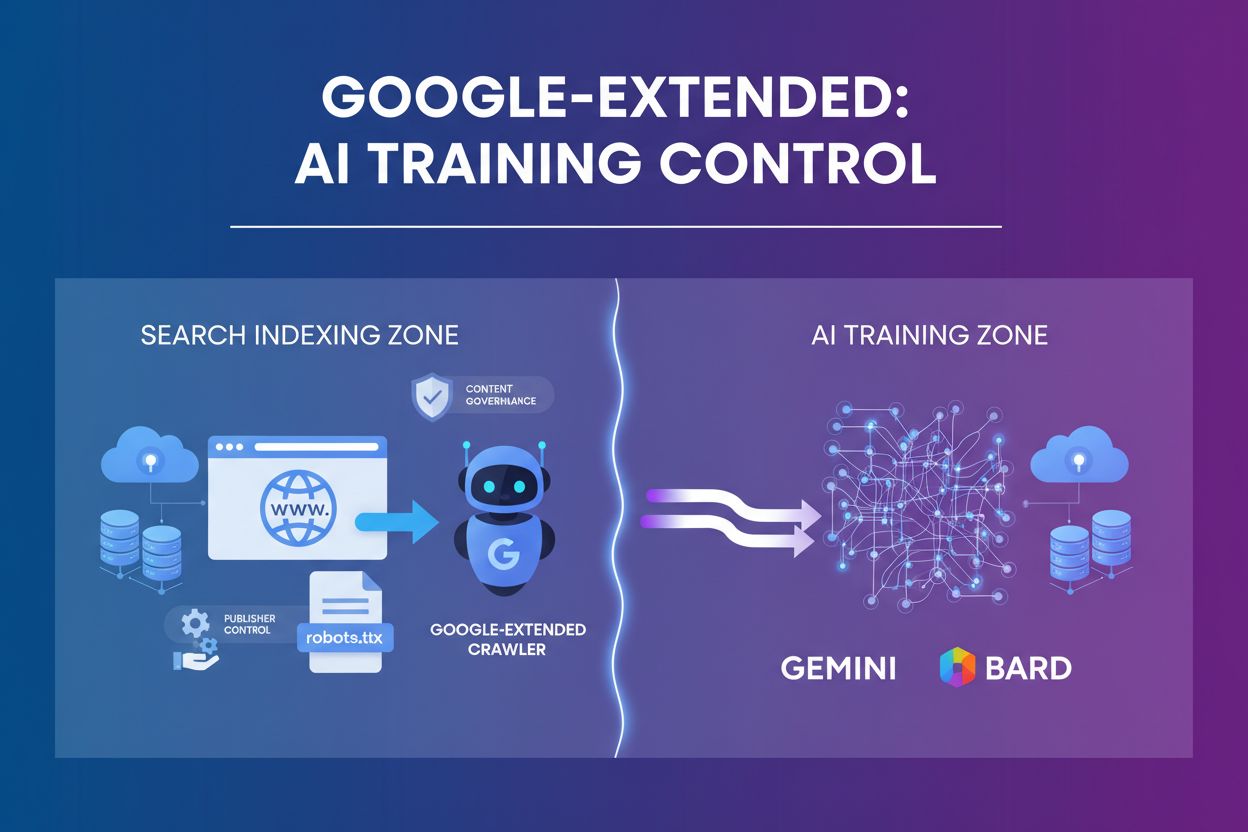
Google-Extended
Erfahren Sie mehr über Google-Extended, das User-Agent-Token, mit dem Publisher steuern können, ob ihre Inhalte für das Training von AI wie Gemini und Vertex AI...
6 Min. Lesezeit
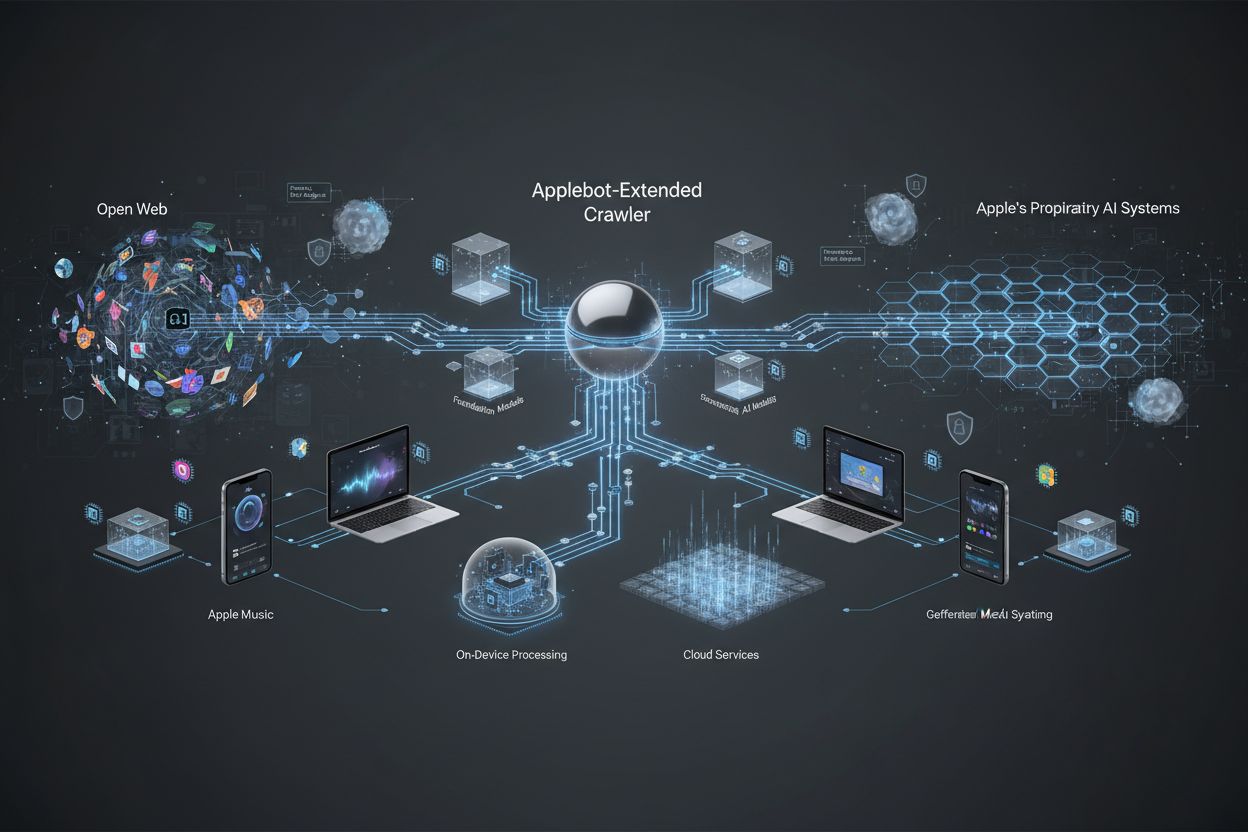
Apples spezialisierter Web-Crawler, der Inhalte für das Training von Apple Intelligence und generativen KI-Modellen bewertet. Er fungiert als sekundärer Bewertungsmechanismus neben dem Standard-Applebot, um festzustellen, welche öffentlich verfügbaren Webinhalte für die Aufnahme in Apples Foundation-Modelle und LLMs geeignet sind. Website-Besitzer können seinen Zugriff unabhängig vom Standard-Applebot über robots.txt steuern.
Apples spezialisierter Web-Crawler, der Inhalte für das Training von Apple Intelligence und generativen KI-Modellen bewertet. Er fungiert als sekundärer Bewertungsmechanismus neben dem Standard-Applebot, um festzustellen, welche öffentlich verfügbaren Webinhalte für die Aufnahme in Apples Foundation-Modelle und LLMs geeignet sind. Website-Besitzer können seinen Zugriff unabhängig vom Standard-Applebot über robots.txt steuern.
Applebot-Extended ist ein spezialisierter Web-Crawler von Apple, der die Fähigkeiten des Standard-Applebot erweitert, um gezielt Inhalte für das Training von Apple Intelligence-Systemen zu sammeln und zu bewerten. Während der ursprüngliche Applebot in erster Linie den Such- und Indexierungsbedarf von Apple abdeckt, arbeitet Applebot-Extended als eigenständiger Crawler, der sich auf die Erfassung hochwertiger Inhalte konzentriert, welche die generativen KI- und Machine-Learning-Modelle von Apple verbessern können. Dieser Crawler unterstreicht Apples Engagement für die Entwicklung fortschrittlicher KI-Trainingsdatensätze, indem er systematisch Webinhalte identifiziert und verarbeitet, die bestimmte Qualitätsstandards erfüllen. Die Unterscheidung zwischen dem Standard-Applebot und Applebot-Extended ist für Website-Besitzer entscheidend, da beide Crawler unterschiedliche Zwecke erfüllen und unabhängig voneinander über robots.txt-Anweisungen gesteuert werden können.
Applebot-Extended arbeitet in einem zweistufigen Crawling-System, bei dem die anfängliche Inhaltserkennung durch den Standard-Applebot erfolgt, gefolgt von einer sekundären Bewertungsphase durch Applebot-Extended. Wenn Applebot-Extended eine Webseite besucht, führt er eine umfassende Inhaltsbewertung durch, um festzustellen, ob das Material den Apple-Standards für die Aufnahme in KI-Trainingsdatensätze entspricht. Der Crawler identifiziert sich durch einen speziellen User-Agent-String, der ihn vom Standard-Applebot unterscheidet, sodass Website-Administratoren die beiden Crawler in ihren Server-Logs und Analyseplattformen unterscheiden können. Applebot-Extended bewertet Inhalte anhand mehrerer Kriterien, darunter Relevanz, Genauigkeit, Originalität und Einhaltung von Qualitätsrichtlinien, die sicherstellen, dass nur Premium-Inhalte in Apple-Intelligence-Systeme einfließen.
| Merkmal | Applebot | Applebot-Extended |
|---|---|---|
| Hauptzweck | Allgemeine Indexierung und Suche | Sammlung von KI-Trainingsdaten |
| Inhaltsfokus | Alle Webinhalte | Hochwertige, kuratierte Inhalte |
| User Agent | Applebot | Applebot-Extended |
| Bewertungstiefe | Standard-Crawling | Erweiterte Qualitätsprüfung |
| Blockiermethode | robots.txt-Anweisungen | Separate robots.txt-Regeln |

Apple Intelligence steht für Apples integrierte Suite von KI-basierten Funktionen, die Benutzererlebnisse auf iOS, iPadOS, macOS und anderen Apple-Plattformen durch On-Device- und Cloud-Verarbeitung verbessern. Die generativen KI-Fähigkeiten, die durch Applebot-Extended-Daten ermöglicht werden, umfassen fortschrittliche Schreibwerkzeuge, Bildgenerierung, intelligente Sucherweiterungen und kontextbewusste Assistentenfunktionen, die auf Foundation Models und großen Sprachmodellen (LLMs) basieren, die mit kuratierten Webinhalten trainiert werden. Diese Systeme ermöglichen Funktionen wie Writing Tools für E-Mails und Dokumente, Image Playground für kreative Inhaltserstellung und erweiterte Siri-Fähigkeiten, die komplexe Nutzeranfragen mit größerer Nuance und Genauigkeit verstehen. Apples Ansatz betont datenschutzfreundliche KI, indem ein Großteil dieser Intelligenz auf dem Gerät verarbeitet wird, während Applebot-Extended sicherstellt, dass die Trainingsdaten für diese Systeme aus hochwertigen, vielfältigen Quellen aus dem Web stammen. Der selektive Ansatz des Crawlers bei der Inhaltsauswahl wirkt sich direkt auf die Komplexität und Zuverlässigkeit der Apple-Intelligence-Funktionen aus, die weltweit Millionen Nutzern zur Verfügung stehen.
Applebot-Extended zielt auf bestimmte Inhaltskategorien ab, die für KI-Trainingszwecke einen hohen Informationswert und Zuverlässigkeit aufweisen. Der Crawler priorisiert Inhalte nach folgenden Kriterien:
Der Crawler verwendet ausgefeilte Datenfiltermechanismen, um minderwertige Inhalte wie Spam, doppelte Materialien und Inhalte mit geringem Informationswert zu entfernen. Apple implementiert datenschutzfreundliche Bewertungsmethoden, die die Inhaltsqualität bewerten, ohne unnötig personenbezogene Daten oder sensible Informationen zu speichern. Der Auswahlprozess beinhaltet automatisierte Qualitätsscoring-Systeme, die Faktoren wie Quellglaubwürdigkeit, Originalität der Inhalte, sachliche Genauigkeit und Relevanz für die Trainingsziele von Apple Intelligence bewerten. Website-Betreiber können die Einbeziehung ihrer Inhalte beeinflussen, indem sie hohe redaktionelle Standards einhalten, originelles und autoritatives Material bereitstellen und Praktiken vermeiden, die die Qualitätsmetriken künstlich erhöhen.
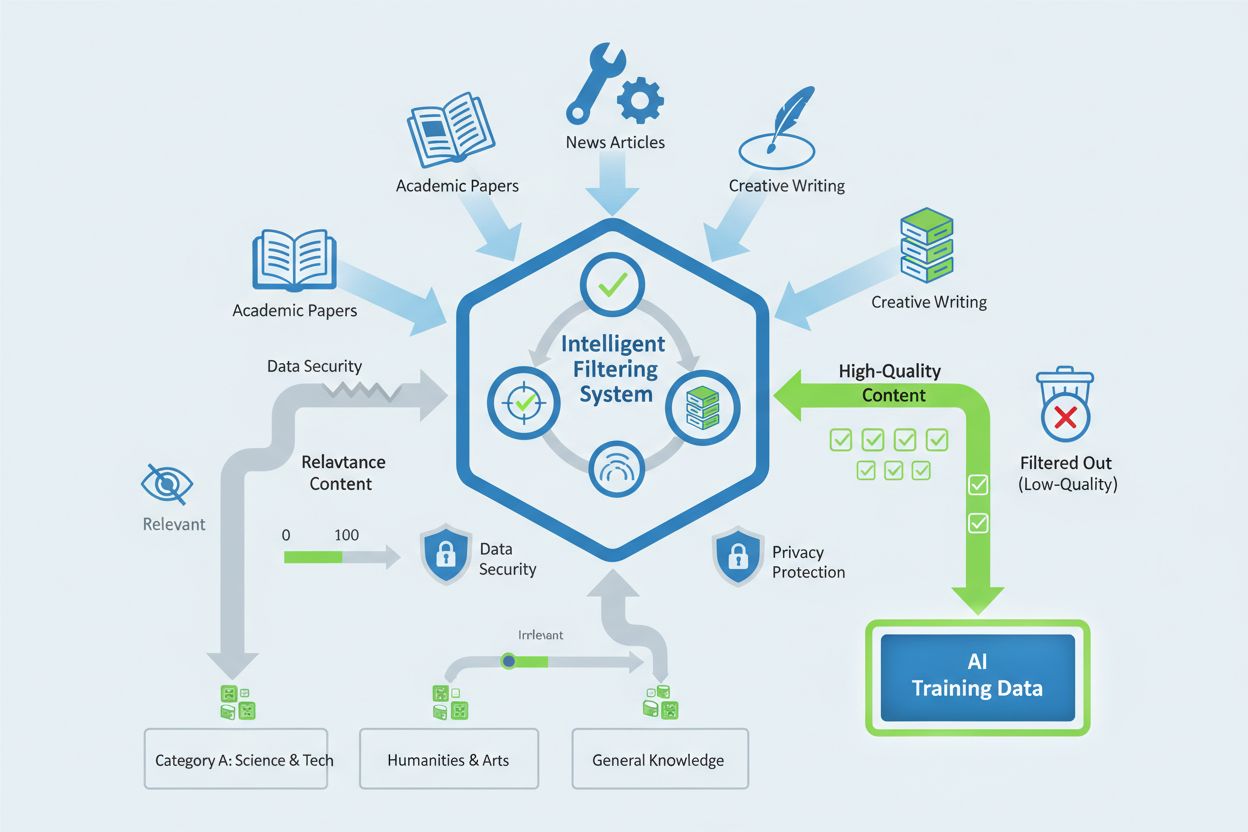
Website-Administratoren können den Zugriff von Applebot-Extended auf ihre Inhalte durch robots.txt-Anweisungen steuern, die eine detaillierte Kontrolle über das Crawler-Verhalten unabhängig von den Beschränkungen des Standard-Applebot ermöglichen. Um speziell Applebot-Extended zu blockieren und den Standard-Applebot weiterhin crawlen zu lassen, können Website-Betreiber gezielte Regeln implementieren, die die beiden Crawler anhand ihrer jeweiligen User-Agent-Kennungen unterscheiden. Der wesentliche Unterschied besteht darin, dass das Blockieren des Standard-Applebot nicht automatisch auch Applebot-Extended blockiert und umgekehrt – jeder Crawler muss separat verwaltet werden, wenn unterschiedliche Zugriffspolitiken gewünscht sind. Das Blockieren von Applebot-Extended hat geringe direkte SEO-Auswirkungen, da es das Suchranking nicht beeinflusst, verhindert jedoch, dass Ihre Inhalte zum Training von Apple Intelligence beitragen, was die Sichtbarkeit Ihrer Website in KI-gestützten Apple-Funktionen und -Diensten einschränken kann.
# Nur Applebot-Extended blockieren, Standard-Applebot weiterhin zulassen
User-agent: Applebot-Extended
Disallow: /
# Standard-Applebot zulassen
User-agent: Applebot
Allow: /
# Sowohl Applebot als auch Applebot-Extended blockieren
User-agent: Applebot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Bestimmte Verzeichnisse für Applebot-Extended blockieren
User-agent: Applebot-Extended
Disallow: /private/
Disallow: /admin/
Allow: /public/
Apple verfolgt bei den Operationen von Applebot-Extended einen datenschutzorientierten Ansatz und betont, dass die Sammlung von Inhalten für das KI-Training den Datenschutz und die Datenschutzgesetze in verschiedenen Ländern respektiert. Das Unternehmen implementiert technische und organisatorische Maßnahmen, um sicherzustellen, dass personenbezogene Daten beim Crawling und bei der Bewertung nicht unnötig erfasst oder aufbewahrt werden, wobei die Inhaltsbewertung auf den Informationswert und nicht auf die Extraktion persönlicher Informationen ausgerichtet ist. Website-Betreiber und Content-Ersteller behalten individuelle Datenschutzrechte in Bezug auf ihre Daten, einschließlich der Möglichkeit, Informationen über die Verwendung ihrer Inhalte anzufordern und Entfernungsrechte gemäß geltenden Datenschutzgesetzen wie DSGVO und CCPA auszuüben. Apple stellt das Formular für Datenschutzanfragen zu Apple Intelligence als offiziellen Mechanismus bereit, mit dem Einzelpersonen Fragen, Anliegen oder Anfragen zur Verwendung ihrer Inhalte oder personenbezogenen Daten im Zusammenhang mit Apple-Intelligence-Systemen einreichen können. Dieser strukturierte Ansatz zum Datenschutz stellt sicher, dass die Vorteile fortschrittlicher KI-Fähigkeiten mit den Grundrechten auf Datenschutz und Nutzerautonomie in Einklang gebracht werden.
Website-Betreiber können Applebot-Extended-Besuche erkennen, indem sie Server-Logs überwachen und User-Agent-Strings analysieren, in denen “Applebot-Extended” im Crawler-Identifikationsfeld angezeigt wird. Spezialisierte Analysetools wie Dark Visitors und UseHall bieten erweiterte Einblicke in den KI-Crawler-Traffic, sodass Administratoren Crawling-Muster, Häufigkeit und Ressourcenverbrauch im Zusammenhang mit Applebot-Extended-Besuchen überwachen können. Diese Monitoring-Lösungen helfen Website-Betreibern, die Auswirkungen von KI-Crawlern auf Serverressourcen und Bandbreite zu verstehen und fundierte Entscheidungen über Crawler-Zugriffsrichtlinien und Optimierungsstrategien zu treffen. Durch die Implementierung geeigneter Verkehrserkennungs- und Protokollierungsmechanismen können Administratoren Applebot-Extended-Aktivitäten von anderen Crawlern und menschlichem Nutzerverhalten unterscheiden und erhalten wertvolle Einblicke, wie ihre Inhalte zum KI-Trainingsinfrastruktur von Apple beitragen.
Applebot-Extended agiert in einem breiteren Ökosystem von KI-orientierten Web-Crawlern, die unterschiedliche Zwecke erfüllen und unter verschiedenen Richtlinien arbeiten – jeweils im Einklang mit der Unternehmensphilosophie der Muttergesellschaft bezüglich KI-Entwicklung und Datensammlung. Googlebot dient hauptsächlich der Suchindexierung und dem Ranking von Google, wobei separate Crawler wie Googlebot-Extended die Inhaltsbewertung für Googles KI-Systeme übernehmen – funktional ähnlich zum zweistufigen Ansatz von Apple, allerdings in deutlich größerem Maßstab. Bingbot, Microsofts Crawler, unterstützt ebenfalls sowohl die Suchindexierung als auch das KI-Training für Copilot und andere generative KI-Dienste, allerdings mit anderen Bewertungskriterien und Datenschutzrahmen. Der ChatGPT-Crawler (betrieben von OpenAI) konzentriert sich speziell auf die Sammlung von Inhalten für das Training großer Sprachmodelle und arbeitet mit expliziten Opt-out-Mechanismen und anderen Nutzungsvereinbarungen als Apple. Im Gegensatz zu einigen Mitbewerbern unterscheidet sich Applebot-Extended durch Apples Fokus auf On-Device-Verarbeitung und Datenschutz, beschränkt die cloudbasierte Datenspeicherung und bietet klarere Opt-out-Möglichkeiten über robots.txt und formale Datenschutzanfragen. Die vergleichende Analyse zeigt, dass zwar alle großen Tech-Unternehmen KI-Crawler einsetzen, sich ihre Bewertungskriterien, Richtlinien zur Datenspeicherung und Kontrollmechanismen für Nutzer jedoch deutlich unterscheiden – was verschiedene Unternehmensphilosophien zu KI-Entwicklung, Datenschutz und den Rechten von Content-Erstellern widerspiegelt. Website-Betreiber sollten diese Unterschiede bei der Entscheidung über Crawler-Zugriffe kennen, da die Richtlinien der einzelnen Crawler und deren Auswirkungen auf die Nutzung ihrer Inhalte in KI-Systemen erheblich variieren.
Applebot ist Apples primärer Web-Crawler, der für die Suchindexierung und Funktionen wie Spotlight und Siri-Suche verwendet wird. Applebot-Extended ist ein sekundärer Crawler, der von Applebot bereits indexierte Inhalte bewertet, um festzustellen, ob sie für das Training von Apples generativen KI-Modellen geeignet sind. Sie erfüllen unterschiedliche Zwecke und können unabhängig voneinander über robots.txt verwaltet werden.
Sie können Applebot-Extended blockieren, indem Sie spezielle Regeln in Ihre robots.txt-Datei einfügen. Verwenden Sie 'User-agent: Applebot-Extended' gefolgt von 'Disallow: /', um die gesamte Website zu blockieren, oder geben Sie bestimmte Verzeichnisse an. Dadurch wird verhindert, dass Ihre Inhalte für das Training von Apple Intelligence verwendet werden, während der Standard-Applebot Ihre Website weiterhin für Suchzwecke indexieren kann.
Das Blockieren von Applebot-Extended hat minimale direkte Auswirkungen auf das SEO, da es keine Auswirkungen auf Suchmaschinen-Rankings hat. Allerdings verhindert es, dass Ihre Inhalte zum Training von Apple Intelligence beitragen, was Ihre Sichtbarkeit in Apples KI-gestützten Funktionen und Diensten in Zukunft verringern könnte.
Applebot-Extended zielt auf hochwertige Inhalte ab, darunter wissenschaftliche Artikel, technische Dokumentationen, professionelle Nachrichtenartikel, originelle kreative Texte und Inhalte von anerkannten Fachexperten. Der Crawler bewertet Inhalte anhand von Glaubwürdigkeit, Originalität, sachlicher Richtigkeit und Relevanz für die KI-Trainingsziele.
Nein. Apple erklärt ausdrücklich, dass beim Training von Foundation-Modellen für Apple Intelligence keine privaten persönlichen Daten oder Nutzerinteraktionen verwendet werden. Das Unternehmen nutzt nur öffentlich verfügbare Webinhalte, lizenzierte Materialien und synthetisch erstellte Daten. Apple implementiert datenschutzfreundliche Maßnahmen, um personenbezogene Informationen aus Trainingsdatensätzen zu entfernen.
Sie können Applebot-Extended-Besuche erkennen, indem Sie Server-Logs auf den User-Agent-String 'Applebot-Extended' überwachen. Spezialisierte Analysetools wie Dark Visitors und UseHall bieten erweiterte Einblicke in KI-Crawler-Traffic, sodass Sie Crawling-Muster, Häufigkeit und Ressourcenverbrauch verfolgen können.
Apple Intelligence ist Apples integrierte Suite von KI-gestützten Funktionen über iOS, iPadOS, macOS und andere Plattformen hinweg. Applebot-Extended sammelt hochwertige Webinhalte, die die Foundation-Modelle und großen Sprachmodelle trainieren, die Apple-Intelligence-Funktionen wie Writing Tools, Image Playground und erweiterte Siri-Funktionen antreiben.
Ja. Apple stellt das Formular für Datenschutzanfragen bezüglich Apple Intelligence bereit, über das Einzelpersonen Anfragen bezüglich der Verwendung ihrer Inhalte oder personenbezogenen Daten im Zusammenhang mit Apple-Intelligence-Systemen einreichen können. Sie können auch Standard-robots.txt-Anweisungen verwenden, um das Crawlen durch Applebot-Extended zu verhindern.
Verfolgen Sie, wie Ihre Inhalte in Apple Intelligence und anderen KI-Systemen mit der umfassenden KI-Überwachungsplattform von AmICited erscheinen.
Erfahren Sie mehr über Google-Extended, das User-Agent-Token, mit dem Publisher steuern können, ob ihre Inhalte für das Training von AI wie Gemini und Vertex AI...

Erfahren Sie, was Google-Extended ist, wie es funktioniert und ob Sie es in Ihrer robots.txt blockieren sollten. Verstehen Sie den Unterschied zwischen KI-Train...

Erfahre, wie du KI-Bots wie GPTBot, PerplexityBot und ClaudeBot das Crawlen deiner Website erlaubst. Konfiguriere robots.txt, richte llms.txt ein und optimiere ...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.