Verstehen Sie, wie KI-Crawler wie GPTBot und ClaudeBot funktionieren, wo sie sich von traditionellen Such-Crawlern unterscheiden und wie Sie Ihre Website für Sichtbarkeit in KI-Suchmaschinen optimieren.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
KI-Crawler sind automatisierte Programme, die dazu entwickelt wurden, systematisch das Internet zu durchsuchen und Daten von Websites zu sammeln, insbesondere zum Trainieren und Verbessern von künstlichen Intelligenz-Modellen. Im Gegensatz zu traditionellen Suchmaschinen-Crawlern wie Googlebot, die Inhalte für Suchergebnisse indexieren, sammeln KI-Crawler Rohdaten aus dem Web, um große Sprachmodelle (LLMs) wie ChatGPT, Claude und andere KI-Systeme zu speisen. Diese Bots sind kontinuierlich auf Millionen von Websites unterwegs, laden Seiten herunter, analysieren Inhalte und extrahieren Informationen, die KI-Plattformen dabei helfen, Sprachmuster, Faktenwissen und unterschiedliche Schreibstile zu verstehen. Zu den wichtigsten Akteuren in diesem Bereich zählen GPTBot von OpenAI, ClaudeBot von Anthropic, Meta-ExternalAgent von Meta, Amazonbot von Amazon und PerplexityBot von Perplexity.ai, die jeweils die Trainings- und Betriebsanforderungen ihrer KI-Plattformen bedienen. Das Verständnis, wie diese Crawler arbeiten, ist für Website-Betreiber und Content-Ersteller mittlerweile unerlässlich, da die Sichtbarkeit in KI-Systemen nun direkt beeinflusst, wie Ihre Marke in KI-gestützten Suchergebnissen und Empfehlungen erscheint.
Der Aufstieg der KI-Crawler
Die Landschaft des Web-Crawlings hat sich im vergangenen Jahr dramatisch verändert: Während traditionelle Such-Crawler stabile Muster aufweisen, verzeichnen KI-Crawler ein explosives Wachstum. Zwischen Mai 2024 und Mai 2025 stieg der gesamte Crawler-Traffic um 18 %, doch die Verteilung verschob sich deutlich – GPTBot legte bei den Anfragen um 305 % zu, während andere Crawler wie ClaudeBot um 46 % fielen und Bytespider sogar um 85 % zurückging. Diese Umwälzung spiegelt den wachsenden Wettbewerb unter KI-Firmen um Trainingsdaten und bessere Modelle wider. Hier ein detaillierter Überblick über die wichtigsten Crawler und ihre aktuelle Marktposition:
Crawler-Name
Unternehmen
Monatliche Anfragen
jährliches Wachstum
Hauptzweck
Googlebot
Google
4,5 Milliarden
96 %
Suchindexierung & AI Overviews
GPTBot
OpenAI
569 Millionen
305 %
ChatGPT-Training & Suche
Claude
Anthropic
370 Millionen
-46 %
Claude-Training & Suche
Bingbot
Microsoft
~450 Millionen
2 %
Suchindexierung
PerplexityBot
Perplexity.ai
24,4 Millionen
157.490 %
KI-Suchindexierung
Meta-ExternalAgent
Meta
~380 Millionen
Neueinsteiger
Meta KI-Training
Amazonbot
Amazon
~210 Millionen
-35 %
Suche & KI-Anwendungen
Die Daten zeigen, dass Googlebot mit 4,5 Milliarden monatlichen Anfragen weiterhin dominiert. KI-Crawler machen jedoch zusammen etwa 28 % des Googlebot-Volumens aus und sind damit eine bedeutende Kraft im Web-Traffic. Das explosive Wachstum von PerplexityBot (157.490 % Zuwachs) zeigt, wie schnell neue KI-Plattformen ihre Crawling-Aktivitäten ausweiten, während der Rückgang einiger etablierter KI-Crawler auf eine Marktkonsolidierung rund um die erfolgreichsten Plattformen hindeutet.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
GPTBot ist der Web-Crawler von OpenAI, der speziell zur Datensammlung für das Training und die Verbesserung von ChatGPT und anderen OpenAI-Modellen konzipiert ist. Gestartet als relativ kleiner Akteur mit nur 5 % Marktanteil im Mai 2024, ist GPTBot bis Mai 2025 zum dominierenden KI-Crawler aufgestiegen und erfasst nun 30 % des gesamten KI-Crawler-Traffics – ein bemerkenswerter Anstieg von 305 % bei den Anfragen. Dieses Wachstum spiegelt die aggressive Strategie von OpenAI wider, ChatGPT Zugang zu aktuellen, vielfältigen Webinhalten sowohl für das Modelltraining als auch für Echtzeit-Suchfunktionen über ChatGPT Search zu verschaffen. GPTBot folgt dabei einem eigenen Crawl-Muster, priorisiert HTML-Inhalte (57,70 % der Abrufe), lädt aber auch JavaScript-Dateien und Bilder herunter, ohne jedoch JavaScript auszuführen oder dynamische Inhalte zu rendern. Das Verhalten des Crawlers zeigt, dass er häufig auf 404-Fehler stößt (34,82 % der Anfragen), was darauf hindeutet, dass er möglicherweise veralteten Links folgt oder versucht, nicht mehr vorhandene Ressourcen aufzurufen. Für Website-Betreiber bedeutet die Dominanz von GPTBot, dass die Erreichbarkeit Ihrer Inhalte für diesen Crawler entscheidend für die Sichtbarkeit in den Suchfunktionen von ChatGPT und für die mögliche Aufnahme in zukünftige Modelltrainings ist.
ClaudeBot und Anthropics Ansatz
ClaudeBot, entwickelt von Anthropic, dient als Hauptcrawler zum Training und zur Aktualisierung des Claude KI-Assistenten sowie zur Unterstützung von Claudes Such- und Grounding-Funktionalitäten. Einst der zweitgrößte KI-Crawler mit 27 % Marktanteil im Mai 2024, verzeichnet ClaudeBot bis Mai 2025 einen Rückgang auf 21 % Marktanteil bei 46 % weniger Anfragen im Jahresvergleich. Dieser Rückgang muss nicht auf eine Schwäche von Anthropics Strategie hindeuten, sondern spiegelt vielmehr die Marktverschiebung zugunsten von OpenAI und das Aufkommen neuer Konkurrenten wie Meta-ExternalAgent wider. ClaudeBot verhält sich ähnlich wie GPTBot, priorisiert HTML-Inhalte, widmet jedoch einen höheren Anteil der Anfragen Bildern (35,17 % der Abrufe), was darauf hindeutet, dass Anthropic Claude gezielt im Verstehen visueller Inhalte neben Text trainiert. Wie andere KI-Crawler rendert ClaudeBot kein JavaScript und sieht daher nur das rohe HTML der Seiten ohne dynamisch geladene Inhalte. Für Content-Ersteller bleibt die Sichtbarkeit für ClaudeBot wichtig, damit Claude Ihre Inhalte auffinden und zitieren kann – besonders während Anthropic Claudes Such- und Argumentationsfähigkeiten weiterentwickelt.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Weitere wichtige KI-Crawler
Neben GPTBot und ClaudeBot sind noch weitere bedeutende KI-Crawler aktiv, die Webdaten für ihre Plattformen sammeln:
Meta-ExternalAgent (Meta): Der Meta-Crawler hat als Neueinsteiger bis Mai 2025 einen Marktanteil von 19 % erreicht. Dieser Bot sammelt Daten für Metas KI-Initiativen, darunter das Training von Meta AI und die Integration in KI-Funktionen von Instagram und Facebook. Der schnelle Aufstieg von Meta deutet auf eine ernsthafte Offensive im Bereich KI-Suche und Empfehlungen hin.
PerplexityBot (Perplexity.ai): Trotz nur 0,2 % Marktanteil verzeichnet PerplexityBot mit 157.490 % das stärkste Wachstum im Jahresvergleich. Das zeigt die rasante Skalierung von Perplexity als KI-Antwortmaschine, die auf Echtzeit-Websuche für fundierte Antworten setzt. Zugriffe von PerplexityBot bieten Websites direkte Chancen, in KI-generierten Antworten zitiert zu werden.
Amazonbot (Amazon): Amazons Crawler fiel von 21 % auf 11 % Marktanteil, mit einem Rückgang der Anfragen um 35 % im Jahresvergleich. Amazonbot sammelt Daten für Amazons Suche und KI-Anwendungen, der Rückgang könnte auf eine Strategieänderung oder Konsolidierung der Crawling-Aktivitäten hindeuten.
Applebot (Apple): Apples Crawler verzeichnete einen Rückgang um 26 % bei den Anfragen und fiel von 1,9 % auf 1,2 % Marktanteil. Applebot dient vorwiegend Siri und Spotlight Search, unterstützt aber auch Apples aufkommende KI-Initiativen. Anders als die meisten KI-Crawler kann Applebot JavaScript rendern und hat damit ähnliche Fähigkeiten wie Googlebot.
Wie KI-Crawler sich von Googlebot unterscheiden
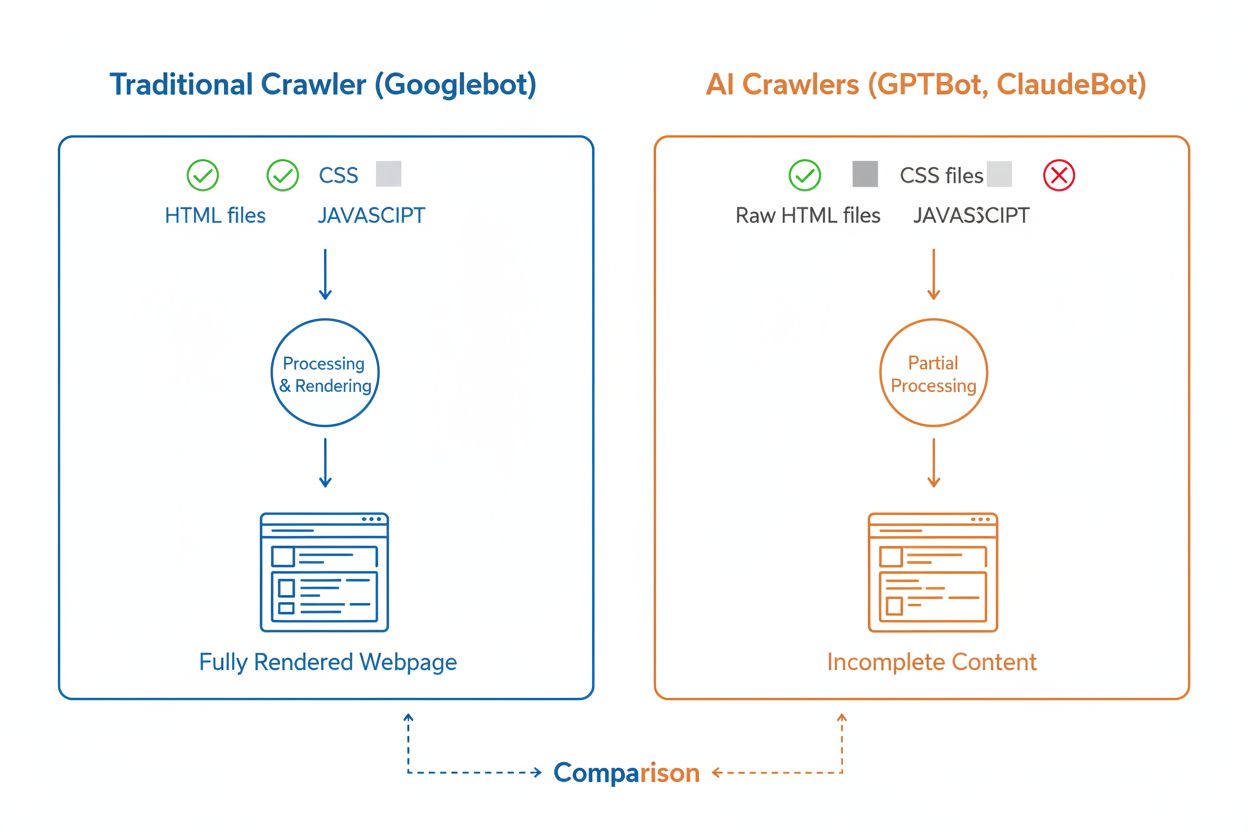
Obwohl KI-Crawler und traditionelle Suchmaschinen-Crawler wie Googlebot das Web systematisch durchsuchen, unterscheiden sich ihre technischen Fähigkeiten und Verhaltensweisen in entscheidenden Punkten, die direkt beeinflussen, wie Ihre Inhalte entdeckt und verstanden werden. Der wichtigste Unterschied ist das JavaScript-Rendering: Googlebot kann nach dem Herunterladen einer Seite JavaScript ausführen und sieht dadurch auch dynamisch geladene Inhalte, während die meisten KI-Crawler (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) lediglich das rohe HTML lesen und JavaScript-abhängige Inhalte ignorieren. Setzt Ihre Website auf clientseitiges Rendering für wichtige Informationen, sehen KI-Crawler somit nur eine unvollständige Version Ihrer Seiten. Auch die Crawl-Muster sind weniger vorhersehbar: KI-Crawler verbringen 34,82 % der Anfragen auf 404-Seiten und 14,36 % auf Weiterleitungen, während Googlebot effizienter mit 8,22 % auf 404s und 1,49 % auf Weiterleitungen arbeitet. Die Crawl-Frequenz unterscheidet sich ebenfalls: Googlebot besucht Seiten nach einem durchdachten Crawl-Budget-System, KI-Crawler hingegen scheinen häufiger, aber weniger systematisch zu crawlen – laut Studien besuchen KI-Crawler manche Seiten über 100-mal häufiger als Google in bestimmten Fällen. Diese Unterschiede machen deutlich, dass herkömmliche SEO-Strategien nicht automatisch für KI-Crawler funktionieren und ein eigener Fokus auf serverseitiges Rendering und saubere URL-Strukturen nötig ist.
Grenzen beim JavaScript-Rendering
Eine der größten technischen Herausforderungen für KI-Crawler ist ihre Unfähigkeit, JavaScript auszuführen – ein Nachteil, der aus dem hohen Rechenaufwand resultiert, der für das Rendern von JavaScript im großen Maßstab beim Training von Sprachmodellen nötig wäre. Lädt ein Crawler Ihre Webseite, erhält er nur die initiale HTML-Antwort; alles, was per JavaScript nachgeladen oder verändert wird – wie Produktdetails, Preise, Nutzerbewertungen oder dynamische Navigationselemente – bleibt für KI-Crawler unsichtbar. Das ist ein ernstes Problem für moderne Websites, die stark auf clientseitige Frameworks wie React, Vue oder Angular ohne serverseitiges Rendering (SSR) oder statische Seitengenerierung (SSG) setzen. Ein Online-Shop etwa, der Produktinformationen via JavaScript lädt, erscheint KI-Crawlern als leere Seite ohne Produktdetails, sodass KI-Systeme diese Inhalte weder verstehen noch zitieren können. Die Lösung: Alle wesentlichen Inhalte sollten in der initialen HTML-Antwort durch serverseitiges Rendering ausgeliefert werden. Damit erhalten sowohl menschliche Besucher als auch KI-Crawler ein vollständiges, inhaltsreiches Erlebnis. Websites, die moderne Frameworks wie Next.js mit SSR, statische Generatoren wie Hugo oder Gatsby oder klassische serverseitige Plattformen wie WordPress nutzen, sind von Haus aus KI-Crawler-freundlich. Wer hingegen ausschließlich auf clientseitiges Rendering setzt, hat große Sichtbarkeitsprobleme in der KI-Suche.
Crawl-Frequenz und -Muster
KI-Crawler zeigen andere Crawl-Frequenzmuster als Googlebot – mit wichtigen Auswirkungen darauf, wie schnell Ihre Inhalte von KI-Systemen erfasst werden. Untersuchungen belegen: KI-Crawler wie ChatGPT und Perplexity besuchen Seiten nach Veröffentlichung oft kurzfristig häufiger als Google – teilweise bis zu 8-mal öfter in den ersten Tagen. Dieser schnelle Erst-Crawl deutet darauf hin, dass KI-Plattformen neue Inhalte zügig entdecken und indexieren wollen, damit Modelle und Suchfunktionen immer die neuesten Informationen nutzen. Nach diesem aggressiven Erstbesuch kehren KI-Crawler jedoch meist nur dann zurück, wenn die Inhalte Qualitätsstandards erfüllen – der erste Eindruck zählt also besonders. Anders als Googlebot, der Seiten regelmäßig nach einem Crawl-Budget-System revisitiert, scheinen KI-Crawler zu bewerten, ob sich ein erneuter Besuch lohnt. Findet ein KI-Crawler bei seinem Besuch wenig Inhalt, technische Fehler oder schlechte Nutzererfahrungs-Signale, kann es sehr lange dauern, bis er zurückkehrt – oder er kommt gar nicht wieder. Für Content-Ersteller bedeutet das: Anders als bei traditionellen Suchmaschinen können Sie sich nicht auf eine zweite Chance zur Optimierung verlassen – Qualitätssicherung vor der Veröffentlichung ist essenziell.
robots.txt und Kontrolle über KI-Crawler
Website-Betreiber können die robots.txt-Datei nutzen, um ihre Präferenzen bezüglich des Zugriffs von KI-Crawlern zu kommunizieren – doch die Wirksamkeit und Durchsetzung dieser Regeln variiert je nach Crawler stark. Aktuellen Daten zufolge haben etwa 14 % der Top-10.000-Websites spezielle Allow- oder Disallow-Regeln für KI-Bots in ihrer robots.txt implementiert. GPTBotist der am häufigsten blockierte Crawler: 312 Domains (250 komplett, 62 teilweise) verbieten ihm explizit den Zugriff; gleichzeitig ist er aber auch der am häufigsten explizit erlaubte Crawler mit 61 Domains, die den Zugang eröffnen. Weitere oft geblockte Crawler sind CCBot (Common Crawl) und Google-Extended (Googles AI-Training-Token). Das Problem bei robots.txt ist, dass die Einhaltung freiwillig ist: Crawler halten sich nur an die Regeln, wenn ihre Betreiber das technisch umsetzen, und manche neue oder weniger transparente Crawler ignorieren robots.txt vollständig. Zudem entsprechen robots.txt-Tokens wie “Google-Extended” nicht direkt User-Agent-Strings im HTTP-Request, sondern kennzeichnen nur den Zweck des Crawlings – eine Überprüfung in den Server-Logs ist daher nicht immer möglich. Für eine stärkere Durchsetzung setzen Website-Betreiber zunehmend auf Firewall-Regeln und Web Application Firewalls (WAFs), die gezielt bestimmte Crawler-User-Agents blockieren und mehr Kontrolle bieten als robots.txt allein. Dieser Trend zu aktiven Blockiermechanismen spiegelt das wachsende Bewusstsein für Inhaltsrechte und das Bedürfnis nach durchsetzbaren Kontrollmöglichkeiten über KI-Crawler wider.
Monitoring der KI-Crawler-Aktivität
Das Tracking von KI-Crawler-Aktivitäten auf der eigenen Website ist entscheidend, um die eigene Sichtbarkeit in der KI-Suche zu verstehen. Dabei gibt es aber besondere Herausforderungen gegenüber dem Monitoring traditioneller Suchmaschinen-Crawler. Klassische Analysetools wie Google Analytics setzen auf JavaScript-Tracking, das von KI-Crawlern nicht ausgeführt wird – sie liefern also keinerlei Einblick in KI-Bot-Besuche. Auch pixelbasiertes Tracking funktioniert nicht, da die meisten KI-Crawler nur Text verarbeiten und Bilder ignorieren. Die einzige verlässliche Methode zur Erfassung von KI-Crawler-Aktivität ist das serverseitige Monitoring – das Auswerten von HTTP-Request-Headern und Server-Logs zur Identifizierung von Crawler-User-Agents, bevor die Seite ausgeliefert wird. Dies erfordert entweder manuelle Log-Analyse oder spezialisierte Tools, die gezielt KI-Crawler-Traffic erkennen und verfolgen. Besonders wichtig ist das Echtzeit-Monitoring, da KI-Crawler zu unvorhersehbaren Zeiten operieren und möglicherweise nicht mehr zurückkehren, wenn sie auf Probleme stoßen – ein wöchentliches oder monatliches Crawl-Audit kann daher kritische Fehler übersehen. Wenn ein KI-Crawler Ihre Seite besucht und technische Fehler oder schlechte Qualität feststellt, bekommen Sie womöglich keine zweite Chance. Mit einer 24/7-Überwachung, die Sie sofort bei Problemen wie 404-Fehlern, langsamen Ladezeiten oder fehlendem Schema-Markup alarmiert, können Sie rechtzeitig reagieren, bevor Ihre KI-Sichtbarkeit leidet. Dieses Echtzeit-Monitoring markiert einen grundlegenden Wandel gegenüber dem klassischen SEO-Monitoring und spiegelt die Geschwindigkeit und Unberechenbarkeit von KI-Crawlern wider.
Optimierung für KI-Crawler
Die Optimierung Ihrer Website für KI-Crawler verlangt einen anderen Ansatz als klassisches SEO – der Fokus liegt auf technischen Faktoren, die direkt beeinflussen, wie KI-Systeme Ihre Inhalte erfassen und verstehen können. Die oberste Priorität ist das serverseitige Rendering: Alle wichtigen Inhalte – Überschriften, Fließtext, Metadaten, strukturierte Daten – sollten in der initialen HTML-Antwort enthalten und nicht erst per JavaScript nachgeladen werden. Das gilt für Ihre Startseite, zentrale Landingpages und alle Inhalte, die von KI-Systemen zitiert oder referenziert werden sollen. Zweitens sollten Sie strukturierte Daten (Schema.org) auf Ihren wichtigsten Seiten implementieren: Article-Schema für Blogposts, Produkt-Schema für E-Commerce-Artikel, Author-Schema zur Etablierung von Expertise und Autorität. KI-Crawler nutzen strukturierte Daten, um die Inhaltsstruktur und den Kontext schnell zu verstehen, was das Auslesen und Zitieren Ihrer Informationen vereinfacht. Drittens müssen Sie auf hohe Inhaltsqualität achten, da KI-Crawler offenbar rasch entscheiden, ob Inhalte indexiert und zitiert werden. Ihre Inhalte sollten daher originell, gut recherchiert, faktisch korrekt und für Leser wirklich wertvoll sein. Viertens: Überwachen und optimieren Sie Core Web Vitals und die allgemeine Seiten-Performance, denn langsam ladende Seiten signalisieren schlechte Nutzererfahrung und können KI-Crawler abschrecken. Schließlich: Halten Sie Ihre URL-Struktur sauber und konsistent, pflegen Sie eine aktuelle XML-Sitemap und konfigurieren Sie Ihre robots.txt so, dass sie Crawler gezielt auf Ihre wichtigsten Inhalte verweist. Diese technischen Optimierungen sorgen dafür, dass Ihre Inhalte von KI-Systemen gefunden, verstanden und zitiert werden können.
Die Zukunft der KI-Crawler
Das Ökosystem der KI-Crawler wird sich weiterhin rasant entwickeln, da der Wettbewerb unter KI-Firmen zunimmt und die Technologie reift. Ein klarer Trend ist die Marktkonsolidierung auf die erfolgreichsten Plattformen – OpenAIs GPTBot hat sich als dominierende Kraft etabliert, während neue Akteure wie Meta-ExternalAgent aggressiv skalieren. Der Markt dürfte sich mittelfristig um wenige große Player stabilisieren. Mit der Reifung der KI-Crawler werden auch deren technische Fähigkeiten zunehmen: Besonders beim JavaScript-Rendering und bei effizienteren Crawl-Mustern, die weniger Anfragen für 404-Seiten und veraltete Inhalte verschwenden, sind Fortschritte zu erwarten. Die Branche bewegt sich zudem auf standardisierte Kommunikationsprotokolle zu, etwa die neue llms.txt-Spezifikation, mit der Websites ihre Inhaltsstruktur und Crawling-Präferenzen explizit an KI-Systeme kommunizieren können. Auch die Kontrollmechanismen für den KI-Crawler-Zugriff werden immer ausgefeilter: Plattformen wie Cloudflare bieten mittlerweile automatisierte KI-Bot-Blockaden als Standard, sodass Website-Betreiber feingranular über ihre Inhalte bestimmen können. Für Content-Ersteller und Website-Betreiber bedeutet das: Wer die Veränderungen aktiv beobachtet, seine technische Infrastruktur für KI-Zugänglichkeit optimiert und die Content-Strategie an die Realität der KI-getriebenen Sichtbarkeit anpasst, bleibt auf Erfolgskurs. Die Zukunft gehört denen, die das neue Crawler-Ökosystem verstehen und gezielt optimieren.
Häufig gestellte Fragen
Was ist ein KI-Crawler und wie unterscheidet er sich von einem Suchmaschinen-Crawler?
KI-Crawler sind automatisierte Programme, die Webdaten speziell sammeln, um künstliche Intelligenz-Modelle wie ChatGPT und Claude zu trainieren und zu verbessern. Im Gegensatz zu traditionellen Suchmaschinen-Crawlern wie Googlebot, die Inhalte für Suchergebnisse indexieren, sammeln KI-Crawler Rohdaten aus dem Web, um große Sprachmodelle zu speisen. Beide Crawler-Typen durchsuchen das Internet systematisch, verfolgen jedoch unterschiedliche Zwecke und verfügen über verschiedene technische Fähigkeiten.
Warum müssen KI-Crawler auf meine Website zugreifen?
KI-Crawler greifen auf Ihre Website zu, um Daten für das Training von KI-Modellen, die Verbesserung von Suchfunktionen und das Untermauern von KI-Antworten mit aktuellen Informationen zu sammeln. Wenn KI-Systeme wie ChatGPT oder Perplexity Nutzerfragen beantworten, müssen sie häufig Ihre Inhalte in Echtzeit abrufen, um genaue, zitierte Informationen bereitzustellen. Wenn Sie KI-Crawlern den Zugriff erlauben, erhöht sich die Wahrscheinlichkeit, dass Ihre Marke in KI-generierten Antworten erwähnt und zitiert wird.
Kann ich KI-Crawler daran hindern, auf meine Website zuzugreifen?
Ja, Sie können Ihre robots.txt-Datei verwenden, um bestimmten KI-Crawlern den Zugriff zu verweigern, indem Sie deren User-Agent-Namen angeben. Allerdings ist die Einhaltung von robots.txt freiwillig, und nicht alle Crawler halten sich an diese Regeln. Für eine stärkere Durchsetzung können Sie Firewall-Regeln und Web Application Firewalls (WAFs) einsetzen, um bestimmte Crawler-User-Agents aktiv zu blockieren. So erhalten Sie eine zuverlässigere Kontrolle darüber, welche KI-Crawler auf Ihre Inhalte zugreifen können.
Rendern KI-Crawler JavaScript wie Google?
Nein, die meisten KI-Crawler (GPTBot, ClaudeBot, Meta-ExternalAgent) führen kein JavaScript aus. Sie lesen nur das rohe HTML Ihrer Seiten, sodass alle Inhalte, die dynamisch über JavaScript geladen werden, für sie unsichtbar bleiben. Deshalb ist serverseitiges Rendering für die KI-Crawlerfähigkeit entscheidend. Wenn Ihre Website auf clientseitiges Rendering angewiesen ist, sehen KI-Crawler nur eine unvollständige Version Ihrer Seiten.
Wie häufig besuchen KI-Crawler Websites?
KI-Crawler besuchen Websites nach der Veröffentlichung von Inhalten kurzfristig häufiger als traditionelle Suchmaschinen. Untersuchungen zeigen, dass sie Seiten in den ersten Tagen 8- bis 100-mal häufiger besuchen als Google. Wenn die Inhalte jedoch nicht den Qualitätsstandards entsprechen, kehren sie möglicherweise nicht zurück. Der erste Eindruck ist also entscheidend – Sie erhalten unter Umständen keine zweite Chance, Ihre Inhalte für KI-Crawler zu optimieren.
Wie optimiere ich meine Website am besten für KI-Crawler?
Die wichtigsten Optimierungen sind: (1) Serverseitiges Rendering, damit relevante Inhalte im anfänglichen HTML stehen, (2) strukturierte Daten (Schema) hinzufügen, damit KI Ihre Inhalte versteht, (3) hohe Qualität und Aktualität der Inhalte wahren, (4) Core Web Vitals für eine gute Nutzererfahrung überwachen, und (5) eine saubere URL-Struktur und eine aktuelle Sitemap pflegen. Diese technischen Optimierungen schaffen die Grundlage dafür, dass Ihre Inhalte von KI-Systemen gefunden und zitiert werden können.
Welcher KI-Crawler ist für meine Website am wichtigsten?
GPTBot von OpenAI ist derzeit der dominierende KI-Crawler und macht 30 % des gesamten KI-Crawler-Traffics aus, mit einem jährlichen Wachstum von 305 %. Sie sollten jedoch für alle wichtigen Crawler wie ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) und andere optimieren. Verschiedene KI-Plattformen haben verschiedene Nutzergruppen – Sichtbarkeit bei mehreren Crawlern maximiert die Präsenz Ihrer Marke in der KI-Suche.
Wie kann ich die Aktivität von KI-Crawlern auf meiner Website verfolgen?
Traditionelle Analysetools wie Google Analytics erfassen keine KI-Crawler-Aktivität, da sie auf JavaScript-Tracking basieren. Stattdessen benötigen Sie serverseitiges Monitoring, das HTTP-Request-Header und Server-Logs analysiert, um Crawler-User-Agents zu identifizieren. Spezialisierte Tools für die KI-Crawler-Erkennung bieten Ihnen Echtzeit-Einblicke darüber, welche Seiten gecrawlt werden, wie oft und ob Crawler auf technische Probleme stoßen.
Überwachen Sie die Sichtbarkeit Ihrer Marke in der KI-Suche
Verfolgen Sie, wie KI-Crawler wie GPTBot und ClaudeBot auf Ihre Inhalte zugreifen und diese zitieren. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Sichtbarkeit mit AmICited.
So erlaubst du KI-Bots das Crawlen deiner Website: Umfassender robots.txt- & llms.txt-Leitfaden
Erfahre, wie du KI-Bots wie GPTBot, PerplexityBot und ClaudeBot das Crawlen deiner Website erlaubst. Konfiguriere robots.txt, richte llms.txt ein und optimiere ...
So erkennen Sie KI-Crawler in Server-Logs: Vollständiger Leitfaden zur Erkennung
Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
Sollten Sie KI-Crawler blockieren oder zulassen? Entscheidungsrahmen
Erfahren Sie, wie Sie strategische Entscheidungen zum Blockieren von KI-Crawlern treffen. Bewerten Sie Inhaltstyp, Traffic-Quellen, Geschäftsmodelle und Wettbew...
10 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.