
¿Qué es la metaetiqueta noai y cómo protege tu contenido de la IA?
Descubre qué es la metaetiqueta noai, cómo funciona para evitar la recopilación de datos de entrenamiento para IA, sus limitaciones y cómo implementarla en tu s...
8 min de lectura

Una metaetiqueta HTML que indica a los sistemas de entrenamiento de IA y rastreadores web que el contenido del sitio web no debe usarse para el entrenamiento de modelos de aprendizaje automático. Originalmente introducida por DeviantArt, sirve como un mecanismo de protección de contenidos y señal de exclusión para creadores preocupados por la recopilación no autorizada de datos por IA.
Una metaetiqueta HTML que indica a los sistemas de entrenamiento de IA y rastreadores web que el contenido del sitio web no debe usarse para el entrenamiento de modelos de aprendizaje automático. Originalmente introducida por DeviantArt, sirve como un mecanismo de protección de contenidos y señal de exclusión para creadores preocupados por la recopilación no autorizada de datos por IA.
La metaetiqueta NoAI es un mecanismo de protección de contenido implementado como una metaetiqueta HTML que señala a los sistemas de entrenamiento de IA y rastreadores web que el contenido de un sitio web no debe usarse para el entrenamiento de modelos de aprendizaje automático. Originalmente introducida por DeviantArt en septiembre de 2022, la directiva NoAI surgió como una respuesta de base ante la preocupación de que el trabajo de los artistas fuera rastreado y usado para entrenar modelos generativos de IA sin consentimiento ni compensación. La metaetiqueta funciona añadiendo una simple declaración HTML en el encabezado de la página web, comunicando una preferencia clara a los sistemas de IA de que el contenido está fuera de los límites para fines de entrenamiento. Aunque no es legalmente vinculante en la mayoría de jurisdicciones, la etiqueta NoAI representa un importante mecanismo de exclusión para creadores que buscan proteger su propiedad intelectual en una era de recopilación de datos por IA cada vez más agresiva.
Los rastreadores web (también llamados bots, spiders o scrapers) son programas automáticos que navegan sistemáticamente por internet, siguiendo enlaces y descargando contenido para indexar, analizar o recopilar datos para diversos fines. Estos rastreadores operan leyendo el archivo robots.txt ubicado en el directorio raíz de un sitio web, que contiene instrucciones sobre qué áreas del sitio deben o no deben ser accedidas por visitantes automatizados. El archivo robots.txt usa directivas específicas como User-agent, Disallow y Allow para comunicar permisos a los rastreadores, aunque el cumplimiento es completamente voluntario y depende de si el desarrollador del rastreador elige respetar estas pautas. Más allá de robots.txt, los sitios web pueden comunicar preferencias mediante encabezados HTTP y metaetiquetas, que brindan señales adicionales sobre los derechos de uso y restricciones de contenido. Diferentes tipos de rastreadores muestran distintos niveles de respeto por estas señales:
| Tipo de Rastreador | Cumplimiento robots.txt | Respeto a Metaetiqueta | Uso en Entrenamiento IA |
|---|---|---|---|
| Motores de Búsqueda | Alto | Alto | Limitado |
| Bots de Entrenamiento IA | Medio | Medio | Sí |
| Rastreadores Comerciales | Bajo | Bajo | Variable |
| Bots Académicos | Alto | Medio | Solo Investigación |
| Bots Maliciosos | Ninguno | Ninguno | Sin Restricción |
Las directivas noai y noimageai cumplen propósitos relacionados pero distintos en la protección de contenido, con la diferencia clave en su alcance y especificidad. La directiva noai es una señal más amplia que indica que todo el contenido de una página—incluyendo texto, imágenes, código y otros medios—no debe usarse para fines de entrenamiento de IA, por lo que es adecuada para sitios web con tipos de contenido mixtos o que buscan protección integral. La directiva noimageai, en cambio, apunta específicamente solo al contenido de imágenes, permitiendo que el texto y otros materiales no visuales se usen potencialmente para entrenamiento mientras se protege el material visual del entrenamiento de modelos de IA. Esta distinción es especialmente importante para sitios que desean permitir la indexación de texto por IA (para motores de búsqueda o accesibilidad) mientras protegen su contenido visual del uso en modelos generativos de imágenes. Aquí se muestran las diferencias de implementación:
<!-- Protección integral para todo el contenido -->
<meta name="robots" content="noai">
<!-- Protección específica solo para imágenes -->
<meta name="robots" content="noimageai">
<!-- Enfoque combinado para máxima claridad -->
<meta name="robots" content="noai, noimageai">
La metaetiqueta NoAI puede implementarse mediante varios métodos, cada uno con diferentes ventajas según tu infraestructura técnica y necesidades específicas. El enfoque más sencillo es añadir la metaetiqueta directamente en la sección <head> de tu HTML, lo que aplica la directiva a páginas individuales y puede personalizarse por página si es necesario. Para sitios web con muchas páginas o que buscan una solución a nivel de todo el sitio, implementar la directiva mediante encabezados de respuesta HTTP ofrece un enfoque más escalable que se aplica de manera uniforme en todo el contenido sin requerir modificaciones individuales. Además, el archivo robots.txt puede incluir directivas dirigidas a rastreadores de IA específicos, aunque este método es menos estándar que las metaetiquetas o encabezados. Aquí tienes los tres métodos principales de implementación:
<!-- Método 1: Metaetiqueta HTML (el más común) -->
<head>
<meta name="robots" content="noai">
</head>
# Método 2: directiva en robots.txt
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Método 3: Encabezado HTTP (vía .htaccess o configuración de servidor)
X-Robots-Tag: noai
Para servidores Apache, añade en .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Para servidores Nginx, añade en tu bloque de servidor:
add_header X-Robots-Tag "noai" always;
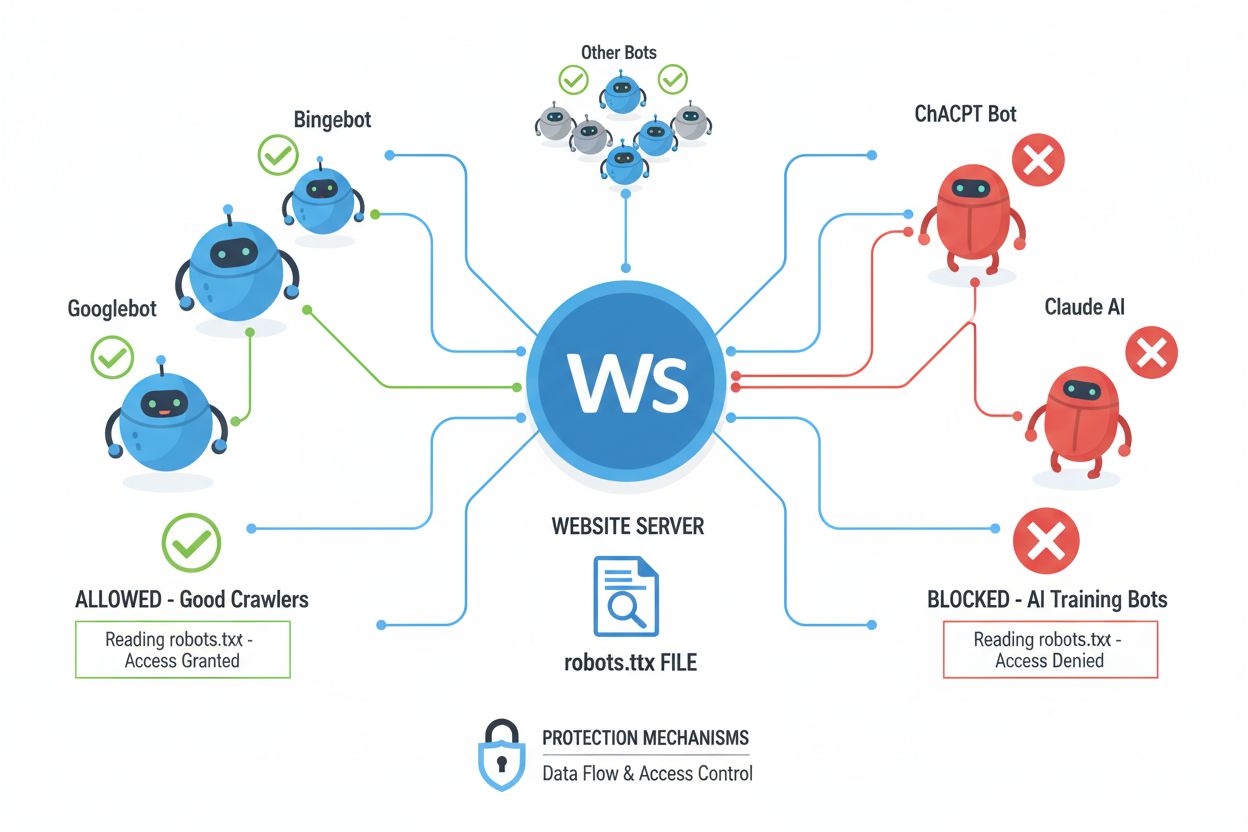
Aunque la metaetiqueta NoAI representa un paso importante hacia la protección de contenido, funciona bajo un sistema de honor que depende completamente de si los desarrolladores de IA y rastreadores de datos deciden respetar la señal. Grandes empresas de IA como OpenAI, Google y Anthropic han comenzado a respetar las directivas NoAI en sus rastreadores, pero actores maliciosos y scrapers no autorizados suelen ignorar estas señales, haciendo que la etiqueta sea ineficaz contra ladrones de datos determinados. La eficacia de NoAI se ve además limitada por el hecho de que solo previene el entrenamiento futuro en el contenido; no puede eliminar datos ya recopilados y usados en modelos existentes, ni ofrece recursos legales si se viola. Las tasas de cumplimiento varían significativamente entre los distintos sistemas de IA, con algunos respetando la directiva y otros eludiéndola deliberadamente, por lo que NoAI es una solución útil pero incompleta. La etiqueta tampoco proporciona protección contra descargas directas, capturas de pantalla o copia manual del contenido, y no puede evitar el uso por parte de competidores que simplemente la ignoran. Por estas razones, NoAI debe considerarse una capa dentro de una estrategia de protección de contenido más amplia y no una solución completa.
La metaetiqueta NoAI ha logrado una adopción significativa entre grandes empresas y plataformas de IA, con OpenAI, Google y Stability AI comprometiéndose públicamente a respetar la directiva en sus procesos de entrenamiento. La implementación de NoAI por parte de DeviantArt ha influido en conversaciones más amplias sobre el desarrollo ético de IA y el consentimiento de creadores, llevando a una mayor concientización tanto en desarrolladores de IA como en creadores de contenido. Sin embargo, la adopción sigue siendo inconsistente en la industria, con empresas de IA más pequeñas, investigadores académicos y rastreadores comerciales mostrando diferentes niveles de cumplimiento. La aparición de estándares como C2PA (Coalition for Content Provenance and Authenticity) y debates sobre expresiones de derechos legibles por máquina sugieren que la industria avanza hacia mecanismos de protección de contenido más sofisticados y respaldados legalmente, yendo más allá de las metaetiquetas voluntarias. Organizaciones y organismos de estandarización trabajan activamente en formalizar estas protecciones, con la expectativa de que la regulación futura de la IA podría exigir el cumplimiento explícito de las preferencias de los creadores de contenido, transformando potencialmente a NoAI de una señal voluntaria a un requisito legalmente exigible.
Implementar la protección NoAI debe formar parte de un enfoque por capas en la seguridad de contenidos y no ser una solución aislada, combinando estrategias técnicas, legales y de monitoreo para una protección integral. Para maximizar la eficacia, considera estas buenas prácticas:
Además, realiza auditorías regulares de la implementación de tu protección para asegurarte de que todas las páginas incluyan las directivas adecuadas y considera usar herramientas automatizadas para escanear tu contenido en conjuntos de datos públicos de IA y repositorios de entrenamiento. Documenta tu implementación de NoAI como parte de tu política de gobernanza de contenido y comunica estas protecciones a tu audiencia para que comprendan las medidas que tomas para proteger su trabajo si eres una plataforma que aloja contenido generado por usuarios.
La directiva noai protege todos los tipos de contenido (texto, imágenes, código) del entrenamiento de IA, mientras que noimageai protege específicamente solo el contenido de imágenes. Usa noai para protección integral y noimageai cuando quieras permitir la indexación de texto pero proteger los recursos visuales de los modelos generativos de imágenes.
No, la metaetiqueta NoAI funciona bajo un sistema de honor y depende de si los desarrolladores de IA deciden respetarla. Grandes empresas como OpenAI y Google la respetan, pero actores maliciosos y rastreadores no autorizados suelen ignorar estas señales, por lo que es una capa de protección y no una solución completa.
Puedes implementarla de tres formas: añadiendo la metaetiqueta HTML en el encabezado de tu página, configurando encabezados HTTP en tu servidor o incluyendo directivas en tu archivo robots.txt. El método de metaetiqueta HTML es el más común y sencillo para la mayoría de propietarios de sitios web.
Grandes empresas de IA como OpenAI (ChatGPT), Google, Anthropic (Claude) y Stability AI se han comprometido públicamente a respetar las directivas NoAI en sus procesos de entrenamiento. Sin embargo, el cumplimiento varía entre empresas de IA más pequeñas, investigadores académicos y rastreadores comerciales.
Sí, puedes usar ambos simultáneamente para máxima efectividad. La metaetiqueta NoAI y las directivas de robots.txt trabajan juntas para comunicar tus preferencias de protección de contenido a diferentes tipos de rastreadores y sistemas.
Combina NoAI con otros métodos de protección como encabezados HTTP, reglas en robots.txt, marcas de agua, controles de acceso y términos legales de servicio. Monitorea tu contenido en conjuntos de datos de IA y considera usar herramientas para rastrear el uso no autorizado.
Aunque es ampliamente adoptada por grandes empresas de IA, NoAI aún no es un estándar formal de la W3C. Sin embargo, organizaciones del sector trabajan en estándares más avanzados como C2PA y expresiones de derechos legibles por máquina que eventualmente podrían brindar respaldo legal.
NoAI es más efectiva cuando se combina con otros métodos como robots.txt, encabezados HTTP, marcas de agua, controles de acceso y protecciones legales. Ningún método por sí solo brinda protección completa, por lo que se recomienda un enfoque por capas para una seguridad integral del contenido.
Rastrea qué sistemas de IA están citando tu marca y contenido con la plataforma de monitoreo de IA de AmICited. Conoce exactamente cómo se está utilizando tu trabajo en ChatGPT, Perplexity, Google AI Overviews y otros sistemas de IA.
Descubre qué es la metaetiqueta noai, cómo funciona para evitar la recopilación de datos de entrenamiento para IA, sus limitaciones y cómo implementarla en tu s...
Debate comunitario sobre la metaetiqueta noai y si realmente protege el contenido del entrenamiento de IA. Usuarios comparten experiencias y limitaciones de est...
Conozca los mecanismos de exclusión de entrenamiento de IA, incluidos robots.txt, marcos legales y mejores prácticas para proteger su contenido del uso no autor...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.