Technische und rechtliche Mechanismen, die es Urheber:innen und Rechteinhabern ermöglichen, ihre Werke von der Verwendung in Trainingsdatensätzen für große Sprachmodelle auszuschließen. Dazu gehören robots.txt-Direktiven, rechtliche Opt-out-Erklärungen und vertragliche Schutzmaßnahmen gemäß Regelungen wie dem EU AI Act.
KI-Training-Opt-out
Technische und rechtliche Mechanismen, die es Urheber:innen und Rechteinhabern ermöglichen, ihre Werke von der Verwendung in Trainingsdatensätzen für große Sprachmodelle auszuschließen. Dazu gehören robots.txt-Direktiven, rechtliche Opt-out-Erklärungen und vertragliche Schutzmaßnahmen gemäß Regelungen wie dem EU AI Act.
Was ist KI-Training-Opt-out?
KI-Training-Opt-out bezeichnet technische und rechtliche Mechanismen, mit denen Urheber:innen, Rechteinhaber und Website-Betreibende verhindern können, dass ihre Werke in Trainingsdatensätzen für große Sprachmodelle (LLM) verwendet werden. Da KI-Unternehmen riesige Datenmengen aus dem Internet zum Training ihrer immer ausgefeilteren Modelle sammeln, ist die Kontrolle darüber, ob eigene Inhalte daran teilnehmen, unerlässlich zum Schutz geistigen Eigentums und zur Wahrung kreativer Kontrolle. Diese Opt-out-Mechanismen wirken auf zwei Ebenen: technische Direktiven, die KI-Crawler anweisen, Ihre Inhalte zu überspringen, und rechtliche Rahmenbedingungen, die vertragliche Rechte schaffen, Ihre Werke von Trainingsdatensätzen auszuschließen. Wer sich Sorgen macht, wie seine Inhalte im KI-Zeitalter verwendet werden, sollte beide Dimensionen kennen.
Technische Mechanismen: robots.txt und User Agents
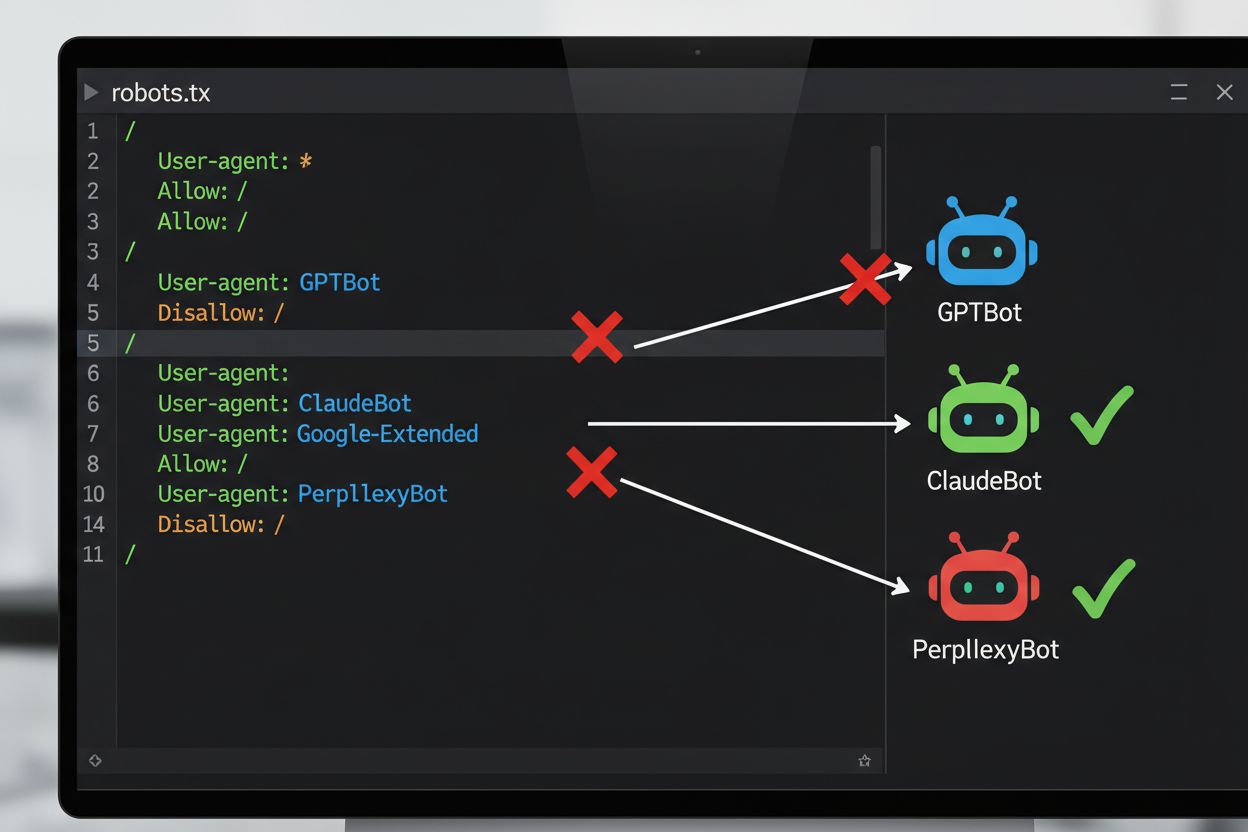
Die gängigste technische Methode für das Opt-out beim KI-Training ist die robots.txt-Datei – eine einfache Textdatei im Root-Verzeichnis einer Website, die automatisierten Bots Crawler-Berechtigungen mitteilt. Wenn ein KI-Crawler Ihre Seite besucht, prüft er zuerst die robots.txt, ob der Zugriff erlaubt ist. Durch gezielte Disallow-Direktiven für bestimmte Crawler-User-Agents können Sie KI-Bots anweisen, Ihre Seite komplett zu überspringen. Jedes KI-Unternehmen betreibt mehrere Crawler mit eigenen User-Agent-Kennungen – das sind quasi die „Namen“, mit denen sich Bots bei Anfragen identifizieren. Beispielsweise verwendet OpenAIs GPTBot den User-Agent-String “GPTBot”, während Anthropics Claude “ClaudeBot” nutzt. Die Syntax ist einfach: Sie geben den User-Agent-Namen an und deklarieren, welche Pfade untersagt sind, etwa „Disallow: /“ für einen Komplettblock.
KI-Unternehmen
Crawler-Name
User-Agent-Token
Zweck
OpenAI
GPTBot
GPTBot
Sammlung von Model-Trainingsdaten
OpenAI
OAI-SearchBot
OAI-SearchBot
ChatGPT-Suchindexierung
Anthropic
ClaudeBot
ClaudeBot
Chat-Zitationsabruf
Google
Google-Extended
Google-Extended
Gemini KI-Trainingsdaten
Perplexity
PerplexityBot
PerplexityBot
KI-Suchindexierung
Meta
Meta-ExternalAgent
Meta-ExternalAgent
KI-Model-Training
Common Crawl
CCBot
CCBot
Offener Datensatz für LLM-Training
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Das rechtliche Umfeld für das KI-Training-Opt-out hat sich mit der Einführung des EU AI Act, der 2024 in Kraft trat und Regelungen aus der Text and Data Mining (TDM) Directive enthält, stark verändert. Nach diesen Regelungen dürfen KI-Entwickler urheberrechtlich geschützte Werke nur dann für maschinelles Lernen nutzen, wenn sie rechtmäßigen Zugang zu den Inhalten haben und der Rechteinhaber nicht ausdrücklich widersprochen hat. Damit entsteht ein formaler rechtlicher Opt-out-Mechanismus: Rechteinhaber können Opt-out-Vorbehalte bei ihren Werken anmelden und so deren Nutzung für KI-Training ohne ausdrückliche Genehmigung wirksam verhindern. Der EU AI Act bedeutet einen bedeutenden Wandel gegenüber dem früheren „move fast and break things“-Ansatz und schreibt vor, dass Unternehmen beim Training von KI-Modellen prüfen müssen, ob Rechteinhaber Vorbehalte angemeldet haben, und technische sowie organisatorische Maßnahmen ergreifen, um eine versehentliche Nutzung auszuschließen. Dieses rechtliche Rahmenwerk gilt EU-weit und beeinflusst, wie globale KI-Unternehmen Datensammlung und Training handhaben.
Wie Opt-out-Mechanismen praktisch funktionieren
Die Umsetzung eines Opt-out-Mechanismus erfordert sowohl technische Konfiguration als auch rechtliche Dokumentation. Technisch fügen Website-Betreiber Disallow-Direktiven für spezifische KI-Crawler-User-Agents in ihrer robots.txt ein, die von konformen Crawlern beim Besuch respektiert werden. Rechtlich können Rechteinhaber Opt-out-Erklärungen bei Verwertungsgesellschaften und Rechteorganisationen abgeben – beispielsweise haben die niederländische Gesellschaft Pictoright und die französische Musikgesellschaft SACEM formale Opt-out-Verfahren eingerichtet, mit denen Kreative ihre Rechte gegen KI-Training vorbehalten können. Viele Websites und Urheber fügen mittlerweile explizite Opt-out-Hinweise in ihre Nutzungsbedingungen oder Metadaten ein, um zu erklären, dass ihre Inhalte nicht für KI-Model-Training genutzt werden sollen. Die Wirksamkeit all dieser Mechanismen hängt jedoch von der Einhaltung durch die Crawler ab: Während große Unternehmen wie OpenAI, Google und Anthropic öffentlich erklären, robots.txt-Direktiven und Opt-out-Vorbehalte zu achten, fehlt eine zentrale Durchsetzung – ob ein Opt-out tatsächlich beachtet wird, muss durch kontinuierliche Überwachung und Kontrolle überprüft werden.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Herausforderungen und Grenzen des Opt-out
Trotz vorhandener Opt-out-Mechanismen gibt es erhebliche Herausforderungen:
Freiwilliger Standard: robots.txt ist ein Gentlemen’s Agreement ohne rechtliche Durchsetzung – nicht-konforme Crawler können Ihre Direktiven schlicht ignorieren
Crawler-Umgehung: Fortgeschrittene Bots können User-Agent-Strings fälschen und sich als normale Browser tarnen, wodurch User-Agent-Blockaden wirkungslos werden
IP-Rotation: Scraper können über Proxies oder Botnets massenhaft IP-Adressen wechseln, sodass IP-Blockaden wenig bringen
Unvollständige Abdeckung: robots.txt stoppt rund 40–60 % der KI-Bots, der Rest bleibt ohne zusätzliche Maßnahmen ungebremst
Rogue Crawler: Unseriöse KI-Unternehmen und unabhängige Scraper ignorieren Opt-out-Mechanismen oft komplett und agieren in Graubereichen
Durchsetzungslücken: Selbst bei Verstößen sind rechtliche Schritte teuer, langwierig und mit unklarem Ausgang
Technische Schutzmaßnahmen jenseits von robots.txt
Für Organisationen, die stärkeren Schutz als robots.txt benötigen, gibt es zusätzliche technische Maßnahmen. User-Agent-Filter auf Server- oder Firewall-Ebene können Anfragen spezifischer Crawler blockieren, bevor sie Ihre Anwendung erreichen, sind aber weiter fälschbar. IP-Adress-Blockaden können auf bekannte Crawler-IP-Bereiche großer KI-Firmen abzielen, doch entschlossene Scraper umgehen dies über Proxy-Netzwerke. Rate Limiting und Throttling können Scraper durch Begrenzung der Anfragen pro Sekunde ausbremsen und wirtschaftlich uninteressant machen, doch ausgeklügelte Bots verteilen Anfragen über viele IPs. Authentifizierungspflicht und Paywalls bieten starken Schutz, indem sie Zugriffe auf eingeloggte Nutzer oder zahlende Kunden beschränken und Scraping verhindern. Device Fingerprinting und Verhaltensanalyse können Bots über Muster wie Browser-APIs, TLS-Handshake oder Interaktionsprofile erkennen, die von Menschen abweichen. Manche Organisationen setzen sogar Honeypots und Tarpits ein – versteckte Links oder Labyrinthe, die nur Bots folgen würden, um deren Ressourcen zu verschwenden und ihre Trainingsdatensätze mit „Müll“ zu verunreinigen.
Praxisbeispiele und Fallstudien
Die Auseinandersetzung zwischen KI-Unternehmen und Urheber:innen führte zu mehreren prominenten Konflikten, die die praktischen Herausforderungen beim Opt-out verdeutlichen. Reddit erhöhte 2023 die API-Preise drastisch, um gezielt KI-Unternehmen für Datenzugriffe zahlen zu lassen und unerlaubte Scraper auszuschließen – OpenAI und Anthropic mussten daraufhin Lizenzverträge aushandeln. Twitter/X ging noch weiter, blockierte zeitweise den anonymen Zugriff komplett und begrenzte auch für eingeloggte Nutzer die Zahl lesbarer Tweets, um Scraper aktiv auszuschließen. Stack Overflow blockierte OpenAIs GPTBot zunächst in der robots.txt wegen Lizenzbedenken bei Nutzer-Content, hob die Sperre später aber auf – vermutlich nach Verhandlungen. Nachrichtenportale reagierten massenhaft: Über 50 % der großen News-Sites sperrten KI-Crawler bis 2023, darunter The New York Times, CNN, Reuters und The Guardian, die alle GPTBot auf ihre Disallow-Listen setzten. Manche Medienhäuser zogen stattdessen vor Gericht – so reichte The New York Times eine Klage gegen OpenAI wegen Urheberrechtsverletzung ein, während andere wie die Associated Press Lizenzverträge abschlossen. Diese Beispiele zeigen: Opt-out-Mechanismen existieren, ihre Wirksamkeit hängt jedoch sowohl von der technischen Umsetzung als auch von der Bereitschaft ab, Verstöße rechtlich zu verfolgen.
Monitoring- und Compliance-Tools
Die Implementierung von Opt-out-Mechanismen ist nur der erste Schritt; deren tatsächliche Wirksamkeit muss laufend überwacht und getestet werden. Verschiedene Tools helfen bei der Validierung: Die Google Search Console enthält einen robots.txt-Tester speziell für Googlebot, während Merkle’s Robots.txt Tester und das Tool von TechnicalSEO.com das Verhalten einzelner Crawler gegen bestimmte User-Agents prüfen. Für umfassendes Monitoring, ob KI-Unternehmen Ihre Opt-out-Direktiven tatsächlich respektieren, bieten Plattformen wie AmICited.com spezialisiertes Monitoring, das verfolgt, wie KI-Systeme Ihre Marke und Inhalte in GPTs, Perplexity, Google AI Overviews und anderen KI-Plattformen referenzieren. Solches Monitoring ist besonders wertvoll, weil es nicht nur zeigt, ob Crawler auf Ihre Seite zugreifen, sondern auch, ob Ihre Inhalte tatsächlich in KI-generierten Antworten erscheinen – und damit, ob Ihr Opt-out effektiv ist. Auch eine regelmäßige Analyse der Server-Logs kann zeigen, welche Crawler Ihre Seite ansteuern und ob sie die robots.txt beachten – allerdings ist dafür technisches Know-how nötig.
Best Practices für Urheber und Content Creators
Um Ihre Inhalte wirksam vor unbefugtem KI-Training zu schützen, empfiehlt sich ein mehrschichtiger Ansatz aus technischen und rechtlichen Maßnahmen. Erstens: Setzen Sie robots.txt-Direktiven für alle wichtigen KI-Trainingscrawler (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot u.a.) um – das bietet Basisschutz gegen konforme Unternehmen. Zweitens: Fügen Sie explizite Opt-out-Erklärungen in Ihren Nutzungsbedingungen und den Metadaten Ihrer Website ein, um klarzustellen, dass Ihre Inhalte nicht für KI-Model-Training genutzt werden dürfen – das stärkt Ihre Rechtsposition im Streitfall. Drittens: Überwachen Sie Ihre Konfiguration regelmäßig mit Test-Tools und Server-Logs, um sicherzustellen, dass Crawler Ihre Direktiven einhalten, und aktualisieren Sie Ihre robots.txt quartalsweise, da ständig neue KI-Crawler entstehen. Viertens: Erwägen Sie zusätzliche technische Maßnahmen wie User-Agent-Filter oder Rate-Limiting, falls technisch möglich – das erhöht den Schutz gegen fortgeschrittene Scraper. Schließlich: Dokumentieren Sie Ihre Opt-out-Maßnahmen gründlich, da diese Dokumentation im Fall rechtlicher Schritte entscheidend sein kann. Denken Sie daran: Opt-out ist keine einmalige Einstellung, sondern ein fortlaufender Prozess, der Wachsamkeit und Anpassung an die sich wandelnde KI-Landschaft erfordert.
Häufig gestellte Fragen
Was ist der Unterschied zwischen robots.txt-Opt-out und rechtlichem Opt-out?
robots.txt ist ein technischer, freiwilliger Standard, der Crawler anweist, Ihre Inhalte zu überspringen, während ein rechtlicher Opt-out das Einreichen formeller Vorbehalte bei Verwertungsgesellschaften oder das Einfügen vertraglicher Klauseln in Ihren Nutzungsbedingungen umfasst. robots.txt ist einfacher umzusetzen, bietet jedoch keine Durchsetzung, während der rechtliche Opt-out einen stärkeren Rechtsschutz bietet, aber formellere Verfahren erfordert.
Respektieren alle KI-Unternehmen robots.txt-Direktiven?
Große KI-Unternehmen wie OpenAI, Google, Anthropic und Perplexity haben öffentlich erklärt, dass sie robots.txt-Direktiven respektieren. Allerdings ist robots.txt ein freiwilliger Standard ohne Durchsetzungsmechanismus, sodass nicht-konforme Crawler und böswillige Scraper Ihre Anweisungen vollständig ignorieren können.
Beeinflusst das Blockieren von KI-Training-Bots mein Suchmaschinenranking?
Nein. Das Blockieren von KI-Training-Crawlern wie GPTBot und ClaudeBot hat keinen Einfluss auf Ihr Google- oder Bing-Suchranking, da traditionelle Suchmaschinen andere Crawler (Googlebot, Bingbot) verwenden, die unabhängig arbeiten. Blockieren Sie diese nur, wenn Sie komplett aus den Suchergebnissen verschwinden möchten.
Wie geht der EU AI Act mit dem Opt-out um?
Der EU AI Act verlangt, dass KI-Entwickler rechtmäßigen Zugang zu Inhalten haben und die Opt-out-Vorbehalte von Rechteinhabern respektieren. Rechteinhaber können Opt-out-Erklärungen mit ihren Werken einreichen und so deren Nutzung für KI-Training ohne ausdrückliche Zustimmung effektiv verhindern. Dies schafft einen formellen rechtlichen Mechanismus zum Schutz von Inhalten vor unbefugtem Training.
Kann ich mit Opt-out verhindern, dass meine Inhalte in KI-Suchergebnissen erscheinen?
Das hängt vom jeweiligen Mechanismus ab. Das Blockieren aller KI-Crawler verhindert, dass Ihre Inhalte in KI-Suchergebnissen erscheinen, entfernt Sie aber auch komplett aus KI-gestützten Suchplattformen. Einige Publisher bevorzugen selektives Blockieren – sie erlauben suchfokussierten Crawlern den Zugriff, während sie Trainingscrawler blockieren, um Sichtbarkeit in der KI-Suche zu behalten und dennoch das Training zu verhindern.
Was passiert, wenn ein KI-Unternehmen mein Opt-out ignoriert?
Wenn ein KI-Unternehmen Ihre Opt-out-Direktiven ignoriert, haben Sie rechtliche Möglichkeiten, z.B. wegen Urheberrechtsverletzung oder Vertragsbruch – je nach Rechtslage und Situation. Rechtliche Schritte sind jedoch kostenintensiv, langsam und mit unsicherem Ausgang. Daher sind Überwachung und Dokumentation Ihrer Opt-out-Maßnahmen entscheidend.
Wie oft sollte ich meine Opt-out-Konfiguration aktualisieren?
Überprüfen und aktualisieren Sie Ihre robots.txt-Konfiguration mindestens vierteljährlich. Ständig tauchen neue KI-Crawler auf und Unternehmen führen häufig neue User-Agents ein. So hat Anthropic beispielsweise seine Bots 'anthropic-ai' und 'Claude-Web' zu 'ClaudeBot' zusammengeführt, wodurch der neue Bot vorübergehend uneingeschränkten Zugriff auf Seiten hatte, deren Regeln nicht aktualisiert wurden.
Ist Opt-out bei allen KI-Crawlern wirksam?
Opt-out ist wirksam bei seriösen KI-Unternehmen, die robots.txt und rechtliche Rahmenbedingungen respektieren. Bei böswilligen Crawlern und nicht-konformen Scraper, die sich in rechtlichen Grauzonen bewegen, ist es weniger effektiv. robots.txt stoppt etwa 40-60% der KI-Bots – daher empfiehlt sich ein mehrschichtiger Ansatz mit mehreren technischen und rechtlichen Maßnahmen.
Überwachen Sie, wie KI auf Ihre Inhalte verweist
Verfolgen Sie, ob Ihre Inhalte in KI-generierten Antworten über ChatGPT, Perplexity, Google AI Overviews und andere KI-Plattformen mit AmICited erscheinen.
So optimieren Sie Ihre Inhalte für KI-Trainingsdaten und KI-Suchmaschinen
Erfahren Sie, wie Sie Ihre Inhalte für die Aufnahme in KI-Trainingsdaten optimieren. Entdecken Sie Best Practices, um Ihre Website durch richtige Inhaltsstruktu...
Kontrolle über KI-Trainingsdaten: Wem gehört Ihr Inhalt?
Erkunden Sie die komplexe Rechtslage rund um das Eigentum an KI-Trainingsdaten. Erfahren Sie, wer Ihre Inhalte kontrolliert, welche urheberrechtlichen Implikati...
Urheberrechtliche Implikationen von KI-Suchmaschinen und Generativer KI
Verstehen Sie die urheberrechtlichen Herausforderungen für KI-Suchmaschinen, Fair-Use-Einschränkungen, aktuelle Klagen und rechtliche Implikationen für KI-gener...
8 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.