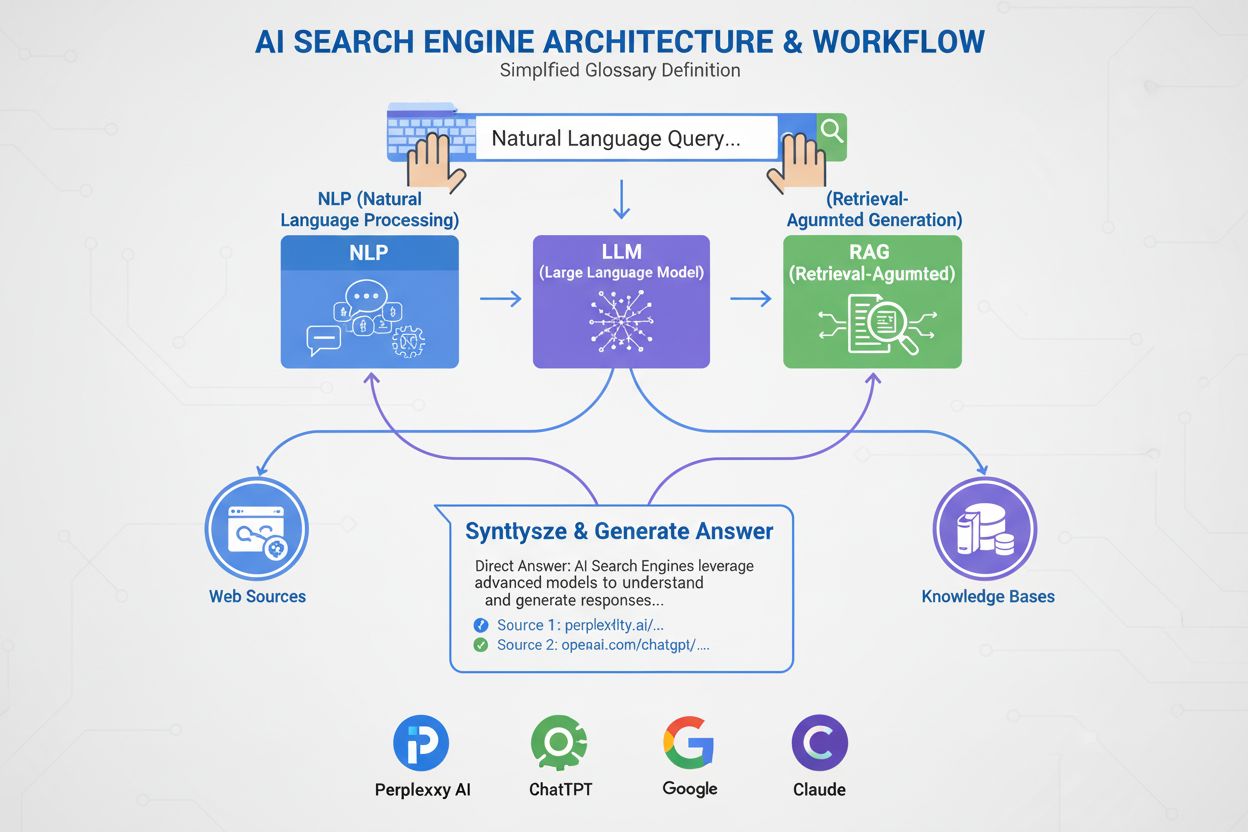
Definition von Natural Language Processing (NLP)
Natural Language Processing (NLP) ist ein Teilgebiet der Künstlichen Intelligenz und Informatik, das Computern ermöglicht, menschliche Sprache auf sinnvolle Weise zu verstehen, zu interpretieren, zu manipulieren und zu generieren. NLP verbindet Computerlinguistik (regelbasierte Modellierung menschlicher Sprache), maschinelle Lernalgorithmen und Deep-Learning-Neuronale Netzwerke, um sowohl Text- als auch Sprachdaten zu verarbeiten. Die Technologie erlaubt es Maschinen, die semantische Bedeutung von Sprache zu erfassen, Muster in der menschlichen Kommunikation zu erkennen und kohärente Antworten zu generieren, die menschliches Sprachverständnis nachahmen. NLP ist grundlegend für moderne KI-Anwendungen und treibt alles an – von Suchmaschinen und Chatbots über Sprachassistenten bis zu KI-Monitoringsystemen, die Markenerwähnungen auf Plattformen wie ChatGPT, Perplexity und Google AI Overviews verfolgen.
Historischer Kontext und Entwicklung von NLP
Das Feld des Natural Language Processing entstand in den 1950er Jahren, als Forscher erstmals maschinelle Übersetzung versuchten. Das bahnbrechende Georgetown-IBM-Experiment von 1954 übersetzte erfolgreich 60 russische Sätze ins Englische. Frühere NLP-Systeme waren jedoch stark eingeschränkt, da sie auf starre, regelbasierte Ansätze angewiesen waren und nur auf spezifische, vorprogrammierte Eingaben reagieren konnten. In den 1990er- und frühen 2000er-Jahren gab es bedeutende Fortschritte mit der Entwicklung statistischer NLP-Methoden, die maschinelles Lernen in die Sprachverarbeitung einführten und Anwendungen wie Spam-Filterung, Dokumentklassifizierung und einfache Chatbots ermöglichten. Die eigentliche Revolution erfolgte in den 2010er-Jahren mit dem Aufkommen von Deep-Learning-Modellen und neuronalen Netzwerken, die größere Textmengen analysieren und komplexe Muster in Sprachdaten erkennen konnten. Heute erlebt der NLP-Markt ein explosives Wachstum – Prognosen zufolge wächst der globale NLP-Markt von 59,70 Milliarden US-Dollar im Jahr 2024 auf 439,85 Milliarden US-Dollar bis 2030, was einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 38,7 % entspricht. Dieses Wachstum verdeutlicht die wachsende Bedeutung von NLP in Unternehmenslösungen, KI-gestützter Automatisierung und Anwendungen im Markenmonitoring.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Zentrale NLP-Techniken und Methoden
Natural Language Processing nutzt mehrere grundlegende Techniken, um menschliche Sprache zu zerlegen und zu analysieren. Tokenisierung ist der Prozess der Aufteilung von Text in kleinere Einheiten wie Wörter, Sätze oder Phrasen und macht komplexe Texte für maschinelle Lernmodelle handhabbar. Stemming und Lemmatisierung reduzieren Wörter auf ihre Wortstämme (z. B. werden “laufen”, “läuft” und “lief” zu “lauf”), sodass Systeme verschiedene Formen desselben Wortes erkennen können. Named Entity Recognition (NER) identifiziert und extrahiert spezifische Begriffe wie Personennamen, Orte, Organisationen, Daten und Geldbeträge aus Text – eine entscheidende Fähigkeit für Markenmonitoringsysteme, die Unternehmensnamen in KI-generierten Inhalten erkennen müssen. Sentiment-Analyse bestimmt die emotionale Tonlage oder Meinung in Texten und klassifiziert sie als positiv, negativ oder neutral. Dies ist essenziell, um zu verstehen, wie Marken in KI-Antworten dargestellt werden. Wortarten-Tagging (Part-of-Speech-Tagging) identifiziert die grammatische Rolle jedes Wortes im Satz (Substantiv, Verb, Adjektiv usw.) und hilft Systemen, Satzstruktur und Bedeutung zu erfassen. Textklassifikation ordnet Dokumente oder Textpassagen vordefinierten Kategorien zu, sodass Systeme Informationen organisieren und filtern können. Diese Techniken arbeiten zusammen in NLP-Pipelines, um unstrukturierte Rohtexte in strukturierte, analysierbare Daten zu überführen, die von KI-Systemen verarbeitet und erlernt werden können.
Vergleich von NLP-Ansätzen und Technologien
| NLP-Ansatz | Beschreibung | Anwendungsfälle | Vorteile | Einschränkungen |
|---|
| Regelbasierte NLP | Nutzt vorprogrammierte Wenn-Dann-Entscheidungsbäume und Grammatikregeln | Einfache Chatbots, grundlegende Textfilterung | Vorhersehbar, transparent, kein Trainingsdatensatz nötig | Nicht skalierbar, kann keine Sprachvariationen verarbeiten, eingeschränkte Flexibilität |
| Statistische NLP | Nutzt maschinelles Lernen zur Mustererkennung in beschrifteten Daten | Spam-Erkennung, Dokumentklassifikation, Wortarten-Tagging | Flexibler als regelbasiert, lernt aus Daten | Benötigt beschriftete Trainingsdaten, Schwierigkeiten mit Kontext und Nuancen |
| Deep Learning NLP | Nutzt neuronale Netzwerke und Transformer-Modelle auf riesigen, unstrukturierten Datensätzen | Chatbots, maschinelle Übersetzung, Content-Generierung, Markenmonitoring | Sehr genau, erkennt komplexe Sprachmuster, lernt Kontext | Benötigt enorme Rechenressourcen, anfällig für Verzerrungen in Trainingsdaten |
| Transformer-Modelle (BERT, GPT) | Nutzt Self-Attention-Mechanismen zur gleichzeitigen Verarbeitung kompletter Sequenzen | Sprachverständnis, Textgenerierung, Sentiment-Analyse, NER | Spitzenleistung, effizientes Training, Kontextverständnis | Rechenintensiv, benötigt große Datensätze, schwer interpretierbar (Black-Box) |
| Überwachtes Lernen | Trainiert auf beschrifteten Input-Output-Paaren | Sentiment-Klassifikation, Named Entity Recognition, Textkategorisierung | Hohe Genauigkeit für spezifische Aufgaben, vorhersehbare Leistung | Benötigt umfangreiche beschriftete Daten, zeitaufwändiger Annotierungsprozess |
| Unüberwachtes Lernen | Erkennt Muster in unbeschrifteten Daten | Themenmodellierung, Clustering, Anomalieerkennung | Keine Beschriftung erforderlich, entdeckt verborgene Muster | Weniger genau, schwerer interpretierbar, erfordert Fachexpertise |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wie Natural Language Processing funktioniert: Die vollständige Pipeline
Natural Language Processing arbeitet in einer systematischen Pipeline, die rohe menschliche Sprache in maschinenlesbare Erkenntnisse umwandelt. Der Prozess beginnt mit der Textvorverarbeitung, bei der der Eingabetext bereinigt und standardisiert wird. Tokenisierung teilt Text in einzelne Wörter oder Phrasen, Kleinschreibung konvertiert alle Zeichen in Kleinbuchstaben, sodass “Apple” und “apple” identisch behandelt werden, und Stoppwort-Entfernung filtert häufige Wörter wie “der” oder “ist”, die wenig zum Inhalt beitragen. Stemming und Lemmatisierung reduzieren Wörter auf ihre Stammformen, und Textbereinigung entfernt Satzzeichen, Sonderzeichen und irrelevante Elemente. Nach der Vorverarbeitung folgt die Merkmalextraktion, bei der Text in numerische Repräsentationen umgewandelt wird, die von maschinellen Lernmodellen verarbeitet werden können. Techniken wie Bag of Words und TF-IDF quantifizieren die Bedeutung von Wörtern, während Word Embeddings wie Word2Vec und GloVe Wörter als dichte Vektoren im kontinuierlichen Raum darstellen, um semantische Beziehungen abzubilden. Fortgeschrittene kontextuelle Embeddings berücksichtigen umliegende Wörter und ermöglichen reichhaltigere Repräsentationen. Im nächsten Schritt folgt die Textanalyse, in der Systeme Methoden wie Named Entity Recognition zur Identifikation spezifischer Entitäten, Sentiment-Analyse zur Bestimmung der emotionalen Tonlage, Abhängigkeitsanalyse zum Verständnis grammatischer Beziehungen und Themenmodellierung zur Erkennung zugrundeliegender Themen anwenden. Abschließend nutzt das System die verarbeiteten Daten zum Modelltraining, um maschinelle Lernmodelle zu trainieren, die Muster und Zusammenhänge erkennen. Das trainierte Modell wird dann eingesetzt, um Vorhersagen für neue, unbekannte Daten zu treffen. Diese gesamte Pipeline ermöglicht es Systemen wie AmICited, Markenerwähnungen in KI-generierten Antworten auf Plattformen wie ChatGPT, Perplexity und Google AI Overviews zu erkennen und zu analysieren.
Das Aufkommen von Deep Learning hat das Natural Language Processing grundlegend verändert und die statistischen Methoden um neuronale Netzwerkarchitekturen erweitert, die komplexe Sprachmuster aus riesigen Datensätzen lernen können. Recurrent Neural Networks (RNNs) und Long Short-Term Memory (LSTM)-Netzwerke waren frühe Deep-Learning-Ansätze zur Verarbeitung sequenzieller Daten, stießen jedoch bei langen Abhängigkeiten an ihre Grenzen. Der Durchbruch gelang mit Transformer-Modellen, die den Self-Attention-Mechanismus einführten – einen revolutionären Ansatz, der es Modellen erlaubt, alle Wörter einer Sequenz gleichzeitig zu betrachten und zu bewerten, welche Teile für das Verständnis der Bedeutung am wichtigsten sind. BERT (Bidirectional Encoder Representations from Transformers), entwickelt von Google, bildet die Basis für moderne Suchmaschinen und Aufgaben des Sprachverständnisses, indem es Text bidirektional verarbeitet und Kontext aus beiden Richtungen versteht. GPT (Generative Pre-trained Transformer)-Modelle, einschließlich des weit verbreiteten GPT-4, nutzen eine autoregressive Architektur zur Vorhersage des nächsten Wortes in einer Sequenz und ermöglichen so anspruchsvolle Textgenerierung. Diese Transformer-Modelle können mit selbstüberwachtem Lernen auf riesigen Textdatenbanken ohne manuelle Annotation trainiert werden und sind dadurch äußerst effizient und skalierbar. Foundation Models wie IBMs Granite sind vorgefertigte, kuratierte Modelle, die schnell für verschiedene NLP-Aufgaben wie Content-Generierung, Insight-Extraktion und Named Entity Recognition eingesetzt werden können. Die Stärke dieser Modelle liegt darin, dass sie nuancierte semantische Beziehungen erfassen, Kontext über lange Textpassagen hinweg verstehen und kohärente, kontextgerechte Antworten generieren – Fähigkeiten, die für KI-Monitoring-Plattformen, die Markenerwähnungen in KI-generierten Inhalten verfolgen, unerlässlich sind.
NLP-Anwendungen in Branchen und im KI-Monitoring
Natural Language Processing ist mittlerweile in nahezu jeder Branche unverzichtbar und ermöglicht es Organisationen, verwertbare Erkenntnisse aus riesigen Mengen unstrukturierter Text- und Sprachdaten zu gewinnen. Im Finanzwesen beschleunigt NLP die Analyse von Finanzberichten, regulatorischen Dokumenten und Pressemitteilungen und unterstützt Händler und Analysten bei schnelleren, fundierteren Entscheidungen. Gesundheitsorganisationen nutzen NLP zur Analyse medizinischer Akten, Fachliteratur und klinischer Notizen, was schnellere Diagnosen, Therapieplanung und Forschung ermöglicht. Versicherungen setzen NLP zur Analyse von Schadensfällen ein, um Betrugsmuster oder Ineffizienzen zu erkennen und Prozesse zu optimieren. Rechtskanzleien verwenden NLP für die automatisierte Dokumentenprüfung, organisieren große Mengen an Fallakten und Präzedenzfällen und reduzieren so Zeit und Kosten erheblich. Kundendienstabteilungen setzen NLP-basierte Chatbots für Routineanfragen ein, sodass menschliche Mitarbeiter sich auf komplexe Anliegen konzentrieren können. Marketing- und Markenmanagement-Teams verlassen sich zunehmend auf NLP für Sentiment-Analyse und Markenmonitoring, indem sie verfolgen, wie ihre Marken in digitalen Kanälen erwähnt und wahrgenommen werden. Besonders relevant für AmICiteds Mission ist, dass NLP KI-Monitoring-Plattformen ermöglicht, Markenerwähnungen in KI-generierten Antworten von Systemen wie ChatGPT, Perplexity, Google AI Overviews und Claude zu erkennen und zu analysieren. Diese Plattformen verwenden Named Entity Recognition, um Markennamen zu identifizieren, Sentiment-Analyse, um den Kontext und Tonfall der Erwähnungen zu verstehen, und Textklassifikation, um die Art der Erwähnung zu kategorisieren. Diese Fähigkeit wird immer wichtiger, da Unternehmen erkennen, dass ihre Markenpräsenz in KI-Antworten den Kundenzugang und das Markenimage im Zeitalter generativer KI direkt beeinflusst.
Zentrale NLP-Aufgaben und Fähigkeiten
- Named Entity Recognition (NER): Identifiziert und extrahiert spezifische Begriffe wie Personen, Organisationen, Orte, Daten und Produkte aus Text – unerlässlich für Markenmonitoring und Informationsextraktion
- Sentiment-Analyse: Bestimmt die emotionale Tonlage und Meinung in Texten, klassifiziert Inhalte als positiv, negativ oder neutral, um die Markenwahrnehmung zu verstehen
- Textklassifikation: Ordnet Dokumente oder Textpassagen vordefinierten Kategorien zu und ermöglicht so die automatisierte Organisation und Filterung großer Textmengen
- Maschinelle Übersetzung: Wandelt Text von einer Sprache in eine andere um und erhält dabei Bedeutung und Kontext, unterstützt durch Sequenz-zu-Sequenz-Transformer-Modelle
- Spracherkennung: Wandelt gesprochene Sprache in Text um und ermöglicht sprachbasierte Schnittstellen und Transkriptionsdienste
- Textzusammenfassung: Generiert automatisch prägnante Zusammenfassungen längerer Dokumente, um Zeit bei der Informationsverarbeitung zu sparen
- Question Answering: Ermöglicht Systemen, Fragen zu verstehen und präzise Antworten aus Wissensdatenbanken abzurufen oder zu generieren
- Koreferenzauflösung: Erkennt, wenn verschiedene Wörter oder Phrasen sich auf dieselbe Entität beziehen – entscheidend für Kontext- und Beziehungsverständnis
- Wortarten-Tagging: Identifiziert die grammatische Rolle jedes Wortes und hilft Systemen, Satzstruktur und Bedeutung zu erfassen
- Themenmodellierung: Erkennt zugrundeliegende Themen in Dokumenten oder Dokumentensammlungen – nützlich für Inhaltsanalyse und Organisation
Herausforderungen und Grenzen des Natural Language Processing
Trotz bemerkenswerter Fortschritte steht Natural Language Processing vor erheblichen Herausforderungen, die Genauigkeit und Anwendbarkeit begrenzen. Mehrdeutigkeit ist wohl die grundlegendste Schwierigkeit – Wörter und Phrasen haben oft je nach Kontext verschiedene Bedeutungen, und Sätze können unterschiedlich interpretiert werden. Beispiel: “Ich sah den Mann mit dem Fernrohr” kann bedeuten, dass der Sprecher ein Fernrohr benutzte, um den Mann zu sehen, oder dass der Mann selbst ein Fernrohr hatte. Kontextuelles Verständnis bleibt für NLP-Systeme schwierig, insbesondere wenn Bedeutung auf Informationen aus viel früheren Textteilen basiert oder Weltwissen erfordert. Sarkasmus, Redewendungen und Metaphern sind besonders herausfordernd, da ihre wörtliche von der beabsichtigten Bedeutung abweicht und Systeme, die auf Standardsprache trainiert wurden, sie oft falsch interpretieren. Tonfall und emotionale Nuancen sind im reinen Text schwer zu erfassen – dieselben Wörter können je nach Betonung, Ausdruck und Körpersprache völlig unterschiedliche Bedeutungen haben. Verzerrungen im Trainingsdatensatz sind ein zentrales Problem: NLP-Modelle, die mit Webdaten trainiert werden, übernehmen häufig gesellschaftliche Vorurteile und liefern diskriminierende oder ungenaue Ausgaben. Neues Vokabular und sprachlicher Wandel fordern NLP-Systeme ständig heraus, da neue Wörter, Slang und Grammatik schneller entstehen, als Trainingsdaten aktualisiert werden können. Seltene Sprachen und Dialekte verfügen über weniger Trainingsdaten, was zu deutlich schlechterer Performance für deren Sprecher führt. Grammatikfehler, undeutliche Aussprache, Hintergrundgeräusche und nicht standardisierte Sprache in realen Audiodaten stellen zusätzliche Herausforderungen für Spracherkennungssysteme dar. Diese Einschränkungen bedeuten, dass selbst modernste NLP-Systeme Bedeutungen falsch interpretieren können, insbesondere in Grenzfällen oder bei der Verarbeitung informeller, kreativer oder kulturell spezifischer Sprache.
Die Zukunft von NLP und neue Trends
Das Feld des Natural Language Processing entwickelt sich rasant weiter, wobei mehrere neue Trends die Zukunft bestimmen. Multimodales NLP, das Text-, Bild- und Audioverarbeitung kombiniert, ermöglicht ausgefeiltere KI-Systeme, die Inhalte über mehrere Modalitäten hinweg verstehen und generieren können. Few-shot- und Zero-shot-Lernen reduzieren den Bedarf an riesigen beschrifteten Datensätzen, sodass NLP-Modelle neue Aufgaben mit nur wenigen Trainingsbeispielen bewältigen. Retrieval-Augmented Generation (RAG) verbessert die Genauigkeit und Zuverlässigkeit von KI-generierten Inhalten, indem Sprachmodelle mit externen Wissensquellen verbunden werden – so werden Halluzinationen reduziert und Fakten verbessert. Effiziente NLP-Modelle werden entwickelt, um den Rechenaufwand zu senken und fortschrittliche NLP-Funktionen auch kleineren Unternehmen und Edge-Geräten zugänglich zu machen. Erklärbare KI im NLP gewinnt an Bedeutung, da Unternehmen verstehen wollen, wie Modelle Entscheidungen treffen und regulatorische Anforderungen einhalten. Branchenspezifische NLP-Modelle werden für Spezialanwendungen in Gesundheitswesen, Recht, Finanzen und anderen Branchen feinabgestimmt und verbessern die Genauigkeit für spezifische Fachsprache und Terminologie. Ethische KI und Bias-Reduktion rücken zunehmend in den Fokus, da Unternehmen die Bedeutung fairer, unverzerrter NLP-Systeme erkennen. Besonders für das Markenmonitoring wird die Integration von NLP in KI-Monitoring-Plattformen unerlässlich, da Markenpräsenz und -wahrnehmung in KI-generierten Antworten immer stärker den Kundenzugang und die Wettbewerbsposition beeinflussen. Da KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews zu primären Informationsquellen für Verbraucher werden, wird die Fähigkeit, zu überwachen und zu verstehen, wie Marken dort erscheinen – unterstützt durch ausgereifte NLP-Technologien – zu einem zentralen Bestandteil moderner Marketing- und Markenstrategien.
Die Rolle von NLP im KI-Monitoring und in der Markenpräsenz
Natural Language Processing ist die technologische Grundlage, die Plattformen wie AmICited ermöglicht, Markenerwähnungen in KI-Systemen zu verfolgen. Wenn Nutzer ChatGPT, Perplexity, Google AI Overviews oder Claude abfragen, generieren diese Systeme Antworten mit großen Sprachmodellen, die auf fortschrittlichen NLP-Technologien basieren. AmICited nutzt NLP-Algorithmen, um diese KI-generierten Antworten zu analysieren, erkennt, wann Marken erwähnt werden, extrahiert den Kontext dieser Erwähnungen und analysiert die geäußerte Stimmung. Named Entity Recognition identifiziert Markennamen und verwandte Begriffe, Sentiment-Analyse bestimmt, ob Erwähnungen positiv, negativ oder neutral sind, und Textklassifikation kategorisiert die Art der Erwähnung (Produktempfehlung, Vergleich, Kritik etc.). Diese Fähigkeit verschafft Unternehmen entscheidende Sichtbarkeit ihrer KI-Präsenz – also wie ihre Marke in KI-Systemen, die zunehmend als primäre Informationsquelle für Verbraucher dienen, entdeckt und diskutiert wird. Während der NLP-Markt weiter rasant wächst und Prognosen zufolge bis 2030 auf 439,85 Milliarden US-Dollar ansteigt, wird die Bedeutung von NLP-basiertem Markenmonitoring weiter zunehmen. Es ist daher für Unternehmen unerlässlich, diese Technologien zu verstehen und zu nutzen, um ihre Markenreputation in der KI-getriebenen Zukunft zu schützen und zu stärken.