
Wie Sie den Zugriff von KI-Crawlern auf Ihre Website testen
Erfahren Sie, wie Sie testen können, ob KI-Crawler wie ChatGPT, Claude und Perplexity auf Ihre Website-Inhalte zugreifen können. Entdecken Sie Testmethoden, Too...
9 Min. Lesezeit

Erfahren Sie, wie Sie den Zugang von KI-Crawlern zu Ihrer Website prüfen. Entdecken Sie, welche Bots Ihre Inhalte sehen können, und beheben Sie Blocker, die die Sichtbarkeit in ChatGPT, Perplexity und anderen KI-Suchmaschinen verhindern.
Die Landschaft der Suche und Inhaltsentdeckung verändert sich dramatisch. Mit KI-gestützten Suchtools wie ChatGPT, Perplexity und Google AI Overviews, die exponentiell wachsen, ist die Sichtbarkeit Ihrer Inhalte für KI-Crawler genauso entscheidend wie die klassische Suchmaschinenoptimierung. Wenn KI-Bots Ihre Inhalte nicht erreichen, wird Ihre Website für Millionen von Nutzern unsichtbar, die auf diesen Plattformen nach Antworten suchen. Die Risiken sind hoch: Während Google Ihre Website erneut besucht, wenn etwas schiefgeht, funktionieren KI-Crawler nach einem anderen Prinzip – und ein verpasster, erster, kritischer Crawl kann Monate verlorener Sichtbarkeit und verpasster Chancen für Zitationen, Traffic und Markenautorität bedeuten.
KI-Crawler arbeiten nach grundlegend anderen Regeln als die Google- und Bing-Bots, für die Sie bisher optimiert haben. Der wichtigste Unterschied: KI-Crawler rendern kein JavaScript, das heißt, dynamische Inhalte, die clientseitig geladen werden, sind für sie unsichtbar – im Gegensatz zu Googles fortschrittlichen Rendering-Fähigkeiten. Zudem besuchen KI-Crawler Websites mit deutlich höherer Frequenz – manchmal 100-mal häufiger als traditionelle Suchmaschinen – was Chancen, aber auch Herausforderungen für Ihre Serverressourcen schafft. Anders als bei Googles Indexierungsmodell pflegen KI-Crawler keinen dauerhaften Index, der regelmäßig aktualisiert wird; sie crawlen bedarfsgesteuert, wenn Nutzer ihre Systeme abfragen. Das bedeutet: Es gibt keine erneute Indexierungs-Warteschlange, keine Search Console für Crawl-Anfragen und keine zweite Chance, wenn Ihre Website beim ersten Besuch versagt. Diese Unterschiede zu verstehen, ist entscheidend für die Optimierung Ihrer Content-Strategie.
| Merkmal | KI-Crawler | Traditionelle Bots |
|---|---|---|
| JavaScript-Rendering | Nein (nur statisches HTML) | Ja (vollständiges Rendering) |
| Crawl-Frequenz | Sehr hoch (100x+ häufiger) | Moderat (wöchentlich/monatlich) |
| Re-Indexierungs-Möglichkeit | Keine (nur bei Bedarf) | Ja (kontinuierliche Updates) |
| Inhaltsanforderungen | Reines HTML, Schema-Markup | Flexibel (verarbeitet dynamische Inhalte) |
| User-Agent-Blockierung | Spezifisch pro Bot (GPTBot, ClaudeBot, etc.) | Generisch (Googlebot, Bingbot) |
| Caching-Strategie | Kurzfristige Snapshots | Langfristige Indexpflege |
Ihre Inhalte könnten für KI-Crawler aus Gründen unsichtbar sein, die Sie bislang nicht bedacht haben. Hier sind die wichtigsten Hindernisse, die KI-Bots am Zugriff und Verständnis Ihrer Inhalte hindern:
Ihre robots.txt-Datei ist das wichtigste Instrument, um zu steuern, welche KI-Bots auf Ihre Inhalte zugreifen dürfen. Sie arbeitet mit spezifischen User-Agent-Regeln, die einzelne Crawler ansprechen. Jede KI-Plattform verwendet eigene User-Agent-Strings – OpenAIs GPTBot, Anthropics ClaudeBot, Perplexitys PerplexityBot – und Sie können jeden individuell erlauben oder ausschließen. Diese granulare Kontrolle erlaubt es Ihnen, zu entscheiden, welche KI-Systeme Ihre Inhalte zum Training oder zur Zitation nutzen können – wichtig für den Schutz proprietärer Informationen oder das Wettbewerbsmanagement. Viele Seiten blockieren KI-Crawler jedoch unbewusst durch zu breite Regeln, die einst für ältere Bots gedacht waren, oder sie verzichten ganz auf angemessene Regeln.
Hier ein Beispiel, wie Sie Ihre robots.txt für verschiedene KI-Bots konfigurieren:
# OpenAIs GPTBot erlauben
User-agent: GPTBot
Allow: /
# Anthropics ClaudeBot blockieren
User-agent: ClaudeBot
Disallow: /
# Perplexity erlauben, aber bestimmte Verzeichnisse ausschließen
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Standardregel für alle anderen Bots
User-agent: *
Allow: /
Im Gegensatz zu Google, das Ihre Website regelmäßig crawlt und neu indexiert, arbeiten KI-Crawler nach dem One-Shot-Prinzip – sie besuchen Ihre Seite, wenn ein Nutzer ihr System abfragt, und wenn Ihre Inhalte in diesem Moment nicht erreichbar sind, ist die Chance vertan. Diese grundlegende Differenz bedeutet: Ihre Website muss technisch vom ersten Tag an bereit sein; es gibt keine Schonfrist, keine zweite Chance zur Fehlerbehebung, bevor die Sichtbarkeit leidet. Ein schlechtes erstes Crawl-Erlebnis – etwa durch JavaScript-Rendering-Probleme, fehlendes Schema-Markup oder Serverfehler – kann dazu führen, dass Ihre Inhalte für Wochen oder Monate aus KI-generierten Antworten ausgeschlossen werden. Es gibt keine manuelle Re-Indexierungsoption, keinen „Indexierung anfordern“-Button in einer Konsole, was proaktives Monitoring und Optimierung unverzichtbar macht. Der Druck, es beim ersten Mal richtig zu machen, war nie höher.
Sich auf geplante Crawls zur Überwachung des KI-Crawler-Zugriffs zu verlassen, ist, als würden Sie Ihr Haus nur einmal im Monat auf Brände kontrollieren – Sie verpassen die entscheidenden Momente, wenn Probleme auftreten. Echtzeitüberwachung erkennt Probleme in dem Moment, in dem sie entstehen, sodass Sie reagieren können, bevor Ihre Inhalte für KI-Systeme unsichtbar werden. Geplante Audits, die meist wöchentlich oder monatlich laufen, schaffen gefährliche Blindspots, in denen Ihre Seite tagelang für KI-Crawler ausfallen könnte, ohne dass Sie es merken. Echtzeitlösungen verfolgen das Crawler-Verhalten kontinuierlich und warnen Sie bei JavaScript-Renderfehlern, Schema-Auszeichnungsfehlern, Firewall-Blockaden oder Serverproblemen sofort. Dieser proaktive Ansatz macht aus Ihrem Audit einen aktiven Sichtbarkeitsmanagement-Prozess statt einer reaktiven Kontrollmaßnahme. Bei potenziell 100-mal höherem KI-Crawler-Traffic im Vergleich zu klassischen Suchmaschinen kann selbst der Ausfall weniger Stunden erhebliche Auswirkungen haben.
Mehrere Plattformen bieten mittlerweile spezialisierte Tools zur Überwachung und Optimierung des KI-Crawler-Zugriffs. Cloudflare AI Crawl Control ermöglicht das Management von KI-Bot-Traffic auf Infrastrukturebene, mit der Möglichkeit, Zugriffsbeschränkungen und Richtlinien zu setzen. Conductor bietet umfassende Überwachungs-Dashboards, die zeigen, wie verschiedene KI-Crawler mit Ihren Inhalten interagieren. Elementive fokussiert sich auf technische SEO-Audits mit besonderem Augenmerk auf KI-Crawler-Anforderungen. AdAmigo und MRS Digital bieten spezialisierte Beratungs- und Überwachungsdienste für KI-Sichtbarkeit an. Für kontinuierliche, speziell auf KI-Crawler-Zugriffsmuster ausgelegte Echtzeitüberwachung und frühzeitige Warnungen vor Sichtbarkeitsproblemen hebt sich jedoch AmICited als dedizierte Lösung hervor. AmICited ist darauf spezialisiert, zu überwachen, welche KI-Systeme auf Ihre Inhalte zugreifen, wie häufig sie crawlen und ob technische Barrieren auftreten. Dieser spezialisierte Fokus auf das Verhalten von KI-Crawlern – und nicht auf klassische SEO-Metriken – macht das Tool für Unternehmen mit ernsthaftem KI-Sichtbarkeitsanspruch unverzichtbar.
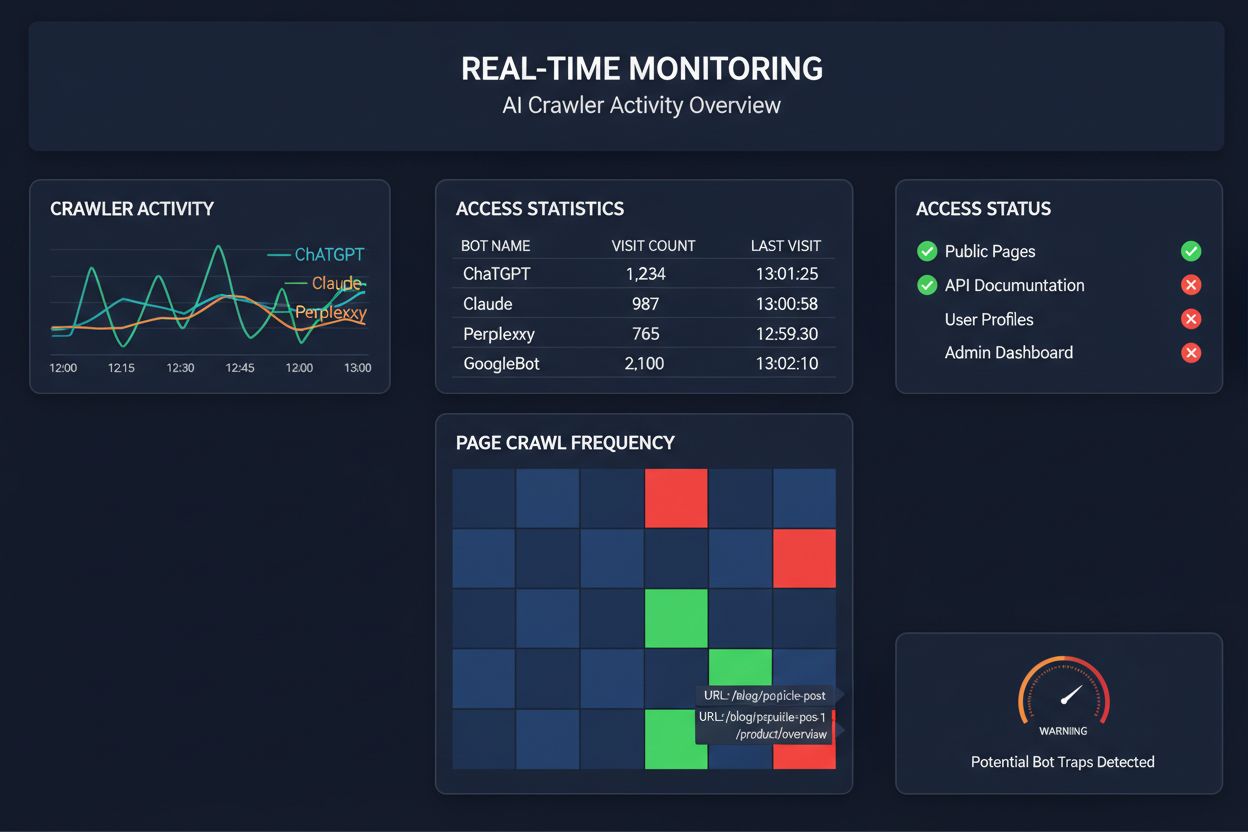
Eine umfassende KI-Crawler-Prüfung erfordert systematisches Vorgehen. Schritt 1: Ermitteln Sie den Status quo, indem Sie Ihre aktuelle robots.txt-Datei prüfen und feststellen, welche KI-Bots derzeit zugelassen oder blockiert werden. Schritt 2: Prüfen Sie Ihre technische Infrastruktur, indem Sie testen, wie zugänglich Ihre Website für Crawler ohne JavaScript ist, Serverantwortzeiten messen und sicherstellen, dass kritische Inhalte im statischen HTML ausgeliefert werden. Schritt 3: Implementieren und validieren Sie Schema-Markup für alle Inhalte, damit Autorenschaft, Veröffentlichungsdatum, Inhaltstyp und weitere Metadaten korrekt als JSON-LD strukturiert sind. Schritt 4: Überwachen Sie das Verhalten der Crawler mit Tools wie AmICited, um zu sehen, welche KI-Bots Ihre Website besuchen, wie häufig und ob Fehler auftreten. Schritt 5: Analysieren Sie die Ergebnisse, indem Sie Crawl-Logs auswerten, Fehlermuster erkennen und Korrekturen nach Auswirkungen priorisieren. Schritt 6: Setzen Sie Optimierungen um, beginnend mit Problemen wie JavaScript-Rendering oder fehlendem Schema und anschließend sekundäre Verbesserungen. Schritt 7: Etablieren Sie fortlaufendes Monitoring, um neue Fehler frühzeitig zu erkennen, und richten Sie Benachrichtigungen für Crawlfehler oder Zugriffsblockaden ein.
Sie müssen Ihre Website nicht komplett umbauen, um den KI-Crawler-Zugriff zu verbessern – einige Maßnahmen mit großem Effekt lassen sich schnell umsetzen. Liefern Sie kritische Inhalte in reinem HTML aus, statt auf JavaScript-Rendering zu setzen; falls JavaScript unvermeidlich ist, stellen Sie sicher, dass wichtige Texte und Metadaten bereits im initialen HTML-Payload enthalten sind. Fügen Sie umfassendes Schema-Markup im JSON-LD-Format hinzu, z. B. Article-Schema, Autoreninformationen, Veröffentlichungsdaten und Inhaltsbeziehungen – das hilft KI-Crawlern, Kontext zu verstehen und Inhalte korrekt zuzuordnen. Sorgen Sie für klare Autorenangaben durch Schema-Markup und Byline, da KI-Systeme zunehmend Wert auf Zitate aus autoritativen Quellen legen. Überwachen und optimieren Sie Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), da langsam ladende Seiten von Crawlern vorzeitig abgebrochen werden können. Überprüfen und aktualisieren Sie Ihre robots.txt, damit Sie nicht versehentlich KI-Bots blockieren, die Ihre Inhalte sehen sollen. Beheben Sie technische Fehler wie Weiterleitungsketten, defekte Links und Serverfehler, die Crawler während des Crawlens zum Abbruch zwingen.
Nicht alle KI-Crawler verfolgen denselben Zweck, und das Verständnis dieser Unterschiede hilft Ihnen, fundierte Entscheidungen beim Zugriffsmanagement zu treffen. GPTBot (OpenAI) dient hauptsächlich der Sammlung von Trainingsdaten und der Verbesserung von Modellen, ist also relevant, wenn Sie möchten, dass Ihre Inhalte ChatGPT-Antworten beeinflussen. OAI-SearchBot (OpenAI) crawlt gezielt für Suchzitate und ist der Bot, der Ihre Inhalte in ChatGPTs suchbasierte Antworten integriert. ClaudeBot (Anthropic) übernimmt vergleichbare Aufgaben für Claude, den KI-Assistenten von Anthropic. PerplexityBot (Perplexity) crawlt für Zitate in Perplexitys KI-Suchmaschine, die für viele Publisher zu einer wichtigen Traffic-Quelle geworden ist. Jeder Bot hat unterschiedliche Crawl-Muster, Frequenzen und Zwecke – einige konzentrieren sich auf Trainingsdaten, andere auf Echtzeit-Suchzitate. Welche Bots Sie zulassen oder blockieren, sollte zu Ihrer Content-Strategie passen: Möchten Sie Zitate in KI-Suchergebnissen, erlauben Sie die suchspezifischen Bots; sind Sie wegen der Datennutzung im Training besorgt, blockieren Sie die datensammelnden Bots und erlauben nur Suchbots. Dieser differenzierte Ansatz ist deutlich ausgefeilter als das traditionelle „alles erlauben“ oder „alles blockieren“.
Ein KI-Crawler-Audit ist eine umfassende Bewertung der Zugänglichkeit Ihrer Website für KI-Bots wie ChatGPT, Claude und Perplexity. Es identifiziert technische Blockaden, Probleme bei der JavaScript-Renderung, fehlende Schema-Auszeichnungen und andere Faktoren, die verhindern, dass KI-Crawler auf Ihre Inhalte zugreifen und diese verstehen. Das Audit liefert umsetzbare Empfehlungen zur Verbesserung Ihrer Sichtbarkeit in KI-gestützten Such- und Antwortmaschinen.
Wir empfehlen, mindestens vierteljährlich ein umfassendes Audit durchzuführen oder immer dann, wenn Sie wesentliche Änderungen an der technischen Infrastruktur, der Inhaltsstruktur oder der robots.txt-Datei Ihrer Website vornehmen. Idealerweise erfolgt jedoch eine kontinuierliche Echtzeitüberwachung, um Probleme sofort zu erkennen, sobald sie auftreten. Viele Organisationen nutzen automatisierte Überwachungstools, die sie in Echtzeit über Crawl-Fehler benachrichtigen und durch vierteljährliche Tiefenprüfungen ergänzen.
Das Zulassen von KI-Crawlern bedeutet, dass Ihre Inhalte von KI-Systemen abgerufen, analysiert und möglicherweise zitiert werden können, was Ihre Sichtbarkeit in KI-generierten Antworten und Empfehlungen erhöhen kann. Das Blockieren von KI-Crawlern verhindert deren Zugriff auf Ihre Inhalte, schützt vertrauliche Informationen, kann aber die Sichtbarkeit in KI-Suchergebnissen verringern. Die richtige Wahl hängt von Ihren Geschäftszielen, der Sensibilität Ihrer Inhalte und Ihrer Wettbewerbspositionierung ab.
Ja, absolut. Ihre robots.txt-Datei ermöglicht eine granulare Steuerung über User-Agent-Regeln. Sie können beispielsweise GPTBot blockieren, während Sie PerplexityBot erlauben, oder suchorientierte Bots (wie OAI-SearchBot) zulassen und datensammelnde Bots (wie GPTBot) blockieren. Dieser differenzierte Ansatz erlaubt es Ihnen, Ihre Content-Strategie darauf abzustimmen, welche KI-Plattformen für Ihr Unternehmen am wichtigsten sind.
Wenn KI-Crawler nicht auf Ihre Inhalte zugreifen können, ist Ihre Website für KI-gestützte Suchmaschinen und Antwortplattformen im Grunde unsichtbar. Ihre Inhalte werden nicht zitiert, empfohlen oder in KI-generierte Antworten aufgenommen, selbst wenn sie hochrelevant sind. Das kann zu Verlust von Traffic, geringerer Markensichtbarkeit und verpassten Chancen führen, Autorität in KI-Suchergebnissen aufzubauen.
Sie können Ihre Server-Logs auf User-Agent-Strings bekannter KI-Crawler (GPTBot, ClaudeBot, PerplexityBot etc.) überprüfen oder spezialisierte Überwachungstools wie AmICited verwenden, die KI-Crawler-Aktivitäten in Echtzeit verfolgen. Diese Tools zeigen Ihnen, welche Bots Ihre Website besuchen, wie häufig sie crawlen, welche Seiten sie ansteuern und ob sie auf Fehler oder Blockaden stoßen.
Das hängt von Ihrer individuellen Situation ab. Wenn Ihre Inhalte vertraulich, sensibel oder Sie wegen der Verwendung als Trainingsdaten besorgt sind, kann das Blockieren sinnvoll sein. Möchten Sie jedoch Sichtbarkeit in KI-Suchergebnissen und Zitationen durch KI-Systeme, ist das Zulassen von Crawlern unerlässlich. Viele Unternehmen wählen einen Mittelweg: Sie erlauben suchorientierte Bots, die Zitationen bringen, und blockieren datensammelnde Bots.
KI-Crawler rendern kein JavaScript, d. h. alle Inhalte, die dynamisch durch clientseitige Skripte geladen werden, sind für sie unsichtbar. Wenn Ihre Website stark auf JavaScript für wesentliche Inhalte, Navigation oder strukturierte Daten setzt, sehen KI-Crawler nur das rohe HTML und wichtige Informationen gehen verloren. Das kann erheblich beeinflussen, wie Ihre Inhalte von KI verstanden und dargestellt werden. Kritische Inhalte sollten daher immer in statischem HTML bereitgestellt werden, um KI-Crawlability sicherzustellen.
Erhalten Sie Echtzeit-Einblicke darüber, welche KI-Bots auf Ihre Inhalte zugreifen und wie sie Ihre Website sehen. Starten Sie noch heute Ihr kostenloses Audit und stellen Sie sicher, dass Ihre Marke auf allen KI-Suchplattformen sichtbar ist.
Erfahren Sie, wie Sie testen können, ob KI-Crawler wie ChatGPT, Claude und Perplexity auf Ihre Website-Inhalte zugreifen können. Entdecken Sie Testmethoden, Too...

Erfahren Sie, wie Sie KI-Crawler wie GPTBot und ClaudeBot mit robots.txt, serverseitiger Blockierung und erweiterten Schutzmethoden blockieren oder zulassen. Vo...
Lernen Sie bewährte Strategien, um die Besuchshäufigkeit von KI-Crawlern auf Ihrer Website zu steigern und die Auffindbarkeit Ihrer Inhalte in ChatGPT, Perplexi...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.