NoAI-Meta-Tags: Steuerung des KI-Zugriffs über Header
Erfahren Sie, wie Sie noai- und noimageai-Meta-Tags implementieren, um den KI-Crawler-Zugriff auf Ihre Website-Inhalte zu steuern. Umfassender Leitfaden zu KI-Zugriffskontroll-Headern und Implementierungsmethoden.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Webcrawler sind automatisierte Programme, die systematisch das Internet durchsuchen und Informationen von Websites sammeln. Historisch wurden diese Bots hauptsächlich von Suchmaschinen wie Google betrieben, deren Googlebot Seiten crawlt, Inhalte indexiert und Nutzer über Suchergebnisse zurück zu den Websites führt – was eine wechselseitig vorteilhafte Beziehung darstellte. Das Aufkommen von KI-Crawlern hat dieses Gleichgewicht jedoch grundlegend verändert. Anders als klassische Suchmaschinen-Bots, die im Austausch für Inhaltszugriff Besucher zurückführen, konsumieren KI-Trainingscrawler große Mengen an Webinhalten, um Datensätze für große Sprachmodelle zu erstellen – oft mit minimalem oder gar keinem Traffic-Rückfluss für Publisher. Dieser Wandel macht Meta-Tags – kleine HTML-Direktiven, die Crawlern Anweisungen geben – für Content-Ersteller immer wichtiger, die Kontrolle darüber behalten möchten, wie ihre Werke von künstlicher Intelligenz genutzt werden.
Was sind NoAI- und NoImageAI-Meta-Tags?
Die noai- und noimageai-Meta-Tags sind Direktiven, die 2022 von DeviantArt entwickelt wurden, um Content-Ersteller dabei zu unterstützen, ihre Werke vor der Verwendung zum Training von KI-Bildgeneratoren zu schützen. Diese Tags funktionieren ähnlich wie die etablierte noindex-Direktive, die Suchmaschinen anweist, eine Seite nicht zu indexieren. Die noai-Direktive signalisiert, dass keine Inhalte der Seite für KI-Training verwendet werden dürfen, während noimageai speziell Bilder vor KI-Training schützt. Sie können diese Tags im Head-Bereich Ihrer HTML mit folgendem Syntax implementieren:
<!-- Alle Inhalte vom KI-Training ausschließen --><metaname="robots"content="noai">
<!-- Nur Bilder vom KI-Training ausschließen --><metaname="robots"content="noimageai">
<!-- Sowohl Inhalte als auch Bilder ausschließen --><metaname="robots"content="noai, noimageai">
Hier ein Vergleich verschiedener Meta-Tag-Direktiven und ihrer Einsatzzwecke:
Direktive
Zweck
Syntax
Geltungsbereich
noai
Verhindert KI-Training aller Inhalte
content="noai"
Gesamter Seiteninhalt
noimageai
Verhindert KI-Training von Bildern
content="noimageai"
Nur Bilder
noindex
Verhindert Suchmaschinenindexierung
content="noindex"
Suchergebnisse
nofollow
Verhindert das Folgen von Links
content="nofollow"
Ausgehende Links
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Der Unterschied zwischen Meta-Tags und HTTP-Headern
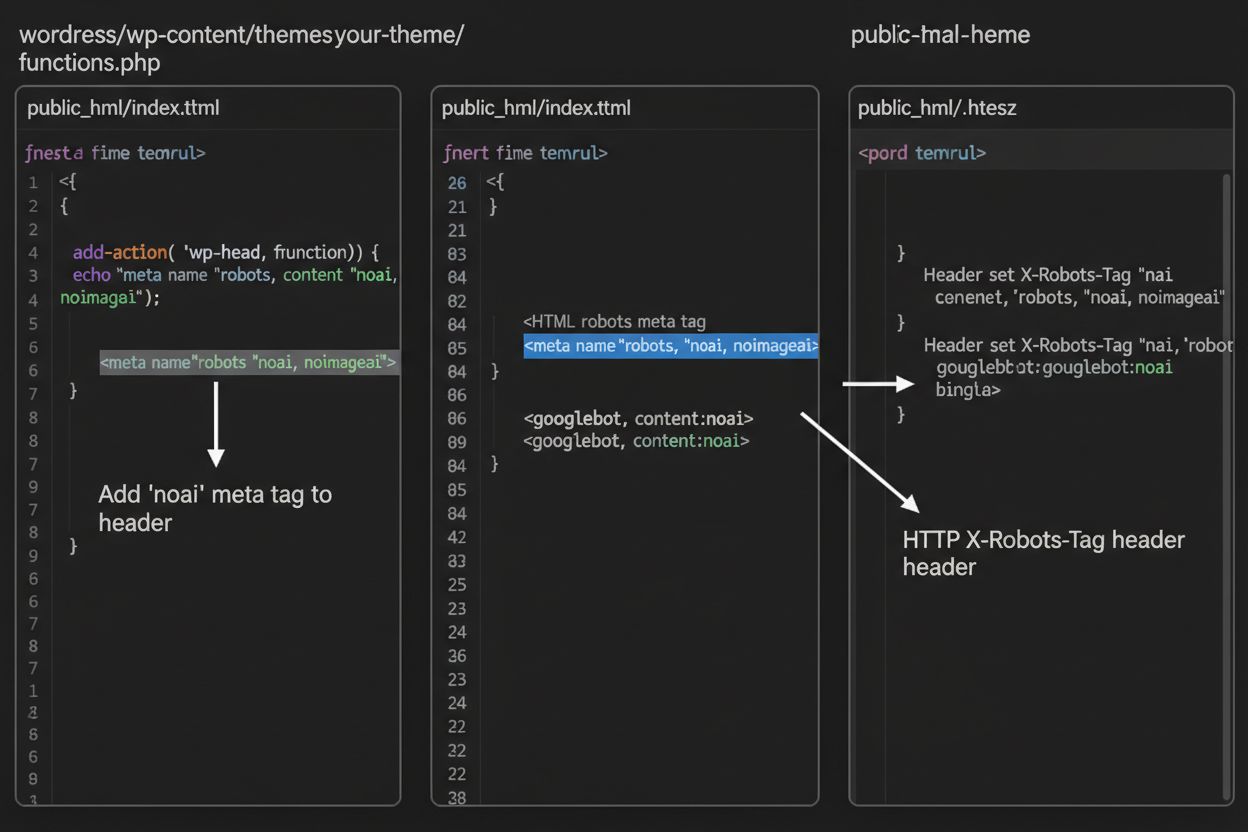
Während Meta-Tags direkt im HTML platziert werden, bieten HTTP-Header eine alternative Methode, um Crawler-Direktiven auf Serverebene zu kommunizieren. Der X-Robots-Tag-Header kann die gleichen Direktiven wie Meta-Tags beinhalten, funktioniert aber anders – er wird in der HTTP-Antwort gesendet, bevor der Seiteninhalt ausgeliefert wird. Dieser Ansatz ist besonders wertvoll, um den Zugriff auf Nicht-HTML-Dateien wie PDFs, Bilder und Videos zu steuern, bei denen keine HTML-Meta-Tags eingebettet werden können.
Für Apache-Server können Sie X-Robots-Tag-Header in Ihrer .htaccess-Datei setzen:
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
Für NGINX-Server fügen Sie den Header in Ihrer Serverkonfiguration hinzu:
Header bieten globalen Schutz für Ihre gesamte Website oder spezifische Verzeichnisse und sind daher ideal für umfassende KI-Zugriffskontrollstrategien.
Wie KI-Crawler diese Direktiven respektieren (oder ignorieren)
Die Wirksamkeit von noai- und noimageai-Tags hängt vollständig davon ab, ob Crawler sie befolgen. Gut programmierte Crawler großer KI-Unternehmen respektieren diese Direktiven in der Regel:
Kleinere/unbekannte Crawler – respektieren die Direktiven möglicherweise nicht
Allerdings können schlecht programmierte Bots und bösartige Crawler diese Direktiven absichtlich ignorieren, weil es keinen Durchsetzungsmechanismus gibt. Anders als robots.txt, das als Branchenstandard von Suchmaschinen respektiert wird, ist noai kein offizieller Webstandard, sodass Crawler nicht verpflichtet sind, sich daran zu halten. Daher empfehlen Sicherheitsexperten einen mehrschichtigen Ansatz, der mehrere Schutzmethoden kombiniert, anstatt sich ausschließlich auf Meta-Tags zu verlassen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Implementierungsmethoden auf verschiedenen Plattformen
Die Implementierung von noai- und noimageai-Tags variiert je nach Website-Plattform. Hier finden Sie Schritt-für-Schritt-Anleitungen für die gängigsten Plattformen:
1. WordPress (über functions.php)
Fügen Sie diesen Code in die functions.php Ihres Child-Themes ein:
3. Squarespace
Navigieren Sie zu Einstellungen > Erweitert > Code-Injektion und fügen Sie es im Header-Bereich hinzu:
<metaname="robots"content="noai, noimageai">
4. Wix
Gehen Sie zu Einstellungen > Benutzerdefinierter Code, klicken Sie auf “Benutzerdefinierten Code hinzufügen”, fügen Sie das Meta-Tag ein, wählen Sie “Head” und wenden Sie es auf alle Seiten an.
Jede Plattform bietet unterschiedliche Steuerungsmöglichkeiten – WordPress erlaubt eine seitenbezogene Implementierung per Plugin, während Squarespace und Wix globale, seitenweite Optionen bieten. Wählen Sie die Methode, die am besten zu Ihren technischen Kenntnissen und Bedürfnissen passt.
Einschränkungen und Wirksamkeit von NoAI-Tags
Obwohl noai- und noimageai-Tags einen wichtigen Schritt zum Schutz von Content-Erstellern darstellen, gibt es bedeutende Einschränkungen. Erstens sind diese keine offiziellen Webstandards – DeviantArt hat sie als Community-Initiative eingeführt, es gibt also keine formale Spezifikation oder Durchsetzung. Zweitens ist die Einhaltung rein freiwillig. Gutartige Crawler großer Unternehmen respektieren die Direktiven, schlecht programmierte Bots und Scraper können sie aber ohne Konsequenzen ignorieren. Drittens bedeutet fehlende Standardisierung eine unterschiedliche Verbreitung. Einige kleinere KI-Unternehmen und Forschungseinrichtungen kennen diese Direktiven womöglich gar nicht, geschweige denn, dass sie sie unterstützen. Schließlich können Meta-Tags allein entschlossene Angreifer nicht aufhalten – ein bösartiger Crawler kann Ihre Vorgaben komplett ignorieren, weshalb zusätzliche Schutzschichten für umfassende Content-Sicherheit unerlässlich sind.
Kombination von Meta-Tags mit robots.txt und anderen Methoden
Die effektivste Strategie zur KI-Zugriffskontrolle nutzt mehrere Schutzebenen anstatt nur auf eine Methode zu setzen. Hier ein Vergleich verschiedener Ansätze:
Methode
Geltungsbereich
Wirksamkeit
Schwierigkeit
Meta-Tags (noai)
Seitenspezifisch
Mittel (freiwillige Einhaltung)
Einfach
robots.txt
Website-weit
Mittel (nur beratend)
Einfach
X-Robots-Tag-Header
Server-Ebene
Mittel-Hoch (alle Dateitypen)
Mittel
Firewall-Regeln
Netzwerk-Ebene
Hoch (blockiert auf Infrastrukturebene)
Schwer
IP-Whitelisting
Netzwerk-Ebene
Sehr hoch (nur verifizierte Quellen)
Schwer
Eine umfassende Strategie könnte beinhalten: (1) noai-Meta-Tags auf allen Seiten, (2) robots.txt-Regeln, die bekannte KI-Trainingscrawler blockieren, (3) X-Robots-Tag-Header auf Serverebene für Nicht-HTML-Dateien und (4) Überwachung der Server-Logs, um Crawler zu identifizieren, die Ihre Vorgaben ignorieren. Dieser mehrschichtige Ansatz erschwert es Angreifern deutlich, während er mit gutartigen Crawlern kompatibel bleibt, die Ihre Präferenzen respektieren.
Überwachung und Überprüfung der Crawler-Compliance
Nach der Implementierung von noai-Tags und anderen Direktiven sollten Sie prüfen, ob Crawler Ihre Regeln tatsächlich befolgen. Die direkteste Methode ist das Überprüfen Ihrer Server-Access-Logs auf Crawler-Aktivitäten. Auf Apache-Servern können Sie gezielt nach bestimmten Crawlern suchen:
Wenn Sie Anfragen von Crawlern sehen, die Sie blockiert haben, ignorieren sie Ihre Direktiven. Für NGINX-Server überprüfen Sie /var/log/nginx/access.log mit demselben grep-Befehl. Darüber hinaus bieten Tools wie Cloudflare Radar Einblicke in KI-Crawler-Traffic-Muster auf Ihrer Seite, zeigen die aktivsten Bots und wie sich deren Verhalten im Zeitverlauf ändert. Eine regelmäßige Log-Überwachung – mindestens monatlich – hilft Ihnen, neue Crawler zu identifizieren und zu überprüfen, ob Ihre Schutzmaßnahmen wie vorgesehen wirken.
Die Zukunft von Standards zur KI-Zugriffskontrolle
Derzeit existieren noai und noimageai in einer Grauzone: Sie werden von großen KI-Unternehmen weithin anerkannt und respektiert, sind aber weiterhin inoffiziell und nicht standardisiert. Allerdings gibt es einen zunehmenden Trend zur formellen Standardisierung. Das W3C (World Wide Web Consortium) und verschiedene Branchenverbände diskutieren, wie offizielle Standards zur KI-Zugriffskontrolle geschaffen werden können, die diesen Direktiven dasselbe Gewicht verleihen wie etablierten Standards wie robots.txt. Sollte noai ein offizieller Webstandard werden, wäre die Einhaltung Branchenerwartung statt freiwillig, was die Wirksamkeit deutlich erhöht. Diese Standardisierungsbestrebungen spiegeln einen breiteren Wandel im Umgang der Tech-Branche mit Rechten von Content-Erstellern und dem Gleichgewicht zwischen KI-Entwicklung und Publisher-Schutz wider. Je mehr Publisher diese Tags nutzen und stärker Schutz fordern, desto wahrscheinlicher wird eine offizielle Standardisierung – wodurch die KI-Zugriffskontrolle ähnlich grundlegend für die Web-Governance werden könnte wie die Regeln zur Suchmaschinenindexierung.
Häufig gestellte Fragen
Was ist das noai-Meta-Tag und wie funktioniert es?
Das noai-Meta-Tag ist eine Anweisung, die im Head-Bereich Ihrer Website-HTML platziert wird und KI-Crawlern signalisiert, dass Ihre Inhalte nicht zum Training von künstlichen Intelligenzmodellen verwendet werden sollen. Es kommuniziert Ihren Wunsch an gutartige KI-Bots, ist jedoch kein offizieller Webstandard und manche Crawler ignorieren es möglicherweise.
Ist noai ein offizieller Webstandard?
Nein, noai und noimageai sind keine offiziellen Webstandards. Sie wurden von DeviantArt als Community-Initiative ins Leben gerufen, um Content-Ersteller beim Schutz ihrer Werke vor KI-Training zu unterstützen. Allerdings haben große KI-Unternehmen wie OpenAI, Anthropic und andere begonnen, diese Direktiven in ihren Crawlern zu respektieren.
Welche KI-Crawler respektieren das noai-Meta-Tag?
Große KI-Crawler wie GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) und andere respektieren die noai-Direktive. Einige kleinere oder schlecht programmierte Crawler ignorieren sie jedoch, weshalb ein mehrschichtiger Schutz empfohlen wird.
Was ist der Unterschied zwischen Meta-Tags und HTTP-Headern zur KI-Steuerung?
Meta-Tags werden im Head-Bereich Ihres HTML platziert und gelten für einzelne Seiten, während HTTP-Header (X-Robots-Tag) auf Serverebene gesetzt werden und global oder für bestimmte Dateitypen gelten können. Header funktionieren auch für Nicht-HTML-Dateien wie PDFs und Bilder und bieten daher einen vielseitigeren Schutz.
Kann ich noai-Tags in WordPress implementieren?
Ja, Sie können noai-Tags in WordPress auf verschiedene Arten implementieren: durch Hinzufügen von Code in die functions.php-Datei Ihres Themes, mit Plugins wie WPCode oder über Page-Builder-Tools wie Divi und Elementor. Die Methode über functions.php ist am gebräuchlichsten und beinhaltet das Hinzufügen eines einfachen Hooks, um das Meta-Tag in den Header Ihrer Seite zu injizieren.
Sollte ich alle KI-Crawler oder nur Trainingscrawler blockieren?
Das hängt von Ihren Geschäftszielen ab. Das Blockieren von Trainings-Crawlern schützt Ihre Inhalte vor der Verwendung im KI-Modelltraining. Das Blockieren von Such-Crawlern wie OAI-SearchBot kann jedoch Ihre Sichtbarkeit in KI-basierten Suchergebnissen und Discovery-Plattformen verringern. Viele Publisher verfolgen einen selektiven Ansatz, der Trainings-Crawler blockiert, Such-Crawler aber zulässt.
Wie kann ich überprüfen, ob KI-Crawler meine noai-Direktiven respektieren?
Sie können Ihre Server-Logs auf Crawler-Aktivitäten überprüfen, indem Sie mit Befehlen wie grep nach bestimmten Bot-User-Agents suchen. Tools wie Cloudflare Radar bieten Einblicke in KI-Crawler-Traffic-Muster. Überwachen Sie Ihre Logs regelmäßig, um zu sehen, ob geblockte Crawler weiterhin auf Ihre Inhalte zugreifen, was darauf hindeutet, dass sie Ihre Direktiven ignorieren.
Was soll ich tun, wenn Crawler meine noai-Meta-Tags ignorieren?
Wenn Crawler Ihre Meta-Tags ignorieren, implementieren Sie zusätzliche Schutzmaßnahmen wie robots.txt-Regeln, X-Robots-Tag-HTTP-Header und serverseitige Blockierung via .htaccess oder Firewall-Regeln. Für eine stärkere Überprüfung können Sie IP-Whitelistings nutzen, um nur Anfragen von verifizierten Crawler-IP-Adressen zuzulassen, die von großen KI-Unternehmen veröffentlicht werden.
Überwachen Sie, wie KI Ihre Marke referenziert
Verwenden Sie AmICited, um zu verfolgen, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews Ihre Inhalte auf verschiedenen KI-Plattformen zitieren und referenzieren.
So erkennen Sie KI-Crawler in Server-Logs: Vollständiger Leitfaden zur Erkennung
Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
Welche KI-Crawler sollte ich zulassen? Vollständiger Leitfaden für 2025
Erfahren Sie, welche KI-Crawler Sie in Ihrer robots.txt zulassen oder blockieren sollten. Umfassender Leitfaden zu GPTBot, ClaudeBot, PerplexityBot und 25+ KI-C...
AI-Crawler-Referenzkarte: Alle Bots auf einen Blick
Vollständiger Referenzleitfaden zu AI-Crawlern und Bots. Identifizieren Sie GPTBot, ClaudeBot, Google-Extended und 20+ weitere AI-Crawler mit User-Agents, Crawl...
15 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.