Mecanismos técnicos y legales que permiten a creadores de contenido y titulares de derechos de autor evitar que su trabajo sea utilizado en conjuntos de datos de entrenamiento de grandes modelos de lenguaje. Estos incluyen directivas robots.txt, declaraciones legales de exclusión y protecciones contractuales bajo regulaciones como la Ley de IA de la UE.
Exclusión de entrenamiento de IA
Mecanismos técnicos y legales que permiten a creadores de contenido y titulares de derechos de autor evitar que su trabajo sea utilizado en conjuntos de datos de entrenamiento de grandes modelos de lenguaje. Estos incluyen directivas robots.txt, declaraciones legales de exclusión y protecciones contractuales bajo regulaciones como la Ley de IA de la UE.
¿Qué es la Exclusión de Entrenamiento de IA?
La exclusión de entrenamiento de IA se refiere a los mecanismos técnicos y legales que permiten a creadores de contenido, titulares de derechos de autor y propietarios de sitios web evitar que su trabajo sea utilizado en conjuntos de datos de entrenamiento de grandes modelos de lenguaje (LLM). A medida que las empresas de IA extraen grandes cantidades de datos de internet para entrenar modelos cada vez más sofisticados, la capacidad de controlar si tu contenido participa en este proceso se ha vuelto esencial para proteger la propiedad intelectual y mantener el control creativo. Estos mecanismos de exclusión operan en dos niveles: directivas técnicas que instruyen a los rastreadores de IA a omitir tu contenido, y marcos legales que establecen derechos contractuales para excluir tu trabajo de los conjuntos de datos de entrenamiento. Comprender ambas dimensiones es crucial para cualquier persona preocupada por cómo se utiliza su contenido en la era de la IA.
Mecanismos Técnicos: robots.txt y Agentes de Usuario
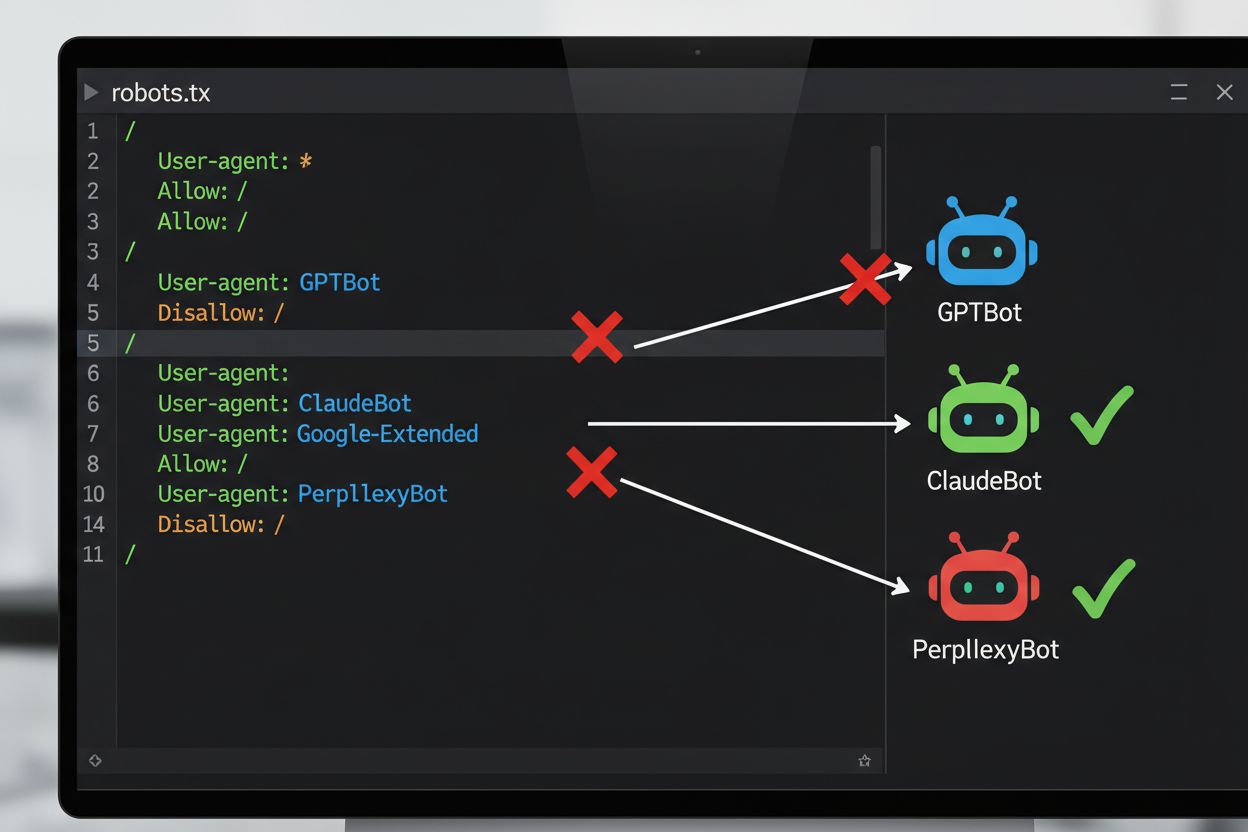
El método técnico más común para excluirse del entrenamiento de IA es mediante el archivo robots.txt, un simple archivo de texto ubicado en el directorio raíz del sitio web que comunica permisos a los bots automatizados. Cuando un rastreador de IA visita tu sitio, primero revisa el robots.txt para ver si tiene permitido acceder a tu contenido. Al agregar directivas de desautorización para agentes de usuario específicos de rastreadores, puedes instruir a los bots de IA para que omitan tu sitio por completo. Cada empresa de IA opera múltiples rastreadores con identificadores de agente de usuario distintos—estos son básicamente los “nombres” que los bots usan para identificarse al realizar solicitudes. Por ejemplo, GPTBot de OpenAI se identifica con la cadena de agente de usuario “GPTBot”, mientras que Claude de Anthropic usa “ClaudeBot”. La sintaxis es sencilla: especificas el nombre del agente de usuario y luego declaras qué rutas están desautorizadas, como “Disallow: /” para bloquear todo el sitio.
Empresa de IA
Nombre del Rastreador
Token de Agente de Usuario
Propósito
OpenAI
GPTBot
GPTBot
Recolección de datos para entrenamiento de modelos
OpenAI
OAI-SearchBot
OAI-SearchBot
Indexación de búsqueda de ChatGPT
Anthropic
ClaudeBot
ClaudeBot
Obtención de citas en chat
Google
Google-Extended
Google-Extended
Datos de entrenamiento para Gemini IA
Perplexity
PerplexityBot
PerplexityBot
Indexación de búsqueda de IA
Meta
Meta-ExternalAgent
Meta-ExternalAgent
Entrenamiento de modelos de IA
Common Crawl
CCBot
CCBot
Conjunto de datos abiertos para entrenamiento de LLM
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
El panorama legal de la exclusión de entrenamiento de IA ha evolucionado significativamente con la introducción de la Ley de IA de la UE, que entró en vigor en 2024 e incorpora disposiciones de la Directiva de Minería de Textos y Datos (TDM). Según estas regulaciones, los desarrolladores de IA pueden utilizar obras protegidas por derechos de autor para fines de aprendizaje automático solo si tienen acceso legal al contenido y el titular de los derechos no ha reservado expresamente el derecho a excluir su obra de la minería de textos y datos. Esto crea un mecanismo legal formal de exclusión: los titulares de derechos pueden presentar reservas de exclusión con sus obras, evitando efectivamente su uso en el entrenamiento de IA sin permiso explícito. La Ley de IA de la UE representa un cambio importante respecto al antiguo enfoque de “moverse rápido y romper cosas”, estableciendo que las empresas que entrenan modelos de IA deben verificar si los titulares de derechos han reservado su contenido e implementar salvaguardias técnicas y organizativas para evitar el uso involuntario de obras excluidas. Este marco legal se aplica en toda la Unión Europea e influye en cómo las empresas globales de IA abordan la recopilación de datos y las prácticas de entrenamiento.
Cómo Funcionan en la Práctica los Mecanismos de Exclusión
Implementar un mecanismo de exclusión implica tanto configuración técnica como documentación legal. En el ámbito técnico, los propietarios de sitios web agregan directivas de desautorización en su archivo robots.txt para agentes de usuario específicos de rastreadores de IA, los cuales los rastreadores compatibles respetarán al visitar el sitio. En el ámbito legal, los titulares de derechos de autor pueden presentar declaraciones de exclusión ante sociedades de gestión colectiva y organizaciones de derechos—por ejemplo, la sociedad holandesa Pictoright y la sociedad francesa de música SACEM han establecido procedimientos formales de exclusión que permiten a los creadores reservar sus derechos frente al uso en entrenamiento de IA. Muchos sitios web y creadores de contenido ahora incluyen declaraciones explícitas de exclusión en sus términos de servicio o metadatos, declarando que su contenido no debe ser utilizado para entrenamiento de modelos de IA. Sin embargo, la efectividad de estos mecanismos depende del cumplimiento de los rastreadores: aunque empresas importantes como OpenAI, Google y Anthropic han declarado públicamente que respetan las directivas de robots.txt y las reservas de exclusión, la falta de un mecanismo centralizado de cumplimiento significa que determinar si una solicitud de exclusión ha sido realmente respetada requiere monitoreo y verificación continuos.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Desafíos y Limitaciones de la Exclusión
A pesar de la disponibilidad de mecanismos de exclusión, existen desafíos significativos que limitan su efectividad:
Estándar Voluntario: robots.txt es un acuerdo de caballeros sin mecanismo de cumplimiento legal, lo que significa que los rastreadores no compatibles pueden simplemente ignorar tus directivas
Evasión de Rastreador: Bots sofisticados pueden suplantar cadenas de agente de usuario para disfrazarse como navegadores legítimos, eludiendo el bloqueo basado en agentes de usuario
Rotación de IP: Los scrapers pueden alternar entre cientos de miles de direcciones IP mediante proxies o botnets, haciendo ineficaz el bloqueo por IP
Cobertura Incompleta: robots.txt detiene aproximadamente el 40-60% de los bots de IA, dejando tráfico significativo sin bloquear si no se aplican medidas técnicas adicionales
Rastreadores Maliciosos: Empresas de IA no reputadas y scrapers independientes pueden ignorar completamente los mecanismos de exclusión, operando en zonas grises legales
Vacíos de Cumplimiento: Incluso cuando se producen violaciones a la exclusión, solicitar recursos legales es costoso y lento, con resultados inciertos en los tribunales
Métodos Técnicos de Implementación Más Allá de robots.txt
Para las organizaciones que requieren una protección más sólida que la que ofrece solo robots.txt, se pueden implementar varios métodos técnicos adicionales. El filtrado de agentes de usuario a nivel de servidor o firewall puede bloquear solicitudes de identificadores de rastreadores específicos antes de que lleguen a tu aplicación, aunque esto sigue siendo vulnerable a la suplantación. El bloqueo de direcciones IP puede dirigirse a rangos de IP conocidos publicados por las principales empresas de IA, aunque los scrapers determinados pueden evadir esto mediante redes de proxies. Limitación y restricción de velocidad pueden ralentizar a los scrapers al limitar el número de solicitudes permitidas por segundo, haciendo que el scraping no sea viable económicamente, aunque bots sofisticados pueden distribuir solicitudes entre múltiples IP para eludir estos límites. Los requisitos de autenticación y los muros de pago proporcionan protección sólida al restringir el acceso a usuarios registrados o clientes de pago, previniendo efectivamente el scraping automatizado. El fingerprinting de dispositivos y el análisis de comportamiento pueden detectar bots analizando patrones como APIs de navegador, handshakes TLS y patrones de interacción que difieren de los usuarios humanos. Algunas organizaciones incluso han implementado honeypots y tarpits—enlaces ocultos o laberintos infinitos de enlaces que solo los bots seguirían—para desperdiciar recursos de rastreadores y, potencialmente, contaminar sus conjuntos de datos de entrenamiento con datos basura.
Ejemplos Reales y Casos de Estudio
La tensión entre empresas de IA y creadores de contenido ha producido varios enfrentamientos de alto perfil que ilustran los desafíos prácticos de aplicar la exclusión. Reddit tomó medidas agresivas en 2023 aumentando drásticamente los precios de acceso a la API específicamente para cobrar a las empresas de IA por los datos, desplazando a scrapers no autorizados y obligando a empresas como OpenAI y Anthropic a negociar acuerdos de licencia. Twitter/X implementó medidas aún más extremas, bloqueando temporalmente todo acceso no autenticado a los tuits y limitando la cantidad de tuits que los usuarios registrados podían leer, apuntando explícitamente a los scrapers de datos. Stack Overflow inicialmente bloqueó el GPTBot de OpenAI en su archivo robots.txt, citando preocupaciones de licencia con el código aportado por los usuarios, aunque luego eliminaron el bloqueo—posiblemente indicando negociaciones con OpenAI. Organizaciones de medios de noticias respondieron en masa: más del 50% de los principales sitios de noticias bloquearon rastreadores de IA para 2023, con medios como The New York Times, CNN, Reuters y The Guardian agregando GPTBot a sus listas de desautorización. Algunas organizaciones de noticias optaron por la vía legal, como The New York Times que presentó una demanda por infracción de derechos de autor contra OpenAI, mientras que otras como la Associated Press negociaron acuerdos de licencia para monetizar su contenido. Estos ejemplos demuestran que, aunque existen mecanismos de exclusión, su efectividad depende tanto de la implementación técnica como de la disposición a emprender acciones legales cuando ocurren violaciones.
Herramientas de Monitoreo y Cumplimiento
Implementar mecanismos de exclusión es solo la mitad de la batalla; verificar que realmente funcionan requiere monitoreo y pruebas continuas. Varias herramientas pueden ayudar a validar tu configuración: Google Search Console incluye un probador de robots.txt para validación específica de Googlebot, mientras que el Robots.txt Tester de Merkle y la herramienta de TechnicalSEO.com prueban el comportamiento de rastreadores individuales según el agente de usuario. Para un monitoreo integral de si las empresas de IA realmente están respetando tus directivas de exclusión, plataformas como AmICited.com ofrecen monitoreo especializado que rastrea cómo los sistemas de IA referencian tu marca y contenido en GPTs, Perplexity, Google AI Overviews y otras plataformas de IA. Este tipo de monitoreo es especialmente valioso porque revela no solo si los rastreadores acceden a tu sitio, sino si tu contenido realmente aparece en respuestas generadas por IA—lo que indica si tu exclusión es efectiva en la práctica. El análisis regular de logs de servidor también puede revelar qué rastreadores intentan acceder a tu sitio y si respetan tus directivas de robots.txt, aunque esto requiere experiencia técnica para interpretarlo correctamente.
Mejores Prácticas para Creadores de Contenido
Para proteger eficazmente tu contenido del uso no autorizado en entrenamiento de IA, adopta un enfoque por capas que combine medidas técnicas y legales. Primero, implementa directivas robots.txt para todos los principales rastreadores de entrenamiento de IA (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot y otros), entendiendo que esto ofrece una defensa básica contra empresas compatibles. Segundo, agrega declaraciones explícitas de exclusión en los términos de servicio y metadatos de tu sitio web, dejando claro que tu contenido no debe ser utilizado para entrenamiento de modelos de IA—esto fortalece tu posición legal si ocurren violaciones. Tercero, monitorea tu configuración regularmente usando herramientas de prueba y logs de servidor para verificar que los rastreadores respetan tus directivas, y actualiza tu robots.txt trimestralmente ya que constantemente surgen nuevos rastreadores de IA. Cuarto, considera medidas técnicas adicionales como filtrado de agentes de usuario o limitación de velocidad si cuentas con recursos técnicos, reconociendo que estas brindan protección incremental contra scrapers más sofisticados. Finalmente, documenta exhaustivamente tus esfuerzos de exclusión, ya que esta documentación será crucial si necesitas emprender acciones legales contra empresas que ignoren tus directivas. Recuerda que la exclusión no es una configuración única sino un proceso continuo que requiere vigilancia y adaptación a medida que el panorama de la IA sigue evolucionando.
Preguntas frecuentes
¿Cuál es la diferencia entre la exclusión mediante robots.txt y la exclusión legal?
robots.txt es un estándar técnico y voluntario que instruye a los rastreadores a omitir tu contenido, mientras que la exclusión legal implica presentar reservas formales ante organizaciones de derechos de autor o incluir cláusulas contractuales en tus términos de servicio. robots.txt es más fácil de implementar pero carece de mecanismos de cumplimiento, mientras que la exclusión legal proporciona una protección legal más sólida pero requiere procedimientos más formales.
¿Todas las empresas de IA respetan las directivas de robots.txt?
Grandes empresas de IA como OpenAI, Google, Anthropic y Perplexity han declarado públicamente que respetan las directivas de robots.txt. Sin embargo, robots.txt es un estándar voluntario sin mecanismo de cumplimiento, por lo que los rastreadores no compatibles y los scrapers maliciosos pueden ignorar completamente tus directivas.
¿Bloquear bots de entrenamiento de IA afecta mi posicionamiento en buscadores?
No. Bloquear rastreadores de entrenamiento de IA como GPTBot y ClaudeBot no afectará tu posicionamiento en Google o Bing porque los motores de búsqueda tradicionales usan rastreadores diferentes (Googlebot, Bingbot) que operan de manera independiente. Solo bloquea esos si quieres desaparecer completamente de los resultados de búsqueda.
¿Cuál es el enfoque de la Ley de IA de la UE respecto a la exclusión?
La Ley de IA de la UE exige que los desarrolladores de IA tengan acceso legal al contenido y deben respetar las reservas de exclusión de los titulares de derechos de autor. Los titulares pueden presentar declaraciones de exclusión con sus obras, impidiendo efectivamente su uso en el entrenamiento de IA sin permiso explícito. Esto crea un mecanismo legal formal para proteger el contenido del uso no autorizado en el entrenamiento.
¿Puedo usar la exclusión para evitar que mi contenido aparezca en resultados de búsqueda de IA?
Depende del mecanismo específico. Bloquear todos los rastreadores de IA evitará que tu contenido aparezca en resultados de búsqueda de IA, pero esto también te elimina completamente de las plataformas de búsqueda impulsadas por IA. Algunos editores prefieren el bloqueo selectivo—permitiendo rastreadores enfocados en búsqueda mientras bloquean los enfocados en entrenamiento—para mantener visibilidad en la búsqueda de IA mientras protegen su contenido del entrenamiento de modelos.
¿Qué ocurre si una empresa de IA ignora mi exclusión?
Si una empresa de IA ignora tus directivas de exclusión, tienes recursos legales mediante reclamaciones por infracción de derechos de autor o incumplimiento de contrato, dependiendo de tu jurisdicción y las circunstancias específicas. Sin embargo, las acciones legales son costosas y lentas, con resultados inciertos. Por eso es crucial monitorear y documentar tus esfuerzos de exclusión.
¿Con qué frecuencia debo actualizar mi configuración de exclusión?
Revisa y actualiza tu configuración de robots.txt al menos trimestralmente. Constantemente aparecen nuevos rastreadores de IA y las empresas introducen frecuentemente nuevos agentes de usuario. Por ejemplo, Anthropic fusionó sus bots 'anthropic-ai' y 'Claude-Web' en 'ClaudeBot', dando a este nuevo bot acceso temporal sin restricciones a los sitios que no actualizaron sus reglas.
¿La exclusión es efectiva contra todos los rastreadores de IA?
La exclusión es efectiva contra empresas reputadas y compatibles que respetan robots.txt y los marcos legales. Sin embargo, es menos efectiva contra rastreadores maliciosos y scrapers no compatibles que operan en zonas grises legales. robots.txt detiene aproximadamente el 40-60% de los bots de IA, por eso se recomienda un enfoque por capas que combine medidas técnicas y legales.
Monitorea cómo la IA referencia tu contenido
Rastrea si tu contenido aparece en respuestas generadas por IA en ChatGPT, Perplexity, Google AI Overviews y otras plataformas de IA con AmICited.
Implicaciones de Derechos de Autor en Motores de Búsqueda con IA y Generación de Contenido
Comprenda los desafíos de derechos de autor que enfrentan los motores de búsqueda con IA, limitaciones del uso legítimo, demandas recientes e implicaciones lega...
Aprende sobre los acuerdos de licenciamiento de contenido para IA que regulan cómo los sistemas de inteligencia artificial utilizan contenido protegido por dere...
Cómo Licenciar tu Contenido a Empresas de IA: Derechos, Pagos y Estructuras de Acuerdo
Aprende cómo licenciar contenido a empresas de IA, entiende estructuras de pago, derechos de licencia y estrategias de negociación para maximizar tus ingresos p...
14 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.