Une balise meta HTML qui signale aux systèmes d’entraînement d’IA et aux robots d’indexation que le contenu du site web ne doit pas être utilisé pour l’entraînement de modèles d’apprentissage automatique. Initialement introduite par DeviantArt, elle sert de mécanisme de protection de contenu et de signal d’exclusion pour les créateurs préoccupés par la collecte non autorisée de données par l’IA.
Balise Meta NoAI
Une balise meta HTML qui signale aux systèmes d'entraînement d'IA et aux robots d'indexation que le contenu du site web ne doit pas être utilisé pour l'entraînement de modèles d'apprentissage automatique. Initialement introduite par DeviantArt, elle sert de mécanisme de protection de contenu et de signal d'exclusion pour les créateurs préoccupés par la collecte non autorisée de données par l'IA.
Qu’est-ce que la balise meta NoAI
La balise meta NoAI est un mécanisme de protection de contenu mis en œuvre sous forme de balise meta HTML qui signale aux systèmes d’entraînement d’IA et aux robots d’indexation que le contenu d’un site web ne doit pas être utilisé pour l’entraînement de modèles d’apprentissage automatique. Initialement introduite par DeviantArt en septembre 2022, la directive NoAI est apparue comme une réponse communautaire aux inquiétudes concernant le scraping des œuvres des artistes et leur utilisation pour entraîner des modèles génératifs d’IA sans consentement ni compensation. La balise meta fonctionne en ajoutant une simple déclaration HTML dans l’en-tête d’une page web, communiquant ainsi une préférence claire aux systèmes d’IA quant à l’interdiction d’utiliser le contenu à des fins d’entraînement. Bien qu’elle n’ait pas de valeur légale dans la plupart des juridictions, la balise NoAI représente un important mécanisme d’exclusion pour les créateurs souhaitant protéger leur propriété intellectuelle à l’ère d’une collecte de données IA de plus en plus agressive.
Comment fonctionnent les robots d’indexation
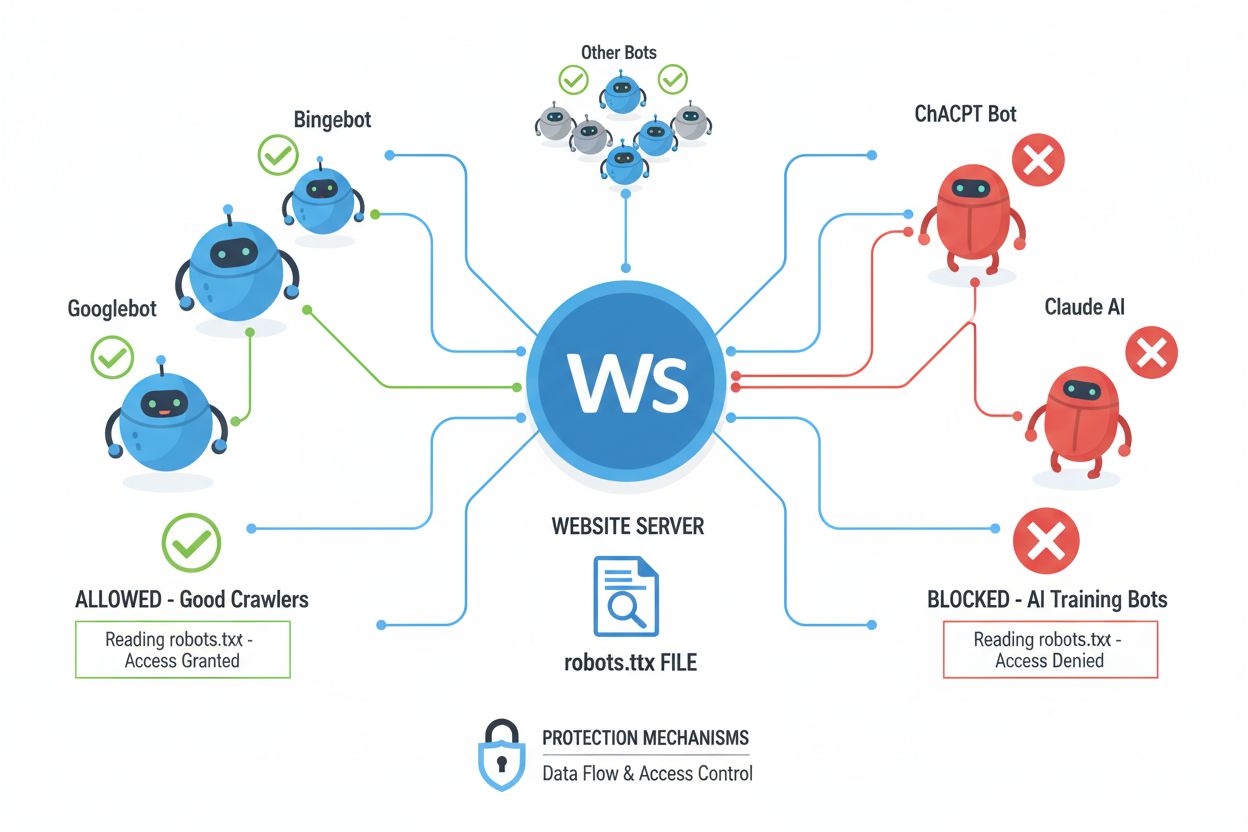
Les robots d’indexation (également appelés bots, spiders ou scrapers) sont des programmes logiciels automatisés qui parcourent systématiquement Internet, suivent les liens et téléchargent du contenu pour l’indexer, l’analyser ou collecter des données à diverses fins. Ces robots opèrent en lisant le fichier robots.txt situé à la racine d’un site web, qui contient des instructions indiquant quelles parties du site peuvent ou non être accessibles aux visiteurs automatisés. Le fichier robots.txt utilise des directives spécifiques telles que User-agent, Disallow et Allow pour communiquer les permissions, mais le respect de ces directives est entièrement volontaire et dépend du choix du développeur du robot. Au-delà de robots.txt, les sites web peuvent communiquer leurs préférences via des en-têtes HTTP et des balises meta, fournissant ainsi des signaux supplémentaires concernant les droits d’utilisation et les restrictions du contenu. Différents types de robots respectent plus ou moins ces signaux :
Robots des moteurs de recherche (Google, Bing, DuckDuckGo) : respectent généralement robots.txt et les balises meta pour maintenir de bonnes relations avec les propriétaires de sites web
Robots d’entraînement IA (Common Crawl, Apify, scrapers IA spécialisés) : ont historiquement ignoré les signaux de protection de contenu, même si cela évolue avec l’apparition de nouvelles normes
Scrapers commerciaux : ignorent souvent complètement robots.txt, privilégiant la collecte de données aux préférences des propriétaires de sites
Robots de recherche académique : respectent généralement robots.txt mais peuvent avoir des standards différents pour la recherche
Bots malveillants : ignorent délibérément tous les signaux et restrictions pour extraire des données sans autorisation
Type de robot
Respect de robots.txt
Respect de la balise meta
Utilisation pour l’entraînement IA
Moteurs de recherche
Élevé
Élevé
Limité
Bots d’entraînement IA
Moyen
Moyen
Oui
Scrapers commerciaux
Faible
Faible
Variable
Bots académiques
Élevé
Moyen
Recherche uniquement
Bots malveillants
Aucun
Aucun
Non restreint
NoAI vs NoImageAI
Les directives noai et noimageai ont des objectifs similaires mais distincts en matière de protection de contenu, la différence clé résidant dans leur portée et leur spécificité. La directive noai est un signal plus large indiquant que tout le contenu d’une page — y compris le texte, les images, le code et autres médias — ne doit pas être utilisé à des fins d’entraînement IA, ce qui la rend adaptée aux sites avec des contenus mixtes ou recherchant une protection complète. La directive noimageai, en revanche, cible spécifiquement uniquement le contenu image, permettant au texte et aux autres éléments non visuels d’être éventuellement utilisés pour l’entraînement tout en protégeant les ressources visuelles des modèles génératifs d’images. Cette distinction est particulièrement importante pour les sites qui souhaitent permettre l’indexation du texte par l’IA (pour les moteurs de recherche ou l’accessibilité) tout en protégeant leur contenu visuel de l’entraînement par l’IA. Voici les différences d’implémentation :
<!-- Protection complète pour tout le contenu --><metaname="robots"content="noai">
<!-- Protection spécifique pour les images uniquement --><metaname="robots"content="noimageai">
<!-- Approche combinée pour une clarté maximale --><metaname="robots"content="noai, noimageai">
Méthodes d’implémentation
La balise meta NoAI peut être implémentée via plusieurs méthodes, chacune présentant des avantages selon votre infrastructure technique et vos besoins spécifiques. L’approche la plus simple consiste à ajouter la balise meta directement dans la section <head> de votre HTML, ce qui applique la directive à chaque page et peut être personnalisé page par page si nécessaire. Pour les sites comprenant de nombreuses pages ou recherchant une solution globale, l’implémentation via les en-têtes de réponse HTTP offre une méthode plus évolutive qui s’applique uniformément à tout le contenu sans modification individuelle des pages. De plus, le fichier robots.txt peut inclure des directives ciblant certains robots IA, même si cette méthode est moins standardisée que les balises meta ou les en-têtes. Voici les trois principales méthodes d’implémentation :
<!-- Méthode 1 : Balise meta HTML (la plus courante) --><head>
<metaname="robots"content="noai">
</head>
# Méthode 3 : En-tête HTTP (via .htaccess ou configuration du serveur)
X-Robots-Tag: noai
Pour les serveurs Apache, ajoutez à .htaccess :
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Pour les serveurs Nginx, ajoutez dans votre bloc serveur :
add_header X-Robots-Tag "noai" always;
Efficacité et limitations
Bien que la balise meta NoAI représente une avancée importante pour la protection du contenu, elle fonctionne selon un système d’honneur qui dépend entièrement du respect ou non du signal par les développeurs d’IA et les scrapers de données. Les grandes entreprises d’IA comme OpenAI, Google et Anthropic ont commencé à respecter les directives NoAI dans leurs robots, mais les acteurs malveillants et les scrapers indésirables ignorent fréquemment ces signaux, rendant la balise inefficace face aux voleurs de données déterminés. L’efficacité de NoAI est aussi limitée par le fait qu’elle ne prévient que l’entraînement futur sur le contenu : elle ne peut pas supprimer les données déjà collectées et utilisées dans des modèles existants, ni offrir de recours juridique en cas de violation. Les taux de conformité varient fortement selon les systèmes d’IA : certains respectent la directive, d’autres la contournent délibérément, ce qui fait de NoAI une solution utile mais incomplète. La balise n’offre aucune protection contre les téléchargements directs, captures d’écran ou copies manuelles du contenu, et ne peut empêcher l’utilisation de votre contenu par des concurrents qui ignorent simplement la directive. Pour toutes ces raisons, NoAI doit être considéré comme une couche parmi d’autres dans une stratégie de protection globale du contenu, et non comme une solution unique.
Adoption industrielle et standards
La balise meta NoAI a connu une adoption significative parmi les grandes entreprises et plateformes d’IA, OpenAI, Google et Stability AI s’étant publiquement engagés à respecter la directive dans leurs pipelines d’entraînement. L’implémentation de NoAI par DeviantArt a influencé des discussions industrielles plus larges sur le développement éthique de l’IA et le consentement des créateurs, sensibilisant à la fois les développeurs d’IA et les créateurs de contenu. Cependant, l’adoption reste inégale dans l’industrie, les petites entreprises d’IA, les chercheurs universitaires et les scrapers commerciaux affichant des niveaux de conformité variables. L’apparition de standards concurrents comme C2PA (Coalition for Content Provenance and Authenticity) et les discussions autour d’expressions de droits lisibles par machine indiquent que l’industrie évolue vers des mécanismes de protection plus sophistiqués et juridiquement contraignants au-delà des balises meta volontaires. Les organismes et groupes de standardisation œuvrent activement à formaliser ces protections, avec l’espoir que de futures réglementations sur l’IA imposeront le respect explicite des préférences des créateurs, transformant potentiellement NoAI d’un signal volontaire en une exigence légalement exécutoire.
Bonnes pratiques et recommandations
La mise en œuvre de la protection NoAI doit faire partie d’une approche en couches de la sécurité du contenu, combinant des stratégies techniques, juridiques et de surveillance pour une protection globale. Pour maximiser l’efficacité, suivez ces bonnes pratiques :
Implémentez via toutes les méthodes : utilisez les balises meta HTML, les en-têtes HTTP et les directives robots.txt simultanément pour toucher différents types de robots et systèmes
Surveillez la conformité : vérifiez régulièrement votre contenu dans les jeux de données d’entraînement IA et utilisez des outils pour détecter son éventuelle présence dans les modèles populaires
Combinez avec des protections juridiques : incluez des conditions d’utilisation claires et des mentions de droits d’auteur interdisant explicitement l’entraînement IA
Utilisez le watermarking et le fingerprinting : ajoutez des marqueurs invisibles ou visibles à votre contenu pour suivre son utilisation non autorisée et prouver la propriété
Mettez en place des contrôles d’accès : recourez à l’authentification, aux paywalls ou à la limitation du débit pour empêcher le scraping à grande échelle, indépendamment des balises meta
Restez informé des normes : suivez l’évolution des standards comme C2PA et participez aux discussions sectorielles sur la protection du contenu
En complément, effectuez régulièrement des audits de votre implémentation de protection pour vous assurer que toutes les pages incluent les directives appropriées, et envisagez d’utiliser des outils automatisés pour scanner votre contenu dans les jeux de données publics d’IA et les référentiels d’entraînement. Documentez votre démarche NoAI dans votre politique de gouvernance de contenu, et communiquez ces protections à votre audience afin qu’elle comprenne les mesures mises en place, notamment si vous hébergez des contenus générés par des utilisateurs.
Questions fréquemment posées
La directive noai protège tous les types de contenu (texte, images, code) contre l'entraînement par l'IA, tandis que noimageai protège spécifiquement uniquement le contenu image. Utilisez noai pour une protection globale et noimageai lorsque vous souhaitez autoriser l'indexation du texte mais protéger les ressources visuelles des modèles génératifs d'images.
Non, la balise meta NoAI fonctionne sur la base d'un système d'honneur et dépend du fait que les développeurs d'IA choisissent ou non de la respecter. Les grandes entreprises comme OpenAI et Google la respectent, mais les acteurs malveillants et les robots indésirables ignorent fréquemment ces signaux, ce qui en fait une couche de protection parmi d'autres plutôt qu'une solution complète.
Vous pouvez l'implémenter de trois manières : ajouter la balise meta HTML dans l'en-tête de votre page, définir des en-têtes de réponse HTTP sur votre serveur ou inclure des directives dans votre fichier robots.txt. La méthode de la balise meta HTML est la plus courante et la plus simple pour la plupart des propriétaires de sites web.
Les principales entreprises d'IA, dont OpenAI (ChatGPT), Google, Anthropic (Claude) et Stability AI se sont publiquement engagées à respecter les directives NoAI dans leurs pipelines d'entraînement. Cependant, la conformité varie selon les petites entreprises d'IA, les chercheurs universitaires et les scrapers commerciaux.
Oui, vous pouvez utiliser les deux simultanément pour une efficacité maximale. La balise meta NoAI et les directives robots.txt fonctionnent ensemble pour communiquer vos préférences de protection de contenu à différents types de robots et de systèmes.
Combinez NoAI avec d'autres méthodes de protection, notamment les en-têtes HTTP, les règles robots.txt, le watermarking, les contrôles d'accès et les conditions d'utilisation juridiques. Surveillez la présence de votre contenu dans les jeux de données d'IA et envisagez d'utiliser des outils pour suivre toute utilisation non autorisée.
Bien qu'adoptée par de grandes entreprises d'IA, NoAI n'est pas encore une norme formelle du W3C. Cependant, des organisations industrielles travaillent sur des normes plus sophistiquées comme C2PA et des expressions de droits lisibles par machine qui pourraient à terme offrir une assise juridique.
NoAI est plus efficace lorsqu'elle est combinée à d'autres méthodes telles que robots.txt, les en-têtes HTTP, le watermarking, les contrôles d'accès et les protections juridiques. Aucune méthode seule n'offre une protection complète, il est donc recommandé d'adopter une approche en couches pour une sécurité optimale du contenu.
Surveillez comment l'IA référence votre contenu
Suivez quels systèmes d'IA citent votre marque et votre contenu grâce à la plateforme de surveillance IA d'AmICited. Sachez exactement comment votre travail est utilisé par ChatGPT, Perplexity, Google AI Overviews et d'autres systèmes d'IA.
Qu'est-ce que la balise meta noai et comment protège-t-elle votre contenu de l’IA ?
Découvrez la balise meta noai, son fonctionnement pour empêcher la collecte de données d’entraînement par l’IA, ses limites, et comment la mettre en œuvre sur v...
Découvrez comment les balises méta ont évolué pour la recherche pilotée par l'IA. Apprenez quelles balises méta sont les plus importantes pour l’optimisation IA...
Le méta-tag noai peut-il réellement protéger mon contenu de l’entraînement des IA ? Ou est-ce juste un vœu pieux ?
Discussion communautaire sur le méta-tag noai et son efficacité à protéger le contenu contre l'entraînement des IA. Les utilisateurs partagent leurs expériences...
8 min de lecture
Discussion
Content Protection
+2
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.