
Kompletní průvodce blokováním (nebo povolováním) AI crawlerů
Naučte se, jak blokovat nebo povolovat AI crawlery jako GPTBot a ClaudeBot pomocí robots.txt, blokování na úrovni serveru a pokročilých metod ochrany. Kompletní...
6 min čtení

Strategická praxe selektivního povolování nebo blokování AI crawlerů za účelem kontroly, jak je váš obsah využíván pro trénink oproti reálnému vyhledávání. Zahrnuje použití souborů robots.txt, serverových kontrol a monitorovacích nástrojů pro řízení toho, které AI systémy mají přístup k vašemu obsahu a za jakým účelem.
Strategická praxe selektivního povolování nebo blokování AI crawlerů za účelem kontroly, jak je váš obsah využíván pro trénink oproti reálnému vyhledávání. Zahrnuje použití souborů robots.txt, serverových kontrol a monitorovacích nástrojů pro řízení toho, které AI systémy mají přístup k vašemu obsahu a za jakým účelem.
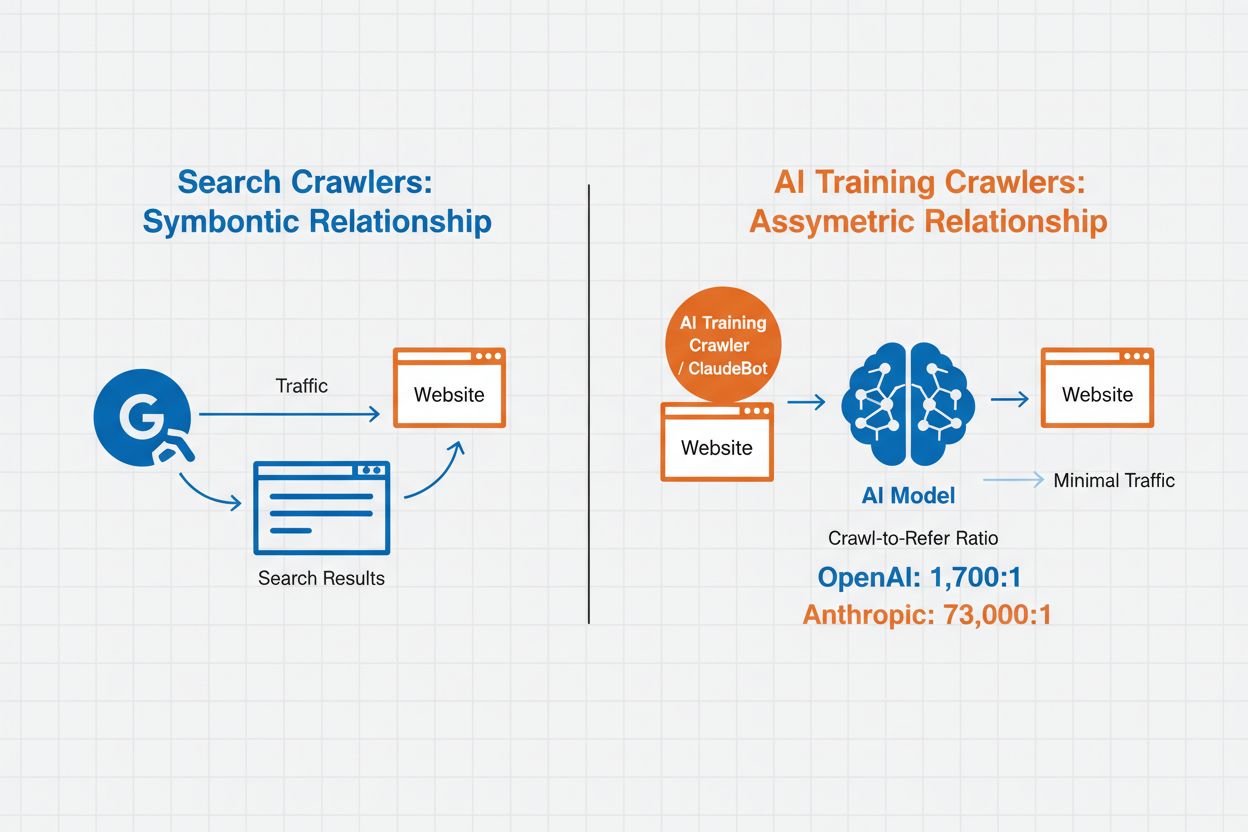
Správa AI crawlerů označuje praxi kontroly a monitorování toho, jak umělé inteligence přistupují a využívají obsah vašeho webu pro trénink i vyhledávání. Na rozdíl od tradičních vyhledávacích crawlerů, kteří indexují obsah pro webové vyhledávání, jsou AI crawlery navrženy speciálně ke sběru dat pro trénink velkých jazykových modelů nebo pohon AI vyhledávacích funkcí. Míra této aktivity se mezi organizacemi dramaticky liší—crawlery OpenAI pracují s poměrem crawl/referral 1 700:1, což znamená, že přistupují k obsahu 1 700krát na každou referenci, zatímco u Anthropic je tento poměr až 73 000:1, což ukazuje na obrovskou datovou spotřebu potřebnou k tréninku moderních AI systémů. Efektivní správa crawlerů umožňuje vlastníkům webu rozhodovat, zda jejich obsah přispěje k tréninku AI, zobrazí se ve výsledcích AI vyhledávání, nebo zůstane chráněný před automatizovaným přístupem.
AI crawlery lze rozdělit do tří kategorií podle účelu a způsobu využití dat. Tréninkoví crawlery jsou určeni ke sběru dat pro vývoj strojového učení a spotřebovávají obrovská množství obsahu pro zlepšení AI. Vyhledávací a citační crawlery indexují obsah pro AI vyhledávání a poskytují citace v AI odpovědích, což umožňuje uživatelům objevit váš obsah skrze AI rozhraní. Uživatelsky spouštění crawlery operují na vyžádání, například když uživatel ChatGPT nahraje dokument nebo žádá analýzu konkrétní stránky. Pochopení těchto kategorií vám pomůže kvalifikovaně rozhodnout, které crawlery blokovat či povolit podle vaší obsahové strategie a obchodních cílů.
| Typ crawleru | Účel | Příklady | Použití dat pro trénink |
|---|---|---|---|
| Tréninkový | Vývoj a zlepšování modelů | GPTBot, ClaudeBot | Ano |
| Vyhledávací/Citační | AI výsledky vyhledávání a citace | Google-Extended, OAI-SearchBot, PerplexityBot | Různé |
| Uživatelsky spouštěný | Analýza obsahu na vyžádání | ChatGPT-User, Meta-ExternalAgent, Amazonbot | Kontextově závislé |
Správa AI crawlerů má přímý dopad na návštěvnost, příjmy i hodnotu vašeho obsahu. Pokud crawlery konzumují váš obsah bez kompenzace, přicházíte o potenciální benefity z návštěvnosti, referralů, zobrazení reklam či zapojení uživatelů. Weby zaznamenaly významné poklesy návštěvnosti, když uživatelé nacházejí odpovědi přímo v AI generovaných odpovědích místo kliknutí na původní zdroj, což fakticky odřezává referral provoz i reklamní příjmy. Kromě finančních dopadů jsou zde i právní a etické otázky—váš obsah je duševní vlastnictví a máte právo rozhodovat, jak je využíván a zda za něj dostáváte citaci nebo odměnu. Dále neomezený přístup crawlerů může zvýšit zátěž serveru a náklady na přenos dat, zvláště u crawlerů s agresivními rychlostmi, které nerespektují limity.
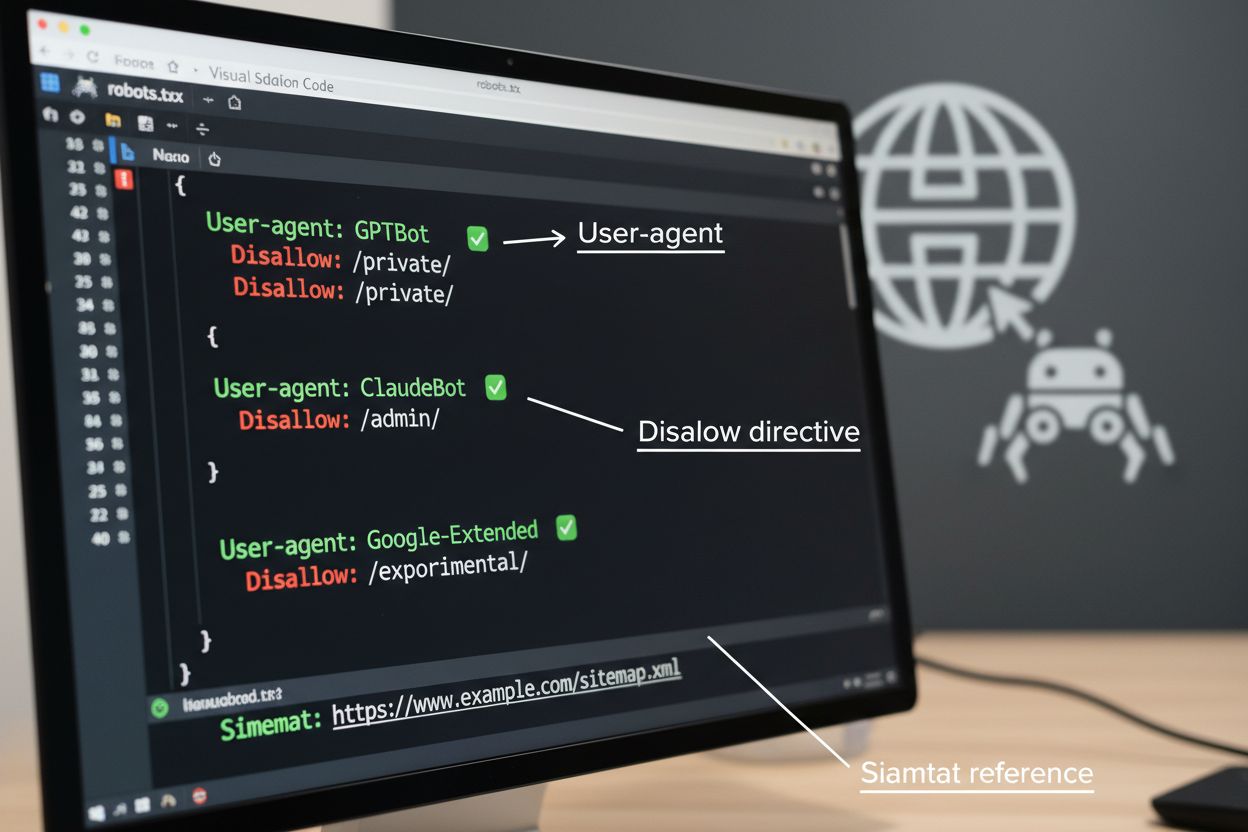
Soubor robots.txt je základním nástrojem pro řízení přístupu crawlerů, umisťuje se do kořenového adresáře webu a komunikuje preference ohledně crawlování automatizovaným agentům. Tento soubor používá direktivy User-agent k cílení na konkrétní crawlery a pravidla Disallow nebo Allow pro povolení či omezení přístupu k určitým cestám a zdrojům. Robots.txt má však svá omezení—jde o dobrovolný standard závislý na vůli crawlerů jej respektovat a škodlivé nebo špatně navržené boty jej mohou ignorovat. Robots.txt navíc crawlerům nebrání v přístupu k veřejnému obsahu; pouze žádá o respektování vašich preferencí. Proto by měl být robots.txt jen součástí víceúrovňové strategie, nikoli jedinou obranou.
# Blokování AI tréninkových crawlerů
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Povolení vyhledávačům
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Výchozí pravidlo pro ostatní crawlery
User-agent: *
Allow: /
Kromě robots.txt existuje několik pokročilých technik, které poskytují silnější vynucení a jemnější kontrolu nad přístupem crawlerů. Tyto metody pracují na různých úrovních infrastruktury a lze je kombinovat pro komplexní ochranu:
Rozhodnutí blokovat AI crawlery přináší důležité kompromisy mezi ochranou obsahu a jeho objevitelným dosahem. Blokování všech AI crawlerů eliminuje možnost, že se váš obsah objeví ve výsledcích AI vyhledávání, AI souhrnech nebo bude citován AI nástroji—což může snížit viditelnost pro uživatele, kteří již objevují obsah těmito novými kanály. Naopak, povolení neomezeného přístupu znamená, že váš obsah pohání trénink AI bez kompenzace a může omezit referral provoz, protože uživatelé získají odpovědi přímo od AI. Strategický přístup znamená selektivní blokování: povolíte citační crawlery jako OAI-SearchBot a PerplexityBot, které přivádějí referral provoz, a zablokujete tréninkové crawlery jako GPTBot a ClaudeBot, které obsah spotřebují bez uvedení zdroje. Můžete také zvážit povolení Google-Extended pro udržení viditelnosti v Google AI Overviews, které může přinést významnou návštěvnost, a zároveň blokovat tréninkové crawlery konkurence. Optimální strategie závisí na typu obsahu, obchodním modelu a publiku—zpravodajské weby a vydavatelé často upřednostňují blokování, zatímco autoři vzdělávacího obsahu mohou profitovat z širší AI viditelnosti.
Zavedení kontrol crawlerů je efektivní pouze tehdy, pokud ověříte, že je crawlery skutečně respektují. Analýza serverových logů je základní metodou monitorování aktivity crawlerů—prohlížejte přístupové logy pro User-Agent řetězce a vzorce požadavků, abyste zjistili, kteří crawlery navštěvují váš web a zda respektují vaše robots.txt pravidla. Mnoho crawlerů sice deklaruje soulad, ale přesto přistupuje na blokované cesty, proto je kontinuální monitoring zásadní. Nástroje jako Cloudflare Radar poskytují přehled o provozních vzorcích v reálném čase a pomohou odhalit podezřelé či nevyhovující chování crawlerů. Nastavte automatizovaná upozornění na pokusy o přístup k blokovaným zdrojům a pravidelně auditujte logy kvůli novým crawlerům nebo změnám chování, které mohou naznačovat pokusy o obejití restrikcí.
Efektivní správa AI crawlerů vyžaduje systematický přístup, který vyvažuje ochranu se strategickou viditelností. Dodržujte těchto osm kroků pro vytvoření komplexní strategie správy crawlerů:
AmICited.com nabízí specializovanou platformu pro sledování, jak AI systémy odkazují a využívají váš obsah napříč různými modely a aplikacemi. Služba poskytuje v reálném čase přehled o vašich citacích v AI generovaných odpovědích a pomáhá pochopit, které crawlery nejvíce pracují s vaším obsahem a jak často se vaše práce v AI výstupech objevuje. Analýzou vzorců crawlerů a dat o citacích umožňuje AmICited.com dělat rozhodnutí o strategii správy crawlerů na základě dat—jasně vidíte, které crawlery přinášejí hodnotu prostřednictvím citací a referralů, a které obsah pouze spotřebovávají bez uvedení zdroje. Tato inteligence mění správu crawlerů z defenzivní praxe na strategický nástroj pro optimalizaci viditelnosti a dopadu vašeho obsahu v AI prostředí webu.
AmICited.com sleduje v reálném čase zmínky o vaší značce v ChatGPT, Perplexity, Google AI Overviews a dalších AI systémech. Dělejte rozhodnutí ohledně správy crawlerů na základě dat.
Naučte se, jak blokovat nebo povolovat AI crawlery jako GPTBot a ClaudeBot pomocí robots.txt, blokování na úrovni serveru a pokročilých metod ochrany. Kompletní...

Zjistěte, jak konfigurovat robots.txt pro AI crawlery včetně GPTBot, ClaudeBot a PerplexityBot. Porozumějte kategoriím AI crawlerů, blokovacím strategiím a osvě...

Kompletní průvodce AI crawlery a boty. Identifikujte GPTBot, ClaudeBot, Google-Extended a dalších 20+ AI crawlerů podle user agentů, rychlostí procházení a stra...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.