indhold. Den mest almindelige model er annoncebaseret indtjening, hvor scrapers fylder deres sider med reklamer fra netværk som Google AdSense eller andre annoncenetværk. Ved at genudgive populært indhold tiltrækker scrapers organisk søgetrafik og genererer annoncevisninger og -klik uden at skabe nogen original værdi. En anden udbredt model er e-handelsbedrageri, hvor scrapers opretter falske webshops, der efterligner legitime forhandlere, og kopierer produktbeskrivelser, billeder og priser. Intetanende kunder køber fra disse bedrageriske sider og modtager enten falske varer eller får deres betalingsoplysninger stjålet. E-mail-høstning er en anden betydelig forretningsmodel, hvor kontaktoplysninger indsamles fra hjemmesider og sælges til spammere eller bruges til målrettede phishingkampagner. Nogle scrapers deltager også i affiliate marketing-bedrageri ved at kopiere produktanmeldelser og indhold, mens de indsætter deres egne affiliate-links for at tjene provision. De lave driftsomkostninger ved skrabning—der kun kræver serverplads og automatiseret software—gør disse forretningsmodeller meget indbringende trods deres ulovlige karakter.
Konsekvenserne af indholdsskrabning for originale skabere er alvorlige og mangesidede. Når scrapers genudgiver dit indhold på deres domæner, skaber de duplikeret indhold, der forvirrer søgemaskiner om, hvilken version der er originalen. Googles algoritme kan have vanskeligt ved at identificere den autoritative kilde, hvilket potentielt kan få både originalen og de skrabede versioner til at rangere lavere i søgeresultaterne. Dette har direkte indvirkning på organisk trafik, da dit omhyggeligt optimerede indhold mister synlighed til scraper-sites, der ikke har bidraget til indholdets skabelse. Ud over søgerangeringer forvansker scrapers dine webstatistikker ved at generere falsk trafik fra bots, hvilket gør det svært at forstå ægte brugeradfærd og engagement. Dine serverressourcer bliver også spildt på at håndtere forespørgsler fra scraper-bots, hvilket øger båndbreddeomkostninger og potentielt sænker din side for legitime besøgende. Den negative SEO-påvirkning rækker ud over domæneautoritet og linkprofil, da scrapers kan skabe links af lav kvalitet til dit site eller bruge dit indhold i spam-sammenhænge. Derudover mister du muligheden for at etablere thought leadership og autoritet i din branche, når scrapers rangerer højere end dit originale indhold i søgeresultaterne, hvilket skader dit brands omdømme og troværdighed.
At identificere scraper-sites kræver en kombination af manuelle og automatiserede tilgange. Google Alerts er et af de mest effektive gratis værktøjer, der lader dig overvåge dine artikeltitler, unikke sætninger og brandnavn for uautoriseret genudgivelse. Når Google Alerts giver besked om et match, kan du undersøge, om det er en legitim kildeangivelse eller et scraper-site. Pingback-overvågning er særlig nyttig for WordPress-sider, da pingbacks genereres, når andre sider linker til dit indhold. Hvis du modtager pingbacks fra ukendte eller mistænkelige domæner, kan det være scraper-sites, der har kopieret dine interne links. SEO-værktøjer som Ahrefs, SEM Rush og Grammarly tilbyder funktioner til at finde duplikeret indhold, der scanner nettet for sider, der matcher dit indhold. Disse værktøjer kan identificere både nøjagtige dubletter og omskrevne versioner af dine artikler. Serverlog-analyse giver teknisk indsigt i bot-trafikmønstre og afslører mistænkelige IP-adresser, usædvanlige forespørgselsrater og bot-user-agents. Reverse image search med Google Billeder eller TinEye kan hjælpe med at finde steder, hvor dine billeder er blevet genudgivet uden tilladelse. Regelmæssig overvågning af din Google Search Console kan afsløre indekseringsanomalier og problemer med duplikeret indhold, som kan indikere skrabning.
Indholdsskrabning overtræder flere lag af juridisk beskyttelse og er en af de mest retsforfølgelsesværdige former for onlinebedrageri. Ophavsretsloven beskytter automatisk alt originalt indhold, uanset om det er offentliggjort online eller trykt, og giver skabere eneret til at reproducere, distribuere og vise deres arbejde. At skrabe indhold uden tilladelse er en direkte krænkelse af ophavsret og udsætter scrapers for civilretligt ansvar, herunder erstatning og påbud. Digital Millennium Copyright Act (DMCA) giver yderligere beskyttelse ved at forbyde omgåelse af teknologiske foranstaltninger, der kontrollerer adgang til ophavsretligt beskyttet materiale. Hvis du implementerer adgangskontrol eller anti-scraping-foranstaltninger, gør DMCA det ulovligt at omgå dem. Computer Fraud and Abuse Act (CFAA) kan også finde anvendelse, især når bots får adgang til systemer uden autorisation eller overskrider den tilladte adgang. Hjemmesiders servicevilkår forbyder ofte udtrykkeligt skrabning, og overtrædelse af disse vilkår kan føre til retslige skridt for kontraktbrud. Mange indholdsskabere har med succes ført retssager mod scrapers og opnået retskendelser om at fjerne indhold og stoppe skrabeaktiviteter. Nogle jurisdiktioner har også anerkendt skrabning som en form for illoyal konkurrence, hvilket gør det muligt for virksomheder at sagsøge for tabt omsætning og markedsmæssig skade.
Fremkomsten af AI-søgemaskiner og store sprogmodeller (LLM’er) har tilføjet en ny dimension til scraper-problemet. Når AI-systemer som ChatGPT, Perplexity, Google AI Overviews og Claude crawler nettet for at indsamle træningsdata eller generere svar, kan de støde på scraper-sites sammen med originalt indhold. Hvis scraper-sitet forekommer hyppigere eller har bedre teknisk SEO, kan AI-systemet citere scraperen i stedet for den oprindelige kilde. Dette er særligt problematisk, da AI-citater tillægges stor betydning for brands synlighed og autoritet. Når et scraper-site citeres i et AI-svar i stedet for dit originale indhold, mister du muligheden for at etablere dit brand som en autoritativ kilde i AI-drevne søgeresultater. Derudover kan scrapers introducere unøjagtigheder eller forældet information i AI-træningsdata og potentielt få AI-systemer til at generere forkerte eller misvisende svar. Problemet forværres af, at mange AI-systemer ikke har gennemsigtig kildeangivelse, hvilket gør det svært for brugere at verificere, om de læser originalt indhold eller skrabet materiale. Overvågningsværktøjer som AmICited hjælper indholdsskabere med at spore, hvor deres brand og indhold optræder på tværs af AI-platforme, så man kan identificere, når scrapers konkurrerer om synlighed i AI-svar.
Beskyttelse af dit indhold mod skrabning kræver en flerlaget teknisk og operationel tilgang. Bot-detektion og blokering som ClickCease’s Bot Zapping kan identificere og blokere ondsindede bots, før de får adgang til dit indhold, og omdirigere dem til fejlsider i stedet for de rigtige sider. Robots.txt-konfiguration giver dig mulighed for at begrænse bots adgang til specifikke mapper eller sider, selvom målrettede scrapers kan ignorere disse instruktioner. Noindex-tags kan anvendes på følsomme sider eller automatisk genereret indhold (som WordPress tag- og kategorisider) for at forhindre, at de indekseres og skrabes. Adgangskontrol kræver, at brugere udfylder formularer eller logger ind for at få adgang til premium-indhold, hvilket gør det sværere for bots at indsamle oplysninger i stor skala. Rate limiting på din server begrænser antallet af forespørgsler fra en enkelt IP-adresse inden for en given periode, hvilket bremser scraper-bots og gør deres drift mindre effektiv. CAPTCHA-udfordringer kan verificere, at forespørgsler kommer fra mennesker i stedet for bots, selvom avancerede bots nogle gange kan omgå disse. Server-side overvågning af forespørgselsmønstre hjælper med at identificere mistænkelig aktivitet, så du proaktivt kan blokere problematiske IP-adresser. Regelmæssige backups af dit indhold sikrer, at du har dokumentation for originale oprettelsesdatoer, hvilket er værdifuldt, hvis du skal føre sag mod scrapers.
Scraper-landskabet udvikler sig løbende i takt med teknologiens fremskridt og nye muligheder. AI-drevet omskrivning bliver stadig mere sofistikeret, hvilket gør skrabet indhold sværere at opdage som dubletter med traditionelle plagiatværktøjer. Scrapers investerer i mere avanceret proxy-rotation og browser-automatisering for at undgå bot-detektion. Fremkomsten af AI-træningsdatascraping er et nyt område, hvor scrapers målretter indhold specifikt til brug i træning af maskinlæringsmodeller, ofte uden kompensation til de oprindelige skabere. Nogle scrapers bruger nu headless-browsere og JavaScript-rendering for at få adgang til dynamisk indhold, som traditionelle scrapers ikke kunne nå. Integration af skrabning med affiliate-netværk og annoncebedrageri skaber mere komplekse og sværere at opdage scraper-operationer. Dog er der også positive udviklinger: AI-detekteringssystemer bliver bedre til at identificere skrabet indhold, og søgemaskiner straffer i stigende grad scraper-sites i deres algoritmer. Googles core-opdatering i november 2024 var specifikt rettet mod scraper-sites og resulterede i betydelige synlighedstab for mange scraper-domæner. Indholdsskabere tager også i stigende grad i brug vandmærketeknologier og blockchain-baseret verifikation for at bevise original skabelse og ejerskab. Efterhånden som AI-søgemaskiner modnes, implementerer de bedre kildeangivelse og gennemsigtighed for at sikre, at originale skabere får den rette kredit og synlighed.
For indholdsskabere og brandmanagers rækker udfordringen med scraper-sites ud over traditionelle søgemaskiner til det nye landskab af AI-drevet søgning og svarsystemer. AmICited tilbyder specialiseret overvågning til at spore, hvor dit brand, indhold og domæne optræder på AI-platforme som Perplexity, ChatGPT, Google AI Overviews og Claude. Ved at overvåge din AI-synlighed kan du identificere, når scraper-sites konkurrerer om citater i AI-svar, når dit originale indhold krediteres korrekt, og når uautoriserede kopier vinder frem. Denne indsigt gør det muligt for dig at handle proaktivt for at beskytte din intellektuelle ejendom og opretholde din brandauthoritet i AI-drevne søgeresultater. At forstå forskellen på legitim indholdsaggregator og ondsindet skrabning er afgørende i AI-æraen, da indsatsen for brandsynlighed og autoritet aldrig har været højere.
Ja, indholdsskrabning er teknisk set ulovligt i de fleste jurisdiktioner. Det overtræder ophavsretslove, der beskytter digitalt indhold på samme måde som fysiske publikationer. Derudover overtræder skrabning ofte hjemmesiders servicevilkår og kan udløse retlige skridt i henhold til Digital Millennium Copyright Act (DMCA) og Computer Fraud and Abuse Act (CFAA). Ejere af hjemmesider kan retsforfølge skrabere civilretligt og strafferetligt.
Scraper-sites påvirker SEO negativt på flere måder. Når duplikeret indhold fra scrapers rangerer højere end det originale, udvandes den oprindelige sides synlighed i søgninger og organiske trafik. Googles algoritme har svært ved at identificere, hvilken version der er originalen, hvilket potentielt kan få alle versioner til at rangere lavere. Derudover spilder scrapers dit sites crawl-budget og kan forvride dine analyser, hvilket gør det svært at forstå ægte brugeradfærd og præstationsmålinger.
Scraper-sites tjener flere ondsindede formål: at oprette falske e-handelsbutikker for at begå bedrageri, hoste forfalskede hjemmesider, der efterligner legitime brands, generere annonceindtægter gennem bedragerisk trafik, plagiere indhold for at fylde sider uden indsats og indsamle e-maillister og kontaktoplysninger til spamkampagner. Nogle scrapers målretter også prisoplysninger, produktdetaljer og indhold fra sociale medier til konkurrenceanalyse eller videresalg.
Du kan opdage skrabet indhold på flere måder: opsæt Google Alerts for dine artikeltitler eller unikke sætninger, søg dine indholdstitler på Google for at se, om der dukker dubletter op, tjek for pingbacks på interne links (især i WordPress), brug SEO-værktøjer som Ahrefs eller SEM Rush til at finde duplikeret indhold, og overvåg dit websites trafikmønstre for usædvanlig bot-aktivitet. Regelmæssig overvågning hjælper dig med hurtigt at identificere scrapers.
Web-skrabning er en bredere teknisk betegnelse for at udtrække data fra hjemmesider, hvilket kan være legitimt, når det sker med tilladelse til forskning eller dataanalyse. Indholdsskrabning henviser specifikt til uautoriseret kopiering af udgivet indhold som artikler, produktbeskrivelser og billeder med henblik på genudgivelse. Mens web-skrabning kan være lovlig, er indholdsskrabning grundlæggende ondsindet og ulovlig, da det overtræder ophavsret og servicevilkår.
Scraper-bots bruger automatiseret software til at crawle hjemmesider, downloade HTML-indhold, udtrække tekst og billeder og gemme dem i databaser. Disse bots simulerer menneskelig browseradfærd for at omgå basale detektionsmetoder. De kan få adgang til både offentligt synligt indhold og nogle gange skjulte databaser, hvis sikkerheden er svag. De indsamlede data behandles derefter, nogle gange omskrevet ved hjælp af AI-værktøjer, og genudgives på scraper-sites med minimale ændringer for at undgå nøjagtig dubletdetektion.
Effektive forebyggelsesstrategier omfatter implementering af bot-detektion og blokering, brug af robots.txt til at begrænse bots adgang, tilføjelse af noindex-tags til følsomme sider, at lægge premium-indhold bag login-formularer, løbende overvågning med Google Alerts og SEO-værktøjer, brug af CAPTCHA-udfordringer, implementering af rate limiting på din server og overvågning af serverlogs for mistænkelige IP-adresser og trafikmønstre. En flerlags tilgang er mest effektiv.
Scraper-sites udgør en betydelig udfordring for AI-søgemaskiner som ChatGPT, Perplexity og Google AI Overviews. Når AI-systemer crawler nettet for træningsdata eller for at generere svar, kan de støde på skrabet indhold og citere scraper-sites i stedet for originale kilder. Dette udvander synligheden for legitime indholdsskabere i AI-svar og kan få AI-systemer til at sprede misinformation. Overvågningsværktøjer som AmICited hjælper med at spore, hvor dit brand og indhold optræder på tværs af AI-platforme.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Indholdsbeskæring er den strategiske fjernelse eller opdatering af underpræsterende indhold for at forbedre SEO, brugeroplevelse og søgesynlighed. Lær hvordan d...
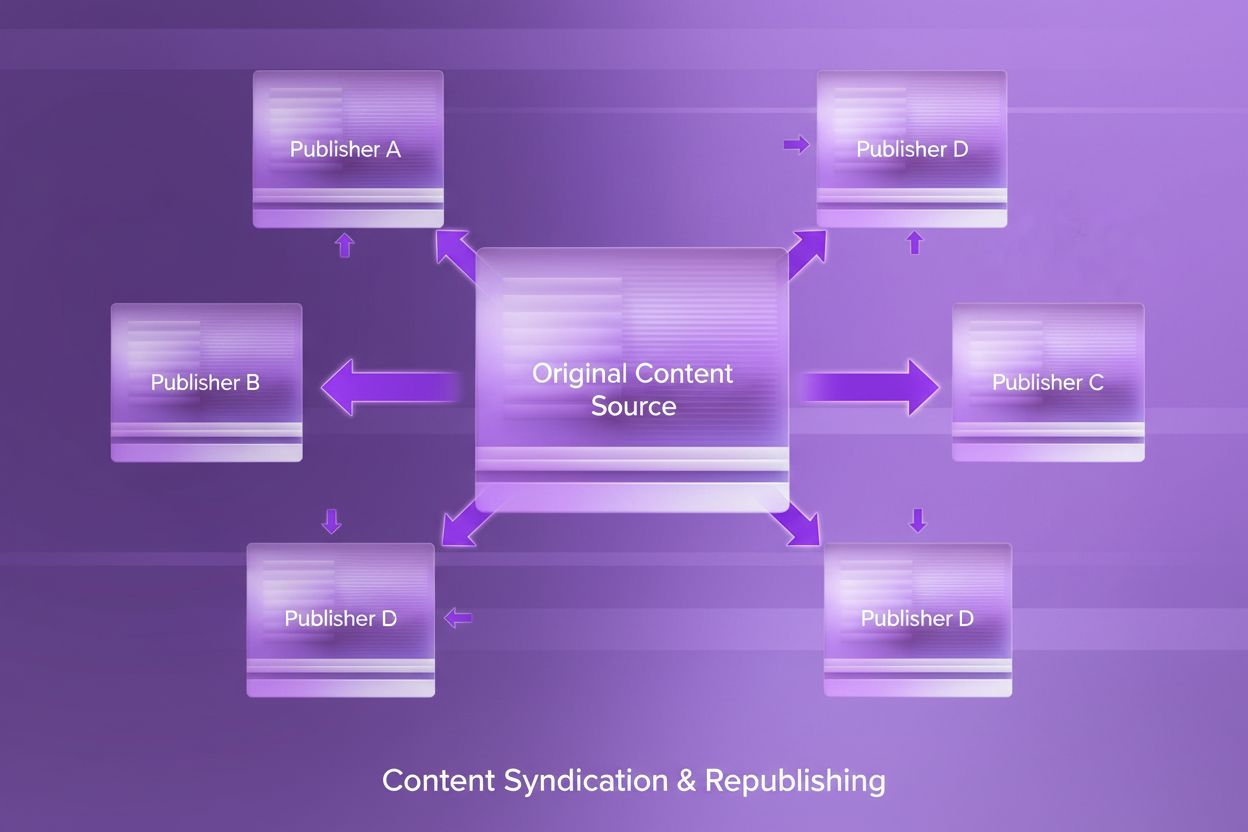
Lær hvad indholdssyndikering er, hvordan det fungerer, dets SEO-konsekvenser og bedste praksis for genudgivelse af indhold på tværs af platforme for at udvide r...

Hacket indhold er uautoriseret hjemmeside-materiale ændret af cyberkriminelle. Lær hvordan kompromitterede hjemmesider påvirker SEO, AI-søgeresultater og brande...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.