Lernen Sie, KI-Crawler wie GPTBot, ClaudeBot und PerplexityBot in Ihren Server-Logs zu erkennen und zu überwachen. Umfassender Leitfaden mit User-Agent-Strings, IP-Verifizierung und praktischen Monitoring-Strategien.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Die Struktur des Web-Traffics hat sich mit dem Aufkommen der KI-Datensammlung grundlegend verändert und geht weit über die herkömmliche Suchmaschinen-Indexierung hinaus. Während Googlebot oder der Bing-Crawler seit Jahrzehnten bekannt sind, stellen KI-Crawler heute einen bedeutenden und rasant wachsenden Anteil am Server-Traffic dar – einige Plattformen verzeichnen jährliche Wachstumsraten von über 2.800 %. Das Verständnis der KI-Crawler-Aktivität ist für Website-Betreiber entscheidend, weil sie die Bandbreitenkosten, Server-Performance, Datenverbrauchsmetriken und vor allem Ihre Kontrolle darüber beeinflusst, wie Ihre Inhalte zum Training von KI-Modellen genutzt werden. Ohne angemessenes Monitoring tappen Sie im Dunkeln gegenüber einem grundlegenden Wandel darin, wie Ihre Daten abgerufen und verwendet werden.
Verständnis von KI-Crawler-Typen & User-Agent-Strings
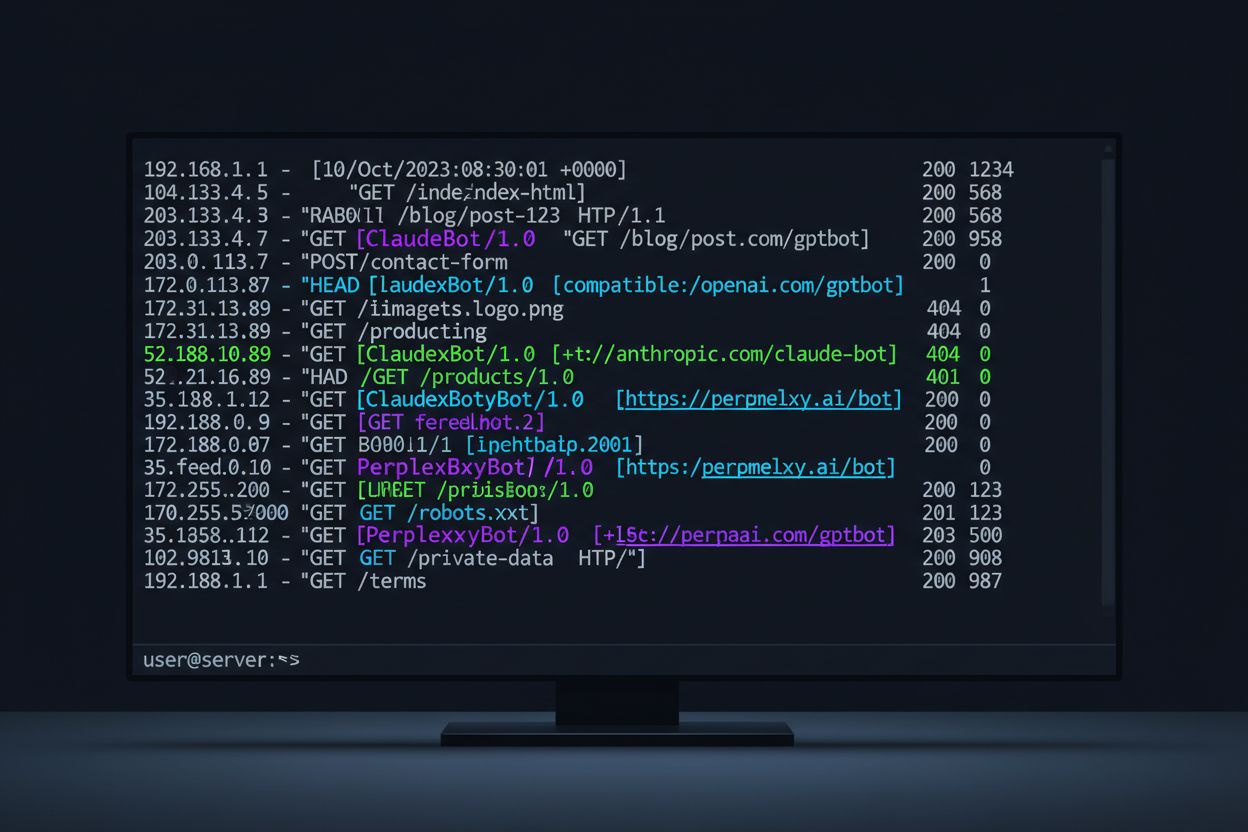
KI-Crawler treten in vielen Formen auf – mit unterschiedlichen Zielen und durch ihre User-Agent-Strings eindeutig identifizierbar. Diese Strings sind die digitalen Fingerabdrücke, die Crawler in Ihren Server-Logs hinterlassen und mit deren Hilfe Sie exakt feststellen können, welche KI-Systeme auf Ihre Inhalte zugreifen. Nachfolgend eine umfassende Referenztabelle der derzeit wichtigsten KI-Crawler im Web:
Für die Analyse Ihrer Server-Logs auf KI-Crawler-Aktivität ist ein systematisches Vorgehen und Verständnis des Log-Formats Ihres Webservers nötig. Die meisten Websites verwenden Apache oder Nginx – die Strukturen unterscheiden sich leicht, aber beide ermöglichen die Identifikation von Crawler-Traffic. Entscheidend ist, zu wissen, wo man suchen und auf welche Muster man achten muss. Hier ein Beispiel für einen Apache-Access-Log-Eintrag:
Dieser Befehl extrahiert den User-Agent-String, filtert bot-ähnliche Einträge und zählt die Vorkommen – so erhalten Sie einen klaren Überblick, welche Crawler Ihre Seite am häufigsten besuchen.
IP-Verifizierung & Authentifizierung
User-Agent-Strings können gefälscht werden, sodass ein Angreifer vorgeben kann, GPTBot zu sein, tatsächlich aber etwas ganz anderes ist. Deshalb ist die IP-Verifizierung unerlässlich, um zu bestätigen, dass Traffic, der angeblich von legitimen KI-Unternehmen stammt, auch tatsächlich von deren Infrastruktur ausgeht. Sie können einen Reverse-DNS-Lookup auf die IP-Adresse ausführen, um den Besitzer zu prüfen:
nslookup 192.0.2.1
Löst der Reverse DNS auf eine Domain eines legitimen KI-Unternehmens wie OpenAI oder Anthropic auf, ist der Traffic vermutlich echt. Die wichtigsten Verifizierungsmethoden sind:
Reverse DNS Lookup: Prüfen, ob das Reverse DNS der IP zur Unternehmensdomain passt
IP-Bereichsprüfung: Abgleich mit den veröffentlichten IP-Bereichen von OpenAI, Anthropic oder anderen KI-Unternehmen
WHOIS-Abfrage: Prüfen, ob der IP-Block der angegebenen Organisation gehört
Historische Analyse: Nachverfolgen, ob die IP durchgehend mit demselben User-Agent auf die Website zugreift
Verhaltensmuster: Legitime Crawler zeigen vorhersehbare Muster; gefälschte Bots verhalten sich oft erratisch
Die IP-Verifizierung ist wichtig, da Sie so nicht auf gefälschte Crawler hereinfallen, die etwa als Konkurrenz Inhalte absaugen oder als böswillige Akteure Ihre Server überlasten, während sie sich als legitime KI-Dienste tarnen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
KI-Crawler in Analysetools erkennen
Traditionelle Analyseplattformen wie Google Analytics 4 und Matomo filtern Bot-Traffic standardmäßig aus, wodurch Aktivitäten von KI-Crawlern in Ihren Dashboards weitgehend unsichtbar bleiben. Diese Blindstelle verhindert, dass Sie erkennen, wie viel Traffic und Bandbreite KI-Systeme tatsächlich verbrauchen. Um KI-Crawler-Aktivität wirklich zu überwachen, benötigen Sie serverseitige Lösungen, die Rohdaten aus Logs erfassen, bevor sie gefiltert werden:
ELK Stack (Elasticsearch, Logstash, Kibana): Zentralisierte Logaggregation und Visualisierung
Splunk: Unternehmensweite Log-Analyse mit Echtzeit-Alarmierung
Datadog: Cloud-native Überwachung mit Bot-Erkennung
Grafana + Prometheus: Open-Source-Monitoring-Stack für individuelle Dashboards
Sie können KI-Crawler-Daten auch über das Measurement Protocol für GA4 in Google Data Studio integrieren, um benutzerdefinierte Berichte zu erstellen, die KI-Traffic neben Ihren regulären Analytics anzeigen. Damit erhalten Sie ein vollständiges Bild über alle Zugriffe auf Ihre Website – nicht nur von menschlichen Besuchern.
Praktischer Workflow zur Log-Analyse
Für ein effektives Monitoring der KI-Crawler-Aktivität müssen zunächst Basiswerte erhoben und regelmäßig geprüft werden. Sammeln Sie eine Woche lang Grundlagendaten, um die normalen Crawler-Traffic-Muster zu verstehen, und richten Sie dann ein automatisiertes Monitoring zur Erkennung von Anomalien ein. Die tägliche Monitoring-Checkliste:
Gesamte Crawler-Anfragen prüfen und mit dem Basiswert vergleichen
Neue, bisher unbekannte Crawler identifizieren
Ungewöhnliche Crawl-Raten oder Muster prüfen
IP-Adressen der Top-Crawler verifizieren
Bandbreitenverbrauch durch Crawler überwachen
Alarmierung bei Überschreitung von Rate-Limits
Nutzen Sie dieses Bash-Skript zur täglichen Automatisierung der Analyse:
Lassen Sie dieses Skript per Cronjob täglich laufen:
09 * * * /usr/local/bin/crawler_analysis.sh
Für die Dashbord-Visualisierung nutzen Sie Grafana und erstellen Panels, die Crawler-Traffic-Trends im Zeitverlauf darstellen – mit separaten Visualisierungen je Haupt-Crawler und Alarmierung bei Anomalien.
Zugriff von KI-Crawlern kontrollieren
Die Kontrolle des KI-Crawler-Zugriffs beginnt mit der Analyse Ihrer Optionen und des gewünschten Kontrollniveaus. Manche Seitenbetreiber wollen alle KI-Crawler zum Schutz von Inhalten blockieren, andere wünschen den Traffic, möchten ihn aber steuern. Die erste Verteidigungslinie ist die robots.txt, mit der Sie Crawlern Anweisungen geben, welche Bereiche sie betreten dürfen. Beispiel:
Allerdings hat robots.txt erhebliche Einschränkungen: Sie ist nur eine Empfehlung, die Crawler ignorieren können, und böswillige Akteure berücksichtigen sie ohnehin nicht. Für robustere Kontrolle setzen Sie Firewall-basiertes Blocking auf Serverebene ein – beispielsweise mit iptables oder den Sicherheitsgruppen Ihres Cloud-Providers. Sie können bestimmte IP-Bereiche oder User-Agent-Strings auf Webserver-Ebene (Apache mod_rewrite, Nginx if-Statements) blockieren. Kombinieren Sie in der Praxis robots.txt für legitime Crawler mit Firewall-Regeln gegen solche, die sich nicht daran halten, und überwachen Sie Ihre Logs, um Verstöße zu erkennen.
Fortgeschrittene Erkennungstechniken
Fortgeschrittene Erkennungstechniken gehen über einfaches User-Agent-Matching hinaus, um auch raffinierte Crawler und gefälschten Traffic zu identifizieren. RFC 9421 HTTP Message Signatures bieten einen kryptographischen Nachweis: Crawler signieren ihre Anfragen mit privaten Schlüsseln und machen so Spoofing nahezu unmöglich. Einige KI-Unternehmen beginnen, Signature-Agent-Header zu implementieren, die einen Identitätsnachweis enthalten. Darüber hinaus können Sie Verhaltensmuster analysieren: Legitime Crawler führen JavaScript zuverlässig aus, halten konstante Crawl-Geschwindigkeiten, respektieren Rate-Limits und nutzen konsistente IPs. Rate-Limit-Analysen zeigen Auffälligkeiten – ein Crawler, der plötzlich 500 % mehr Anfragen schickt oder Seiten in zufälliger Reihenfolge abruft statt der Seitenstruktur zu folgen, ist vermutlich böswillig. Da agentische KI-Browser immer ausgereifter werden, zeigen sie zunehmend menschliches Verhalten wie JavaScript-Ausführung, Cookie-Handling oder Referrer-Muster. Daher sind künftig umfassendere Erkennungsmethoden nötig, die die gesamte Anfrage-Signatur und nicht nur User-Agent-Strings prüfen.
Monitoring-Strategie für den Echtbetrieb
Eine umfassende Monitoring-Strategie für Produktionsumgebungen erfordert Basiswerterhebung, Anomalieerkennung und detaillierte Protokollierung. Sammeln Sie zunächst zwei Wochen Basisdaten, um Ihre normalen Crawler-Traffic-Muster, Stoßzeiten, typische Anfrageraten pro Crawler und Bandbreitenverbrauch zu verstehen. Richten Sie eine Anomalieerkennung ein, die Sie alarmiert, wenn ein Crawler 150 % seiner Basisrate überschreitet oder neue Crawler auftauchen. Definieren Sie Alarm-Schwellen, zum Beispiel sofortige Benachrichtigung, wenn ein einzelner Crawler mehr als 30 % der Bandbreite verbraucht oder wenn der gesamte Crawler-Traffic 50 % des Gesamtaufkommens übersteigt. Messen Sie Berichts-Kennzahlen wie Gesamtanzahl der Crawler-Anfragen, verbrauchte Bandbreite, erkannte eindeutige Crawler und geblockte Anfragen. Für Unternehmen, denen die Nutzung ihrer Daten zum KI-Training wichtig ist, bietet AmICited.com ergänzendes KI-Zitattracking: Sie sehen, welche KI-Modelle Ihre Inhalte zitieren und behalten so die Kontrolle über die Verwendung Ihrer Daten. Implementieren Sie diese Strategie mit Server-Logs, Firewall-Regeln und Analysetools, um die vollständige Sichtbarkeit und Kontrolle über KI-Crawler-Aktivitäten zu behalten.
Häufig gestellte Fragen
Was ist der Unterschied zwischen KI-Crawlern und Suchmaschinen-Crawlern?
Suchmaschinen-Crawler wie der Googlebot indexieren Inhalte für Suchergebnisse, während KI-Crawler Daten sammeln, um große Sprachmodelle zu trainieren oder KI-Antwort-Engines zu betreiben. KI-Crawler crawlen oft aggressiver und greifen möglicherweise auf Inhalte zu, die Suchmaschinen nicht erfassen. Sie stellen daher eigenständige Traffic-Quellen dar, die eine separate Überwachung und Managementstrategien erfordern.
Können KI-Crawler ihre User-Agent-Strings fälschen?
Ja, User-Agent-Strings lassen sich leicht fälschen, da sie lediglich Text-Header in HTTP-Anfragen sind. Deshalb ist die IP-Verifizierung entscheidend – legitime KI-Crawler stammen aus bestimmten IP-Bereichen, die ihren Unternehmen gehören. Die IP-basierte Verifizierung ist daher deutlich verlässlicher als der User-Agent-Abgleich allein.
Wie blockiere ich bestimmte KI-Crawler auf meiner Website?
Sie können robots.txt verwenden, um das Crawling zu untersagen (Crawler können diese aber ignorieren), oder eine serverseitige Firewall einsetzen – etwa mittels iptables, Apache mod_rewrite oder Nginx-Regeln. Für maximale Kontrolle kombinieren Sie robots.txt für legitime Crawler mit IP-basierten Firewall-Regeln für diejenigen, die robots.txt nicht beachten.
Google Analytics 4, Matomo und ähnliche Plattformen sind darauf ausgelegt, Bot-Traffic herauszufiltern, sodass KI-Crawler im Standard-Dashboard unsichtbar bleiben. Sie benötigen serverseitige Lösungen wie ELK Stack, Splunk oder Datadog, um Rohdaten aus Logs zu erfassen und die gesamte Crawler-Aktivität zu sehen.
Welchen Einfluss haben KI-Crawler auf die Server-Bandbreite?
KI-Crawler können beträchtliche Bandbreite verbrauchen – manche Seiten berichten, dass 30-50 % des Gesamt-Traffics von Crawlern stammen. ChatGPT-User crawlt allein mit 2.400 Seiten/Stunde und wenn mehrere KI-Crawler gleichzeitig aktiv sind, steigen die Bandbreitenkosten ohne Monitoring und Kontrolle erheblich.
Wie oft sollte ich meine Server-Logs auf KI-Aktivität überwachen?
Richten Sie eine automatisierte tägliche Überwachung ein, indem Sie Cronjobs nutzen, um Logs zu analysieren und Berichte zu erstellen. Für kritische Anwendungen implementieren Sie ein Echtzeit-Alerting, das Sie sofort benachrichtigt, wenn ein Crawler die Basisrate um 150 % überschreitet oder mehr als 30 % der Bandbreite verbraucht.
Reicht die IP-Verifizierung zur Authentifizierung von KI-Crawlern aus?
Die IP-Verifizierung ist deutlich verlässlicher als der User-Agent-Abgleich, aber nicht absolut sicher – eine IP-Spoofing ist technisch möglich. Für maximale Sicherheit kombinieren Sie IP-Verifizierung mit RFC 9421 HTTP Message Signatures, die einen kryptographischen Identitätsnachweis liefern, der nahezu unmöglich zu fälschen ist.
Was soll ich tun, wenn ich verdächtige Crawler-Aktivität entdecke?
Überprüfen Sie zunächst die IP-Adresse mit den offiziellen Bereichen des angeblichen Unternehmens. Bei keinem Treffer blockieren Sie die IP auf Firewall-Ebene. Wenn sie übereinstimmt, das Verhalten aber ungewöhnlich ist, setzen Sie ein Rate-Limit oder blockieren den Crawler vorübergehend, während Sie nachforschen. Führen Sie stets detaillierte Logs für Analysen und spätere Rückfragen.
Verfolgen Sie, wie KI-Systeme auf Ihre Inhalte verweisen
AmICited überwacht, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews Ihre Marke und Inhalte zitieren. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Sichtbarkeit und schützen Sie Ihre Content-Rechte.
Erfahren Sie, wie Sie die Aktivitäten von KI-Crawlern auf Ihrer Website mithilfe von Serverprotokollen, Tools und Best Practices verfolgen und überwachen. Ident...
So erkennen Sie KI-Crawler in Server-Logs: Vollständiger Leitfaden zur Erkennung
Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
Der vollständige Leitfaden zum Blockieren (oder Zulassen) von KI-Crawlern
Erfahren Sie, wie Sie KI-Crawler wie GPTBot und ClaudeBot mit robots.txt, serverseitiger Blockierung und erweiterten Schutzmethoden blockieren oder zulassen. Vo...
6 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.