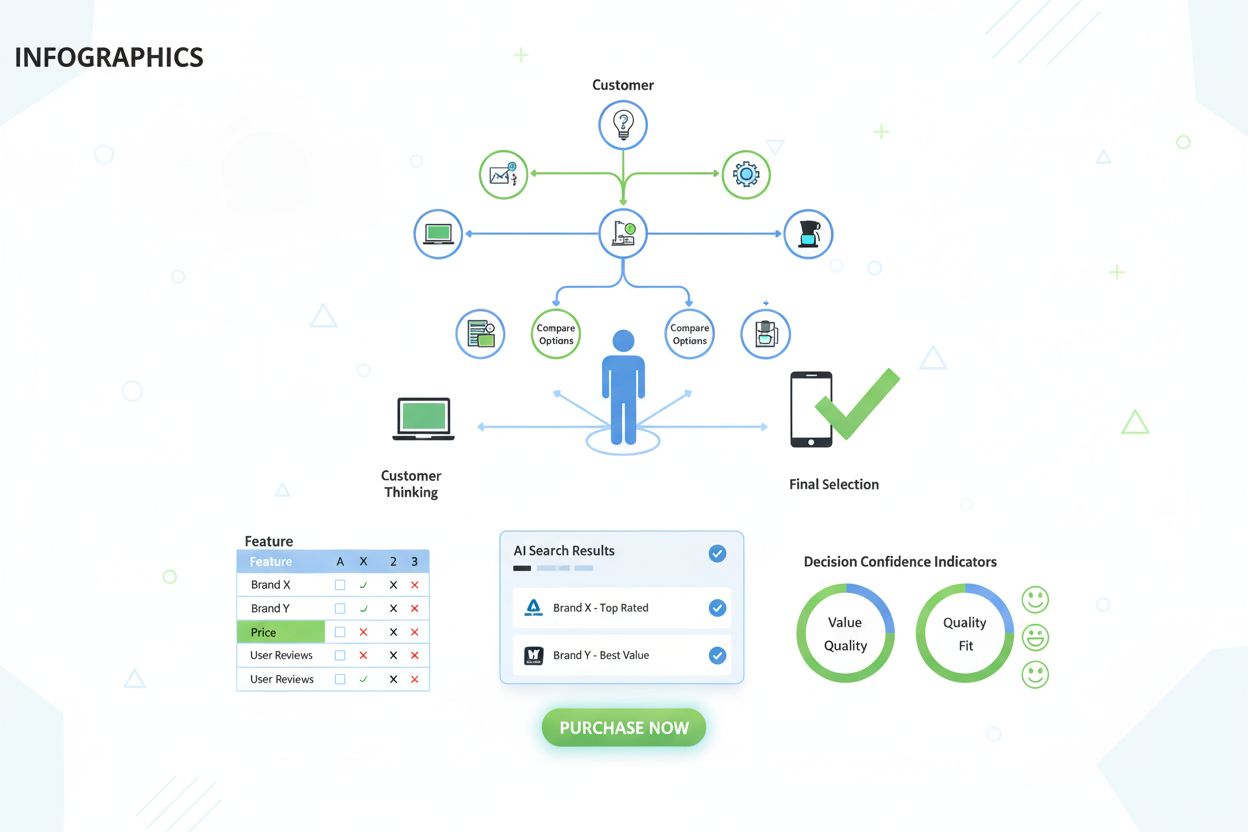
Entscheidungsphase – Finale Auswahlphase
Erfahren Sie, was die Entscheidungsphase in der Customer Journey ist. Verstehen Sie, wie die finale Auswahlphase die Markenpräsenz, KI-Suchergebnisse und Konver...
9 Min. Lesezeit

Schlussfolgerung ist der Prozess, bei dem ein trainiertes KI-Modell durch Anwendung der während des Trainings erlernten Muster und Kenntnisse aus neuen Eingabedaten Ausgaben, Vorhersagen oder Schlussfolgerungen generiert. Sie stellt die Betriebsphase dar, in der KI-Systeme ihre erlernte Intelligenz auf reale Probleme in Produktionsumgebungen anwenden.
Schlussfolgerung ist der Prozess, bei dem ein trainiertes KI-Modell durch Anwendung der während des Trainings erlernten Muster und Kenntnisse aus neuen Eingabedaten Ausgaben, Vorhersagen oder Schlussfolgerungen generiert. Sie stellt die Betriebsphase dar, in der KI-Systeme ihre erlernte Intelligenz auf reale Probleme in Produktionsumgebungen anwenden.
Schlussfolgerung ist der Prozess, bei dem ein trainiertes Modell der künstlichen Intelligenz durch Anwendung von Mustern und Wissen, das während der Trainingsphase erlernt wurde, aus neuen Eingabedaten Ausgaben, Vorhersagen oder Schlussfolgerungen generiert. Im Kontext von KI-Systemen stellt die Schlussfolgerung die Betriebsphase dar, in der maschinelle Lernmodelle aus dem Labor in Produktionsumgebungen überführt werden, um reale Probleme zu lösen. Wenn Sie mit ChatGPT, Perplexity, Google AI Overviews oder Claude interagieren, erleben Sie die KI-Schlussfolgerung in Aktion – das Modell nimmt Ihre Eingabe und generiert intelligente Antworten basierend auf Mustern, die es aus umfangreichen Trainingsdaten gelernt hat. Schlussfolgerung unterscheidet sich grundlegend vom Training; während das Training dem Modell beibringt, was zu tun ist, setzt es das Gelernte in der Schlussfolgerung tatsächlich um und wendet das Wissen auf noch nie zuvor gesehene Daten an.
Die Unterscheidung zwischen KI-Training und KI-Schlussfolgerung ist entscheidend, um zu verstehen, wie moderne Systeme der künstlichen Intelligenz funktionieren. Während der Trainingsphase füttern Datenwissenschaftler neuronale Netze mit riesigen, kuratierten Datensätzen, sodass das Modell Muster, Zusammenhänge und Entscheidungsregeln durch iterative Optimierung erlernen kann. Dieser Prozess ist rechnerisch sehr aufwendig und dauert oft Wochen oder Monate auf spezialisierter Hardware wie GPUs und TPUs. Sobald das Training abgeschlossen und das Modell auf optimale Gewichte und Parameter konvergiert ist, beginnt die Schlussfolgerungsphase. Ab diesem Zeitpunkt ist das Modell eingefroren – es lernt nicht mehr aus neuen Daten, sondern wendet seine erlernten Muster an, um Vorhersagen oder Ausgaben für bislang unbekannte Eingaben zu generieren. Laut Untersuchungen von IBM und Oracle wird der eigentliche geschäftliche Mehrwert der KI in der Schlussfolgerung realisiert, da hier KI-Fähigkeiten im großen Maßstab in Produktionssystemen eingesetzt werden können. Der Markt für KI-Schlussfolgerung hatte 2025 einen Wert von 106,15 Milliarden USD und wird bis 2030 voraussichtlich auf 254,98 Milliarden USD wachsen, was die enorme Nachfrage nach Schlussfolgerungsfähigkeiten in allen Branchen widerspiegelt.
KI-Schlussfolgerung erfolgt in einem mehrstufigen Prozess, der Rohdaten in intelligente Ausgaben umwandelt. Wenn ein Nutzer eine Anfrage an ein großes Sprachmodell wie ChatGPT stellt, beginnt die Schlussfolgerungspipeline mit dem Input-Encoding, bei dem Text in numerische Tokens umgewandelt wird, die das neuronale Netz verarbeiten kann. Anschließend folgt die Prefill-Phase, in der alle Eingabetokens gleichzeitig durch jede Schicht des neuronalen Netzes verarbeitet werden, sodass das Modell den Kontext und die Zusammenhänge in der Nutzeranfrage versteht. Diese Phase ist rechnerisch aufwendig, aber für das Verständnis notwendig. Nach der Prefill-Phase folgt die Decode-Phase, in der die Ausgabetokens nacheinander sequenziell generiert werden, wobei jedes neue Token von allen vorherigen Tokens in der Sequenz abhängt. Diese sequentielle Generierung erzeugt den charakteristischen Stream-Effekt, den Nutzer beim Einsatz von KI-Chatbots erleben. Abschließend werden in der Ausgabekonvertierungsphase die vorhergesagten Tokens zurück in lesbaren Text, Bilder oder andere Formate umgewandelt, die für den Nutzer verständlich und nutzbar sind. Dieser gesamte Prozess muss für Echtzeitanwendungen in Millisekunden ablaufen, weshalb die Optimierung der Schlussfolgerungslatenz für Anbieter von KI-Diensten eine zentrale Rolle spielt.
Organisationen, die KI-Systeme einsetzen, müssen zwischen drei grundlegenden Schlussfolgerungsarchitekturen wählen, die jeweils für unterschiedliche Anwendungsfälle und Leistungsanforderungen optimiert sind. Batch-Schlussfolgerung verarbeitet große Datenmengen offline zu festgelegten Zeiten und eignet sich für Szenarien, in denen keine Echtzeitantworten erforderlich sind, etwa für tägliche Analyse-Dashboards, wöchentliche Risikobewertungen oder nächtliche Empfehlungsupdates. Dieser Ansatz ist höchst effizient und kostengünstig, da Tausende Vorhersagen gleichzeitig verarbeitet werden und die Rechenkosten auf viele Anfragen verteilt werden können. Online-Schlussfolgerung, auch dynamische Schlussfolgerung genannt, erzeugt Vorhersagen sofort auf Anfrage mit minimaler Latenz und ist damit essenziell für interaktive Anwendungen wie Chatbots, Suchmaschinen und Echtzeit-Betrugserkennungssysteme. Online-Schlussfolgerung erfordert eine ausgefeilte Infrastruktur, um niedrige Latenzen und hohe Verfügbarkeit zu gewährleisten, häufig unter Einsatz von Caching-Strategien und Modelloptimierungen, damit Antworten in Millisekunden bereitstehen. Streaming-Schlussfolgerung verarbeitet kontinuierlich Datenströme von Sensoren, IoT-Geräten oder Echtzeitdatenpipelines und generiert für jeden eintreffenden Datenpunkt Vorhersagen. Diese Variante ist die Basis für Anwendungen wie vorausschauende Wartungssysteme, die Industrieanlagen überwachen, autonome Fahrzeuge, die Sensordaten in Echtzeit verarbeiten, oder Smart-City-Systeme, die Verkehrsströme permanent analysieren. Jeder Schlussfolgerungstyp stellt unterschiedliche Anforderungen an Architektur, Hardware und Optimierungsstrategien.
| Aspekt | Batch-Schlussfolgerung | Online-Schlussfolgerung | Streaming-Schlussfolgerung |
|---|---|---|---|
| Latenzanforderung | Sekunden bis Minuten | Millisekunden | Echtzeit (unter einer Sekunde) |
| Datenverarbeitung | Große Datensätze offline | Einzelanfragen auf Abruf | Kontinuierlicher Datenstrom |
| Anwendungsfälle | Analysen, Berichte, Empfehlungen | Chatbots, Suche, Betrugserkennung | IoT-Monitoring, autonome Systeme |
| Kosteneffizienz | Hoch (auf viele Vorhersagen verteilt) | Mittel (erfordert dauerhafte Infrastruktur) | Mittel bis hoch (abhängig vom Datenvolumen) |
| Skalierbarkeit | Hervorragend (Stapelverarbeitung) | Gut (erfordert Lastverteilung) | Hervorragend (verteilte Verarbeitung) |
| Modelloptimierungs-Priorität | Durchsatz | Ausgewogenheit von Latenz und Durchsatz | Ausgewogenheit von Latenz und Genauigkeit |
| Hardware-Anforderungen | Standard-GPUs/CPUs | Hochleistungs-GPUs/TPUs | Spezialisierte Edge-Hardware oder verteilte Systeme |
Optimierung der Schlussfolgerung ist zu einer zentralen Disziplin geworden, da Unternehmen KI-Modelle effizienter und kostengünstiger bereitstellen möchten. Quantisierung ist eine der wirkungsvollsten Optimierungstechniken: Sie reduziert die numerische Präzision der Modellgewichte von standardmäßigen 32-Bit-Gleitkommazahlen auf 8-Bit- oder sogar 4-Bit-Ganzzahlen. Dadurch kann die Modellgröße um 75–90 % verringert werden, während 95–99 % der ursprünglichen Genauigkeit erhalten bleiben – das führt zu schnelleren Schlussfolgerungen und geringerem Speicherbedarf. Modell-Pruning entfernt nicht-kritische Neuronen, Verbindungen oder ganze Schichten aus dem neuronalen Netz und eliminiert so überflüssige Parameter, die kaum zur Vorhersage beitragen. Studien zeigen, dass Pruning die Modellkomplexität um 50–80 % ohne nennenswerten Genauigkeitsverlust reduzieren kann. Knowledge Distillation trainiert ein kleineres, schnelleres „Schülermodell“ darauf, das Verhalten eines größeren, genaueren „Lehrermodells“ nachzuahmen, sodass es auch auf ressourcenbeschränkten Geräten mit akzeptabler Performance eingesetzt werden kann. Optimierung der Batch-Verarbeitung gruppiert mehrere Schlussfolgerungsanfragen, um die GPU-Auslastung und den Durchsatz zu maximieren. Key-Value-Caching speichert Zwischenergebnisse von Berechnungen, um redundante Rechenarbeit während der Decode-Phase von Sprachmodellen zu vermeiden. Nach NVIDIA-Forschung lassen sich durch die Kombination mehrerer Optimierungstechniken 10-fache Leistungssteigerungen erzielen und die Infrastrukturkosten um 60–70 % senken. Diese Optimierungen sind essenziell für den großflächigen Einsatz der Schlussfolgerung, besonders für Unternehmen mit Tausenden gleichzeitigen Schlussfolgerungsanfragen.
Hardware-Beschleunigung ist grundlegend, um die Latenz- und Durchsatzanforderungen moderner KI-Schlussfolgerungs-Workloads zu erfüllen. Grafikprozessoren (GPUs) sind nach wie vor die am meisten eingesetzten Beschleuniger, da ihre parallele Architektur besonders für die Matrixoperationen neuronaler Netze geeignet ist. NVIDIA-GPUs betreiben die Mehrheit der Sprachmodell-Schlussfolgerungen weltweit, wobei spezialisierte CUDA-Kerne massive Parallelisierung ermöglichen. Tensor Processing Units (TPUs), entwickelt von Google, sind speziell für neuronale Netze optimierte ASICs und bieten für bestimmte Workloads ein überlegenes Verhältnis von Leistung zu Stromverbrauch im Vergleich zu Allzweck-GPUs. Field-Programmable Gate Arrays (FPGAs) bieten anpassbare Hardware, die für spezielle Schlussfolgerungsaufgaben umprogrammiert werden kann – das bringt Flexibilität für besondere Anwendungen. Application-Specific Integrated Circuits (ASICs) wie Googles TPU oder Cerebras’ WSE-3 sind für spezifische Schlussfolgerungs-Workloads entwickelt und liefern außergewöhnliche Leistung bei eingeschränkter Flexibilität. Die Wahl der Hardware hängt von vielen Faktoren ab: Modellarchitektur, benötigte Latenz, Durchsatzanforderungen, Energieverbrauch und Gesamtkosten. Für Edge-Schlussfolgerungen auf mobilen Geräten oder IoT-Sensoren ermöglichen spezialisierte Edge-Beschleuniger und Neuronale Verarbeitungseinheiten (NPUs) effiziente Schlussfolgerung bei minimalem Stromverbrauch. Der weltweite Trend zu KI-Fabriken – hochoptimierter Infrastruktur zur Herstellung von Intelligenz im großen Maßstab – hat zu massiven Investitionen in Schlussfolgerungshardware geführt, wobei Unternehmen Tausende GPUs und TPUs in Rechenzentren einsetzen, um der steigenden Nachfrage nach KI-Diensten gerecht zu werden.
Generative KI-Systeme wie ChatGPT, Claude und Perplexity basieren vollständig auf Schlussfolgerung, um menschenähnlichen Text, Code, Bilder und andere Inhalte zu generieren. Wenn Sie diesen Systemen eine Eingabe übermitteln, beginnt der Schlussfolgerungsprozess mit der Tokenisierung Ihrer Eingabe in numerische Repräsentationen, die das neuronale Netz verarbeiten kann. Anschließend führt das Modell die Prefill-Phase aus, verarbeitet alle Ihre Eingabetokens gleichzeitig und baut so ein umfassendes Verständnis Ihrer Anfrage inklusive Kontext, Intention und Nuancen auf. Danach folgt die Decode-Phase, in der Ausgabetokens sequenziell generiert werden, wobei das wahrscheinlichste nächste Token auf Basis aller vorherigen Tokens und der während des Trainings gelernten Muster vorhergesagt wird. Diese Token-für-Token-Generierung ist der Grund, warum beim Einsatz dieser Dienste ein Textstrom in Echtzeit erscheint. Der Schlussfolgerungsprozess muss verschiedene konkurrierende Ziele ausbalancieren: Erzeugung genauer, kohärenter und kontextuell passender Antworten bei gleichzeitig niedriger Latenz, um die Nutzerbindung zu sichern. Spekulatives Decoding, eine fortschrittliche Optimierungstechnik, ermöglicht es einem kleineren Modell, mehrere zukünftige Tokens vorherzusagen, während das größere Modell diese Vorhersagen validiert – das senkt die Latenz deutlich. Das Ausmaß der Schlussfolgerung bei großen Sprachmodellen ist enorm – OpenAIs ChatGPT verarbeitet täglich Millionen Schlussfolgerungsanfragen, bei denen jeweils Hunderte oder Tausende Tokens generiert werden; hierfür sind riesige Recheninfrastrukturen und ausgefeilte Optimierungsstrategien nötig, um die Wirtschaftlichkeit zu gewährleisten.
Für Organisationen, die auf ihre Markenpräsenz und die Zitierung ihrer Inhalte in KI-generierten Ausgaben achten, ist Schlussfolgerungsmonitoring zunehmend bedeutend. Wenn Systeme wie Perplexity, Google AI Overviews oder Claude Antworten generieren, führen sie Schlussfolgerungen auf ihren trainierten Modellen durch, um Ausgaben zu produzieren, die Ihre Domain, Marke oder Inhalte referenzieren oder zitieren können. Zu verstehen, wie Schlussfolgerungssysteme arbeiten, hilft Unternehmen, ihre Content-Strategie zu optimieren, um die korrekte Darstellung in KI-generierten Antworten sicherzustellen. AmICited ist darauf spezialisiert, zu überwachen, wo Marken und Domains in Schlussfolgerungsausgaben verschiedener Plattformen erscheinen, und bietet Einblicke, wie KI-Systeme auf Ihre Inhalte Bezug nehmen. Dieses Monitoring ist entscheidend, da Schlussfolgerungssysteme auf Basis der Trainingsdatenqualität, Relevanzsignale und Modelloptimierungen Antworten erzeugen, die Ihre Marke ein- oder ausschließen können. Organisationen können die Monitoringdaten nutzen, um zu verstehen, welche Inhalte zitiert werden, wie häufig ihre Marke in KI-Antworten erscheint und ob ihre Domain korrekt zugeordnet wird. Diese Erkenntnisse ermöglichen datenbasierte Entscheidungen zur Inhaltsoptimierung, SEO-Strategie und Markenpositionierung in der neuen KI-getriebenen Suchlandschaft. Da Schlussfolgerung zum wichtigsten Weg wird, über den Nutzer Informationen finden, ist die Überwachung Ihrer Präsenz in KI-Ausgaben genauso wichtig wie klassische Suchmaschinenoptimierung.
Der großflächige Einsatz von Schlussfolgerungssystemen bringt zahlreiche technische, operative und strategische Herausforderungen mit sich. Latenzmanagement bleibt ein zentrales Problem, da Nutzer von interaktiven KI-Anwendungen Reaktionen in unter einer Sekunde erwarten, komplexe Modelle mit Milliarden von Parametern aber beträchtliche Rechenzeit benötigen. Durchsatzoptimierung ist ebenso entscheidend – Unternehmen müssen Tausende oder Millionen gleichzeitige Schlussfolgerungsanfragen bedienen und dabei akzeptable Latenz und Genauigkeit aufrechterhalten. Modelldrift tritt auf, wenn die Leistung des Modells in der Schlussfolgerung mit der Zeit nachlässt, weil sich reale Datenverteilungen von den Trainingsdaten entfernen; dies erfordert kontinuierliches Monitoring und regelmäßiges Retraining. Interpretierbarkeit und Erklärbarkeit werden zunehmend wichtig, da Schlussfolgerungssysteme Entscheidungen mit Auswirkungen auf Anwender treffen – Unternehmen müssen verstehen und erklären können, wie Modelle zu bestimmten Vorhersagen gelangen. Regulatorische Anforderungen nehmen zu, etwa durch Vorschriften wie den EU AI Act, der Transparenz, Bias-Erkennung und menschliche Aufsicht für KI-Schlussfolgerungssysteme fordert. Datenqualität ist weiterhin grundlegend – Schlussfolgerungssysteme sind nur so gut wie ihre Trainingsdaten; schlechte Trainingsdaten führen zu verzerrten, ungenauen oder schädlichen Ausgaben. Infrastrukturkosten können erheblich sein, da großflächige Schlussfolgerungseinsätze erhebliche Investitionen in GPUs, TPUs, Netzwerke und Kühlung erfordern. Fachkräftemangel bedeutet, dass Unternehmen Schwierigkeiten haben, Ingenieure und Datenwissenschaftler mit Expertise in Schlussfolgerungsoptimierung, Modellauslieferung und MLOps zu finden – das treibt Gehälter in die Höhe und verzögert Rollouts.
Die Zukunft der KI-Schlussfolgerung entwickelt sich rasant und wird die Art und Weise, wie Unternehmen KI-Systeme einsetzen und nutzen, grundlegend verändern. Edge-Schlussfolgerung – also die Ausführung auf lokalen Geräten statt in der Cloud – nimmt stark zu, getrieben durch Fortschritte bei Modellkomprimierung, spezialisierter Edge-Hardware und Datenschutzanforderungen. Dadurch werden Echtzeit-KI-Fähigkeiten auf Smartphones, IoT-Geräten und autonomen Systemen ohne Cloud-Anbindung möglich. Multimodale Schlussfolgerung, bei der Modelle gleichzeitig Text, Bilder, Audio und Video verarbeiten und generieren, wird immer häufiger und erfordert neue Optimierungsstrategien und Hardware-Überlegungen. Reasoning-Modelle, die mehrstufige Schlussfolgerungen zur Lösung komplexer Probleme durchführen, entstehen – mit Systemen wie OpenAIs o1, die zeigen, dass die Schlussfolgerung selbst durch mehr Rechenzeit und Tokens, nicht nur durch größere Modelle, skalieren kann. Disaggregierte Serving-Architekturen kommen verstärkt zum Einsatz: Separate Hardware-Cluster übernehmen Prefill- und Decode-Phasen, um Ressourcen für unterschiedliche Rechenmuster zu optimieren. Spekulatives Decoding und andere fortschrittliche Techniken werden zum Standard und ermöglichen 2–3-fache Reduzierungen der Latenz. Edge-Schlussfolgerung kombiniert mit föderiertem Lernen wird es Unternehmen ermöglichen, KI-Fähigkeiten lokal bereitzustellen, Privatsphäre zu wahren und Bandbreite zu sparen. Der Markt für KI-Schlussfolgerung wird voraussichtlich mit einer CAGR von 19,2 % bis 2030 wachsen, getrieben durch zunehmende Unternehmensadoption, neue Anwendungsfälle und die wirtschaftliche Notwendigkeit, Schlussfolgerungskosten zu optimieren. Da Schlussfolgerung zur dominierenden Aufgabe in KI-Infrastrukturen wird, werden Optimierungstechniken, spezialisierte Hardware und spezielle Software-Frameworks immer ausgefeilter und entscheidender für den Wettbewerbsvorteil.
KI-Training ist der Prozess, bei dem ein Modell anhand großer Datensätze darauf trainiert wird, Muster zu erkennen. Die KI-Schlussfolgerung hingegen ist der Moment, in dem das trainierte Modell das Gelernte anwendet, um Vorhersagen oder Ausgaben für neue Daten zu generieren. Das Training ist rechnerisch aufwendig und erfolgt einmalig, während die Schlussfolgerung typischerweise schneller, ressourcenschonender und fortlaufend in Produktionsumgebungen stattfindet. Man kann das Training mit dem Lernen für eine Prüfung und die Schlussfolgerung mit dem Ablegen der Prüfung selbst vergleichen.
Die Latenz bei der Schlussfolgerung – also die Zeit, die ein Modell benötigt, um eine Ausgabe zu generieren – ist entscheidend für die Nutzererfahrung und Echtzeitanwendungen. Eine niedrige Latenz ermöglicht sofortige Antworten in Chatbots, Echtzeitübersetzungen, autonomen Fahrzeugen und Betrugserkennungssystemen. Hohe Latenzen können Anwendungen für zeitkritische Aufgaben unbrauchbar machen. Unternehmen optimieren die Latenz mit Techniken wie Quantisierung, Modell-Pruning und spezialisierter Hardware wie GPUs und TPUs, um Service-Level-Agreements einzuhalten.
Die drei wichtigsten Typen sind Batch-Schlussfolgerung (Verarbeitung großer Datensätze offline), Online-Schlussfolgerung (sofortige Vorhersagen auf Anfrage) und Streaming-Schlussfolgerung (kontinuierliche Verarbeitung von Daten aus Sensoren oder IoT-Geräten). Batch-Schlussfolgerung eignet sich für Szenarien wie tägliche Analyse-Dashboards, Online-Schlussfolgerung treibt Chatbots und Suchmaschinen an, und Streaming-Schlussfolgerung ermöglicht Echtzeit-Überwachungssysteme. Jeder Typ hat unterschiedliche Latenzanforderungen und Anwendungsfälle.
Quantisierung reduziert die numerische Präzision der Modellgewichte von 32-Bit auf 8-Bit oder weniger, was die Modellgröße und den Rechenaufwand erheblich verringert, während die Genauigkeit erhalten bleibt. Pruning entfernt nicht-kritische Neuronen oder Verbindungen aus dem neuronalen Netzwerk und reduziert so die Komplexität. Beide Techniken können die Latenz der Schlussfolgerung um 50–80 % senken und die Hardwarekosten reduzieren. Diese Optimierungsmethoden sind unerlässlich für den Einsatz auf Edge-Geräten und mobilen Plattformen.
Schlussfolgerung ist der zentrale Mechanismus, der generativen KI-Systemen die Erzeugung von Text, Bildern und Code ermöglicht. Wenn Sie ChatGPT auffordern, beginnt der Schlussfolgerungsprozess mit der Tokenisierung Ihrer Eingabe, deren Verarbeitung durch die trainierten Schichten des neuronalen Netzes und der sequentiellen Generierung von Ausgabetokens. Die Prefill-Phase verarbeitet alle Eingabetokens gleichzeitig, während die Decode-Phase die Ausgabe schrittweise erzeugt. Diese Schlussfolgerungsfähigkeit macht große Sprachmodelle reaktionsschnell und praxistauglich.
Die Überwachung der Schlussfolgerung verfolgt, wie KI-Modelle in der Produktion hinsichtlich Genauigkeit, Latenz und Ausgabequalität arbeiten. Plattformen wie AmICited überwachen, wo Marken und Domains in KI-generierten Antworten in Systemen wie ChatGPT, Perplexity und Google AI Overviews erscheinen. Das Verständnis des Schlussfolgerungsverhaltens hilft Organisationen sicherzustellen, dass ihre Inhalte korrekt zitiert und dargestellt werden, wenn KI-Systeme Ausgaben generieren, die auf ihre Domains oder Markeninformationen Bezug nehmen.
Gängige Beschleuniger für die Schlussfolgerung sind GPUs (Graphics Processing Units) für parallele Verarbeitung, TPUs (Tensor Processing Units), die für neuronale Netze optimiert sind, FPGAs (Field-Programmable Gate Arrays) für anpassbare Aufgaben und ASICs (Application-Specific Integrated Circuits), die für spezielle Aufgaben entwickelt wurden. GPUs sind am weitesten verbreitet, da sie Leistung und Kosten gut ausbalancieren, während TPUs bei groß angelegter Schlussfolgerung überzeugen. Die Wahl hängt von Durchsatzanforderungen, Latenzvorgaben und Budget ab.
Der globale Markt für KI-Schlussfolgerung hatte 2025 einen Wert von 106,15 Milliarden USD und wird voraussichtlich bis 2030 auf 254,98 Milliarden USD wachsen, was einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 19,2 % entspricht. Dieses schnelle Wachstum spiegelt die zunehmende Nutzung von KI-Anwendungen in Unternehmen wider: 2024 nutzten 78 % der Organisationen KI, gegenüber 55 % im Jahr 2023. Der Anstieg wird durch die Nachfrage nach Echtzeit-KI-Anwendungen in Branchen wie Gesundheitswesen, Finanzen, Einzelhandel und autonomen Systemen getrieben.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Erfahren Sie, was die Entscheidungsphase in der Customer Journey ist. Verstehen Sie, wie die finale Auswahlphase die Markenpräsenz, KI-Suchergebnisse und Konver...
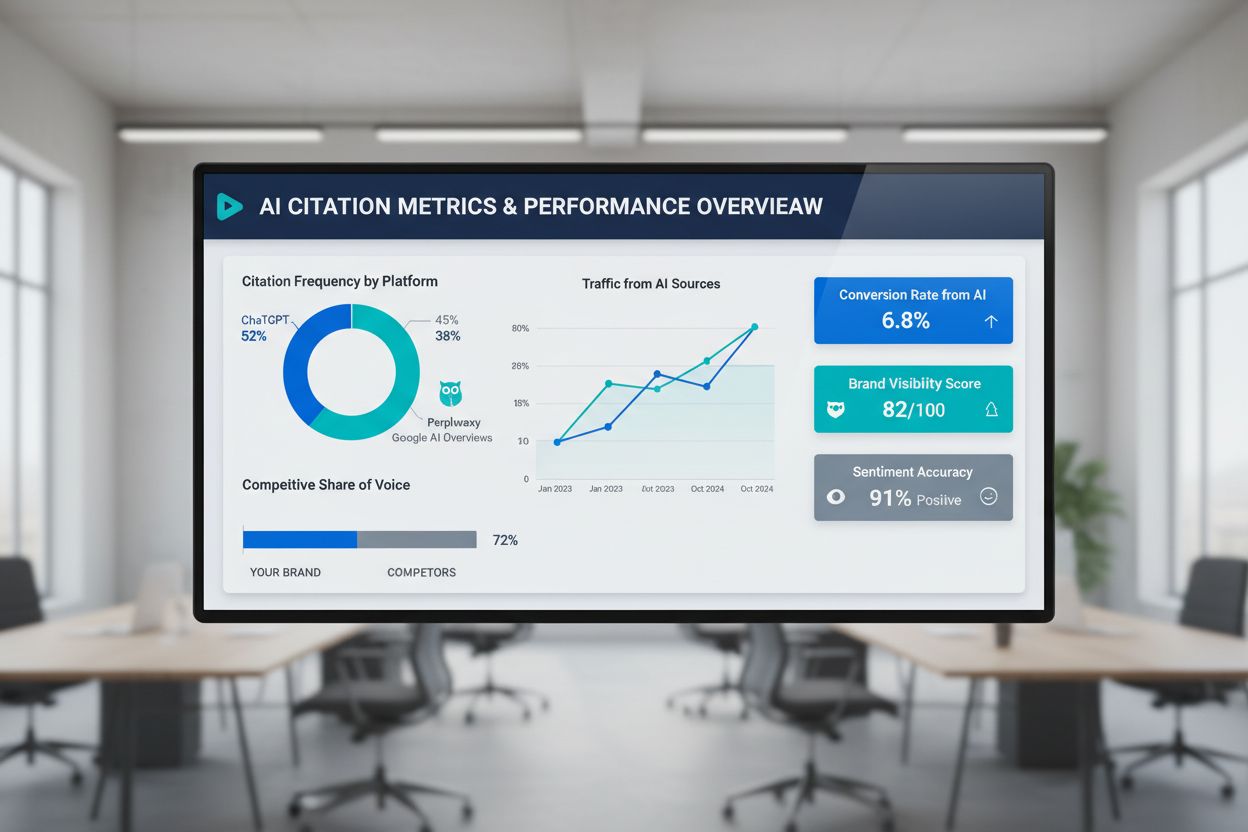
Erfahren Sie, was nachlaufende KI-Indikatoren sind, wie sie sich von führenden Indikatoren unterscheiden und warum das Tracking tatsächlicher Zitationen, KI-Tra...

Definition Feinabstimmung: Anpassung vortrainierter KI-Modelle für spezifische Aufgaben durch domänenspezifisches Training. Erfahren Sie, wie Feinabstimmung die...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.