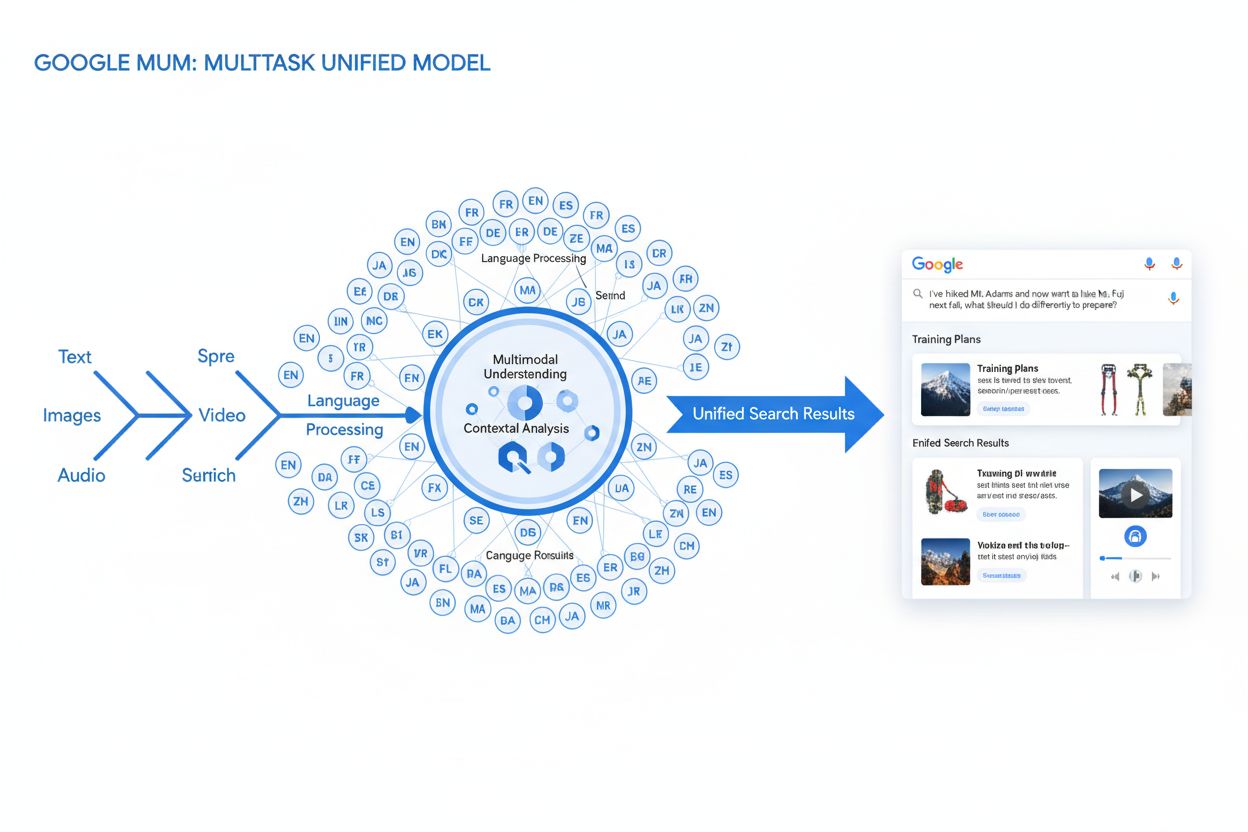
Definition von MUM (Multitask Unified Model)
MUM (Multitask Unified Model) ist Googles fortschrittliches multimodales KI-Modell, das darauf ausgelegt ist, die Art und Weise zu revolutionieren, wie Suchmaschinen komplexe Nutzeranfragen verstehen und beantworten. Vorgestellt im Mai 2021 von Pandu Nayak, Google Fellow und Vice President of Search, stellt MUM einen grundlegenden Wandel in der Informationstechnologie für die Suche dar. Basierend auf dem T5-Text-zu-Text-Framework und bestehend aus etwa 110 Milliarden Parametern ist MUM 1.000-mal leistungsfähiger als BERT, Googles bisheriges bahnbrechendes Modell für natürliche Sprachverarbeitung. Im Gegensatz zu traditionellen Suchalgorithmen, die Text isoliert verarbeiten, verarbeitet MUM gleichzeitig Text, Bilder, Videos und Audio und versteht Informationen nativ in über 75 Sprachen. Diese multimodalen und mehrsprachigen Fähigkeiten ermöglichen es MUM, komplexe Anfragen zu erfassen, für die Nutzer zuvor mehrere Suchen durchführen mussten – und verwandeln die Suche von einer einfachen Stichwortsuche in ein intelligentes, kontextbewusstes Informationssystem. MUM versteht nicht nur Sprache, sondern generiert sie auch und kann so Informationen aus verschiedenen Quellen und Formaten zusammenfassen, um umfassende, nuancierte Antworten zu liefern, die die gesamte Nutzerintention abdecken.
Historischer Kontext und Entwicklung von Googles KI-Modellen
Googles Weg zu MUM ist das Ergebnis jahrelanger schrittweiser Innovationen im Bereich der natürlichen Sprachverarbeitung und des maschinellen Lernens. Die Entwicklung begann mit Hummingbird (2013), das semantisches Verständnis einführte, um die Bedeutung hinter Suchanfragen zu interpretieren, statt nur Stichwörter abzugleichen. Es folgte RankBrain (2015), das maschinelles Lernen nutzte, um Long-Tail-Keywords und neue Suchmuster zu verstehen. Neural Matching (2018) ging noch einen Schritt weiter und setzte neuronale Netze ein, um Suchanfragen und relevante Inhalte auf einer tieferen semantischen Ebene abzugleichen. BERT (Bidirectional Encoder Representations from Transformers), eingeführt 2019, war ein wichtiger Meilenstein, da es Kontext innerhalb von Sätzen und Absätzen verstand und Googles Fähigkeit verbesserte, nuancierte Sprache zu interpretieren. BERT hatte jedoch erhebliche Einschränkungen – es verarbeitete nur Text, hatte eine begrenzte Mehrsprachigkeit und konnte keine komplexen Anfragen bewältigen, die die Synthese von Informationen aus mehreren Formaten erforderten. Laut Google recherchieren Nutzer im Durchschnitt acht separate Anfragen, um komplexe Fragen zu beantworten, wie etwa der Vergleich zweier Wanderziele oder die Bewertung von Produktoptionen. Diese Statistik verdeutlichte eine entscheidende Lücke, die MUM gezielt schließt. Das Helpful Content Update (2022) und das E-E-A-T-Framework (2023) verfeinerten zudem, wie Google autoritative, vertrauenswürdige Inhalte priorisiert. MUM baut auf all diesen Innovationen auf und bringt Fähigkeiten ein, die frühere Grenzen überwinden – und stellt so nicht nur eine Weiterentwicklung, sondern einen Paradigmenwechsel in der Verarbeitung und Bereitstellung von Informationen durch Suchmaschinen dar.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technische Architektur und multimodale Verarbeitung
Die technische Grundlage von MUM basiert auf der Transformer-Architektur, insbesondere dem T5 (Text-to-Text Transfer Transformer) Framework, das Google zuvor entwickelt hat. Das T5-Framework behandelt alle Aufgaben der natürlichen Sprachverarbeitung als Text-zu-Text-Probleme und wandelt Eingaben und Ausgaben in einheitliche Textdarstellungen um. MUM erweitert diesen Ansatz durch multimodale Verarbeitungsfähigkeiten, sodass es Text, Bilder, Videos und Audio gleichzeitig in einem einzigen Modell verarbeiten kann. Diese Architektur ist deshalb so bedeutsam, weil MUM so Zusammenhänge und Kontext über verschiedene Medientypen hinweg erkennt, wie es frühere Modelle nicht konnten. Wird beispielsweise eine Anfrage zum Wandern auf dem Fuji zusammen mit einem Bild bestimmter Wanderschuhe gestellt, analysiert MUM Text und Bild nicht separat – es verarbeitet sie gemeinsam und versteht, wie die Eigenschaften der Schuhe mit dem Kontext der Anfrage zusammenhängen. Die 110 Milliarden Parameter des Modells ermöglichen es, riesige Mengen an Wissen über Sprache, visuelle Konzepte und deren Beziehungen zu speichern und zu verarbeiten. MUM wird gleichzeitig in 75 verschiedenen Sprachen und zahlreichen Aufgabenbereichen trainiert, wodurch ein umfassenderes Verständnis von Weltwissen entsteht als bei Modellen, die nur in einer Sprache oder für eine Aufgabe trainiert werden. Dieses Multitask-Lernen bedeutet, dass MUM Muster und Zusammenhänge erkennt, die sich über Sprachen und Domänen hinweg übertragen lassen – für mehr Robustheit und Generalisierbarkeit als bei früheren Modellen. Das gleichzeitige Training in mehreren Sprachen ermöglicht Wissensübertragung über Sprachgrenzen hinweg – MUM kann also Informationen, die in einer Sprache vorliegen, für Anfragen in einer anderen Sprache nutzen und so Sprachbarrieren abbauen, die Suchergebnisse bisher eingeschränkt haben.
Vergleichstabelle: MUM vs. verwandte KI-Modelle und Technologien
| Attribut | MUM (2021) | BERT (2019) | RankBrain (2015) | T5 Framework |
|---|
| Hauptfunktion | Multimodales Verständnis von Anfragen und Antwortsynthese | Kontextuelles Textverständnis | Interpretation von Long-Tail-Keywords | Text-zu-Text-Transferlernen |
| Eingabeformate | Text, Bilder, Video, Audio | Nur Text | Nur Text | Nur Text |
| Sprachunterstützung | Über 75 Sprachen nativ | Begrenzte Mehrsprachigkeit | Vorwiegend Englisch | Vorwiegend Englisch |
| Modellparameter | ~110 Milliarden | ~340 Millionen | Nicht veröffentlicht | ~220 Millionen |
| Leistungsvergleich | 1.000x leistungsfähiger als BERT | Ausgangswert | Vorgänger von BERT | Grundlage für MUM |
| Fähigkeiten | Verstehen + Generieren | Nur Verstehen | Mustererkennung | Texttransformation |
| SERP-Auswirkung | Multiformat-angereicherte Ergebnisse | Bessere Snippets und Kontext | Verbesserte Relevanz | Basistechnologie |
| Komplexitätsbewältigung bei Anfragen | Komplexe mehrstufige Anfragen | Kontext pro Einzelanfrage | Long-Tail-Variationen | Texttransformationen |
| Wissensübertragung | Über Sprach- und Formatgrenzen | Nur innerhalb einer Sprache | Begrenzte Übertragung | Über Aufgaben hinweg |
| Praktische Anwendung | Google Search, AI Overviews | Google Search Ranking | Google Search Ranking | Technische Grundlage für MUM |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wie MUM komplexe Suchanfragen verarbeitet
Die Anfrageverarbeitung von MUM umfasst mehrere ausgeklügelte Schritte, die zusammenspielen, um umfassende, kontextbezogene Antworten zu liefern. Gibt ein Nutzer eine Suchanfrage ein, startet MUM mit einer sprachagnostischen Vorverarbeitung und versteht die Anfrage in jeder der über 75 unterstützten Sprachen, ohne Übersetzung zu benötigen. So bleibt sprachliche Nuance und regionaler Kontext erhalten. Anschließend verwendet MUM Sequence-to-Sequence-Matching und analysiert die gesamte Anfrage als Bedeutungssequenz statt isolierter Keywords. Dadurch erkennt MUM Zusammenhänge zwischen Konzepten – etwa, dass eine Anfrage zu „Vorbereitung für Mount Fuji nach Besteigung des Mount Adams“ Vergleich, Vorbereitung und Kontextanpassung beinhaltet. Gleichzeitig führt MUM eine Analyse multimodaler Eingaben durch und verarbeitet Bilder, Videos oder andere Medien, die der Anfrage beigefügt sind. Das Modell betreibt dann gleichzeitige Anfrageverarbeitung und bewertet mehrere mögliche Nutzerintentionen parallel, statt sich auf eine zu beschränken. So erkennt MUM etwa bei einer Anfrage zum Wandern auf dem Fuji, dass es um körperliche Vorbereitung, Ausrüstungswahl, Kulturerfahrungen oder Reiseplanung gehen könnte – und spielt für alle diese Interpretationen passende Informationen aus. Vektorbasierte semantische Analyse wandelt Anfragen und indexierte Inhalte in hochdimensionale Vektoren um, die die Bedeutung abbilden und ein Abrufen auf Basis konzeptioneller Ähnlichkeit und nicht bloß nach Stichworten ermöglichen. MUM filtert Inhalte dann über Wissensübertragung, indem maschinelles Lernen auf Suchprotokollen, Nutzerdaten und Verhaltenstrends trainiert wurde, um hochwertige, autoritative Quellen zu priorisieren. Abschließend generiert MUM eine multimedial angereicherte SERP-Komposition, in der Textausschnitte, Bilder, Videos, verwandte Fragen und interaktive Elemente zu einem visuell vielschichtigen Sucherlebnis zusammengefügt werden. Dieser gesamte Prozess dauert nur Millisekunden und ermöglicht es MUM, Ergebnisse zu liefern, die nicht nur die explizite Anfrage, sondern auch antizipierte Folgefragen und Informationsbedarfe abdecken.
Multimodale und mehrsprachige Fähigkeiten
MUMs multimodale Fähigkeiten stellen einen grundlegenden Bruch mit rein textbasierten Suchsystemen dar. Das Modell kann Informationen aus Text, Bildern, Video und Audio gleichzeitig verarbeiten und verstehen, Bedeutung aus jedem Format extrahieren und zu kohärenten Antworten zusammenführen. Besonders bei Anfragen, die von visuellem Kontext profitieren, zeigt sich die Stärke: Fragt ein Nutzer etwa „Kann ich diese Wanderschuhe für den Mount Fuji verwenden?“ und zeigt ein Bild seiner Schuhe, erkennt MUM die Eigenschaften der Schuhe – Material, Profil, Höhe, Farbe – und verbindet dieses Wissen mit Informationen über das Gelände, Klima und die Anforderungen am Fuji, um eine kontextbezogene Antwort zu geben. Auch die mehrsprachige Dimension von MUM ist transformativ. Mit nativer Unterstützung für über 75 Sprachen kann MUM Wissensübertragung über Sprachgrenzen hinweg leisten – es lernt aus Quellen in einer Sprache und nutzt dieses Wissen für Suchanfragen in einer anderen. Das durchbricht eine wesentliche Schranke, die Suchergebnisse bisher auf Inhalte in der Nutzersprache beschränkte. Gibt es etwa umfassende Informationen über den Fuji vor allem in japanischen Quellen – inklusive lokaler Wanderführer, saisonaler Wetterdaten und kultureller Einblicke –, kann MUM diese verstehen und relevante Inhalte auch englischsprachigen Nutzern präsentieren. Laut Google konnte MUM in Tests 800 Variationen von COVID-19-Impfstoffen in über 50 Sprachen innerhalb von Sekunden auflisten, was die Leistungsfähigkeit und Geschwindigkeit der mehrsprachigen Verarbeitung zeigt. Dieses Verständnis ist besonders wertvoll für Nutzer in nicht-englischsprachigen Märkten und für Themen, zu denen es in mehreren Sprachen reiche Informationen gibt. Die Kombination aus multimodaler und mehrsprachiger Verarbeitung ermöglicht es MUM, die relevantesten Informationen unabhängig vom Format oder der Ursprungssprache aufzuspüren und so eine wirklich globale Suche zu schaffen.
Auswirkungen auf Suchergebnisse und Nutzererfahrung
MUM verändert grundlegend, wie Suchergebnisse angezeigt und von Nutzern erlebt werden. Statt der traditionellen Liste blauer Links erzeugt MUM angereicherte, interaktive SERPs, die verschiedene Inhaltsformate auf einer Seite kombinieren. Nutzer sehen jetzt Textausschnitte, hochauflösende Bilder, Video-Karussells, verwandte Fragen und interaktive Elemente – alles, ohne die Suchseite zu verlassen. Dieser Wandel hat erhebliche Auswirkungen auf das Nutzerverhalten: Komplexe Fragen können direkt durch verschiedene Perspektiven und Unterthemen innerhalb der SERP erschlossen werden, statt mehrerer Einzelanfragen. Sucht man beispielsweise nach „Vorbereitung für den Mount Fuji im Herbst“, erscheinen Höhenvergleiche, Wetterprognosen, Ausrüstungsempfehlungen, Videoguides und Nutzerbewertungen – alles kontextuell organisiert auf einer Seite. Die Google-Lens-Integration mit MUM ermöglicht es, mit Bildern statt Stichwörtern zu suchen und visuelle Elemente in Fotos zu interaktiven Suchwerkzeugen zu machen. „Things to Know“-Panels zerlegen komplexe Anfragen in verständliche Unterthemen und führen Nutzer durch die verschiedenen Aspekte eines Themas. Zoombare, hochauflösende Bilder erscheinen direkt in den Suchergebnissen, was visuelle Vergleiche und frühe Entscheidungsfindung erleichtert. Die „Refine and Broaden“-Funktion schlägt verwandte Konzepte vor, um Nutzern das Vertiefen oder Erweitern eines Themas zu erleichtern. Diese Neuerungen machen aus der Suche ein interaktives, exploratives Erlebnis, das Nutzerbedürfnisse antizipiert und umfassende Informationen direkt in der Suchoberfläche bereitstellt. Studien zeigen, dass sich die durchschnittliche Anzahl an Suchanfragen zur Beantwortung komplexer Fragen reduziert – allerdings konsumieren Nutzer Informationen häufiger direkt in der Suche, ohne auf Websites zu klicken.
Die Rolle von MUM im KI-Monitoring und für Marken-Sichtbarkeit
Für Organisationen, die ihre Präsenz in KI-Systemen tracken, stellt MUM eine entscheidende Weiterentwicklung dar, wie Informationen gefunden und dargestellt werden. Da MUM zunehmend in die Google-Suche integriert und dadurch auch andere KI-Systeme beeinflusst, wird es für Marken und Domains essenziell, ihre Sichtbarkeit in MUM-gesteuerten Ergebnissen zu verstehen und zu optimieren. MUMs multimodale Verarbeitung bedeutet, dass Marken über mehrere Formate hinweg optimieren müssen, nicht nur für Text. Wer früher auf Rankings für bestimmte Keywords setzte, muss jetzt sicherstellen, dass seine Inhalte in Bildern, Videos und über strukturierte Daten auffindbar sind. Da das Modell Informationen aus verschiedenen Quellen zusammenführt, hängt die Sichtbarkeit einer Marke nicht mehr nur von der eigenen Website, sondern auch davon ab, wie sie im gesamten Web-Ökosystem vertreten ist. Die mehrsprachigen Fähigkeiten von MUM eröffnen für globale Marken neue Chancen und Herausforderungen. Inhalte, die in einer Sprache veröffentlicht wurden, können jetzt von Nutzern in anderen Sprachen entdeckt werden, was die Reichweite erheblich erweitert. Gleichzeitig müssen Marken darauf achten, dass ihre Informationen in allen Sprachen korrekt und konsistent sind, da MUM bei einer einzigen Anfrage Inhalte aus mehreren Sprachquellen kombinieren kann. Für KI-Monitoring-Plattformen wie AmICited ist das Tracking von MUMs Einfluss entscheidend, da es zeigt, wie moderne KI-Systeme Inhalte abrufen und präsentieren. Wer überwacht, wo eine Marke in KI-Antworten erscheint – etwa in Google AI Overviews, Perplexity, ChatGPT oder Claude – versteht durch die Kenntnis von MUMs Technologie besser, warum bestimmte Inhalte ausgespielt werden und wie man Sichtbarkeit optimiert. Der Trend zu multimodaler, mehrsprachiger Suche erfordert Monitoring, das Präsenz in verschiedenen Formaten und Sprachen abdeckt, nicht nur klassisches Keyword-Ranking. Wer MUMs Fähigkeiten versteht, kann seine Content-Strategie optimal auf die neue Suchlandschaft ausrichten.
Zentrale Vorteile und Nutzen von MUM
- Reduzierte Suchhürden: Nutzer benötigen weniger Suchanfragen, um komplexe Fragen zu beantworten, da MUM Informationen aus verschiedenen Quellen und Formaten zu umfassenden Antworten zusammenfasst
- Multimodales Verständnis: Gleichzeitige Verarbeitung von Text, Bildern, Videos und Audio ermöglicht reichhaltigeren Kontext und präzisere Antworten auf Anfragen mit visuellem oder multimedialem Bezug
- Mehrsprachige Wissensübertragung: Native Unterstützung für über 75 Sprachen ermöglicht das Auffinden von Informationen über Sprachbarrieren hinweg und erweitert Reichweite und Zugänglichkeit weltweit
- Kontextuelle Relevanz: MUM versteht Nutzerintentionen auf tieferer Ebene, erkennt Zusammenhänge zwischen Konzepten und liefert Informationen auch zu erwarteten Folgefragen
- Angereichertes SERP-Erlebnis: Interaktive, visuell vielschichtige Suchergebnisse liefern mehr Informationen direkt in der Suche und verbessern Engagement und Entscheidungsfindung
- Bessere Behandlung von Mehrdeutigkeiten: MUM kann durch gleichzeitige Auswertung mehrerer Interpretationen auch auf vage oder mehrdeutige Fragen relevante Ergebnisse liefern
- Wissenssynthese: MUM kann Informationen aus verschiedenen Quellen zusammenführen und zu umfassenden Antworten verknüpfen, statt nur Inhalte zu finden
- Verbesserte Zugänglichkeit: Multimodale und mehrsprachige Verarbeitung macht Informationen für verschiedenste Nutzergruppen mit unterschiedlichen Sprachen und Bedürfnissen zugänglich
- Höherwertige Featured Snippets: MUM ermöglicht fortschrittlichere Snippet-Generierung mit mehreren Formaten je Anfrage, je nach Nutzerintention
- Formatübergreifende Inhaltsentdeckung: Inhalte in jedem Format – Text, Bild, Video, Audio – können gefunden und ausgespielt werden, was multimediale Content-Strategien belohnt
Einschränkungen und Herausforderungen von MUM
So bedeutsam MUMs Fortschritt ist, bringt es auch neue Herausforderungen und Grenzen mit sich, denen sich Organisationen stellen müssen. Niedrigere Klickraten sind eine zentrale Sorge für Publisher und Content-Ersteller, da Nutzer nun umfassende Informationen direkt in den Suchergebnissen konsumieren, ohne auf Websites zu klicken. Klassische Traffic-Metriken verlieren dadurch an Aussagekraft. Höhere Anforderungen an technisches SEO bedeuten, dass Inhalte, um von MUM richtig verstanden zu werden, gut strukturiert, mit passendem Schema-Markup, semantischem HTML und klaren Entitätsbeziehungen versehen sein müssen. Fehlende technische Grundlage kann dazu führen, dass Inhalte von MUMs multimodaler Verarbeitung nicht korrekt erfasst oder indexiert werden. SERP-Sättigung erschwert Sichtbarkeit, da verschiedene Formate auf einer Seite konkurrieren; auch starke Inhalte können weniger oder keine Klicks erhalten, wenn Nutzer bereits in der SERP alles Benötigte finden. Potenzial für irreführende Ergebnisse besteht, wenn MUM Informationen aus mehreren Quellen zusammenführt, die sich widersprechen oder in der Synthese Kontext verloren geht. Abhängigkeit von strukturierten Daten bedeutet, dass unstrukturierte oder schlecht formatierte Inhalte von MUM möglicherweise nicht richtig verstanden oder ausgespielt werden. Herausforderungen bei Sprache und kultureller Nuance entstehen, wenn bei der Wissensübertragung Kontext oder regionale Bedeutungen verloren gehen. Hoher Rechenaufwand für den Betrieb von MUM im großen Maßstab ist erheblich, auch wenn Google an Effizienzsteigerungen zur Reduktion des CO2-Fußabdrucks arbeitet. Bias- und Fairness-Probleme erfordern kontinuierliche Aufmerksamkeit, um zu verhindern, dass MUM Verzerrungen aus Trainingsdaten übernimmt oder bestimmte Sichtweisen benachteiligt.
Auswirkungen auf SEO und Content-Strategie
Durch MUM müssen Organisationen ihre SEO- und Content-Strategie grundlegend anpassen. Klassische Keyword-Optimierung verliert an Bedeutung, da MUM Intention und Kontext unabhängig von exakten Suchbegriffen versteht. Themenbasierte Content-Strategie wird wichtiger als keyword-basierte, mit umfassenden Content-Clusters, die ein Thema aus verschiedenen Perspektiven beleuchten. Multimediale Inhaltserstellung ist keine Kür mehr, sondern Pflicht – hochwertige Bilder, Videos und interaktive Inhalte müssen Text sinnvoll ergänzen. Strukturierte Daten und Schema-Markup werden essenziell, damit MUM die Struktur und Zusammenhänge von Inhalten erkennen kann. Entity-Building und semantische Optimierung stärken thematische Autorität und verbessern das Verständnis von Content-Beziehungen durch MUM. Mehrsprachige Content-Strategie gewinnt an Relevanz, da MUM Inhalte über Sprachmärkte hinweg auffindbar macht. User-Intent-Mapping wird komplexer: Es reicht nicht mehr, nur Hauptintentionen zu adressieren, sondern auch thematisch verwandte Fragen und Aspekte zu berücksichtigen. Aktualität und Genauigkeit von Inhalten werden wichtiger, da MUM Informationen aus vielen Quellen zusammenführt – veraltete oder ungenaue Inhalte werden abgewertet. Plattformübergreifende Optimierung umfasst nicht nur Google Search, sondern auch die Darstellung in KI-Systemen wie Google AI Overviews, Perplexity und andere KI-gestützte Suchoberflächen. E-E-A-T-Signale (Experience, Expertise, Authoritativeness, Trustworthiness) gewinnen an Gewicht, da MUM Inhalte von vertrauenswürdigen Quellen priorisiert. Wer seine Strategie auf MUMs Fähigkeiten ausrichtet – mit umfassenden, multimodalen, gut strukturierten Inhalten, die Expertise und Autorität zeigen –, bleibt in der neuen Suchlandschaft sichtbar.
Zukünftige Entwicklung und strategischer Ausblick
MUM ist kein Endpunkt, sondern ein Meilenstein in der Entwicklung KI-gestützter Suche. Google hat angekündigt, dass MUMs Fähigkeiten weiter ausgebaut werden, insbesondere bei der Verarbeitung von Video und Audio. Zudem wird daran geforscht, den Ressourcenbedarf von MUM weiter zu senken, ohne Leistung einzubüßen – auch im Hinblick auf Nachhaltigkeit großer KI-Modelle. Die Integration von MUM in andere Google-Technologien lässt erwarten, dass MUMs Verständnis künftig nicht nur die Suche, sondern auch Google Assistant, Google Lens und weitere Produkte antreibt. Konkurrenzdruck durch andere KI-Systeme wie OpenAIs ChatGPT, Anthropics Claude und Perplexitys KI-Suche sorgt dafür, dass MUM sich weiter entwickeln wird, um Googles Wettbewerbsvorteil zu sichern. Regulatorische Anforderungen an KI werden Einfluss auf MUMs Entwicklung haben, insbesondere hinsichtlich Fairness, Transparenz und Bias. Verändertes Nutzerverhalten wird die Evolution von MUM mitbestimmen – je mehr Nutzer interaktive, umfassende Sucherlebnisse erwarten, desto höher werden die Ansprüche an Qualität und Vollständigkeit. Mit dem Aufstieg generativer KI werden MUMs Fähigkeiten zur Synthese und Generierung von Informationen immer wichtiger; künftig könnte MUM auch eigenständige Inhalte erzeugen, statt nur bestehende zu organisieren. Multimodale KI wird zum Standard – MUMs Ansatz, Formate simultan zu verarbeiten, dürfte sich auf andere Systeme ausweiten. Datenschutz und Nutzerkontrolle werden beeinflussen, wie MUM Verhaltenssignale zur Personalisierung nutzt. Organisationen sollten sich auf ständige Weiterentwicklung einstellen und flexible, qualitativ hochwertige Content-Strategien verfolgen, statt auf Taktiken zu setzen, die schnell überholt sein können. Der Kern bleibt: Inhalte zu schaffen, die Nutzerintention in verschiedenen Formaten und Sprachen bestmöglich bedienen – das bleibt unabhängig von MUMs technischer Entwicklung relevant.