Audit d'accès des crawlers IA : les bons robots voient-ils votre contenu ?
Découvrez comment auditer l’accès des crawlers IA à votre site web. Identifiez quels bots peuvent voir votre contenu et corrigez les obstacles empêchant la visibilité IA dans ChatGPT, Perplexity et d’autres moteurs de recherche IA.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Pourquoi les audits de crawlers IA sont essentiels
Le paysage de la recherche et de la découverte de contenu évolue radicalement. Avec la croissance exponentielle des outils de recherche alimentés par l’IA comme ChatGPT, Perplexity et Google AI Overviews, la visibilité de votre contenu aux yeux des crawlers IA est devenue aussi cruciale que l’optimisation pour les moteurs de recherche traditionnels. Si les bots IA ne peuvent pas accéder à votre contenu, votre site devient invisible pour des millions d’utilisateurs qui comptent sur ces plateformes pour obtenir des réponses. Les enjeux sont plus élevés que jamais : alors que Google pourrait revisiter votre site en cas de problème, les crawlers IA fonctionnent selon un paradigme différent—et rater ce premier crawl critique peut signifier des mois de visibilité perdue et d’opportunités manquées de citations, de trafic et d’autorité de marque.
En quoi les crawlers IA diffèrent-ils des bots traditionnels
Les crawlers IA obéissent à des règles fondamentalement différentes de celles des bots Google et Bing pour lesquels vous avez optimisé pendant des années. La différence la plus critique : les crawlers IA ne rendent pas le JavaScript, ce qui signifie que le contenu dynamique chargé via des scripts côté client leur est invisible—un contraste frappant avec les capacités avancées de rendu de Google. De plus, les crawlers IA visitent les sites avec une fréquence bien plus élevée, parfois 100 fois plus souvent que les moteurs de recherche traditionnels, créant à la fois des opportunités et des défis pour les ressources serveur. Contrairement au modèle d’indexation de Google, les crawlers IA ne maintiennent pas un index persistant qui serait rafraîchi ; ils crawlent à la demande quand les utilisateurs interrogent leurs systèmes. Cela signifie qu’il n’y a pas de file d’attente pour la réindexation, pas de Search Console pour demander un recrawl, et pas de seconde chance si votre site rate cette première impression. Comprendre ces différences est essentiel pour optimiser votre stratégie de contenu.
Fonctionnalité
Crawlers IA
Bots traditionnels
Rendu JavaScript
Non (HTML statique uniquement)
Oui (rendu complet)
Fréquence de crawl
Très élevée (100x+ plus fréquent)
Modérée (hebdomadaire/mensuelle)
Capacité de réindexation
Aucune (à la demande uniquement)
Oui (mises à jour continues)
Exigences de contenu
HTML simple, balisage schema
Flexible (gère le contenu dynamique)
Blocage User-Agent
Spécifique par bot (GPTBot, ClaudeBot, etc.)
Générique (Googlebot, Bingbot)
Stratégie de cache
Snapshots court terme
Maintenance d’index long terme
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Votre contenu pourrait être invisible aux crawlers IA pour des raisons auxquelles vous n’avez jamais pensé. Voici les principaux obstacles empêchant les bots IA d’accéder à votre contenu et de le comprendre :
Contenu fortement basé sur JavaScript : si votre site s’appuie sur du JavaScript côté client pour afficher du texte, des images ou des données structurées, les crawlers IA ne le verront pas—ils ne traitent que le HTML statique
Absence de balisage schema : sans données structurées appropriées (JSON-LD, microdonnées), les crawlers IA ont du mal à comprendre le contexte, l’auteur, la date de publication et les relations de contenu
Problèmes d’infrastructure technique : des temps de réponse serveur lents, des erreurs 5xx, des chaînes de redirections et de mauvais Core Web Vitals peuvent pousser les crawlers à abandonner votre site en cours d’exploration
Contenu protégé ou payant : le contenu derrière des murs de connexion, des paywalls ou des CAPTCHA est totalement inaccessible aux crawlers IA
Règles robots.txt trop restrictives : bloquer des répertoires entiers ou des user-agents empêche les crawlers d’accéder au contenu que vous souhaitez pourtant leur montrer
Blocages liés au pare-feu et à la sécurité : des règles WAF (Web Application Firewall), un blocage d’IP ou un rate-limiting peuvent qualifier à tort les crawlers IA de menaces et les bloquer complètement
Comprendre robots.txt et les règles User-Agent
Votre fichier robots.txt est le principal mécanisme pour contrôler quels bots IA peuvent accéder à votre contenu, et il fonctionne via des règles User-Agent spécifiques ciblant chaque crawler. Chaque plateforme IA utilise des chaînes user-agent distinctes—GPTBot d’OpenAI, ClaudeBot d’Anthropic, PerplexityBot de Perplexity—et vous pouvez autoriser ou interdire chacun indépendamment. Ce contrôle granulaire vous permet de choisir quels systèmes IA peuvent s’entraîner sur ou citer votre contenu, ce qui est crucial pour protéger des informations propriétaires ou gérer des préoccupations concurrentielles. Cependant, de nombreux sites bloquent par inadvertance les crawlers IA via des règles trop larges conçues pour d’anciens bots, ou bien n’implémentent pas correctement de règles du tout.
Voici un exemple de configuration de robots.txt pour différents bots IA :
# Autoriser GPTBot d’OpenAI
User-agent: GPTBot
Allow: /
# Bloquer ClaudeBot d’Anthropic
User-agent: ClaudeBot
Disallow: /
# Autoriser Perplexity mais restreindre certains répertoires
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Règle par défaut pour tous les autres bots
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
L’importance de la première impression
Contrairement à Google, qui crawle et ré-indexe votre site en continu, les crawlers IA fonctionnent sur une base unique—ils visitent dès qu’un utilisateur interroge leur système, et si votre contenu n’est pas accessible à ce moment-là, l’opportunité est perdue. Cette différence fondamentale signifie que votre site doit être prêt techniquement dès le premier jour ; il n’y a pas de délai de grâce, pas de seconde chance pour corriger les problèmes avant que la visibilité ne soit impactée. Une mauvaise première expérience de crawl—due à des échecs de rendu JavaScript, un balisage schema absent ou des erreurs serveur—peut entraîner l’exclusion de votre contenu des réponses générées par l’IA pendant des semaines ou des mois. Il n’existe pas d’option de réindexation manuelle, pas de bouton “Request Indexing” dans une console, ce qui rend la surveillance proactive et l’optimisation indispensables. La pression pour réussir du premier coup n’a jamais été aussi forte.
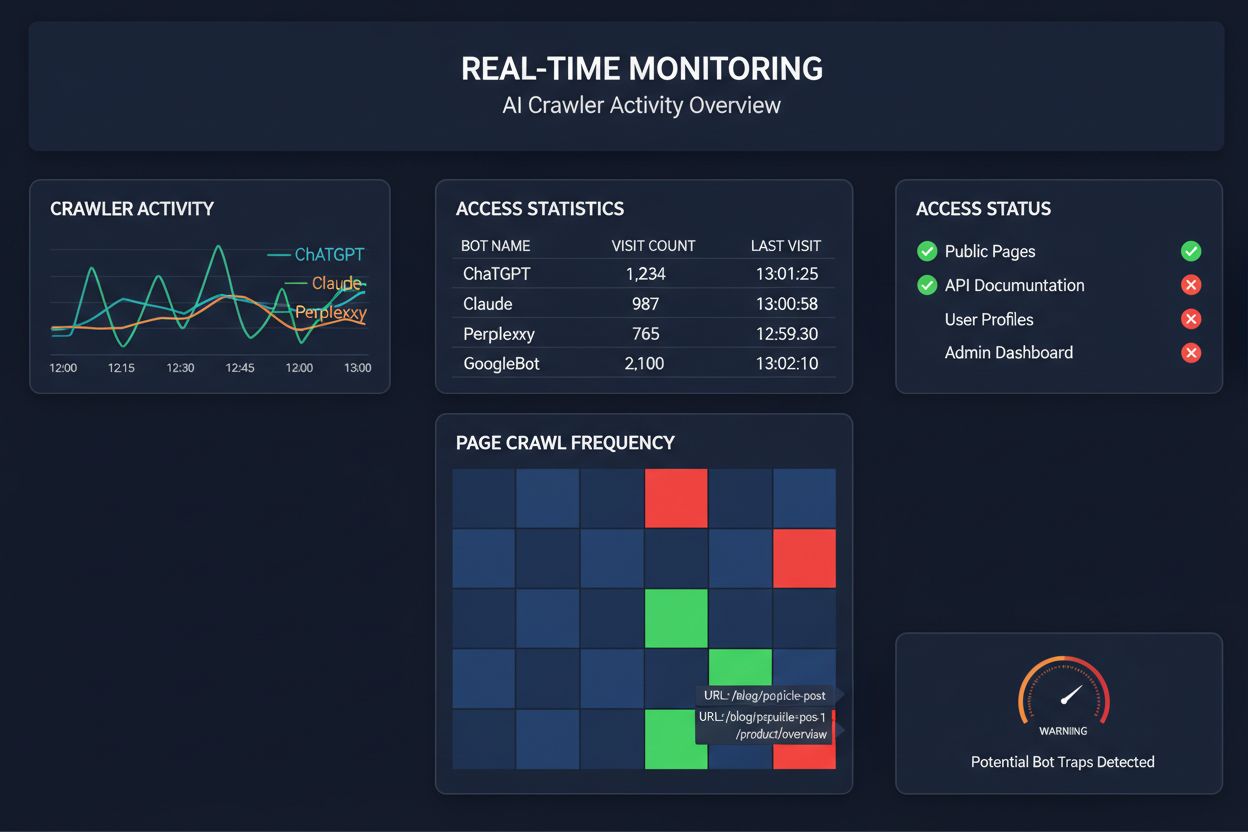
Surveillance en temps réel vs crawls programmés
Se contenter de crawls programmés pour surveiller l’accès des crawlers IA, c’est comme vérifier la présence d’un incendie chez vous une fois par mois—vous manquez les moments critiques où les problèmes surviennent. La surveillance en temps réel détecte les problèmes dès qu’ils se produisent, vous permettant de réagir avant que votre contenu ne devienne invisible pour les systèmes IA. Les audits programmés, généralement hebdomadaires ou mensuels, créent des angles morts dangereux où votre site pourrait échouer auprès des crawlers IA pendant des jours sans que vous le sachiez. Les solutions en temps réel suivent le comportement des crawlers en continu, vous alertant en cas d’échec de rendu JavaScript, d’erreur de balisage schema, de blocage firewall ou de problème serveur. Cette approche proactive transforme votre audit en une véritable stratégie de gestion de visibilité et non un simple contrôle de conformité. Avec un trafic de crawlers IA potentiellement 100 fois plus élevé que les moteurs de recherche traditionnels, le coût de quelques heures d’inaccessibilité peut être très important.
Outils et solutions pour les audits de crawlers IA
Plusieurs plateformes proposent aujourd’hui des outils spécialisés pour surveiller et optimiser l’accès des crawlers IA. Cloudflare AI Crawl Control offre une gestion au niveau de l’infrastructure du trafic des bots IA, vous permettant de définir des limites de taux et des politiques d’accès. Conductor propose des tableaux de bord de surveillance complets qui affichent la manière dont les différents crawlers IA interagissent avec votre contenu. Elementive est axé sur les audits SEO techniques avec une attention particulière aux exigences des crawlers IA. AdAmigo et MRS Digital fournissent des services de conseil et de surveillance spécialisés pour la visibilité IA. Cependant, pour une surveillance continue et en temps réel spécifiquement conçue pour suivre les schémas d’accès des crawlers IA et vous alerter avant que des problèmes n’impactent la visibilité, AmICited s’impose comme une solution dédiée. AmICited est spécialisé dans la surveillance des systèmes IA qui accèdent à votre contenu, la fréquence de leurs crawls et la détection de barrières techniques. Cette spécialisation sur le comportement des crawlers IA—plutôt que sur les métriques SEO classiques—en fait un outil indispensable pour les organisations qui prennent au sérieux leur visibilité IA.
Processus d’audit étape par étape
La réalisation d’un audit complet de crawler IA nécessite une approche méthodique. Étape 1 : Établissez une base de référence en vérifiant votre fichier robots.txt actuel et en identifiant quels bots IA vous autorisez ou bloquez. Étape 2 : Auditez votre infrastructure technique en testant l’accessibilité de votre site aux crawlers sans JavaScript, vérifiez les temps de réponse serveur et assurez-vous que le contenu critique est servi en HTML statique. Étape 3 : Mettez en place et validez le balisage schema sur l’ensemble de votre contenu, en veillant à ce que l’auteur, la date de publication, le type de contenu et les autres métadonnées soient correctement structurés au format JSON-LD. Étape 4 : Surveillez le comportement des crawlers avec des outils comme AmICited pour savoir quels bots IA accèdent à votre site, à quelle fréquence et s’ils rencontrent des erreurs. Étape 5 : Analysez les résultats en examinant les logs de crawl, en identifiant les motifs d’échec et en hiérarchisant les corrections selon leur impact. Étape 6 : Appliquez les correctifs en commençant par les problèmes à fort impact comme les soucis de rendu JavaScript ou l’absence de schema, puis passez aux optimisations secondaires. Étape 7 : Mettez en place une surveillance continue pour détecter de nouveaux problèmes avant qu’ils n’affectent la visibilité, et configurez des alertes en cas d’échec de crawl ou de blocage d’accès.
Actions rapides pour améliorer l’explorabilité IA
Vous n’avez pas besoin d’une refonte totale pour améliorer l’accès des crawlers IA—plusieurs changements à fort impact peuvent être mis en place rapidement. Servez le contenu critique en HTML simple plutôt que de compter sur le rendu JavaScript ; si l’utilisation de JavaScript est indispensable, assurez-vous que les textes importants et les métadonnées sont aussi présents dans le payload HTML initial. Ajoutez un balisage schema complet au format JSON-LD, incluant le schéma d’article, les informations d’auteur, les dates de publication et les relations entre contenus—cela aide les crawlers IA à comprendre le contexte et à bien attribuer le contenu. Soignez la mention de l’auteur via le balisage schema et les signatures, car les systèmes IA privilégient de plus en plus la citation de sources faisant autorité. Surveillez et optimisez les Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), car des pages lentes peuvent être abandonnées par les crawlers avant la fin du traitement. Vérifiez et mettez à jour votre robots.txt pour éviter de bloquer par inadvertance les bots IA que vous souhaitez voir accéder à votre contenu. Corrigez les problèmes techniques comme les chaînes de redirections, les liens cassés et les erreurs serveur qui pourraient amener les crawlers à abandonner votre site en cours d’exploration.
Surveiller différents bots IA
Tous les crawlers IA n’ont pas la même fonction, et comprendre ces différences vous aide à prendre les bonnes décisions en matière de contrôle d’accès. GPTBot (OpenAI) est principalement utilisé pour la collecte de données d’entraînement et l’amélioration des modèles, ce qui est pertinent si vous souhaitez que votre contenu influence les réponses de ChatGPT. OAI-SearchBot (OpenAI) crawl spécifiquement pour la citation dans les résultats de recherche, c’est le bot responsable d’intégrer votre contenu dans les réponses de ChatGPT liées à la recherche. ClaudeBot (Anthropic) assure des fonctions similaires pour Claude, l’assistant IA d’Anthropic. PerplexityBot (Perplexity) crawl pour citer dans le moteur de recherche IA de Perplexity, qui est devenu une source de trafic majeure pour de nombreux éditeurs. Chaque bot adopte des schémas de crawl, des fréquences et des objectifs différents—certains sont axés sur la collecte de données d’entraînement, d’autres sur la citation en temps réel dans la recherche. Le choix des bots à autoriser ou bloquer doit s’aligner sur votre stratégie de contenu : si vous souhaitez être cité dans les résultats de recherche IA, autorisez les bots dédiés à la recherche ; si vous craignez l’utilisation de vos données pour l’entraînement, vous pouvez bloquer les bots de collecte tout en autorisant les bots de recherche. Cette approche nuancée de la gestion des bots est bien plus sophistiquée que le traditionnel « tout autoriser » ou « tout bloquer ».
Questions fréquemment posées
Qu'est-ce qu'un audit de crawler IA ?
Un audit de crawler IA est une évaluation complète de l'accessibilité de votre site web aux bots IA comme ChatGPT, Claude et Perplexity. Il identifie les obstacles techniques, les problèmes de rendu JavaScript, l'absence de balisage schema et d'autres facteurs empêchant les crawlers IA d'accéder à votre contenu et de le comprendre. L'audit fournit des recommandations concrètes pour améliorer votre visibilité dans la recherche et les moteurs de réponse alimentés par l'IA.
À quelle fréquence dois-je auditer l'accès des crawlers IA à mon site ?
Nous recommandons de réaliser un audit complet au moins tous les trimestres, ou à chaque modification importante de l'infrastructure technique, de la structure du contenu ou du fichier robots.txt de votre site. Cependant, une surveillance continue en temps réel est idéale pour détecter immédiatement les problèmes dès qu'ils surviennent. De nombreuses organisations utilisent des outils de surveillance automatisés qui les alertent en temps réel en cas d'échec de crawl, complétés par des audits approfondis trimestriels.
Quelle est la différence entre bloquer et autoriser les crawlers IA ?
Autoriser les crawlers IA signifie que votre contenu peut être accessible, analysé et potentiellement cité par les systèmes IA, ce qui peut accroître votre visibilité dans les réponses et recommandations générées par l'IA. Bloquer les crawlers IA les empêche d'accéder à votre contenu, protégeant ainsi des informations propriétaires mais pouvant réduire votre visibilité dans les résultats de recherche IA. Le bon choix dépend de vos objectifs business, de la sensibilité de votre contenu et de votre positionnement concurrentiel.
Puis-je bloquer certains bots IA tout en en autorisant d'autres ?
Oui, tout à fait. Votre fichier robots.txt permet un contrôle granulaire via des règles User-Agent. Vous pouvez bloquer GPTBot tout en autorisant PerplexityBot, ou autoriser les bots axés recherche (comme OAI-SearchBot) tout en bloquant les bots de collecte de données (comme GPTBot). Cette approche nuancée vous permet d'optimiser votre stratégie de contenu selon les plateformes IA qui comptent le plus pour votre activité.
Que signifie le fait que les crawlers IA ne puissent pas accéder à mon contenu ?
Si les crawlers IA ne peuvent pas accéder à votre contenu, cela signifie que votre site est effectivement invisible pour les moteurs de recherche et plateformes de réponse alimentés par l'IA. Votre contenu ne sera ni cité, ni recommandé, ni inclus dans les réponses générées par l'IA, même s'il est très pertinent. Cela peut entraîner une perte de trafic, une baisse de la visibilité de la marque et des occasions manquées pour asseoir votre autorité dans les résultats de recherche IA.
Comment savoir quels bots IA visitent mon site ?
Vous pouvez consulter les logs de votre serveur pour repérer les chaînes User-Agent des crawlers IA connus (GPTBot, ClaudeBot, PerplexityBot, etc.), ou utiliser des outils spécialisés comme AmICited qui suivent en temps réel l'activité des crawlers IA. Ces outils vous montrent quels bots accèdent à votre site, à quelle fréquence ils crawlent, quelles pages ils visitent et s'ils rencontrent des erreurs ou des blocages.
Dois-je bloquer les crawlers IA de mon site web ?
Cela dépend de votre situation spécifique. Si votre contenu est propriétaire, sensible ou si vous craignez une utilisation pour l'entraînement de modèles, le blocage peut être approprié. En revanche, si vous souhaitez apparaître dans les résultats de recherche IA et être cité par les systèmes IA, il est indispensable d'autoriser les crawlers. Beaucoup d'organisations optent pour une approche intermédiaire : autoriser les bots axés recherche qui génèrent des citations, tout en bloquant les bots de collecte de données.
Quel est l'impact du JavaScript sur l'accès des crawlers IA ?
Les crawlers IA ne rendent pas le JavaScript, ce qui signifie que tout contenu chargé dynamiquement via des scripts côté client leur est invisible. Si votre site dépend fortement du JavaScript pour son contenu essentiel, sa navigation ou ses données structurées, les crawlers IA ne verront que le HTML brut et manqueront des informations importantes. Cela peut fortement impacter la façon dont votre contenu est compris et représenté dans les réponses IA. Il est essentiel de servir le contenu critique en HTML statique pour garantir l'exploration par les IA.
Surveillez l'accès de vos crawlers IA avec AmICited
Obtenez des informations en temps réel sur les bots IA qui accèdent à votre contenu et sur la façon dont ils voient votre site web. Lancez votre audit gratuit dès aujourd'hui et assurez-vous que votre marque est visible sur toutes les plateformes de recherche IA.
Suivi de l'activité des crawlers IA : Guide complet de surveillance
Apprenez à suivre et surveiller l'activité des crawlers IA sur votre site web à l'aide des logs serveurs, d'outils et de bonnes pratiques. Identifiez GPTBot, Cl...
Comment identifier les crawlers IA dans vos journaux de serveur
Apprenez à identifier et surveiller les crawlers IA comme GPTBot, ClaudeBot et PerplexityBot dans vos journaux de serveur. Guide complet avec chaînes user-agent...
Le guide complet pour bloquer (ou autoriser) les crawlers IA
Apprenez à bloquer ou autoriser les crawlers IA comme GPTBot et ClaudeBot grâce à robots.txt, au blocage serveur et à des méthodes de protection avancées. Guide...
8 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.