
Refinamiento de consultas
El refinamiento de consultas es el proceso iterativo de optimizar consultas de búsqueda para obtener mejores resultados en motores de búsqueda de IA. Descubre c...
18 min de lectura
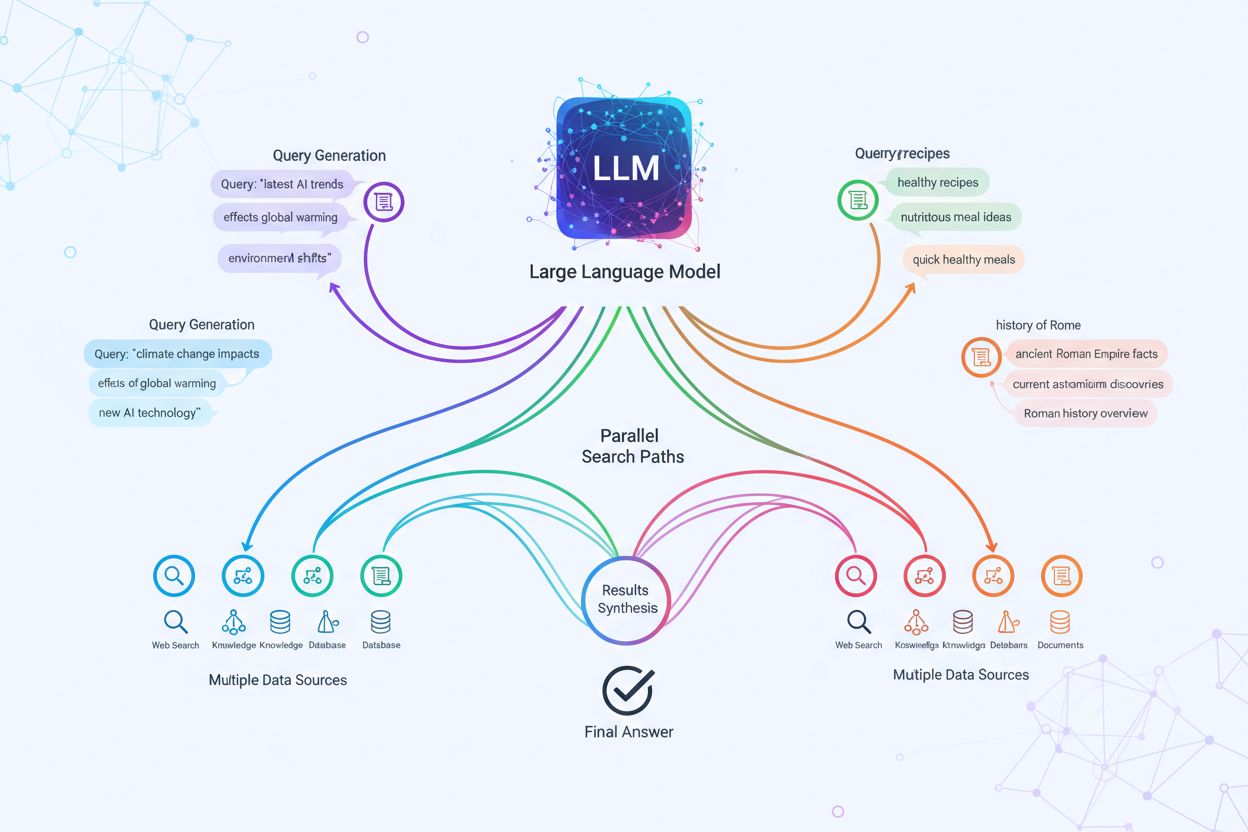
Descubre cómo sistemas de IA modernos como Google AI Mode y ChatGPT descomponen una sola consulta en múltiples búsquedas. Aprende sobre los mecanismos de ramificación de consultas, sus implicaciones para la visibilidad en IA y la optimización de la estrategia de contenidos.
La ramificación de consultas es el proceso mediante el cual los grandes modelos de lenguaje dividen automáticamente una sola consulta de usuario en múltiples subconsultas para recopilar información más completa de fuentes diversas. En lugar de ejecutar una sola búsqueda, los sistemas modernos de IA descomponen la intención del usuario en 5-15 consultas relacionadas que capturan diferentes ángulos, interpretaciones y aspectos de la solicitud original. Por ejemplo, cuando un usuario busca “mejores auriculares para corredores” en el Modo de IA de Google, el sistema genera aproximadamente 8 búsquedas diferentes incluyendo variaciones como “auriculares para correr con cancelación de ruido”, “auriculares inalámbricos ligeros para atletas”, “auriculares deportivos resistentes al sudor” y “auriculares de larga duración de batería para correr”. Esto representa un cambio fundamental frente a la búsqueda tradicional, donde una sola cadena de consulta se compara contra un índice. Las características clave de la ramificación de consultas incluyen:
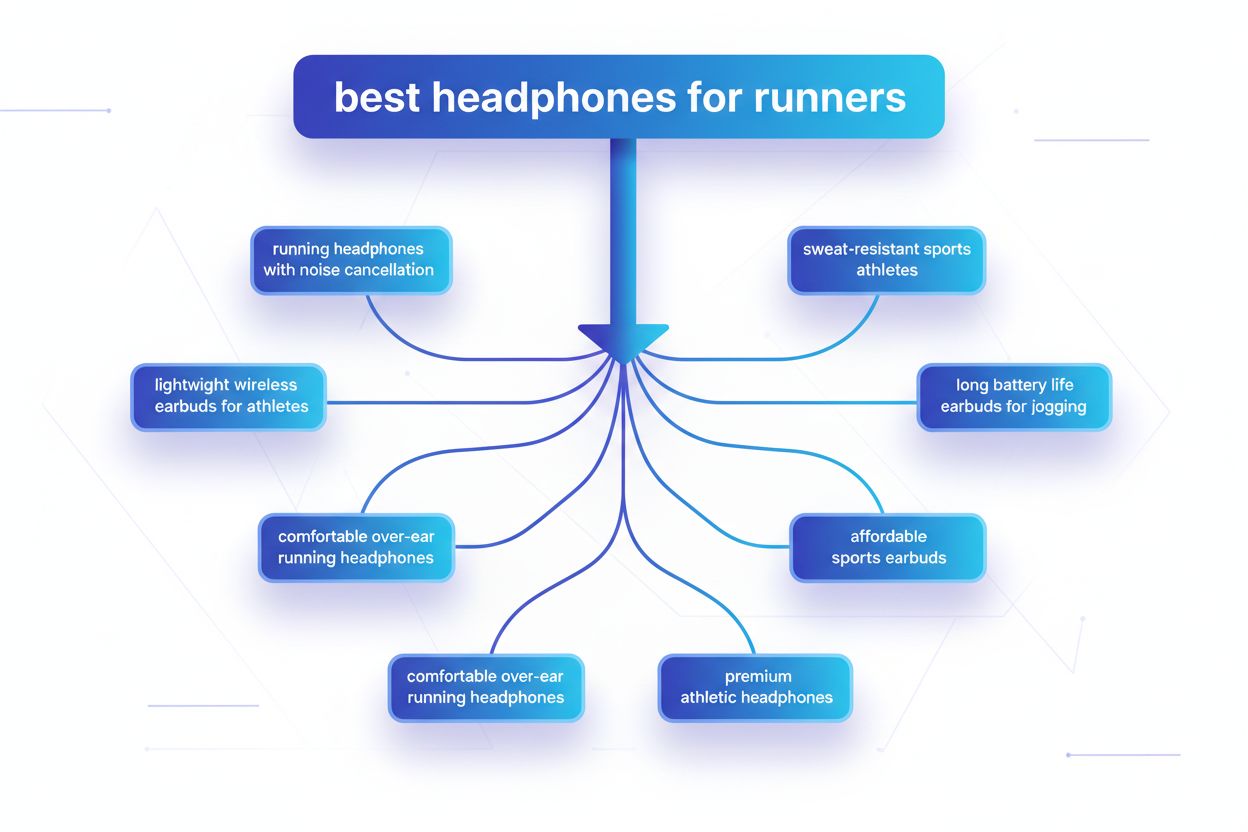
La implementación técnica de la ramificación de consultas se apoya en sofisticados algoritmos de PLN que analizan la complejidad de la consulta y generan variantes semánticamente significativas. Los LLM producen ocho tipos principales de variantes: consultas equivalentes (reformulación con significado idéntico), consultas de seguimiento (explorando temas relacionados), consultas de generalización (ampliando el alcance), consultas de especificación (enfocando el tema), consultas de canonización (estandarizando la terminología), consultas de traducción (convirtiendo entre dominios), consultas de implicación (explorando implicancias lógicas), y consultas de clarificación (desambiguando términos ambiguos). El sistema emplea modelos de lenguaje neuronales para evaluar la complejidad de la consulta—midiendo factores como el conteo de entidades, la densidad de relaciones y la ambigüedad semántica—para determinar cuántas subconsultas generar. Una vez generadas, estas consultas se ejecutan en paralelo a través de múltiples sistemas de recuperación incluyendo rastreadores web, grafos de conocimiento (como el Knowledge Graph de Google), bases de datos estructuradas e índices de similitud vectorial. Las diferentes plataformas implementan esta arquitectura con distintos niveles de transparencia y sofisticación:
| Plataforma | Mecanismo | Transparencia | Número de Consultas | Método de Ranking |
|---|---|---|---|---|
| Google AI Mode | Ramificación explícita con consultas visibles | Alta | 8-12 consultas | Ranking de múltiples etapas |
| Microsoft Copilot | Orquestador Bing iterativo | Media | 5-8 consultas | Puntuación de relevancia |
| Perplexity | Recuperación híbrida con ranking de múltiples etapas | Alta | 6-10 consultas | Basado en citas |
| ChatGPT | Generación implícita de consultas | Baja | Desconocido | Ponderación interna |
Las consultas complejas se someten a una sofisticada descomposición donde el sistema las divide en entidades, atributos y relaciones antes de generar variantes. Al procesar una consulta como “auriculares Bluetooth con diseño cómodo de diadema y batería de larga duración para corredores”, el sistema realiza una comprensión centrada en entidades identificando las principales (auriculares Bluetooth, corredores) y extrayendo atributos críticos (cómodos, de diadema, batería de larga duración). El proceso de descomposición aprovecha grafos de conocimiento para entender cómo se relacionan estas entidades y qué variaciones semánticas existen—reconociendo que “auriculares de diadema” y “auriculares circumaurales” son equivalentes, o que “batería de larga duración” podría significar 8+ horas, 24+ horas o varios días según el contexto. El sistema identifica conceptos relacionados mediante medidas de similitud semántica, entendiendo que consultas sobre “resistencia al sudor” y “resistencia al agua” son relacionadas pero distintas, y que los “corredores” también pueden estar interesados en “ciclistas”, “gimnastas” o “atletas al aire libre”. Esta descomposición permite la generación de subconsultas dirigidas que capturan distintos matices de la intención del usuario en lugar de simplemente reformular la solicitud original.
La ramificación de consultas fortalece fundamentalmente el componente de recuperación de los marcos de Generación Aumentada por Recuperación (RAG) al permitir una recopilación de evidencia más rica y diversa antes de la fase de generación. En los flujos RAG tradicionales, una sola consulta se incrusta y compara contra una base de datos vectorial, lo que puede hacer que se pierda información relevante que use terminología o enfoques conceptuales diferentes. La ramificación de consultas aborda esta limitación ejecutando múltiples recuperaciones en paralelo, cada una optimizada para una variante específica, lo que en conjunto recopila evidencia desde distintos ángulos y fuentes. Esta estrategia paralela reduce significativamente el riesgo de alucinaciones al fundamentar las respuestas de los LLM en fuentes independientes—cuando el sistema recupera información sobre “auriculares de diadema”, “diseños circumaurales” y “auriculares de tamaño completo” por separado, puede comparar y validar afirmaciones entre estos diversos resultados. La arquitectura incorpora fragmentación semántica y recuperación basada en pasajes, donde los documentos se dividen en unidades semánticas significativas en lugar de fragmentos de longitud fija, permitiendo recuperar los pasajes más relevantes sin importar la estructura del documento. Al combinar evidencia de múltiples recuperaciones, los sistemas RAG producen respuestas más completas, mejor fundamentadas y menos propensas a respuestas erróneas pero seguras que aquejan los enfoques de recuperación de consulta única.
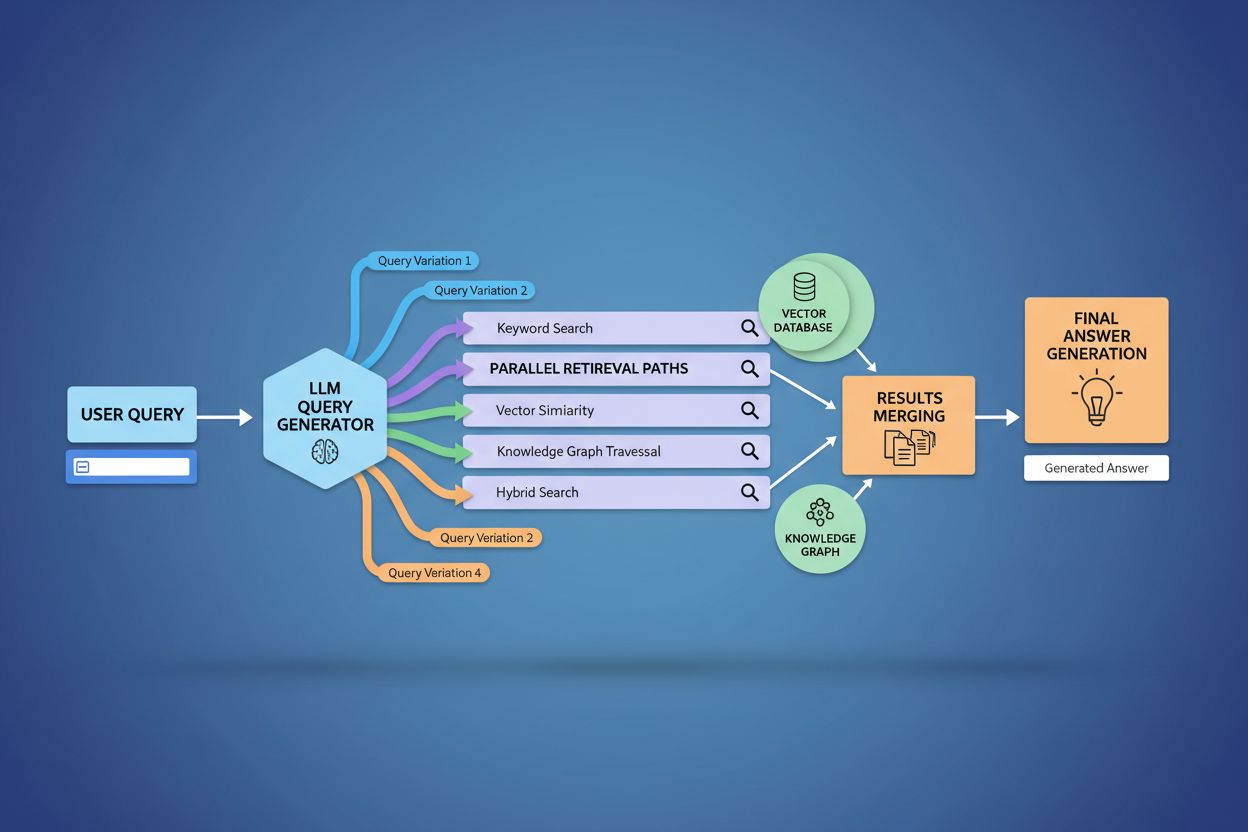
El contexto y las señales de personalización del usuario moldean dinámicamente cómo la ramificación de consultas expande las solicitudes individuales, creando rutas de recuperación personalizadas que pueden diferir significativamente entre usuarios. El sistema incorpora múltiples dimensiones de personalización incluyendo atributos del usuario (ubicación geográfica, perfil demográfico, rol profesional), patrones de historial de búsqueda (consultas previas y resultados clicados), señales temporales (hora del día, temporada, eventos actuales) y contexto de la tarea (si el usuario está investigando, comprando o aprendiendo). Por ejemplo, una consulta sobre “mejores auriculares para corredores” se expande de manera diferente para un atleta de ultramaratón de 22 años en Kenia versus un corredor recreativo de 45 años en Minnesota—la expansión del primer usuario podría enfatizar durabilidad y resistencia al calor mientras que la del segundo resalta comodidad y accesibilidad. Sin embargo, esta personalización introduce el problema de la “transformación de dos puntos”, donde el sistema trata las consultas actuales como variaciones de patrones históricos, lo que podría limitar la exploración y reforzar preferencias existentes. La personalización puede crear inadvertidamente burbujas de filtro donde la expansión de la consulta favorece sistemáticamente fuentes y perspectivas alineadas con el comportamiento histórico del usuario, limitando la exposición a puntos de vista alternativos o información emergente. Comprender estos mecanismos de personalización es clave para los creadores de contenido, ya que el mismo contenido puede o no ser recuperado dependiendo del perfil e historial del usuario.
Las principales plataformas de IA implementan la ramificación de consultas con arquitecturas, niveles de transparencia y enfoques estratégicos marcadamente diferentes, reflejando su infraestructura subyacente y filosofías de diseño. El Modo de IA de Google emplea una ramificación explícita y visible donde los usuarios pueden ver las 8-12 subconsultas generadas junto a los resultados, lanzando cientos de búsquedas individuales contra el índice de Google para recopilar evidencia completa. Microsoft Copilot utiliza un enfoque iterativo impulsado por el Orquestador Bing, que genera 5-8 consultas secuencialmente, refinando el conjunto de consultas en función de los resultados intermedios antes de ejecutar la recuperación final. Perplexity implementa una estrategia híbrida de recuperación con ranking de múltiples etapas, generando 6-10 consultas y ejecutándolas tanto en fuentes web como en su propio índice, aplicando sofisticados algoritmos de ranking para mostrar los pasajes más relevantes. El enfoque de ChatGPT permanece en gran parte opaco para los usuarios, con la generación de consultas sucediendo implícitamente dentro del procesamiento interno del modelo, lo que dificulta saber cuántas consultas se generan o cómo se ejecutan exactamente. Estas diferencias arquitectónicas tienen implicaciones importantes en transparencia, reproducibilidad y la capacidad de los creadores de contenido para optimizar para cada plataforma:
| Aspecto | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Visibilidad de Consultas | Totalmente visible para usuarios | Parcialmente visible | Visible en citas | Oculto |
| Modelo de Ejecución | Lote paralelo | Secuencial iterativo | Paralelo con ranking | Interno/implícito |
| Diversidad de Fuentes | Solo índice de Google | Bing + propio | Web + índice propio | Datos de entrenamiento + plugins |
| Transparencia de Citas | Alta | Media | Muy alta | Baja |
| Opciones de Personalización | Limitadas | Media | Alta | Media |
La ramificación de consultas introduce varios desafíos técnicos y semánticos que pueden hacer que el sistema se desvíe de la verdadera intención del usuario, recuperando información técnicamente relacionada pero poco útil. La deriva semántica ocurre mediante la expansión generativa cuando el LLM crea variantes de consulta que, aunque relacionadas con la original, van desplazando el significado—una consulta sobre “mejores auriculares para corredores” puede expandirse a “auriculares deportivos”, luego a “equipamiento deportivo”, después a “accesorios de fitness”, alejándose progresivamente de la intención original. El sistema debe distinguir entre la intención latente (lo que el usuario podría querer si supiera más) y la intención explícita (lo que realmente pidió), y una expansión agresiva puede confundir estas categorías, recuperando información sobre productos que el usuario nunca buscó. La divergencia por expansión iterativa ocurre cuando cada consulta generada genera a su vez subconsultas, creando un árbol ramificado de búsquedas cada vez más tangenciales que acaban recuperando información lejana a la solicitud inicial. Las burbujas de filtro y el sesgo de personalización implican que dos usuarios que hacen la misma pregunta reciban expansiones sistemáticamente diferentes según su perfil, potencialmente creando cámaras de eco donde cada expansión refuerza las preferencias existentes. Escenarios reales ilustran estos riesgos: un usuario buscando “auriculares asequibles” podría ver su consulta expandida a incluir marcas de lujo en función de su historial, o una consulta sobre “auriculares para personas con discapacidad auditiva” podría expandirse a productos de accesibilidad en general, diluyendo la especificidad de la intención original.
El auge de la ramificación de consultas cambia fundamentalmente la estrategia de contenidos, pasando de la optimización por ranking de palabras clave hacia la visibilidad basada en citas, requiriendo que los creadores replanteen cómo estructuran y presentan la información. El SEO tradicional se centraba en posicionarse por palabras clave específicas; la búsqueda impulsada por IA prioriza ser citado como fuente autoritativa en múltiples variantes de consulta y contextos. Los creadores deben adoptar estrategias de contenido atómico, rico en entidades, donde la información se estructura en torno a entidades específicas (productos, conceptos, personas) con marcado semántico que permita a los sistemas de IA extraer y citar pasajes relevantes. El clustering temático y la autoridad topical cobran mayor importancia—en vez de crear artículos aislados por palabra clave, el contenido exitoso establece cobertura comprensiva de áreas temáticas, incrementando la probabilidad de ser recuperado en las diversas variantes generadas por la ramificación. La implementación de marcado de esquema y datos estructurados permite a los sistemas de IA comprender la estructura del contenido y extraer información más eficazmente, aumentando las probabilidades de cita. Las métricas de éxito pasan de rastrear rankings de palabras clave a monitorear la frecuencia de citas mediante herramientas como AmICited.com, que rastrean cuántas veces una marca o contenido aparece en respuestas generadas por IA. Las mejores prácticas incluyen: crear contenido completo y bien fundamentado que aborde múltiples ángulos; implementar marcado de esquema rico (Organization, Product, Article schemas); construir autoridad topical mediante contenido interconectado; y auditar regularmente cómo aparece tu contenido en respuestas IA en distintas plataformas y segmentos de usuarios.
La ramificación de consultas representa el cambio arquitectónico más importante en búsqueda desde la indexación mobile-first, reestructurando de fondo cómo se descubre y presenta la información a los usuarios. La evolución hacia infraestructura semántica implica que los sistemas de búsqueda operarán cada vez más sobre significados en vez de palabras clave, con la ramificación de consultas como mecanismo por defecto para la recuperación de información en vez de una mejora opcional. Las métricas de citas se vuelven tan importantes como los backlinks para determinar la visibilidad y autoridad del contenido—un contenido citado en 50 respuestas IA diferentes tiene más peso que uno que aparece #1 para una sola palabra clave. Este cambio crea desafíos y oportunidades: las herramientas SEO tradicionales centradas en rankings pierden relevancia, requiriendo nuevos marcos de medición enfocados en la frecuencia de citas, diversidad de fuentes y aparición en distintas variantes de consulta. Sin embargo, esta evolución también abre oportunidades para que las marcas optimicen específicamente para la búsqueda en IA, construyendo contenido autoritativo y bien estructurado que sirva como fuente confiable en múltiples interpretaciones de consulta. El futuro probablemente implicará mayor transparencia sobre los mecanismos de ramificación, con plataformas compitiendo por mostrar más claramente el razonamiento tras su enfoque multi-consulta, y creadores desarrollando estrategias especializadas para maximizar la visibilidad a través de los diversos caminos de recuperación que crea la ramificación.
La ramificación de consultas es el proceso automatizado donde los sistemas de IA descomponen una sola consulta de usuario en múltiples subconsultas y las ejecutan en paralelo, mientras que la expansión de consultas tradicionalmente se refiere a añadir términos relacionados a una sola consulta. La ramificación de consultas es más sofisticada, generando variantes semánticas diversas que capturan diferentes ángulos e interpretaciones de la intención original.
La ramificación de consultas impacta significativamente la visibilidad porque tu contenido debe ser descubrible a través de múltiples variantes de consulta, no solo la consulta exacta del usuario. El contenido que aborda diferentes ángulos, utiliza terminología variada y está bien estructurado con marcado de esquema es más probable que sea recuperado y citado a través de las diversas subconsultas generadas por la ramificación.
Todas las principales plataformas de búsqueda de IA utilizan mecanismos de ramificación de consultas: Google AI Mode usa ramificación explícita y visible (8-12 consultas); Microsoft Copilot utiliza ramificación iterativa a través de Bing Orchestrator; Perplexity implementa recuperación híbrida con ranking de múltiples etapas; y ChatGPT utiliza generación implícita de consultas. Cada plataforma la implementa de manera diferente pero todas descomponen consultas complejas en múltiples búsquedas.
Sí. Optimiza creando contenido atómico y rico en entidades estructurado en torno a conceptos específicos; implementando un marcado de esquema integral; construyendo autoridad temática mediante contenido interconectado; usando terminología clara y variada; y abordando múltiples ángulos de un tema. Herramientas como AmICited.com te ayudan a monitorear cómo aparece tu contenido en diferentes descomposiciones de consulta.
La ramificación de consultas incrementa la latencia porque múltiples consultas se ejecutan en paralelo, pero los sistemas modernos mitigan esto mediante procesamiento paralelo. Mientras una sola consulta puede tardar 200ms, ejecutar 8 consultas en paralelo normalmente suma solo 300-500ms de latencia total debido a la ejecución concurrente. El intercambio vale la pena por una mejor calidad de respuesta.
La ramificación de consultas fortalece la Generación Aumentada por Recuperación (RAG) al permitir una recopilación de evidencia más rica. En lugar de recuperar documentos para una sola consulta, la ramificación recupera evidencia para múltiples variantes en paralelo, proporcionando al LLM un contexto más diverso y completo para generar respuestas precisas y reduciendo el riesgo de alucinaciones.
La personalización moldea cómo se descomponen las consultas en función de atributos del usuario (ubicación, historial, demografía), señales temporales y contexto de la tarea. La misma consulta se expande de manera diferente para distintos usuarios, creando caminos de recuperación personalizados. Esto puede mejorar la relevancia pero también crear burbujas de filtro donde los usuarios ven resultados sistemáticamente diferentes según su perfil.
La ramificación de consultas representa el cambio más significativo en búsqueda desde la indexación mobile-first. Las métricas tradicionales de ranking de palabras clave pierden relevancia ya que la misma consulta se expande de diferentes formas para distintos usuarios. Los profesionales de SEO deben cambiar el enfoque de los rankings de palabras clave hacia la visibilidad basada en citas, la estructura del contenido y la optimización de entidades para tener éxito en la búsqueda impulsada por IA.
Comprende cómo aparece tu marca en plataformas de búsqueda de IA cuando las consultas se expanden y descomponen. Haz seguimiento de citas y menciones en respuestas generadas por IA.
El refinamiento de consultas es el proceso iterativo de optimizar consultas de búsqueda para obtener mejores resultados en motores de búsqueda de IA. Descubre c...
Descubre cómo la reformulación de consultas ayuda a los sistemas de IA a interpretar y mejorar las consultas de los usuarios para una mejor recuperación de info...
Aprende cómo la optimización de expansión de consultas mejora los resultados de búsqueda de IA al salvar las diferencias de vocabulario. Descubre técnicas, desa...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.