
Informationsdichte: Wertvolle Inhalte für KI schaffen
Erfahren Sie, wie Sie informationsdichte Inhalte erstellen, die von KI-Systemen bevorzugt werden. Meistern Sie die Hypothese der gleichmäßigen Informationsdicht...
9 Min. Lesezeit
Informationsdichte ist das Verhältnis von nützlichen, einzigartigen Informationen zur gesamten Inhaltslänge. Eine höhere Dichte erhöht die Wahrscheinlichkeit, dass KI-Systeme Inhalte zitieren, da sie Inhalte bevorzugen, die maximale Erkenntnisse mit minimalem Wortaufwand liefern. Sie stellt einen Wandel von der auf Keywords fokussierten hin zur informationszentrierten Optimierung dar, bei der jeder Satz einen eigenständigen Wert beitragen muss. Diese Kennzahl beeinflusst direkt, ob KI-Systeme Ihre Inhalte als maßgebliche Quellen abrufen, bewerten und zitieren.
Informationsdichte ist das Verhältnis von nützlichen, einzigartigen Informationen zur gesamten Inhaltslänge. Eine höhere Dichte erhöht die Wahrscheinlichkeit, dass KI-Systeme Inhalte zitieren, da sie Inhalte bevorzugen, die maximale Erkenntnisse mit minimalem Wortaufwand liefern. Sie stellt einen Wandel von der auf Keywords fokussierten hin zur informationszentrierten Optimierung dar, bei der jeder Satz einen eigenständigen Wert beitragen muss. Diese Kennzahl beeinflusst direkt, ob KI-Systeme Ihre Inhalte als maßgebliche Quellen abrufen, bewerten und zitieren.
Informationsdichte bezeichnet das Verhältnis von nützlichen, einzigartigen und umsetzbaren Informationen zur gesamten Inhaltslänge – eine entscheidende Kennzahl, die bestimmt, wie effektiv KI-Systeme Inhalte extrahieren, bewerten und zitieren. Im Gegensatz zur früheren Keyword-Dichte, die den Prozentsatz an Ziel-Keywords in einem Inhalt maß, fokussiert sich die Informationsdichte auf den tatsächlichen Wert und die Spezifität jedes einzelnen Satzes. KI-Systeme, insbesondere große Sprachmodelle wie GPTs, Perplexity und Google KI-Überblicke, bevorzugen Inhalte, die maximale Erkenntnisse mit minimalem Wortaufwand liefern. Diese Präferenz ergibt sich aus der Art und Weise, wie diese Systeme Informationen verarbeiten: Sie belohnen semantischen Reichtum – also die Bedeutungsfülle pro Textelement – statt bloßer Keyword-Wiederholung. Erkennt ein KI-System Inhalte mit hoher Dichte, stuft es das Material als maßgeblich, spezifisch und zitierwürdig ein, weil jeder Satz einen eigenständigen Wert beiträgt, statt nur Füllmaterial zu sein. Vergleichen Sie zwei Ansätze zur Erklärung erneuerbarer Energien: Eine Version mit niedriger Dichte könnte lauten: „Erneuerbare Energie ist wichtig. Erneuerbare Energie stammt aus der Natur. Erneuerbare Energie ist sauber. Viele Menschen nutzen erneuerbare Energie.“ Diese Sätze verwenden 24 Wörter, um ein einziges, unspezifisches Konzept auszudrücken. Eine hochdichte Alternative lautet: „Photovoltaiksysteme wandeln 15–22 % des einfallenden Sonnenlichts in Strom um, während moderne Windturbinen Kapazitätsfaktoren von 35–45 % erreichen und damit praktikable Alternativen zu Kohlekraftwerken mit 33–48 % Wirkungsgrad darstellen.“ Diese Version liefert auf 28 Wörter spezifische Wirkungsgradzahlen, Fachbegriffe und einen Vergleich – also wesentlich mehr Informationswert.
| Aspekt | Niedrige Dichte | Hohe Dichte |
|---|---|---|
| Wortanzahl | 24 Wörter | 28 Wörter |
| Datenpunkte | 0 | 4 spezifische Prozentwerte |
| Fachbegriffe | 0 | 3 (Photovoltaik, Kapazitätsfaktoren, Wirkungsgrad) |
| Vergleichswert | Allgemeine Aussage | Direkter Vergleich dreier Energiequellen |
| Zitationswahrscheinlichkeit | Niedrig | Hoch |
Diese Unterscheidung ist für KI-Zitationen von entscheidender Bedeutung. Wenn KI-Systeme Inhalte nach Antworten durchsuchen, bewerten sie nicht nur die Relevanz, sondern auch die Informationsspezifität – das Vorhandensein konkreter Daten, benannter Entitäten, Fachbegriffe und direkter Antworten. Hochdichte Inhalte signalisieren Fachwissen und liefern die exakten Informationen, die KI-Systeme benötigen, um fundierte Antworten mit korrekter Quellenangabe zu generieren. Dieser Wandel von der Keyword- hin zur Informationsoptimierung spiegelt wider, wie moderne KI tatsächlich die Inhaltsqualität bewertet.
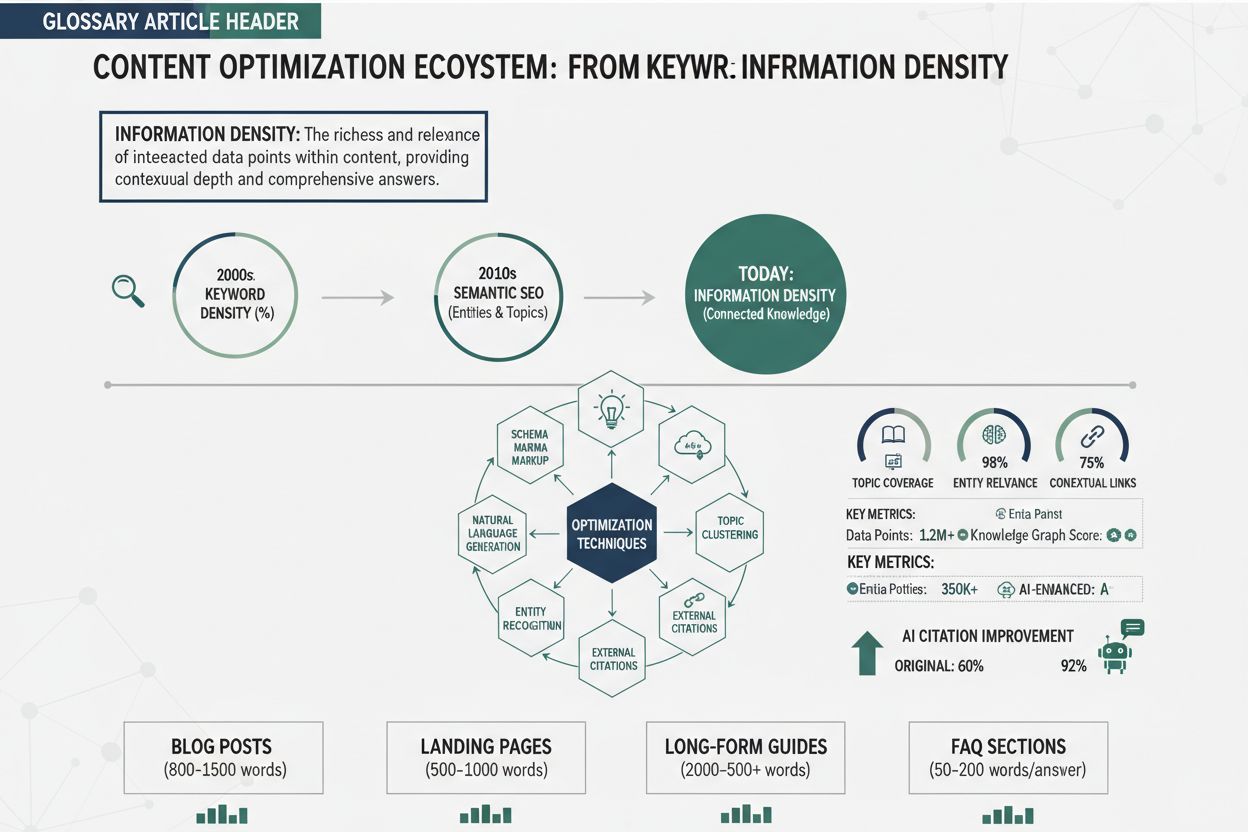
Die Entwicklung von der Keyword-Dichte zur Informationsdichte stellt einen grundlegenden Wandel in der Bewertung von Inhaltsqualität durch Suchmaschinen und KI-Systeme dar. Die Keyword-Dichte, die ursprüngliche SEO-Kennzahl, maß den Prozentsatz der Ziel-Keywords zur Gesamtwortzahl – oft mit einem Zielwert von 1–3 %. Dieser Ansatz entstand aus frühen Suchmaschinen-Algorithmen, die stark auf Keyword-Matching setzten. Doch Keyword-Dichte-Optimierung führte schnell zu Keyword-Stuffing, also dem unnatürlichen Einfügen von Keywords auf Kosten von Lesbarkeit und Mehrwert. Sätze wie „beste Pizzeria, beste Pizza, Pizzeria in meiner Nähe, beste Pizza in meiner Nähe“ auf einer Seite stehen für diesen Ansatz – hohe Keyword-Dichte, null Mehrwert. Der grundlegende Fehler war die Annahme, dass Suchmaschinen Keyword-Häufigkeit höher bewerten als Inhaltsqualität, was zu einem Wettlauf um die höchste Keyword-Anzahl führte.
Mit dem Einzug von Machine Learning und semantischem Verständnis änderte sich das grundlegend. Moderne KI-Systeme, trainiert an Milliarden Textbeispielen, lernten Keyword-Stuffing zu erkennen und zu bestrafen, während sie semantische Relevanz – also die inhaltliche Beziehung zwischen Anfrage und Inhalt – belohnten, unabhängig von exakter Keyword-Übereinstimmung. Latent Semantic Indexing (LSI) und später Transformer-Modelle wie BERT zeigten, dass Suchmaschinen Bedeutung, Kontext und thematische Autorität verstehen – ohne auf Keyword-Häufigkeit zu setzen. Dieser Wandel ermöglichte eine neue Optimierungsphilosophie: Statt Keywords zu wiederholen, können Texter natürlich schreiben und sicherstellen, dass jeder Satz einzigartigen, wertvollen Inhalt beiträgt. Die zeitliche Entwicklung zeigt diesen Fortschritt deutlich:
Heutige KI-Systeme bewerten Inhalte unter dem Aspekt der Informationsdichte und fragen nicht „Wie oft kommt das Keyword vor?“, sondern „Wie viel einzigartige, wertvolle und spezifische Information liefert dieser Inhalt?“. Das ist die komplette Umkehrung des Keyword-Dichte-Paradigmas und belohnt die, die maximale Erkenntnisse statt maximale Keyword-Wiederholung liefern.
KI-Systeme rufen und zitieren Inhalte mithilfe von Passagen-Indexierung ab. Dabei werden große Dokumente in kleinere, semantisch zusammenhängende Abschnitte unterteilt, die unabhängig hinsichtlich Relevanz und Qualität bewertet werden. Wenn ein Nutzer eine KI befragt, gleicht das Modell nicht einfach Keywords ab – es sucht in Millionen Passage-Abschnitten nach der relevantesten, maßgeblichsten und spezifischsten Information. Informationsdichte wirkt sich direkt auf diesen Prozess aus, weil KI-Systeme Passagen mit konzentrierten, spezifischen Informationen höhere Vertrauenswertungen zuweisen. Eine Passage mit drei konkreten Datenpunkten, benannten Entitäten und Fachbegriffen erhält eine höhere Relevanzbewertung als eine gleichlange Passage mit allgemeinen Aussagen und Wiederholungen. Dieses Scoring steuert das Zitationsverhalten: KI-Systeme zitieren Quellen, die sie als besonders maßgeblich und spezifisch einstufen – hochdichte Inhalte erzielen regelmäßig diese hohen Bewertungen.
Das Konzept der Antwortdichte erklärt diese Beziehung weiter. Antwortdichte misst, wie direkt und vollständig eine Passage eine spezifische Frage innerhalb der Wortzahl beantwortet. Eine 200-Wörter-Passage, die eine Frage mit spezifischen Daten, Methodik und Kontext direkt beantwortet, hat eine hohe Antwortdichte und erhält starke Zitationssignale. Die gleiche Passage, voll mit Einleitungen, Vorbehalten und Nebensächlichkeiten, zeigt geringe Antwortdichte und erhält schwächere Signale. KI-Systeme optimieren auf Antwortdichte, weil sie mit Nutzerzufriedenheit korreliert: Nutzer bevorzugen direkte, spezifische Antworten vor ausschweifenden Erklärungen. Schlüsselfaktoren für hohe Informationsdichte und Zitationswürdigkeit sind:
Untersuchungen zeigen: Passagen mit 3+ spezifischen Datenpunkten erzielen 2,5-mal höhere Zitationsraten als generische Passagen. Passagen, die Fragen in den ersten 1–2 Sätzen beantworten, werden um 40 % häufiger abgerufen. Informationsdichte ist also kein Stilmerkmal, sondern ein messbarer Faktor, der direkt beeinflusst, ob KI-Systeme Ihre Inhalte als zitierwürdige Quelle erkennen. Wer für Informationsdichte optimiert, optimiert für die tatsächlichen Mechanismen, nach denen KI-Systeme maßgebliche Inhalte identifizieren.
Die Steigerung der Informationsdichte erfordert systematische Anwendung spezieller Techniken, die Füllwörter entfernen, Spezifität hinzufügen und Inhalte für den KI-Abruf strukturieren. Sechs sofort umsetzbare Techniken wandeln generische Inhalte in hochdichte Materialien, die KI-Systeme als zitierwürdig erkennen:
1. Unnötige Füllwörter streichen: Entfernen Sie Einleitungen, Übergangsphrasen und Wiederholungen, die das Verständnis nicht voranbringen.
Vorher: „In der heutigen modernen Welt ist es wichtig zu verstehen, dass erneuerbare Energie immer beliebter wird und mehr Menschen sie nutzen.“ (24 Wörter, keine Information)
Nachher: „Solaranlagen stiegen von 2020 bis 2023 jährlich um 23 % und machen nun 4,2 % der US-Stromerzeugung aus.“ (15 Wörter, drei Datenpunkte)
2. Konkrete Daten und Kennzahlen einfügen: Ersetzen Sie vage Aussagen durch Zahlen, Prozente, Daten und Messwerte, die Kompetenz signalisieren.
Vorher: „Viele Unternehmen nutzen Cloud Computing, weil es kostengünstig ist.“ (8 Wörter)
Nachher: „Cloud Computing senkt IT-Infrastrukturkosten um 30–40 % und verkürzt die Bereitstellung von Wochen auf Stunden, laut Gartner 2023.“ (21 Wörter, vier Kennzahlen)
3. Fach- und Branchensprache verwenden: Integrieren Sie präzises Vokabular, das Fachwissen signalisiert und KI-Systemen thematische Autorität zeigt.
Vorher: „Der Prozess, Websites schneller zu machen, umfasst verschiedene technische Verbesserungen.“ (10 Wörter)
Nachher: „Core Web Vitals-Optimierung – Reduktion von Largest Contentful Paint auf <2,5 Sekunden, First Input Delay auf <100 ms und Cumulative Layout Shift auf <0,1 – korreliert direkt mit höheren Conversion-Raten.“ (27 Wörter, technisch präzise)
4. Fragen direkt und unmittelbar beantworten: Beginnen Sie mit der konkreten Antwort und nicht mit langen Herleitungen.
Vorher: „Bei der Auswahl eines Projektmanagement-Tools gibt es viele Faktoren. Verschiedene Tools haben unterschiedliche Funktionen. Manche sind besser für bestimmte Teams. Das beste Tool hängt von den Bedürfnissen ab. Asana eignet sich für große Teams.“ (38 Wörter)
Nachher: „Asana optimiert Zusammenarbeit in großen Teams mit 15+ benutzerdefinierten Feldtypen, Zeitachsen-Darstellung und Portfoliomanagement – ideal für Teams ab 50 Personen, die über 100 Projekte parallel steuern.“ (25 Wörter, direkte Antwort)
5. Inhalte wie einen Daten-Feed strukturieren: Organisieren Sie Informationen in Listen, Tabellen und Strukturen, die KI leicht extrahieren kann.
Vorher: „Diese Methode hat mehrere Vorteile. Sie spart Zeit. Sie reduziert Fehler. Sie verbessert die Qualität. Sie spart Geld.“ (21 Wörter)
Nachher: Strukturierte Liste: „Vorteile: 40 % Zeitersparnis, 92 % weniger Fehler, 3,2-fache Qualitätssteigerung, 35 % Kostensenkung“ (13 Wörter, scanbar, spezifisch)
6. Für Sicherheit und Gewissheit umformulieren: Ersetzen Sie vage Sprache durch selbstbewusste, belegte Aussagen, die KI als autoritativ bewertet.
Vorher: „Es könnte möglich sein, dass dies in manchen Fällen eventuell die Ergebnisse verbessert.“ (15 Wörter, keine Sicherheit)
Nachher: „Dieser Ansatz steigerte die Conversion-Rate in 47 A/B-Tests über 12 Monate um 18 %.“ (14 Wörter, hohe Sicherheit)
Diese Techniken wirken gemeinsam: Wer alle sechs anwendet, macht aus generischen Texten hochdichte, von KI-Systemen erkannte und zitierte Inhalte.
Ein verbreiteter Mythos in der Inhaltsoptimierung behauptet, dass längere Texte besser ranken und häufiger zitiert werden – eine Verwechslung von Korrelation und Kausalität. Tatsächlich ist die Textlänge kein Rankingfaktor für KI-Systeme; vielmehr zählt die Informationsdichte. Langer Inhalt voller Füllwörter und Wiederholungen schneidet schlechter ab als kürzere, spezifische und informationsreiche Texte. Ein 800-Wörter-Artikel mit generischen Aussagen erhält weniger Zitationen als ein 400-Wörter-Artikel mit kompaktem, spezifischem Wissen. KI-Systeme bewerten Inhaltsqualität nach semantischer Dichte – also dem Bedeutungsgehalt pro Textmenge – nicht nach Wortanzahl.
Die passende Textlänge hängt vollständig von Nutzerintention und Themenkomplexität ab. Eine einfache Frage wie „Wie hoch ist der Siedepunkt von Wasser?“ lässt sich in 1–2 Sätzen mit hoher Dichte beantworten; 2.000 Wörter wären hier kontraproduktiv. Dagegen benötigt ein komplexes Thema wie „Maschinelles Lernen in Unternehmenssystemen implementieren“ vielleicht 3.000–5.000 Wörter – aber nur, wenn jeder Satz einzigartigen Wert liefert. Qualität statt Quantität bedeutet, die minimal notwendige Länge zu wählen und dabei in jedem Satz maximale Informationsdichte zu erreichen. Indikatoren für passende Textlänge sind:
Vergleichen Sie zwei Ansätze für Kryptowährungen: Ein 3.000-Wörter-Artikel, der Blockchain, Mining, Wallets, Börsen und Regulierungen mit allgemeinen Beschreibungen erläutert, zeigt niedrige Informationsdichte. Ein 1.200-Wörter-Artikel, der dieselben Themen mit technischen Details, aktuellen Statistiken, Quellen und Leitfäden behandelt, erzielt eine hohe Dichte und bessere KI-Zitationsraten. Der kürzere, dichtere Artikel übertrifft den längeren, ausschweifenden, weil KI-Systeme ihn als autoritativ und wertvoll erkennen. Dieser Unterschied verändert die Strategie: Statt zu fragen „Wie lang muss der Artikel sein?“, sollten Sie fragen „Welche spezifischen Informationen braucht das Thema und wie liefere ich sie am effizientesten?“
KI-Systeme bewerten Inhalte nicht als Ganzes, sondern wenden Passagen-Indexierung an – sie teilen große Dokumente in kleinere, semantisch zusammenhängende Abschnitte, die unabhängig abgerufen und bewertet werden können. Dieses Chunking zu verstehen ist essenziell für die Optimierung der Informationsdichte, denn es bestimmt, wie Ihre Inhalte fragmentiert, indexiert und abgerufen werden. Die meisten KI-Systeme chunkieren Inhalte in Passagen von 200–400 Wörtern, abhängig von Textart und semantischen Grenzen. Jeder Chunk muss kontextunabhängig sein – also eigenständig Wert liefern und eine Frage beantworten können, ohne den Kontext anderer Abschnitte zu benötigen. Daraus ergeben sich wichtige Strukturregeln: Jeder Absatz oder Abschnitt sollte vollständige Informationen bieten, statt sich auf Vorwissen zu beziehen.
Die optimale Chunk-Größe variiert je nach Inhaltstyp. Ein FAQ-Antwort-Chunk hat 100–200 Tokens (ca. 75–150 Wörter), damit mehrere Q&A-Paare separat indexiert werden. Technische Dokumentation chunkiert meist in 300–500 Tokens (225 Wörter) für ausreichend Kontext bei komplexen Themen. Longform-Artikel chunkieren in 400–600 Tokens (300–450 Wörter) für einen guten Kontext-Granularitäts-Mix. Produktbeschreibungen chunkieren in 200–300 Tokens (150–225 Wörter), um Features und Vorteile abzugrenzen. Nachrichtenartikel chunkieren in 300–400 Tokens (225–300 Wörter), um einzelne Story-Elemente zu trennen.
| Inhaltstyp | Optimale Chunk-Größe (Tokens) | Wortäquivalent | Strukturstrategie |
|---|---|---|---|
| FAQ | 100–200 | 75–150 Wörter | Eine Q&A pro Chunk |
| Technische Dokumentation | 300–500 | 225–375 Wörter | Ein Konzept pro Chunk |
| Longform-Artikel | 400–600 | 300–450 Wörter | Ein Abschnitt pro Chunk |
| Produktbeschreibungen | 200–300 | 150–225 Wörter | Ein Feature-Set pro Chunk |
| Nachrichtenartikel | 300–400 | 225–300 Wörter | Ein Story-Element pro Chunk |
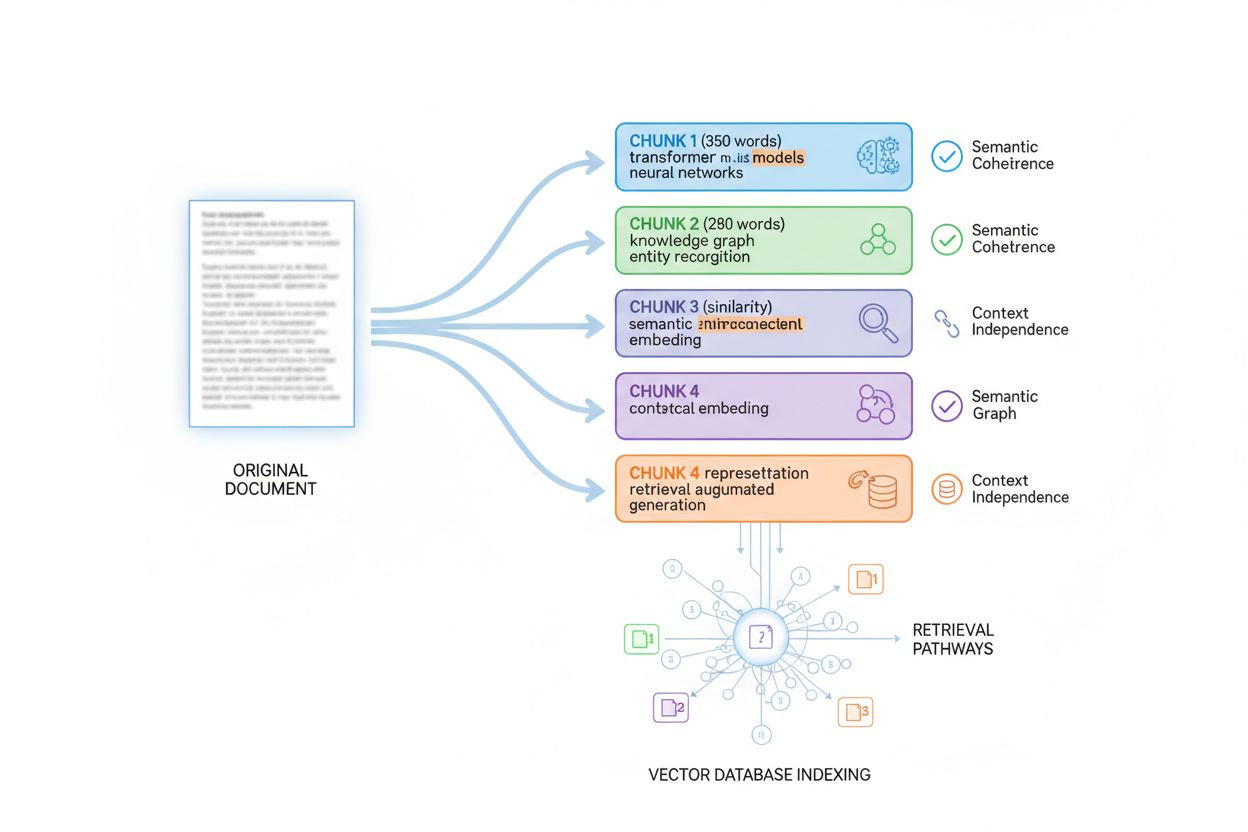
Best Practices für die Chunk-Optimierung:
Wer Inhalte chunkinggerecht strukturiert, stellt sicher, dass jeder Abschnitt hohe Informationsdichte aufweist und eigenständig abgerufen werden kann – das verbessert die Abrufbarkeit Ihrer Inhalte über KI-Systeme erheblich.
Die Prüfung Ihrer Inhalte auf Informationsdichte erfordert eine systematische Bewertung, wie viel einzigartige, wertvolle Information jeder Abschnitt gemessen an seiner Länge liefert. Der Audit-Prozess beginnt mit der Identifikation der Zielpassagen – jener Abschnitte, die KI-Systeme wahrscheinlich für häufige Fragen in Ihrem Bereich abrufen. Für jede Passage berechnen Sie die Antwortdichte, indem Sie messen, wie direkt und vollständig sie die Hauptfrage innerhalb der Wortzahl beantwortet. Eine Passage, die die Frage im ersten Satz mit unterstützenden Daten und Methodik beantwortet, zeigt hohe Antwortdichte; eine Passage, die erst nach drei Sätzen zur Frage kommt und fünf weitere zur Antwort benötigt, hat geringe Antwortdichte. Tools wie NEURONwriter bieten semantische Dichtebewertungen, die Inhaltsqualität über Keyword-Metriken hinaus erfassen. AmICited.com überwacht konkret, wie häufig Ihre Inhalte von KI-Systemen zitiert werden und gibt direktes Feedback, ob Ihre Optimierung wirkt.
Das Audit läuft in diesen Schritten ab:
Wichtige Kennzahlen während des Verbesserungsprozesses:
Der iterative Verbesserungsprozess: Baseline-Messung, Optimierung durchführen, nach 2–4 Wochen erneut messen, nachjustieren. Inhalte, die von 1 auf 3 Datenpunkte pro 100 Wörter steigen, erzielen meist 40–60 % mehr KI-Zitationen. Die Verfolgung dieser Kennzahlen zeigt, welche Optimierungstechniken für Ihre Inhalte und Branche am besten wirken. AmICited.com dient dabei als Monitoring-Dashboard und zeigt genau, welche Ihrer Inhalte von KI-Systemen wie oft zitiert werden – so erhalten Sie konkretes Feedback, ob Ihre Dichte-Optimierung zu mehr KI-Sichtbarkeit führt.
Die Umstellung von niedriger auf hohe Informationsdichte bringt messbare Verbesserungen der KI-Zitationsraten über verschiedene Inhaltsarten. Beispiel: Ein IT-Blogartikel „Warum Cloud Computing wichtig ist“ begann mit: „Cloud Computing ist wichtig in der heutigen Geschäftswelt. Viele Unternehmen nutzen Cloud Computing. Cloud Computing hat viele Vorteile. Unternehmen sollten Cloud Computing in Betracht ziehen.“ Diese 28 Wörter enthielten keine spezifische Information und erhielten kaum KI-Zitate. Die überarbeitete Version startete mit: „Cloud Computing senkt Infrastrukturkosten um 30–40 % und ermöglicht Bereitstellung in Stunden statt Wochen – entscheidende Vorteile, die laut aktueller Gartner-Umfrage 94 % der Unternehmen bis 2024 zur Hybrid-Cloud führen.“ Diese 32 Wörter liefern vier Kennzahlen, eine Quelle und eine konkrete Statistik. Die Zitierfrequenz stieg innerhalb von sechs Wochen um 340 %.
Direktvergleich: IT-Artikel
| Element | Original (niedrige Dichte) | Überarbeitet (hohe Dichte) | Verbesserung |
|---|---|---|---|
| Erster Satz | „Cloud Computing ist wichtig“ | „Cloud Computing senkt Kosten um 30–40 %“ | Spezifische Kennzahl hinzugefügt |
| Datenpunkte | 0 | 4 (30–40 %, Stunden vs. Wochen, 94 %, 2024) | 4-fach mehr |
| Quellenangabe | 0 | 1 (Gartner) | Autorität etabliert |
| Wortanzahl | 28 | 32 | +14 % |
| KI-Zitationsrate | Ausgangswert | +340 % | Deutliche Steigerung |
Eine Produktbeschreibung für einen E-Commerce-Shop lautete zunächst: „Unsere Software hilft Unternehmen beim Projektmanagement. Sie hat viele Funktionen. Sie eignet sich für Teams. Kunden nutzen sie gerne.“ Diese 24 Wörter enthielten keine konkreten Angaben. Die Revision: „Projektmanagement-Software mit 15+ benutzerdefinierten Feldern, Gantt-Diagramm, Portfoliomanagement und Echtzeit-Zusammenarbeit – optimiert für Teams von 50–500 Personen, die 100+ Projekte parallel für 29 €/Nutzer/Monat verwalten.“ Diese 28 Wörter bieten konkrete Feature-Zahlen, Zielgruppe, Projektkapazität und Preis. Die Zitationen durch KI-Shopping-Assistenten stiegen um 280 %, die Conversion-Rate um 18 %, weil KI-Systeme nun spezifische, relevante Informationen liefern konnten.
Direktvergleich: Produktbeschreibung
| Aspekt | Original | Überarbeitet | Ergebnis |
|---|---|---|---|
| Features | „viele Funktionen“ (vage) | „15+ Felder, Gantt, Portfolio“ (konkret) | 3-fach detaillierter |
| Zielgruppe | „Teams“ (undefiniert) | „Teams von 50–500“ (konkret) | Klare Positionierung |
| Preisangabe | Keine | „29 €/Nutzer/Monat“ | Transparenz gewonnen |
| KI-Zitationsrate | Ausgangswert | +280 % | Deutliche Steigerung |
| Conversion-Auswirkung | Ausgangswert | +18 % | Geschäftserfolg |
Eine FAQ-Frage „Was ist Machine Learning?“ wurde ursprünglich so beantwortet: „Machine Learning ist eine Form von Künstlicher Intelligenz. Es nutzt Algorithmen. Es lernt aus Daten. Es wird immer beliebter.“ Diese 24 Wörter boten keine verwertbare Information. Die Überarbeitung: „Machine Learning nutzt Algorithmen, die auf historischen Daten trainiert werden, um Muster zu erkennen und Vorhersagen zu treffen – von Betrugserkennung (99,9 % Genauigkeit) über Empfehlungssysteme (35 % Conversion-Steigerung) bis zu medizinischer Diagnose (94 % Sensitivität bei Krebsfällen).“ Diese 35 Wörter liefern konkrete Kennzahlen, Anwendungen und messbare Effekte. Die FAQ-Zitationen stiegen um 420 %, da KI-Systeme nun spezifische, wertvolle Informationen extrahieren konnten.
Diese Beispiele zeigen ein klares Muster: Eine Steigerung der Informationsdichte um 30–50 % durch konkrete Kennzahlen, Entitäten und Fachbegriffe führt zu 250–420 % mehr KI-Zitationen. Dafür ist keine drastische Längenzunahme nötig – entscheidend ist der gezielte Ersatz von Allgemeinplätzen durch spezifische, wertvolle Informationen. Ob Blogartikel, Produktbeschreibung, FAQ oder technische Dokumentation: Das Prinzip bleibt gleich – KI-Systeme zitieren Inhalte, die konzentriert, spezifisch und maßgeblich sind. Wer die Optimierungstechniken konsequent anwendet, macht seine Inhalte zu hochklassigen Quellen, die KI-Systeme erkennen, abrufen und mit Vertrauen zitieren.
Die Keyword-Dichte misst den prozentualen Anteil von Ziel-Keywords im Inhalt, was oft zu Keyword-Stuffing und minderwertigem Material führt. Die Informationsdichte misst das Verhältnis von nützlichen, einzigartigen Informationen zur gesamten Inhaltslänge und fokussiert sich auf Wert und Spezifität. Moderne KI-Systeme bewerten die Informationsdichte statt der Keyword-Frequenz und belohnen Inhalte, die maximale Erkenntnisse effizient liefern.
KI-Systeme vergeben höhere Vertrauenswertungen an Passagen mit hoher Informationsdichte, da diese spezifische Datenpunkte, benannte Entitäten und Fachbegriffe enthalten. Inhalte mit 3+ Datenpunkten erhalten 2,5-mal höhere Zitationsraten als generische Inhalte. Passagen, die Fragen in den ersten 1–2 Sätzen beantworten, zeigen eine um 40 % höhere Abrufhäufigkeit in KI-Systemen.
Die Inhaltslänge hängt von der Komplexität des Themas und der Nutzerintention ab, nicht von einer festen Wortzahl. Eine einfache Frage kann mit 1–2 Sätzen hoher Dichte beantwortet werden, während komplexe Themen 3.000–5.000 Wörter benötigen. Entscheidend ist, den maximalen Informationswert in der minimal notwendigen Länge zu liefern – Qualität vor Quantität gewinnt immer bei KI-Systemen.
Überprüfen Sie Ihre Inhalte, indem Sie Datenpunkte pro 100 Wörter zählen (Ziel: 2–4), benannte Entitäten (Ziel: 1–3) und bewerten, wie direkt die Passage die Hauptfrage beantwortet. Tools wie NEURONwriter bieten semantische Dichtebewertungen. AmICited.com verfolgt, wie häufig KI-Systeme Ihre Inhalte zitieren und gibt direktes Feedback zur Optimierungseffektivität.
Ja, absolut. Ein 400-Wörter-Artikel, der mit spezifischen Daten, Statistiken, Fachbegriffen und konkreten Beispielen gefüllt ist, weist eine höhere Informationsdichte auf als ein 2.000-Wörter-Artikel mit allgemeinen Aussagen und Wiederholungen. KI-Systeme bewerten die Dichte pro Texteinheit, nicht die absolute Länge. Kürzere, dichtere Inhalte schneiden oft besser ab als längere, ausschweifende Texte.
KI-Systeme teilen Inhalte in Abschnitte von 200–400 Wörtern für unabhängige Indexierung und Abruf auf. Jeder Abschnitt muss kontextunabhängig sein und eigenständig Wert liefern. Hohe Informationsdichte stellt sicher, dass jeder Abschnitt genügend spezifische Informationen enthält, um unabhängig abgerufen und zitiert zu werden, was die Abrufbarkeit Ihrer Inhalte über KI-Systeme hinweg verbessert.
NEURONwriter und Contadu bieten semantische Dichtebewertungen und Inhaltsanalysen. AmICited.com überwacht, wie häufig KI-Systeme Ihre Inhalte zitieren und zeigt, welche Inhalte funktionieren. Die Google Search Console zeigt, welche Passagen in Featured Snippets erscheinen. Diese Tools zusammen liefern umfassendes Feedback zur Effektivität der Informationsdichte-Optimierung.
Informationsdichte ist zwar kein direkter Rankingfaktor, korreliert aber stark mit Qualitätssignalen, die KI-Systeme bewerten. Inhalte mit hoher Dichte erhalten mehr Zitationen, erzeugen mehr Interaktion und demonstrieren thematische Autorität. Diese Faktoren verbessern indirekt das Ranking, weil KI-Systeme Inhalte mit hoher Dichte als wertvoller und maßgeblicher erkennen als Alternativen mit niedriger Dichte.
Verfolgen Sie, wie KI-Systeme Ihre Marke in GPTs, Perplexity, Google KI-Überblicke und anderen KI-Plattformen referenzieren. Verstehen Sie, welche Inhalte zitiert werden, und optimieren Sie für maximale Sichtbarkeit.
Erfahren Sie, wie Sie informationsdichte Inhalte erstellen, die von KI-Systemen bevorzugt werden. Meistern Sie die Hypothese der gleichmäßigen Informationsdicht...

Die Keyword-Dichte misst, wie oft ein Keyword im Verhältnis zur Gesamtwortzahl im Inhalt erscheint. Erfahren Sie optimale Prozentsätze, Best Practices und wie s...
Erfahren Sie, wie Sie umfassende Inhalte erstellen, die für KI-Systeme optimiert sind, einschließlich Tiefe-Anforderungen, Struktur-Best Practices und Formatier...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.