
FAQ-Erweiterung
Erfahren Sie, wie FAQ-Erweiterung umfassende Frage-Antwort-Paare für KI-Systeme entwickelt. Entdecken Sie Strategien zur Verbesserung von KI-Zitationen, plattfo...
8 Min. Lesezeit
Die Optimierung der Abfrageerweiterung ist der Prozess, bei dem Benutzeranfragen durch verwandte Begriffe, Synonyme und kontextuelle Variationen erweitert werden, um die Genauigkeit der KI-Systeme bei der Informationsbeschaffung und die Relevanz der Inhalte zu verbessern. Sie überbrückt Wortschatzlücken zwischen Benutzeranfragen und relevanten Dokumenten und stellt sicher, dass KI-Systeme wie GPTs und Perplexity passendere Inhalte finden und referenzieren können. Diese Technik ist unerlässlich, um sowohl die Vollständigkeit als auch die Genauigkeit KI-generierter Antworten zu verbessern. Durch intelligente Erweiterung von Anfragen können KI-Plattformen die Auffindbarkeit und Zitierfähigkeit relevanter Quellen erheblich steigern.
Die Optimierung der Abfrageerweiterung ist der Prozess, bei dem Benutzeranfragen durch verwandte Begriffe, Synonyme und kontextuelle Variationen erweitert werden, um die Genauigkeit der KI-Systeme bei der Informationsbeschaffung und die Relevanz der Inhalte zu verbessern. Sie überbrückt Wortschatzlücken zwischen Benutzeranfragen und relevanten Dokumenten und stellt sicher, dass KI-Systeme wie GPTs und Perplexity passendere Inhalte finden und referenzieren können. Diese Technik ist unerlässlich, um sowohl die Vollständigkeit als auch die Genauigkeit KI-generierter Antworten zu verbessern. Durch intelligente Erweiterung von Anfragen können KI-Plattformen die Auffindbarkeit und Zitierfähigkeit relevanter Quellen erheblich steigern.
Optimierung der Abfrageerweiterung ist der Prozess der Umformulierung und Verbesserung von Suchanfragen durch das Hinzufügen verwandter Begriffe, Synonyme und semantischer Variationen, um die Retrieval-Leistung und die Antwortqualität zu steigern. Im Kern adressiert die Abfrageerweiterung das Wortschatzproblem – die grundlegende Herausforderung, dass Nutzer und KI-Systeme oft unterschiedliche Begriffe für dieselben Konzepte verwenden, was dazu führt, dass relevante Ergebnisse übersehen werden. Diese Technik ist für KI-Systeme entscheidend, da sie die Lücke zwischen der natürlichen Ausdrucksweise von Informationsbedarfen und der tatsächlichen Indexierung und Speicherung von Inhalten schließt. Durch intelligente Erweiterung von Anfragen können KI-Plattformen sowohl die Relevanz als auch die Vollständigkeit ihrer Antworten erheblich verbessern.
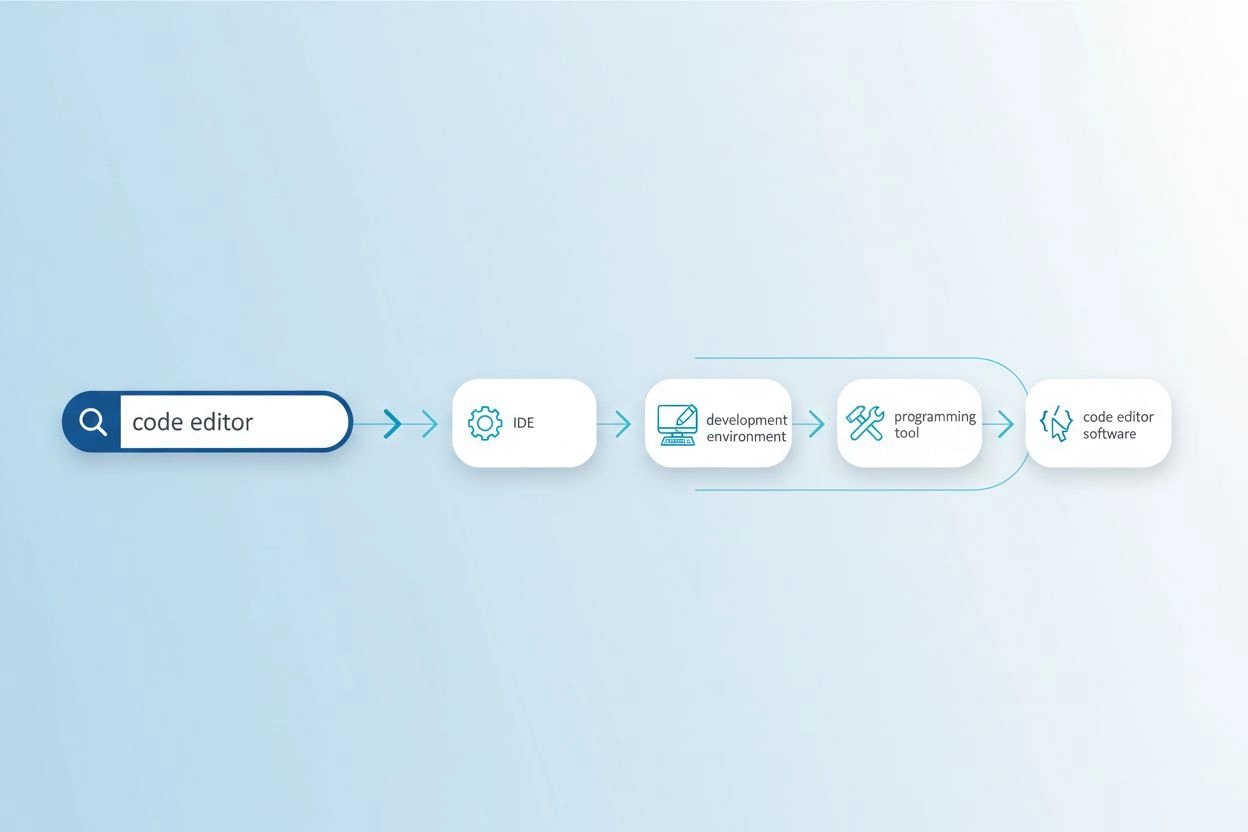
Das Wortschatzproblem tritt auf, wenn die in einer Anfrage verwendeten Begriffe nicht mit der Terminologie in relevanten Dokumenten übereinstimmen und Suchsysteme dadurch wertvolle Informationen übersehen. Sucht zum Beispiel jemand nach „Code-Editor“, könnten Ergebnisse zu „IDEs“ (Integrierte Entwicklungsumgebungen) oder „Texteditoren“ fehlen, obwohl diese sehr relevante Alternativen sind. Ähnlich könnte jemand, der nach „Fahrzeug“ sucht, keine Treffer mit „Auto“, „Automobil“ oder „Kraftfahrzeug“ finden, obwohl eine klare semantische Überlappung besteht. Dieses Problem verschärft sich in spezialisierten Bereichen, in denen mehrere Fachbegriffe dasselbe Konzept beschreiben, und beeinflusst direkt die Qualität KI-generierter Antworten, indem es das verfügbare Quellmaterial einschränkt. Die Abfrageerweiterung löst dieses Problem, indem sie automatisch verwandte Anfragevarianten generiert, welche verschiedene Ausdrucksweisen derselben Information abdecken.
| Ursprüngliche Anfrage | Erweiterte Anfrage | Auswirkung |
|---|---|---|
| code editor | IDE, Texteditor, Entwicklungsumgebung, Source-Code-Editor | Findet 3–5x mehr relevante Ergebnisse |
| machine learning | KI, künstliche Intelligenz, Deep Learning, neuronale Netze | Erfasst domänenspezifische Terminologie |
| vehicle | Auto, Automobil, Kraftfahrzeug, Transportmittel | Bezieht gängige Synonyme und verwandte Begriffe ein |
| headache | Migräne, Spannungskopfschmerz, Schmerzmittel, Kopfschmerzbehandlung | Deckt medizinische Terminologie-Variationen ab |
Moderne Abfrageerweiterung nutzt mehrere komplementäre Techniken, die je nach Anwendungsfall und Fachbereich unterschiedliche Vorteile bieten:
Jede Technik bietet unterschiedliche Kompromisse zwischen Rechenaufwand, Erweiterungsqualität und Fachspezifität, wobei LLM-basierte Ansätze die höchste Qualität liefern, aber mehr Ressourcen erfordern.
Die Abfrageerweiterung verbessert KI-Antworten, indem sie Sprachmodellen und Retrieval-Systemen eine reichhaltigere und umfassendere Sammlung von Ausgangsmaterial zur Verfügung stellt. Wenn eine Anfrage um Synonyme, verwandte Konzepte und alternative Formulierungen erweitert wird, kann das Suchsystem auf Dokumente zugreifen, die unterschiedliche Terminologie verwenden, aber dennoch relevante Informationen enthalten – was die Recall-Rate des Suchprozesses deutlich erhöht. Dieser erweiterte Kontext ermöglicht es KI-Systemen, vollständigere und nuanciertere Antworten zu generieren, da sie nicht länger durch die spezifische Wortwahl in der ursprünglichen Anfrage eingeschränkt sind. Allerdings bringt die Abfrageerweiterung einen Trade-off zwischen Präzision und Recall mit sich: Während erweiterte Anfragen mehr relevante Dokumente liefern, können sie bei zu starker Erweiterung auch Rauschen und weniger relevante Ergebnisse einführen. Die Optimierung besteht darin, die Intensität der Erweiterung so zu kalibrieren, dass die Relevanz maximiert und irrelevantes Rauschen minimiert wird, sodass KI-Antworten umfassender werden, ohne an Genauigkeit zu verlieren.
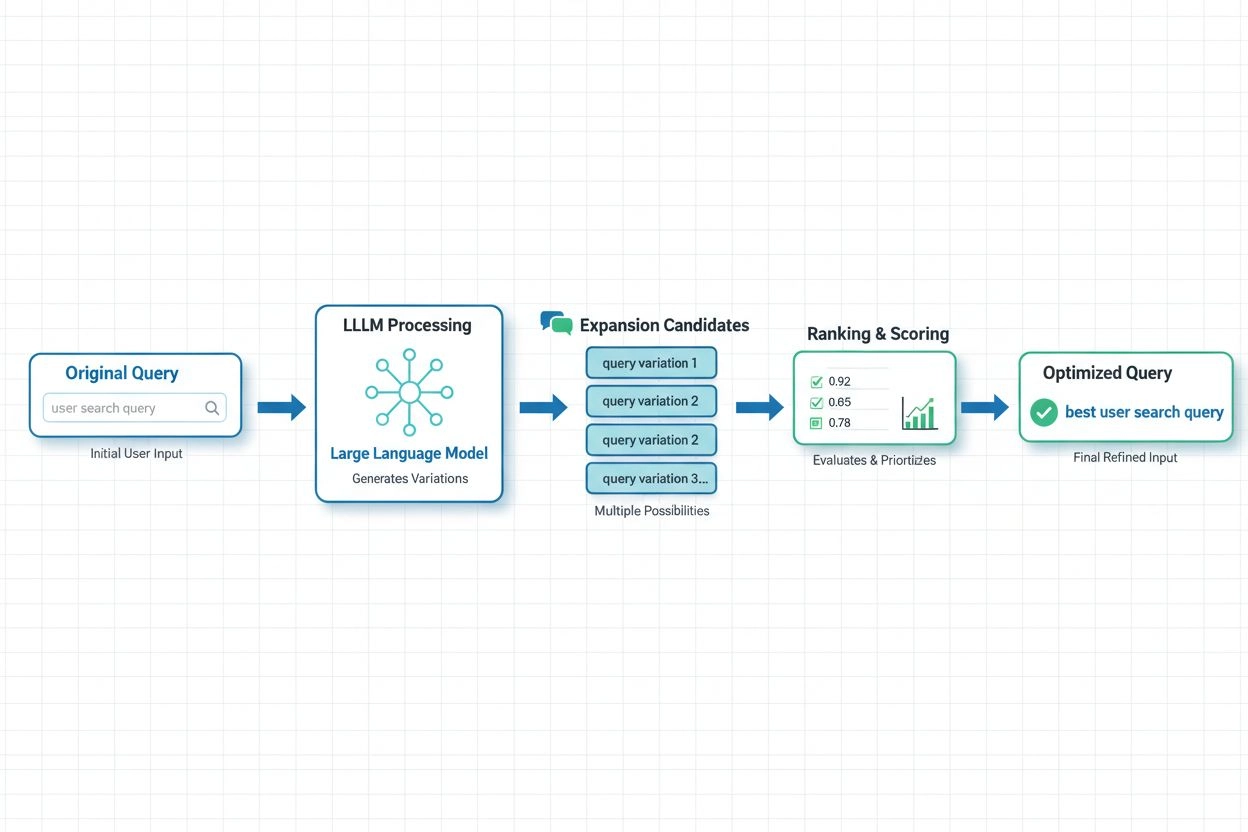
In modernen KI-Systemen hat sich die LLM-basierte Abfrageerweiterung als fortschrittlichster Ansatz etabliert. Sie nutzt die semantischen Fähigkeiten großer Sprachmodelle, um kontextuell passende Anfragevariationen zu generieren. Aktuelle Forschung von Spotify zeigt die Leistungsfähigkeit dieses Ansatzes: Durch den Einsatz von Präferenzabstimmungs-Techniken (Kombination von RSFT- und DPO-Methoden) konnte eine ca. 70 % geringere Verarbeitungszeit erreicht werden – bei gleichzeitig verbesserter Top-1-Retrieval-Genauigkeit. Diese Systeme funktionieren, indem sie Sprachmodelle darauf trainieren, Nutzerpräferenzen und -absichten zu verstehen und dann Erweiterungen zu generieren, die dem entsprechen, was Nutzer tatsächlich als wertvoll empfinden – statt nur wahllos Synonyme hinzuzufügen. Echtzeit-Optimierungsansätze passen Erweiterungsstrategien kontinuierlich anhand von Nutzerfeedback und Retrieval-Ergebnissen an, sodass Systeme lernen, welche Erweiterungen für bestimmte Anfragearten und Domänen am besten funktionieren. Dieser dynamische Ansatz ist besonders wertvoll für KI-Monitoring-Plattformen, da er es ermöglicht, nachzuverfolgen, wie sich Abfrageerweiterung auf Zitiergenauigkeit und Content-Discovery in verschiedenen Themen und Branchen auswirkt.
Trotz ihrer Vorteile bringt die Abfrageerweiterung erhebliche Herausforderungen mit sich, die gezielte Optimierungsstrategien erfordern. Das Übererweiterungsproblem tritt auf, wenn zu viele Anfragevarianten hinzugefügt werden und dadurch Rauschen sowie irrelevante Dokumente abgerufen werden, was die Antwortqualität mindert und die Rechenlast erhöht. Domänenspezifisches Tuning ist unerlässlich, denn Erweiterungstechniken, die im allgemeinen Web-Suchumfeld funktionieren, können in spezialisierten Bereichen wie der medizinischen Forschung oder juristischen Dokumentation versagen, wo terminologische Präzision entscheidend ist. Organisationen müssen das Gleichgewicht zwischen Abdeckung und Genauigkeit halten – also genug erweitern, um relevante Variationen abzudecken, aber nicht so stark, dass irrelevante Ergebnisse das Signal überlagern. Effektive Validierungsansätze umfassen A/B-Tests verschiedener Erweiterungsstrategien mit menschlicher Relevanzbewertung, das Monitoring von Metriken wie precision@k und recall@k sowie die fortlaufende Analyse, welche Erweiterungen tatsächlich die Leistung nachgelagerter Aufgaben verbessern. Erfolgreiche Implementierungen setzen auf adaptive Erweiterungen, die die Intensität je nach Anfrageeigenschaften, Domänenkontext und beobachteter Retrieval-Qualität steuern, statt pauschale Regeln auf alle Anfragen anzuwenden.
Für AmICited.com und KI-Monitoring-Plattformen ist die Optimierung der Abfrageerweiterung grundlegend, um präzise nachzuverfolgen, wie KI-Systeme Quellen zu unterschiedlichen Themen und Suchkontexten zitieren und referenzieren. Wenn KI-Systeme intern erweiterte Anfragen verwenden, greifen sie auf eine breitere Palette potenzieller Quellen zu, was direkt beeinflusst, welche Zitate in ihren Antworten erscheinen und wie umfassend sie die verfügbaren Informationen abdecken. Das bedeutet, dass das Monitoring der KI-Antwortqualität erfordert, nicht nur zu verstehen, was Nutzer fragen, sondern auch, welche erweiterten Anfragevarianten das KI-System im Hintergrund zur Beschaffung unterstützender Informationen nutzt. Marken und Content-Ersteller sollten ihre Content-Strategie darauf ausrichten, wie ihr Material durch Abfrageerweiterung auffindbar werden kann – durch die Nutzung verschiedener Terminologievarianten, Synonyme und verwandter Konzepte im Content, um Sichtbarkeit bei unterschiedlichen Anfrageformulierungen zu gewährleisten. AmICited unterstützt Organisationen dabei, indem überwacht wird, wie ihre Inhalte in KI-generierten Antworten bei verschiedenen Anfragearten und Erweiterungen erscheinen – und so Lücken aufdeckt, in denen Inhalte durch Wortschatzprobleme übersehen werden, sowie Einblicke liefert, wie Erweiterungsstrategien Zitiermuster und Content-Discovery in KI-Systemen beeinflussen.
Bei der Abfrageerweiterung werden der ursprünglichen Anfrage verwandte Begriffe und Synonyme hinzugefügt, wobei die Kernabsicht erhalten bleibt, während bei der Abfrageumschreibung die gesamte Anfrage umformuliert wird, um besser zu den Fähigkeiten des Suchsystems zu passen. Die Erweiterung ist additiv – sie vergrößert den Suchbereich – während die Umschreibung transformativ ist und verändert, wie die Anfrage ausgedrückt wird. Beide Techniken verbessern die Retrieval-Leistung, aber die Erweiterung ist in der Regel weniger riskant, da die ursprüngliche Absicht bewahrt bleibt.
Die Abfrageerweiterung wirkt sich direkt darauf aus, welche Quellen von KI-Systemen entdeckt und zitiert werden, da sie die zur Verfügung stehenden Dokumente für die Suche verändert. Wenn KI-Systeme intern erweiterte Anfragen verwenden, greifen sie auf eine breitere Palette potenzieller Quellen zu, was beeinflusst, welche Zitate in ihren Antworten erscheinen. Das bedeutet, dass das Monitoring der KI-Antwortqualität erfordert, nicht nur zu verstehen, was Benutzer fragen, sondern auch, welche erweiterten Anfragevarianten das KI-System im Hintergrund verwendet.
Ja, eine zu starke Erweiterung kann Rauschen erzeugen und irrelevante Dokumente abrufen, die die Antwortqualität verwässern. Dies geschieht, wenn zu viele Anfragevarianten ohne ausreichende Filterung hinzugefügt werden. Entscheidend ist es, die Intensität der Erweiterung so zu steuern, dass die Relevanz maximiert und irrelevantes Rauschen minimiert wird. Effektive Implementierungen nutzen adaptive Erweiterungen, die die Intensität anhand der Anfrageneigenschaften und der beobachteten Retrieval-Qualität anpassen.
Large Language Models haben die Abfrageerweiterung revolutioniert, indem sie ein semantisches Verständnis der Benutzerabsicht ermöglichen und kontextuell passende Anfragevariationen generieren. LLM-basierte Erweiterungen nutzen Präferenzabstimmungs-Techniken, um Modelle darauf zu trainieren, Erweiterungen zu erzeugen, die die Retrieval-Ergebnisse tatsächlich verbessern, statt nur beliebige Synonyme hinzuzufügen. Neuere Forschungen zeigen, dass LLM-basierte Ansätze die Verarbeitungszeit um ca. 70 % reduzieren können und dabei die Trefferquote verbessern.
Marken sollten verschiedene Terminologie-Varianten, Synonyme und verwandte Konzepte in ihren Inhalten verwenden, um Sichtbarkeit bei unterschiedlichen Anfrageformulierungen sicherzustellen. Das bedeutet, zu berücksichtigen, wie Ihr Material durch Abfrageerweiterung auffindbar werden kann – durch die Nutzung technischer und umgangssprachlicher Begriffe, alternativer Formulierungen und die Abdeckung verwandter Konzepte. So ist Ihr Content unabhängig von der verwendeten Anfragevariante auffindbar.
Zentrale Metriken sind precision@k (Relevanz der Top-k-Ergebnisse), recall@k (Abdeckung relevanter Inhalte in den Top-k-Ergebnissen), Mean Reciprocal Rank (Position des ersten relevanten Ergebnisses) und die Leistung nachgeschalteter Aufgaben. Unternehmen beobachten auch Verarbeitungszeit, Rechenaufwand und Nutzerzufriedenheit. A/B-Tests verschiedener Erweiterungsstrategien mit menschlicher Relevanzbewertung bieten die zuverlässigste Validierung.
Nein, es sind komplementäre, aber unterschiedliche Techniken. Die Abfrageerweiterung verändert die Eingabeanfrage zur Verbesserung der Suche, während die semantische Suche Einbettungen und Vektorrepräsentationen nutzt, um inhaltlich ähnliche Inhalte zu finden. Abfrageerweiterung kann Teil einer semantischen Suchpipeline sein, aber semantische Suche funktioniert auch ohne explizite Abfrageerweiterung. Beide Methoden adressieren Wortschatzprobleme, aber auf unterschiedliche Weise.
AmICited verfolgt, wie KI-Systeme Quellen zu unterschiedlichen Themen und Suchkontexten zitieren und referenzieren und zeigt auf, welche erweiterten Anfragen dazu führen, dass Ihre Marke genannt wird. Durch die Überwachung von Zitiermustern über verschiedene Anfragearten und Erweiterungen hinweg liefert AmICited Einblicke, wie sich Erweiterungsstrategien auf Content-Discovery und Zitiergenauigkeit in KI-Systemen wie GPTs und Perplexity auswirken.
Die Optimierung der Abfrageerweiterung beeinflusst, wie KI-Systeme wie GPTs und Perplexity Ihre Inhalte entdecken und zitieren. Verwenden Sie AmICited, um nachzuverfolgen, welche erweiterten Anfragen dazu führen, dass Ihre Marke in KI-Antworten referenziert wird.
Erfahren Sie, wie FAQ-Erweiterung umfassende Frage-Antwort-Paare für KI-Systeme entwickelt. Entdecken Sie Strategien zur Verbesserung von KI-Zitationen, plattfo...

Community-Diskussion zur Identifizierung verwandter Themen zur Erweiterung der KI-Sichtbarkeit. Marketer teilen Methoden zur Entdeckung semantischer Assoziation...

Query Refinement ist der iterative Prozess der Optimierung von Suchanfragen für bessere Ergebnisse in KI-Suchmaschinen. Erfahren Sie, wie es bei ChatGPT, Perple...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.