Jak nakonfigurovat robots.txt pro AI crawlery: Kompletní průvodce
Naučte se, jak nakonfigurovat robots.txt pro kontrolu přístupu AI crawlerů včetně GPTBot, ClaudeBot a Perplexity. Spravujte viditelnost své značky v odpovědích ...
7 min čtení
Technické a právní mechanismy umožňující tvůrcům obsahu a držitelům autorských práv zabránit použití jejich díla v trénovacích datasetech velkých jazykových modelů. Tyto zahrnují direktivy robots.txt, právní prohlášení o opt-out a smluvní ochrany podle regulací jako je EU AI Act.
Technické a právní mechanismy umožňující tvůrcům obsahu a držitelům autorských práv zabránit použití jejich díla v trénovacích datasetech velkých jazykových modelů. Tyto zahrnují direktivy robots.txt, právní prohlášení o opt-out a smluvní ochrany podle regulací jako je EU AI Act.
AI training opt-out odkazuje na technické a právní mechanismy umožňující tvůrcům obsahu, držitelům autorských práv a majitelům webových stránek zabránit použití jejich díla v trénovacích datasetech velkých jazykových modelů (LLM). Jak AI společnosti sbírají obrovské množství dat z internetu k trénování stále sofistikovanějších modelů, schopnost kontrolovat, zda se váš obsah účastní tohoto procesu, se stala nezbytnou pro ochranu duševního vlastnictví a udržení tvůrčí kontroly. Tyto opt-out mechanismy fungují na dvou úrovních: technické direktivy, které instruují AI crawlery, aby přeskočily váš obsah, a právní rámce, které stanovují smluvní práva vyloučit vaše dílo z trénovacích datasetů.

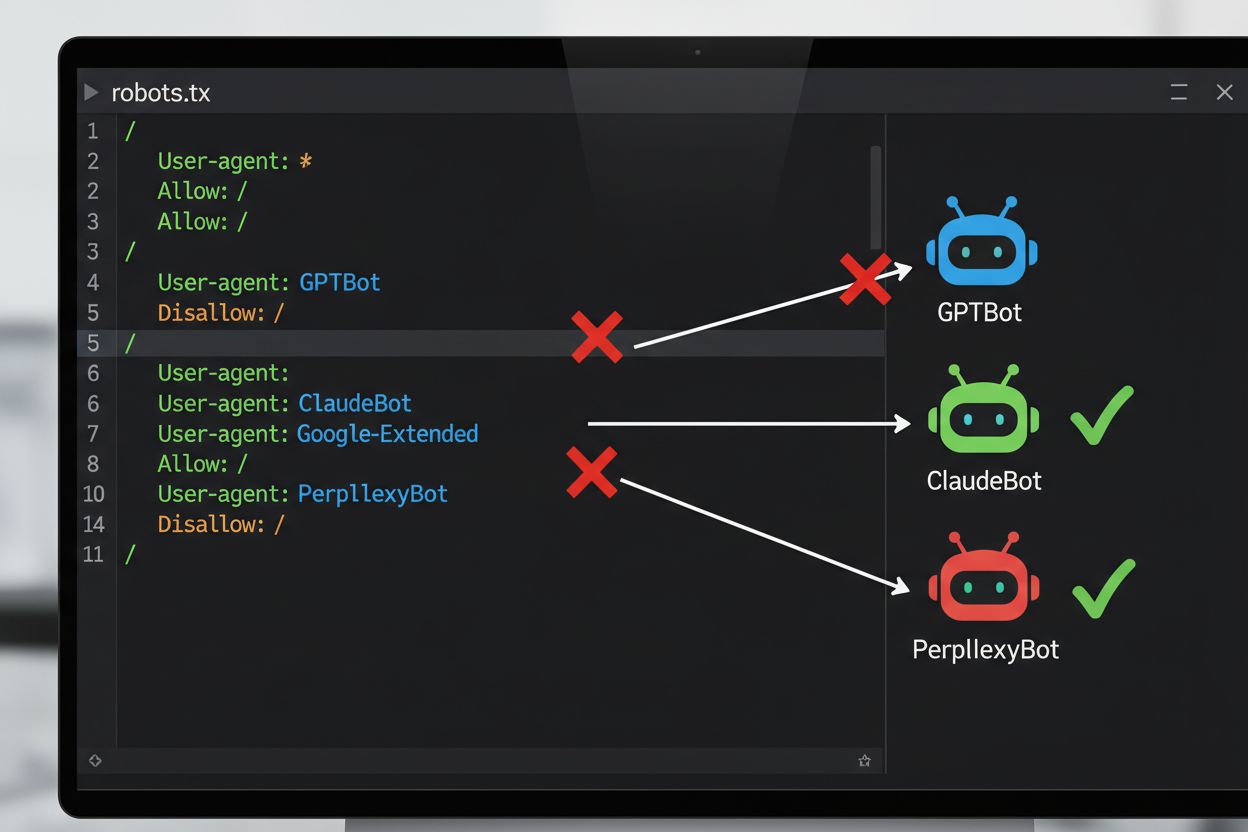
Nejběžnější technickou metodou pro opt-out z AI tréninku je soubor robots.txt, jednoduchý textový soubor umístěný v kořenovém adresáři webu, který komunikuje oprávnění crawlerů automatizovaným botům. Když AI crawler navštíví váš web, nejprve zkontroluje robots.txt, aby zjistil, zda má přístup k vašemu obsahu povolen. Přidáním specifických disallow direktiv pro konkrétní crawler user agenty můžete instruovat AI boty, aby váš web zcela přeskočily.
| AI společnost | Název crawleru | User Agent Token | Účel |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Sběr trénovacích dat modelu |
| OpenAI | OAI-SearchBot | OAI-SearchBot | Indexování vyhledávání ChatGPT |
| Anthropic | ClaudeBot | ClaudeBot | Fetch citací chatu |
| Google-Extended | Google-Extended | Trénovací data Gemini AI | |
| Perplexity | PerplexityBot | PerplexityBot | Indexování AI vyhledávání |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | Trénink AI modelu |
| Common Crawl | CCBot | CCBot | Otevřený dataset pro LLM trénink |
Právní krajina pro AI training opt-out se významně vyvinula zavedením EU AI Act, který vstoupil v platnost v roce 2024 a zahrnuje ustanovení ze směrnice o těžbě textů a dat (TDM). Podle těchto regulací je vývojářům AI povoleno používat díla chráněná autorským právem pro účely strojového učení pouze pokud mají zákonný přístup k obsahu a držitel autorských práv výslovně nerezervoval právo vyloučit své dílo z těžby textů a dat.
Implementace opt-out mechanismu zahrnuje jak technickou konfiguraci, tak právní dokumentaci. Na technické straně majitelé webů přidávají disallow direktivy do svého souboru robots.txt pro specifické AI crawler user agenty, které kompatibilní crawlery budou respektovat při návštěvě webu. Na právní straně mohou držitelé autorských práv podat prohlášení o opt-out u kolektivních správců a organizací pro správu práv.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Navzdory dostupnosti opt-out mechanismů, významné výzvy omezují jejich účinnost:
Pro efektivní ochranu vašeho obsahu před neoprávněným použitím v AI tréninku přijměte vrstvený přístup kombinující technická a právní opatření. Za prvé, implementujte direktivy robots.txt pro všechny hlavní AI tréninkové crawlery (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot a další). Za druhé, přidejte explicitní prohlášení o opt-out do podmínek služby a metadat vašeho webu. Za třetí, pravidelně monitorujte svou konfiguraci pomocí testovacích nástrojů a serverových logů. Za čtvrté, zvažte další technická opatření jako filtrování user agentů nebo omezení rychlosti. Nakonec, dokumentujte své opt-out snahy důkladně, protože tato dokumentace se stává klíčovou, pokud potřebujete podniknout právní kroky.
Sledujte, zda se váš obsah objevuje v AI-generovaných odpovědích napříč ChatGPT, Perplexity, Google AI Overviews a dalšími AI platformami s AmICited.
Naučte se, jak nakonfigurovat robots.txt pro kontrolu přístupu AI crawlerů včetně GPTBot, ClaudeBot a Perplexity. Spravujte viditelnost své značky v odpovědích ...
Zjistěte, jak povolit AI botům jako GPTBot, PerplexityBot a ClaudeBot procházet váš web. Nastavte robots.txt, vytvořte llms.txt a optimalizujte svůj web pro AI ...
Diskuze komunity o povolení AI botů pro procházení vašeho webu. Skutečné zkušenosti s konfigurací robots.txt, implementací llms.txt a správou AI crawlerů....
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.