Et HTML meta-tag, der signalerer til AI-træningssystemer og webcrawlere, at webstedets indhold ikke må bruges til træning af maskinlæringsmodeller. Oprindeligt introduceret af DeviantArt, fungerer det som en mekanisme til at beskytte indhold og et fravalgssignal for skabere, der er bekymrede for uautoriseret AI-datasamling.
NoAI Meta Tag
Et HTML meta-tag, der signalerer til AI-træningssystemer og webcrawlere, at webstedets indhold ikke må bruges til træning af maskinlæringsmodeller. Oprindeligt introduceret af DeviantArt, fungerer det som en mekanisme til at beskytte indhold og et fravalgssignal for skabere, der er bekymrede for uautoriseret AI-datasamling.
Hvad er NoAI Meta Tag
NoAI meta tagget er en mekanisme til indholdsbeskyttelse, der implementeres som et HTML meta-tag og signalerer til AI-træningssystemer og webcrawlere, at et websteds indhold ikke må bruges til træning af maskinlæringsmodeller. Oprindeligt introduceret af DeviantArt i september 2022 opstod NoAI-direktivet som et græsrodsinitiativ som reaktion på bekymringer om, at kunstneres arbejde blev scraped og brugt til at træne generative AI-modeller uden samtykke eller kompensation. Meta tagget fungerer ved at tilføje en simpel HTML-erklæring i en webside-header, der kommunikerer et klart ønske til AI-systemer om, at indholdet ikke må bruges til træningsformål. Selvom det ikke er juridisk bindende i de fleste jurisdiktioner, repræsenterer NoAI-tagget en vigtig fravalgsmekanisme for skabere, der ønsker at beskytte deres intellektuelle ejendomsret i en tid med stadig mere aggressiv AI-datasamling.
Sådan fungerer webcrawlere
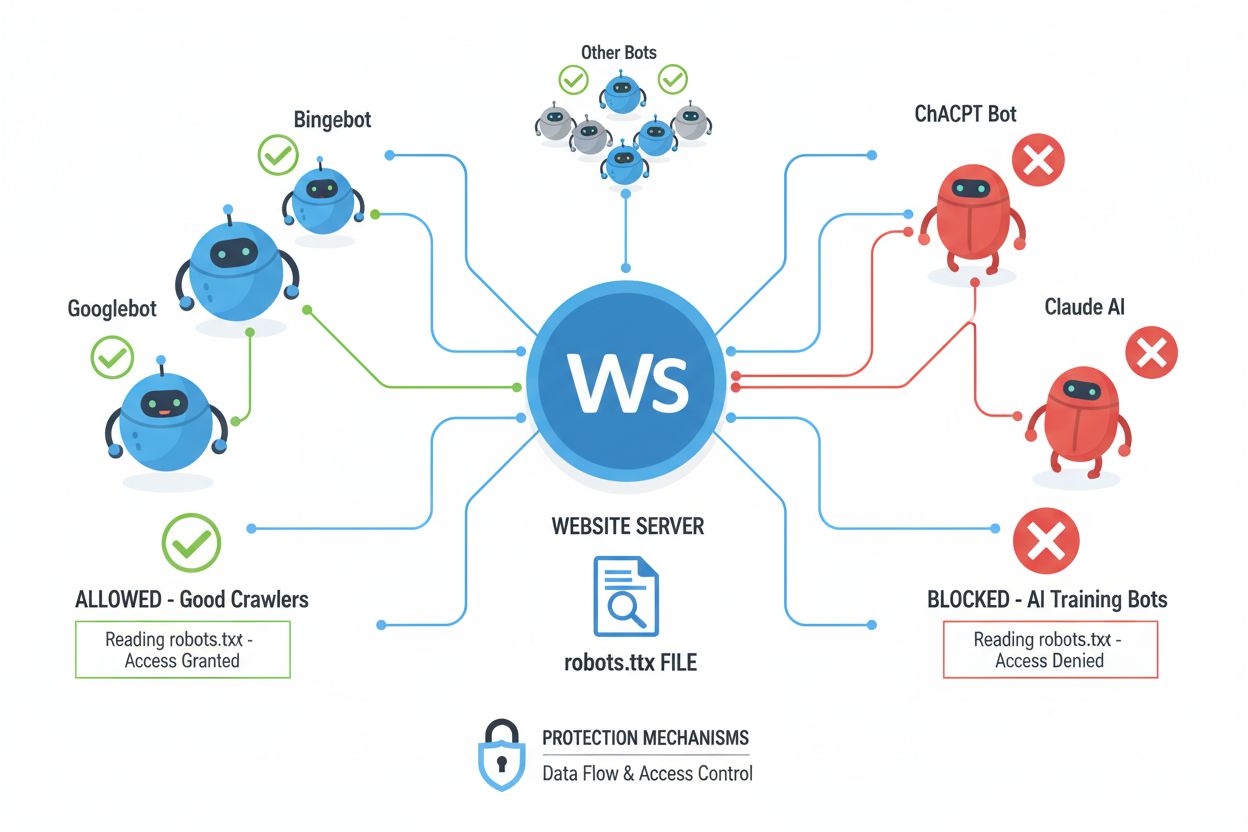
Webcrawlere (også kaldet bots, spiders eller scrapers) er automatiserede softwareprogrammer, der systematisk gennemgår internettet, følger links og downloader indhold for at indeksere, analysere eller indsamle data til forskellige formål. Disse crawlere fungerer ved at læse filen robots.txt, der ligger i roden af et websted, og som indeholder instruktioner om, hvilke områder af siden automatiske besøgende må eller ikke må tilgå. robots.txt-filen bruger specifikke direktiver som User-agent, Disallow og Allow til at kommunikere crawler-adgang, men overholdelse er helt frivillig og afhænger af, om crawlerens udvikler vælger at respektere retningslinjerne. Ud over robots.txt kan websteder kommunikere præferencer via HTTP-headers og meta tags, der giver ekstra signaler om brugsrettigheder og begrænsninger på indholdet. Forskellige typer crawlere respekterer disse signaler i varierende grad:
Søgemaskinecrawlere (Google, Bing, DuckDuckGo): Respekterer generelt robots.txt og meta tags for at opretholde gode relationer til websideejere
AI-træningscrawlere (Common Crawl, Apify, specialiserede AI-scrapers): Har historisk ignoreret indholdsbeskyttelsessignaler, men dette ændrer sig med nye standarder
Kommercielle datacrawlere: Ignorerer ofte robots.txt helt og prioriterer dataindsamling over websideejerens ønsker
Akademiske forskningsbots: Respekterer typisk robots.txt, men kan have andre standarder til forskningsformål
Onskabsfulde bots: Ignorerer bevidst alle signaler og begrænsninger for at udtrække data til uautoriserede formål
Crawler type
robots.txt-overholdelse
Meta tag-respekt
AI-træningsbrug
Søgemaskiner
Høj
Høj
Begrænset
AI-træningsbots
Medium
Medium
Ja
Kommercielle scrapers
Lav
Lav
Varierer
Akademiske bots
Høj
Medium
Kun forskning
Onskabsfulde bots
Ingen
Ingen
Ubegrænset
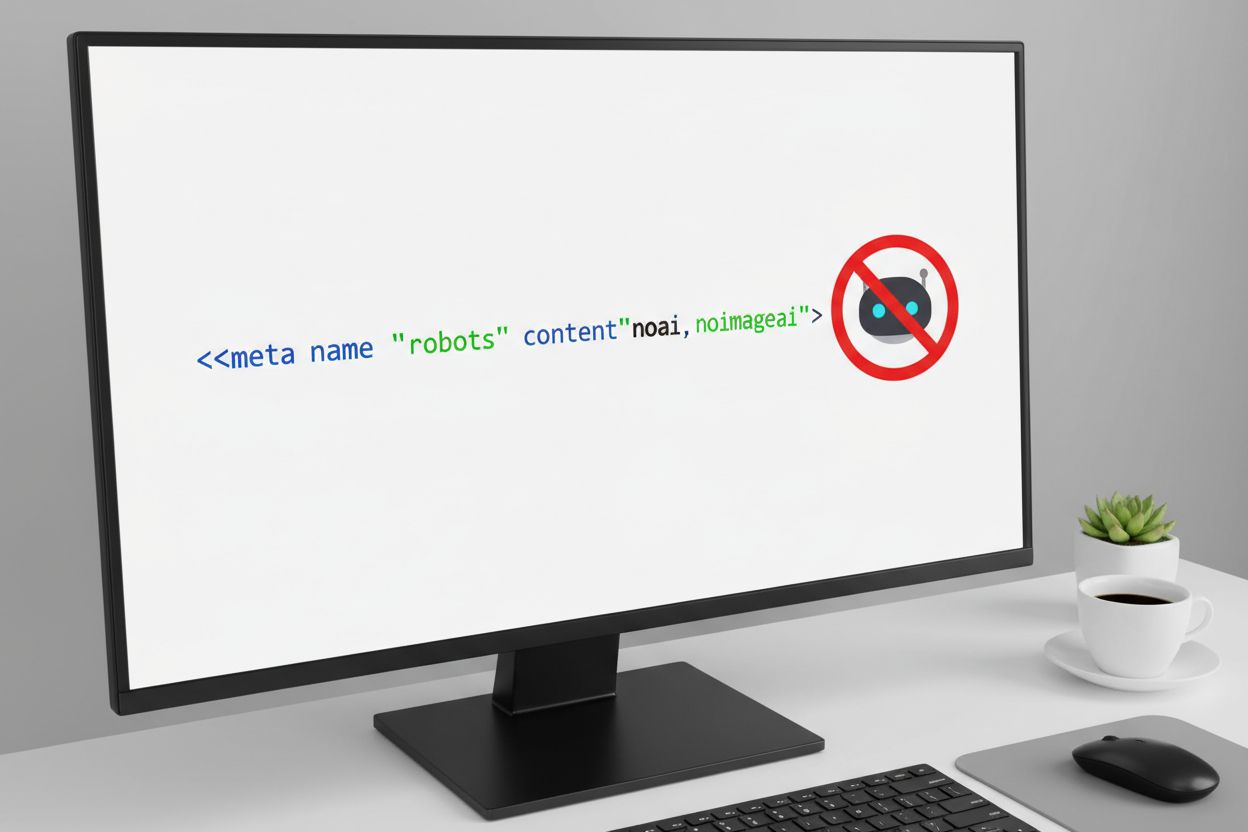
NoAI vs NoImageAI
noai- og noimageai-direktiverne tjener beslægtede, men forskellige formål for indholdsbeskyttelse, hvor hovedforskellen ligger i deres omfang og specificitet. noai-direktivet er et bredt signal, der indikerer, at alt indhold på en side – inklusive tekst, billeder, kode og andre medier – ikke må bruges til AI-træning, hvilket gør det egnet til websteder med blandede indholdstyper eller dem, der ønsker omfattende beskyttelse. noimageai-direktivet retter sig derimod specifikt mod billedindhold og tillader, at tekst og andet ikke-billedmateriale potentielt bruges til træning, mens visuelle aktiver beskyttes mod AI-modeltræning. Denne forskel er særlig vigtig for websteder, der ønsker at tillade tekstbaseret AI-indeksering (f.eks. til søgemaskiner eller tilgængelighed), men beskytte deres visuelle indhold mod brug i generative billedmodeller. Her er forskellene i implementering:
<!-- Omfattende beskyttelse af alt indhold --><metaname="robots"content="noai">
<!-- Specifik beskyttelse af kun billeder --><metaname="robots"content="noimageai">
<!-- Kombineret tilgang for maksimal tydelighed --><metaname="robots"content="noai, noimageai">
Implementeringsmetoder
NoAI meta tagget kan implementeres på flere måder, hver med forskellige fordele afhængigt af din tekniske infrastruktur og specifikke behov. Den mest ligetil tilgang er at tilføje meta tagget direkte i din HTML-<head>-sektion, hvilket gælder direktivet for de enkelte sider og kan tilpasses side for side, hvis nødvendigt. For websteder med mange sider eller som ønsker en løsning på tværs af hele sitet, giver implementering via HTTP-responsheaders en mere skalerbar tilgang, der gælder ensartet på alt indhold uden behov for at ændre de enkelte sider. Derudover kan robots.txt-filen inkludere direktiver målrettet bestemte AI-crawlere, selvom denne metode er mindre standardiseret end meta tags eller headers. Her er de tre primære implementeringsmetoder:
<!-- Metode 1: HTML Meta Tag (mest almindelig) --><head>
<metaname="robots"content="noai">
</head>
# Metode 2: robots.txt-direktiv
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metode 3: HTTP-header (via .htaccess eller serverkonfiguration)
X-Robots-Tag: noai
For Apache-servere, tilføj til .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
For Nginx-servere, tilføj til din serverblok:
add_header X-Robots-Tag "noai" always;
Effektivitet og begrænsninger
Selvom NoAI meta tagget er et vigtigt skridt mod indholdsbeskyttelse, fungerer det på et æressystem, der udelukkende afhænger af, om AI-udviklere og datacrawlere vælger at respektere signalet. Store AI-virksomheder som OpenAI, Google og Anthropic er begyndt at respektere NoAI-direktiver i deres crawlere, men ondsindede aktører og uautoriserede scrapers ignorerer ofte disse signaler, hvilket gør tagget ineffektivt mod målrettede datatyve. Effektiviteten af NoAI er desuden begrænset af, at det kun forhindrer fremtidig træning på indholdet; det kan ikke fjerne data, der allerede er indsamlet og brugt i eksisterende modeller, og det giver ikke juridisk mulighed for at håndhæve, hvis det bliver overtrådt. Overholdelsesraten varierer betydeligt mellem forskellige AI-systemer, hvor nogle respekterer direktivet, mens andre bevidst omgår det – hvilket gør NoAI til en nyttig, men ufuldstændig løsning. Tagget giver heller ingen beskyttelse mod direkte downloads, screenshots eller manuel kopiering af indholdet, og det kan ikke forhindre konkurrenter i at bruge dit indhold, hvis de vælger at ignorere direktivet. Af disse grunde bør NoAI betragtes som ét lag i en samlet strategi for beskyttelse af indhold, ikke som en fuldkommen løsning.
Industriaccept og standarder
NoAI meta tagget har opnået betydelig udbredelse blandt store AI-virksomheder og platforme, hvor OpenAI, Google og Stability AI offentligt har forpligtet sig til at respektere direktivet i deres træningsprocesser. DeviantArts implementering af NoAI har påvirket bredere samtaler i industrien om etisk AI-udvikling og skaberes samtykke, hvilket har øget bevidstheden blandt både AI-udviklere og indholdsskabere. Dog er udbredelsen inkonsekvent på tværs af branchen, hvor mindre AI-virksomheder, akademiske forskere og kommercielle scrapers viser varierende grad af overholdelse. Opkomsten af konkurrerende standarder som C2PA (Coalition for Content Provenance and Authenticity) og diskussioner om maskinlæsbare rettighedsudtryk tyder på, at branchen bevæger sig mod mere avancerede, juridisk understøttede mekanismer til indholdsbeskyttelse ud over frivillige meta tags. Brancheorganisationer og standardiseringsorganer arbejder aktivt på at formalisere disse beskyttelser, med forventning om at fremtidig AI-regulering kan kræve eksplicit overholdelse af indholdsskaberes præferencer og potentielt forvandle NoAI fra et frivilligt signal til et juridisk håndhæveligt krav.
Best practices og anbefalinger
Implementering af NoAI-beskyttelse bør indgå som en del af en lagdelt tilgang til indholdssikkerhed frem for en enkeltstående løsning, hvor tekniske, juridiske og overvågningsstrategier kombineres for at opnå omfattende beskyttelse. For at maksimere effektiviteten bør du overveje disse best practices:
Implementér via alle metoder: Brug HTML meta tags, HTTP-headers og robots.txt-direktiver samtidigt for at nå forskellige typer crawlere og systemer
Overvåg overholdelse: Tjek jævnligt dit indhold mod AI-træningsdatasæt og brug værktøjer til at verificere, om dit indhold optræder i populære modeller
Kombinér med juridisk beskyttelse: Inkludér klare servicevilkår og copyright-meddelelser, der eksplicit forbyder brug til AI-træning
Brug vandmærkning og fingerprinting: Tilføj usynlige eller synlige markeringer i dit indhold for at spore uautoriseret brug og bevise ejerskab
Implementér adgangskontrol: Brug autentificering, betalingsmur eller begrænsning af adgang for at forhindre storskalascraping uanset meta tags
Følg med i nye standarder: Hold dig orienteret om nye standarder som C2PA og deltag i branchesamtaler om indholdsbeskyttelse
Derudover bør du jævnligt revidere din implementering af indholdsbeskyttelse for at sikre, at alle sider indeholder de relevante direktiver, og overveje at bruge automatiserede værktøjer til at scanne efter dit indhold i offentlige AI-datasæt og træningsrepositories. Dokumentér din NoAI-implementering som en del af din indholdsstyringspolitik og kommuniker disse beskyttelser til dit publikum, så de forstår, hvilke skridt du tager for at beskytte deres arbejde, hvis du er en platform, der hoster bruger-genereret indhold.
Ofte stillede spørgsmål
Direktivet noai beskytter alle indholdstyper (tekst, billeder, kode) mod AI-træning, mens noimageai specifikt kun beskytter billedindhold. Brug noai for omfattende beskyttelse og noimageai, når du vil tillade tekstindeksering, men beskytte visuelle aktiver mod generative billedmodeller.
Nej, NoAI meta tag fungerer efter et æressystem og afhænger af, om AI-udviklere vælger at respektere det. Store virksomheder som OpenAI og Google respekterer det, men onde aktører og uautoriserede scrapers ignorerer ofte disse signaler, hvilket gør det til et lag af beskyttelse frem for en komplet løsning.
Du kan implementere det på tre måder: tilføj HTML meta tagget til din sides header, indstil HTTP-responsheaders på din server, eller inkluder direktiver i din robots.txt-fil. HTML meta tag-metoden er mest almindelig og ligetil for de fleste websideejere.
Store AI-virksomheder inklusive OpenAI (ChatGPT), Google, Anthropic (Claude) og Stability AI har offentligt forpligtet sig til at respektere NoAI-direktiver i deres træningsprocesser. Overholdelsen varierer dog blandt mindre AI-virksomheder, akademiske forskere og kommercielle scrapers.
Ja, du kan bruge begge samtidig for maksimal effektivitet. NoAI meta tagget og robots.txt-direktiver arbejder sammen for at kommunikere dine indholdsbeskyttelsespræferencer til forskellige typer crawlere og systemer.
Kombinér NoAI med andre beskyttelsesmetoder, herunder HTTP-headers, robots.txt-regler, vandmærkning, adgangskontrol og juridiske servicevilkår. Overvåg dit indhold i AI-datasæt og overvej at bruge værktøjer til at spore uautoriseret brug.
Selvom det er bredt vedtaget af store AI-virksomheder, er NoAI endnu ikke en formel W3C-standard. Branchen arbejder dog på mere sofistikerede standarder som C2PA og maskinlæsbare rettighedsudtryk, der måske senere giver juridisk støtte.
NoAI er mest effektivt, når det kombineres med andre metoder som robots.txt, HTTP-headers, vandmærkning, adgangskontrol og juridisk beskyttelse. Ingen enkelt metode giver fuld beskyttelse, så en lagdelt tilgang anbefales for omfattende indholdssikkerhed.
Overvåg hvordan AI refererer til dit indhold
Spor hvilke AI-systemer, der citerer dit brand og indhold med AmICiteds AI-overvågningsplatform. Få præcis viden om, hvordan dit arbejde bliver brugt af ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer.
Hvad er noai meta-tagget, og hvordan beskytter det dit indhold mod AI?
Lær om noai meta-tagget, hvordan det fungerer for at forhindre AI-træningsdatakollektion, dets begrænsninger, og hvordan du implementerer det på din hjemmeside ...
Lær hvordan du implementerer noai og noimageai meta tags for at kontrollere AI-crawleres adgang til dit websteds indhold. Komplet guide til AI-adgangskontrol-he...
Kan noai meta-tagget faktisk beskytte mit indhold mod AI-træning? Eller er det bare ønsketænkning?
Fællesskabsdiskussion om noai meta-tagget og om det effektivt beskytter indhold mod AI-træning. Brugere deler erfaringer og begrænsninger ved denne metode.
7 min læsning
Discussion
Content Protection
+2
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.