
Was ist das NoAI-Meta-Tag und wie schützt es Ihre Inhalte vor KI?
Erfahren Sie mehr über das NoAI-Meta-Tag, wie es das Sammeln von Trainingsdaten für KI verhindert, welche Einschränkungen es gibt und wie Sie es auf Ihrer Websi...
7 Min. Lesezeit

Ein HTML-Meta-Tag, das KI-Trainingssystemen und Webcrawlern signalisiert, dass Website-Inhalte nicht für das Training von Machine-Learning-Modellen verwendet werden dürfen. Ursprünglich von DeviantArt eingeführt, dient es als Mechanismus zum Schutz von Inhalten und als Opt-out-Signal für Urheber, die sich um unautorisierte KI-Datensammlung sorgen.
Ein HTML-Meta-Tag, das KI-Trainingssystemen und Webcrawlern signalisiert, dass Website-Inhalte nicht für das Training von Machine-Learning-Modellen verwendet werden dürfen. Ursprünglich von DeviantArt eingeführt, dient es als Mechanismus zum Schutz von Inhalten und als Opt-out-Signal für Urheber, die sich um unautorisierte KI-Datensammlung sorgen.
Das NoAI-Meta-Tag ist ein Mechanismus zum Schutz von Inhalten, der als HTML-Meta-Tag implementiert wird und KI-Trainingssystemen sowie Webcrawlern signalisiert, dass die Inhalte einer Website nicht für das Training von Machine-Learning-Modellen verwendet werden dürfen. Ursprünglich im September 2022 von DeviantArt eingeführt, entstand die NoAI-Direktive als Reaktion der Community auf die Sorge, dass Werke von Künstlern ohne Einwilligung oder Vergütung für generative KI-Modelle gesammelt und verwendet werden. Das Meta-Tag funktioniert durch das Hinzufügen einer einfachen HTML-Deklaration im Seitenkopf einer Website und kommuniziert so klar an KI-Systeme, dass diese Inhalte für Trainingszwecke tabu sind. Auch wenn das NoAI-Tag in den meisten Rechtsordnungen nicht rechtsverbindlich ist, stellt es für Urheber ein wichtiges Opt-out-Instrument dar, um ihr geistiges Eigentum in Zeiten immer aggressiverer KI-Datensammlungen zu schützen.
Webcrawler (auch Bots, Spider oder Scraper genannt) sind automatisierte Softwareprogramme, die systematisch das Internet durchsuchen, Links folgen und Inhalte herunterladen, um sie zu indexieren, zu analysieren oder für verschiedene Zwecke zu sammeln. Diese Crawler lesen die Datei robots.txt, die sich im Root-Verzeichnis einer Website befindet und Anweisungen enthält, welche Bereiche der Seite von automatisierten Besuchern betreten oder nicht betreten werden dürfen. Die robots.txt-Datei verwendet spezifische Direktiven wie User-agent, Disallow und Allow, um die Zugriffsrechte für Crawler zu kommunizieren – die Einhaltung ist jedoch freiwillig und hängt davon ab, ob der Entwickler des Crawlers diese Vorgaben respektiert. Zusätzlich zu robots.txt können Websites ihre Wünsche durch HTTP-Header und Meta-Tags übermitteln, die weitere Hinweise zu Nutzungsrechten und Einschränkungen liefern. Verschiedene Crawler-Typen halten sich unterschiedlich streng an diese Signale:
| Crawler-Typ | robots.txt-Konformität | Meta-Tag-Respekt | KI-Training-Nutzung |
|---|---|---|---|
| Suchmaschinen | Hoch | Hoch | Begrenzt |
| KI-Trainings-Bots | Mittel | Mittel | Ja |
| Kommerzielle Scraper | Niedrig | Niedrig | Variabel |
| Akademische Bots | Hoch | Mittel | Nur Forschung |
| Bösartige Bots | Keine | Keine | Unbeschränkt |
Die Direktiven noai und noimageai dienen ähnlichen, aber unterschiedlichen Zwecken im Schutz von Inhalten, wobei der Hauptunterschied in ihrem Umfang und ihrer Spezifizität liegt. Die noai-Direktive ist ein breiteres Signal, das anzeigt, dass sämtliche Inhalte einer Seite – darunter Text, Bilder, Code und andere Medien – nicht für KI-Trainingszwecke verwendet werden dürfen. Sie eignet sich für Websites mit gemischten Inhalten oder für solche, die umfassenden Schutz wünschen. Die noimageai-Direktive hingegen zielt ausschließlich auf Bildinhalte ab und ermöglicht, dass Text und andere nicht-bildliche Materialien eventuell für Training genutzt werden, während visuelle Assets vor KI-Modell-Training geschützt bleiben. Diese Unterscheidung ist besonders für Websites wichtig, die eine Textindexierung durch KI (etwa für Suchmaschinen oder Barrierefreiheit) erlauben wollen, ihre Bilder aber vor der Nutzung durch generative Bildmodelle schützen möchten. Die Implementierungsunterschiede sehen so aus:
<!-- Umfassender Schutz für alle Inhalte -->
<meta name="robots" content="noai">
<!-- Spezifischer Schutz nur für Bilder -->
<meta name="robots" content="noimageai">
<!-- Kombinierter Ansatz für maximale Klarheit -->
<meta name="robots" content="noai, noimageai">
Das NoAI-Meta-Tag kann auf verschiedene Arten implementiert werden, wobei jede Methode eigene Vorteile bietet – abhängig von Ihrer technischen Infrastruktur und den konkreten Anforderungen. Der einfachste Weg ist das Einfügen des Meta-Tags direkt in den <head>-Bereich Ihres HTMLs; diese Methode gilt seitenweise und kann bei Bedarf individuell angepasst werden. Für Websites mit vielen Seiten oder für eine standortweite Lösung eignet sich die Implementierung per HTTP-Response-Header, die ohne Seitenanpassungen einheitlich für alle Inhalte gilt. Außerdem kann die Datei robots.txt Direktiven enthalten, die speziell auf KI-Crawler abzielen, wobei diese Methode weniger standardisiert ist als Meta-Tags oder Header. Hier die drei wichtigsten Implementierungsmethoden:
<!-- Methode 1: HTML-Meta-Tag (am gebräuchlichsten) -->
<head>
<meta name="robots" content="noai">
</head>
# Methode 2: robots.txt-Direktive
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Methode 3: HTTP-Header (über .htaccess oder Serverkonfiguration)
X-Robots-Tag: noai
Für Apache-Server fügen Sie dies in .htaccess ein:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Für Nginx-Server fügen Sie es in den server block ein:
add_header X-Robots-Tag "noai" always;
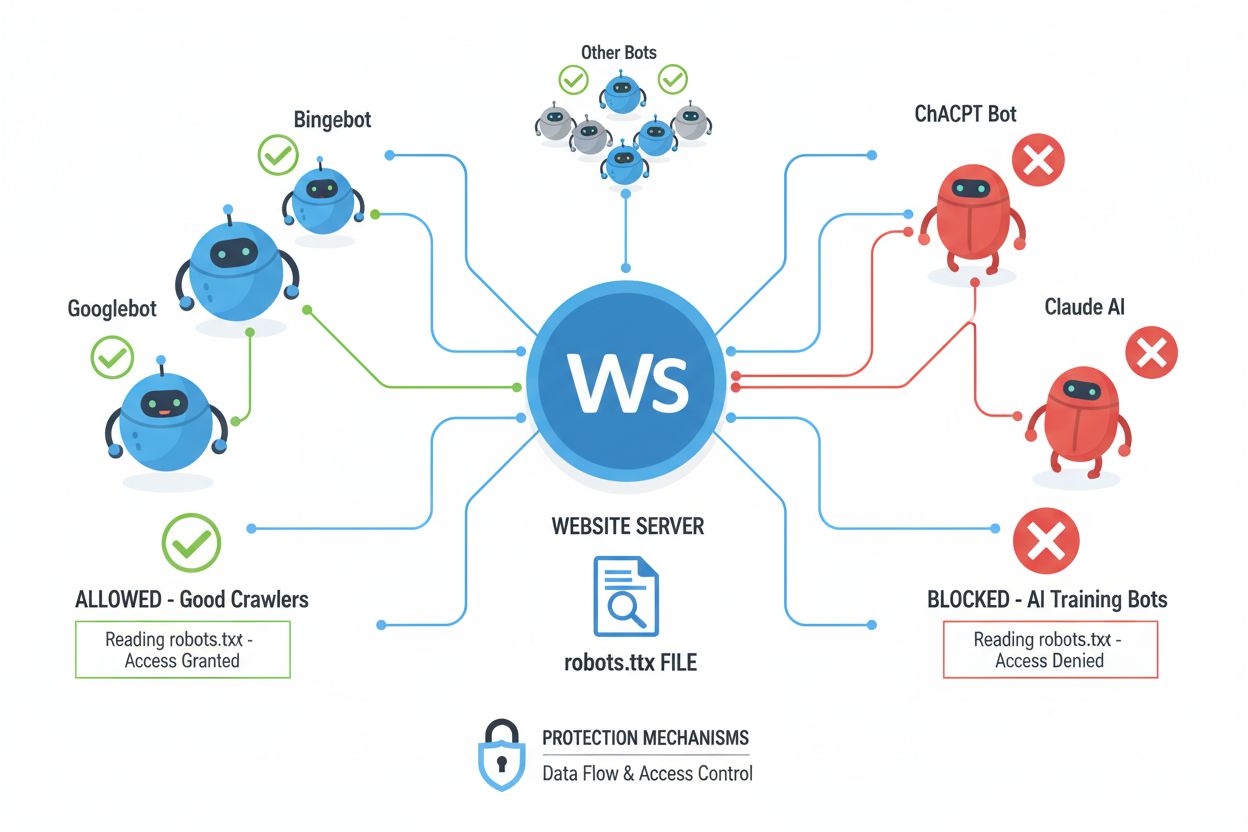
Das NoAI-Meta-Tag ist ein wichtiger Schritt zum Schutz von Inhalten, funktioniert jedoch auf Vertrauensbasis und ist vollständig davon abhängig, ob KI-Entwickler und Datenscraper das Signal respektieren. Große KI-Unternehmen wie OpenAI, Google und Anthropic berücksichtigen NoAI-Direktiven inzwischen in ihren Crawlern, aber böswillige Akteure und unerlaubte Scraper ignorieren diese Signale häufig, sodass das Tag gegen entschlossene Datendiebe wirkungslos bleibt. Die Wirksamkeit von NoAI ist außerdem dadurch begrenzt, dass es nur das künftige Training auf Inhalten verhindert; bereits gesammelte und in bestehenden Modellen verwendete Daten können nicht entfernt werden, und bei Verstößen gibt es keinen Rechtsweg. Die Einhaltungsquoten sind je nach KI-System sehr unterschiedlich – manche respektieren die Direktive, andere umgehen sie absichtlich. NoAI bietet auch keinen Schutz gegen direkte Downloads, Screenshots oder manuelles Kopieren von Inhalten und kann nicht verhindern, dass Wettbewerber Ihre Inhalte nutzen, wenn sie die Direktive ignorieren. Deshalb sollte NoAI als eine Ebene einer umfassenden Schutzstrategie gesehen werden und nicht als vollständige Lösung.
Das NoAI-Meta-Tag hat bei großen KI-Unternehmen und Plattformen breite Akzeptanz gefunden. OpenAI, Google und Stability AI haben öffentlich zugesagt, die Direktive in ihren Trainingspipelines zu respektieren. Die Einführung von NoAI durch DeviantArt hat die branchenweite Diskussion über ethische KI-Entwicklung und Urheber-Zustimmung vorangebracht und das Bewusstsein bei KI-Entwicklern und Content-Erstellern gestärkt. Allerdings bleibt die Akzeptanz branchenweit uneinheitlich, wobei kleinere KI-Unternehmen, akademische Forscher und kommerzielle Scraper unterschiedliche Grade der Einhaltung zeigen. Die Entwicklung konkurrierender Standards wie C2PA (Coalition for Content Provenance and Authenticity) und Gespräche über maschinenlesbare Rechteausdrücke zeigen, dass die Branche an fortschrittlicheren, rechtlich abgesicherten Schutzmechanismen arbeitet. Branchenverbände und Standardisierungsgremien arbeiten aktiv an der Formalisierung dieser Schutzmaßnahmen, und künftige KI-Regulierungen könnten eine explizite Einhaltung der Präferenzen von Urhebern vorschreiben – wodurch NoAI von einem freiwilligen Signal zu einer rechtlich durchsetzbaren Anforderung werden könnte.
Die Implementierung von NoAI-Schutz sollte Teil eines mehrschichtigen Ansatzes zur Inhaltssicherheit sein und nicht als alleinige Lösung betrachtet werden. Kombinieren Sie technische, rechtliche und Überwachungsmaßnahmen für umfassenden Schutz. Für maximale Wirksamkeit beachten Sie diese Best Practices:
Führen Sie außerdem regelmäßige Audits Ihrer Schutzmaßnahmen durch, um sicherzustellen, dass alle Seiten die passenden Direktiven enthalten, und nutzen Sie automatisierte Tools, um Ihre Inhalte in öffentlichen KI-Datensätzen und Trainings-Repositorien zu finden. Dokumentieren Sie Ihre NoAI-Implementierung als Teil Ihrer Content-Governance-Strategie und kommunizieren Sie diese Schutzmaßnahmen gegenüber Ihrem Publikum – insbesondere, wenn Sie als Plattform nutzergenerierte Inhalte hosten.
Die noai-Direktive schützt alle Inhaltstypen (Text, Bilder, Code) vor KI-Training, während noimageai speziell nur Bildinhalte schützt. Verwenden Sie noai für umfassenden Schutz und noimageai, wenn Sie die Indizierung von Text erlauben, aber visuelle Inhalte vor generativen Bildmodellen schützen möchten.
Nein, das NoAI-Meta-Tag funktioniert auf Vertrauensbasis und hängt davon ab, ob KI-Entwickler sich daran halten. Große Unternehmen wie OpenAI und Google respektieren es, aber böswillige Akteure und unerlaubte Scraper ignorieren diese Signale häufig, sodass es nur eine Schutzmaßnahme unter mehreren darstellt und keine vollständige Lösung ist.
Sie können es auf drei Arten implementieren: Fügen Sie das HTML-Meta-Tag in den Seitenkopf ein, setzen Sie HTTP-Response-Header auf Ihrem Server oder fügen Sie Direktiven in Ihre robots.txt-Datei ein. Die HTML-Meta-Tag-Methode ist für die meisten Website-Betreiber am gebräuchlichsten und unkompliziertesten.
Große KI-Unternehmen wie OpenAI (ChatGPT), Google, Anthropic (Claude) und Stability AI haben öffentlich zugesagt, NoAI-Direktiven in ihren Trainingsprozessen zu respektieren. Die Einhaltung variiert jedoch bei kleineren KI-Unternehmen, akademischen Forschern und kommerziellen Scraper-Diensten.
Ja, Sie können beides gleichzeitig für maximale Wirksamkeit einsetzen. Das NoAI-Meta-Tag und robots.txt-Direktiven arbeiten zusammen, um Ihre Schutzwünsche gegenüber unterschiedlichen Crawlern und Systemen zu kommunizieren.
Kombinieren Sie NoAI mit weiteren Schutzmethoden wie HTTP-Headern, robots.txt-Regeln, Wasserzeichen, Zugangskontrollen und rechtlichen Nutzungsbedingungen. Überwachen Sie Ihre Inhalte in KI-Datensätzen und nutzen Sie Tools, um unerlaubte Nutzung zu verfolgen.
Obwohl es von großen KI-Unternehmen weitgehend übernommen wurde, ist NoAI noch kein offizieller W3C-Standard. Branchenorganisationen arbeiten jedoch an fortschrittlicheren Standards wie C2PA und maschinenlesbaren Rechteausdrücken, die künftig rechtliche Unterstützung bieten könnten.
NoAI ist am effektivsten, wenn es mit anderen Methoden wie robots.txt, HTTP-Headern, Wasserzeichen, Zugangskontrollen und rechtlichem Schutz kombiniert wird. Keine einzelne Methode bietet vollständigen Schutz, daher wird ein mehrschichtiger Ansatz für umfassende Sicherheit empfohlen.
Verfolgen Sie, welche KI-Systeme Ihre Marke und Inhalte mit der KI-Überwachungsplattform von AmICited zitieren. Sehen Sie genau, wie Ihre Arbeit von ChatGPT, Perplexity, Google AI Overviews und anderen KI-Systemen genutzt wird.
Erfahren Sie mehr über das NoAI-Meta-Tag, wie es das Sammeln von Trainingsdaten für KI verhindert, welche Einschränkungen es gibt und wie Sie es auf Ihrer Websi...
Community-Diskussion über das noai-Meta-Tag und ob es Inhalte effektiv vor KI-Training schützt. Nutzer teilen Erfahrungen und Grenzen dieses Ansatzes.
Entdecken Sie, wie sich Meta-Tags für KI-gesteuerte Suche entwickelt haben. Erfahren Sie, welche Meta-Tags für KI-Optimierung und Sichtbarkeit in AI Overviews a...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.