
Sådan konfigurerer du robots.txt til AI-crawlere: Komplet guide
Lær hvordan du konfigurerer robots.txt for at kontrollere AI-crawleres adgang, herunder GPTBot, ClaudeBot og Perplexity. Administrer din brands synlighed i AI-g...
8 min læsning
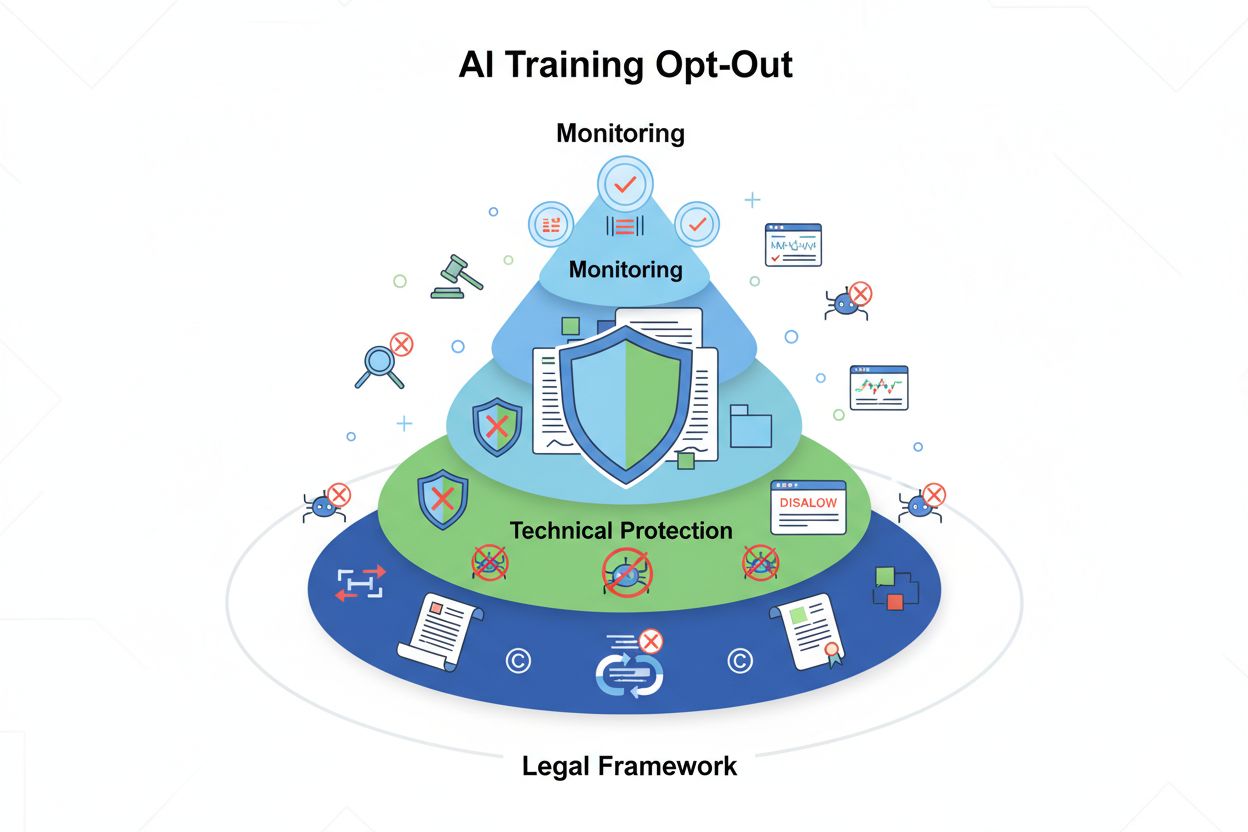
Tekniske og juridiske mekanismer, der gør det muligt for indholdsskabere og ophavsretsindehavere at forhindre deres arbejde i at blive brugt i træningsdatasæt til store sprogmodeller. Disse inkluderer robots.txt-direktiver, juridiske opt-out-erklæringer og kontraktmæssige beskyttelser under reguleringer som EU AI Act.
Tekniske og juridiske mekanismer, der gør det muligt for indholdsskabere og ophavsretsindehavere at forhindre deres arbejde i at blive brugt i træningsdatasæt til store sprogmodeller. Disse inkluderer robots.txt-direktiver, juridiske opt-out-erklæringer og kontraktmæssige beskyttelser under reguleringer som EU AI Act.
AI training opt-out refererer til de tekniske og juridiske mekanismer, der gør det muligt for indholdsskabere, ophavsretsindehavere og webstedsejere at forhindre deres arbejde i at blive brugt i træningsdatasæt til store sprogmodeller (LLM). Efterhånden som AI-virksomheder scraper enorme mængder data fra internettet til at træne stadig mere sofistikerede modeller, er evnen til at kontrollere, om dit indhold deltager i denne proces, blevet essentiel for beskyttelse af intellektuel ejendomsret og opretholdelse af kreativ kontrol. Disse opt-out-mekanismer opererer på to niveauer: tekniske direktiver, der instruerer AI-crawlere om at springe dit indhold over, og juridiske rammer, der etablerer kontraktmæssige rettigheder til at udelukke dit arbejde fra træningsdatasæt.

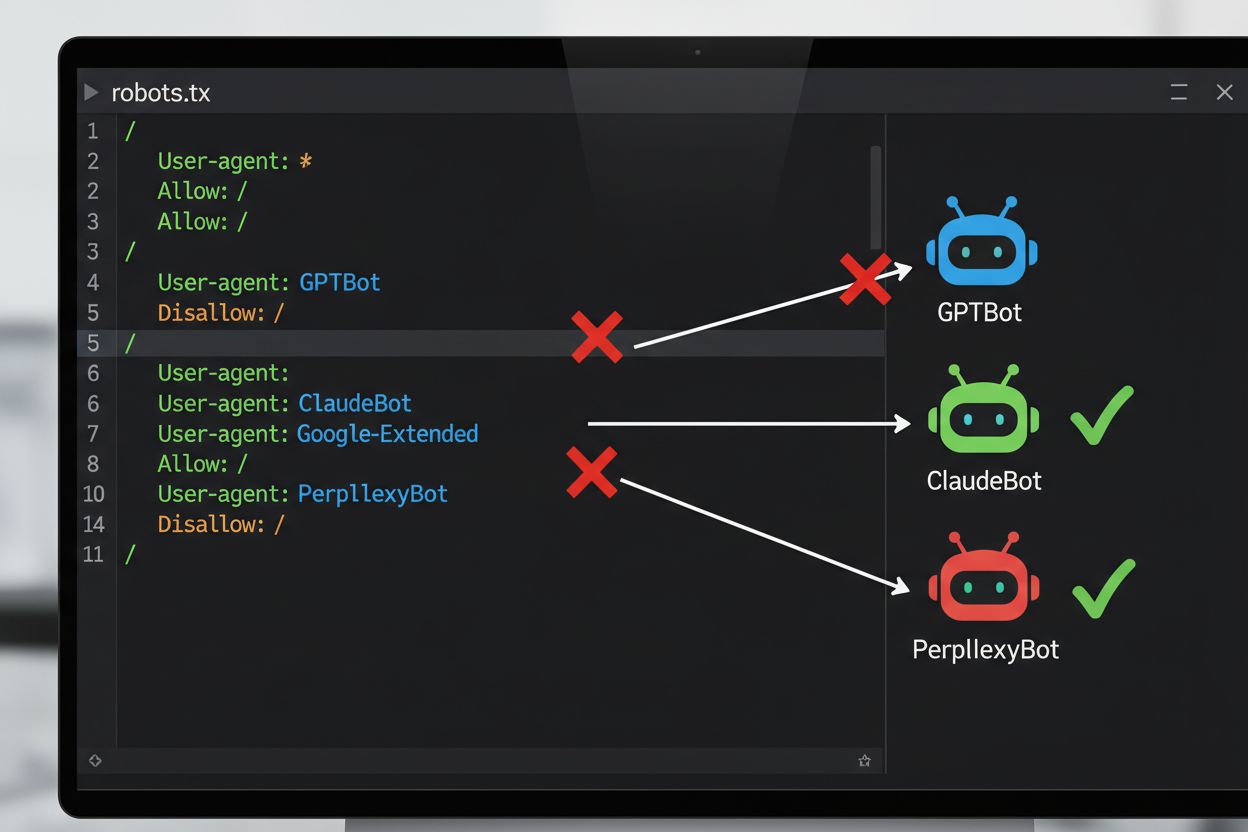
Den mest almindelige tekniske metode til at framelde sig AI-træning er gennem robots.txt-filen, en simpel tekstfil placeret i et websteds rodmappe, der kommunikerer crawlertilladelser til automatiserede bots. Når en AI-crawler besøger dit websted, tjekker den først robots.txt for at se, om den har tilladelse til at tilgå dit indhold. Ved at tilføje specifikke disallow-direktiver for bestemte crawler user agents kan du instruere AI-bots om at springe dit websted helt over.
| AI-virksomhed | Crawlernavn | User Agent Token | Formål |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Indsamling af modeltræningsdata |
| OpenAI | OAI-SearchBot | OAI-SearchBot | ChatGPT-søgeindeksering |
| Anthropic | ClaudeBot | ClaudeBot | Chat-citationsfetch |
| Google-Extended | Google-Extended | Gemini AI-træningsdata | |
| Perplexity | PerplexityBot | PerplexityBot | AI-søgeindeksering |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | AI-modeltræning |
| Common Crawl | CCBot | CCBot | Åbent datasæt til LLM-træning |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Det juridiske landskab for AI training opt-out har udviklet sig betydeligt med introduktionen af EU AI Act, der trådte i kraft i 2024 og inkorporerer bestemmelser fra Text and Data Mining (TDM) Directive. Under disse reguleringer er AI-udviklere tilladt at bruge ophavsretsbeskyttede værker til maskinlæringsformål kun, hvis de har lovlig adgang til indholdet, og ophavsretsindehaveren ikke udtrykkeligt har forbeholdt retten til at udelukke deres arbejde fra tekst- og datamining.
Implementering af en opt-out-mekanisme involverer både teknisk konfiguration og juridisk dokumentation. På den tekniske side tilføjer webstedsejere disallow-direktiver til deres robots.txt-fil for specifikke AI-crawler user agents, som kompatible crawlere vil respektere, når de besøger webstedet. På den juridiske side kan ophavsretsindehavere indgive opt-out-erklæringer til forvaltningsorganisationer og rettighedsorganisationer.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Trods tilgængeligheden af opt-out-mekanismer begrænser betydelige udfordringer deres effektivitet:
For effektivt at beskytte dit indhold mod uautoriseret brug i AI-træning, anvend en lagdelt tilgang, der kombinerer tekniske og juridiske foranstaltninger. Først, implementer robots.txt-direktiver for alle større AI-træningscrawlere (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot og andre). For det andet, tilføj eksplicitte opt-out-erklæringer til dit websteds servicevilkår og metadata. For det tredje, overvåg regelmæssigt din konfiguration ved hjælp af testværktøjer og serverlogs. For det fjerde, overvej yderligere tekniske foranstaltninger som user agent-filtrering eller hastighedsbegrænsning. Endelig, dokumenter dine opt-out-bestræbelser grundigt, da denne dokumentation bliver afgørende, hvis du skal forfølge juridisk handling.
Spor om dit indhold optræder i AI-genererede svar på tværs af ChatGPT, Perplexity, Google AI Overviews og andre AI-platforme med AmICited.
Lær hvordan du konfigurerer robots.txt for at kontrollere AI-crawleres adgang, herunder GPTBot, ClaudeBot og Perplexity. Administrer din brands synlighed i AI-g...

Lær hvordan du konfigurerer robots.txt for AI-crawlere, herunder GPTBot, ClaudeBot og PerplexityBot. Forstå AI-crawlerkategorier, blokeringsstrategier og bedste...
Fællesskabsdiskussion om at tillade AI-bots at crawle dit site. Virkelige erfaringer med robots.txt-konfiguration, llms.txt-implementering og håndtering af AI-c...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.