
Faut-il bloquer ou autoriser les crawlers IA ? Cadre de décision
Découvrez comment prendre des décisions stratégiques concernant le blocage des crawlers IA. Évaluez le type de contenu, les sources de trafic, les modèles de re...
13 min de lecture

Découvrez comment les crawlers IA impactent les ressources serveur, la bande passante et la performance. Consultez des statistiques réelles, des stratégies de mitigation et des solutions d’infrastructure pour gérer efficacement la charge des bots.
Les crawlers IA sont devenus un acteur majeur du trafic web, avec les grandes entreprises d’IA déployant des bots sophistiqués pour indexer le contenu à des fins d’entraînement et de récupération. Ces crawlers opèrent à très grande échelle, générant environ 569 millions de requêtes par mois sur le web et consommant plus de 30 To de bande passante à l’échelle mondiale. Les principaux crawlers IA incluent GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) et Amazonbot (Amazon), chacun ayant des schémas d’exploration et des exigences en ressources distincts. Comprendre le comportement et les spécificités de ces crawlers est essentiel pour les administrateurs de sites web afin de bien gérer les ressources serveur et prendre des décisions éclairées sur les politiques d’accès.
| Nom du crawler | Entreprise | Objectif | Schéma de requêtes |
|---|---|---|---|
| GPTBot | OpenAI | Données d’entraînement pour ChatGPT et modèles GPT | Requêtes agressives, haute fréquence |
| ClaudeBot | Anthropic | Données d’entraînement pour les modèles Claude AI | Fréquence modérée, exploration respectueuse |
| PerplexityBot | Perplexity AI | Recherche temps réel et génération de réponses | Fréquence modérée à élevée |
| Google-Extended | Indexation étendue pour fonctionnalités IA | Contrôlé, respecte robots.txt | |
| Amazonbot | Amazon | Indexation produits et contenus | Variable, axé sur le commerce |
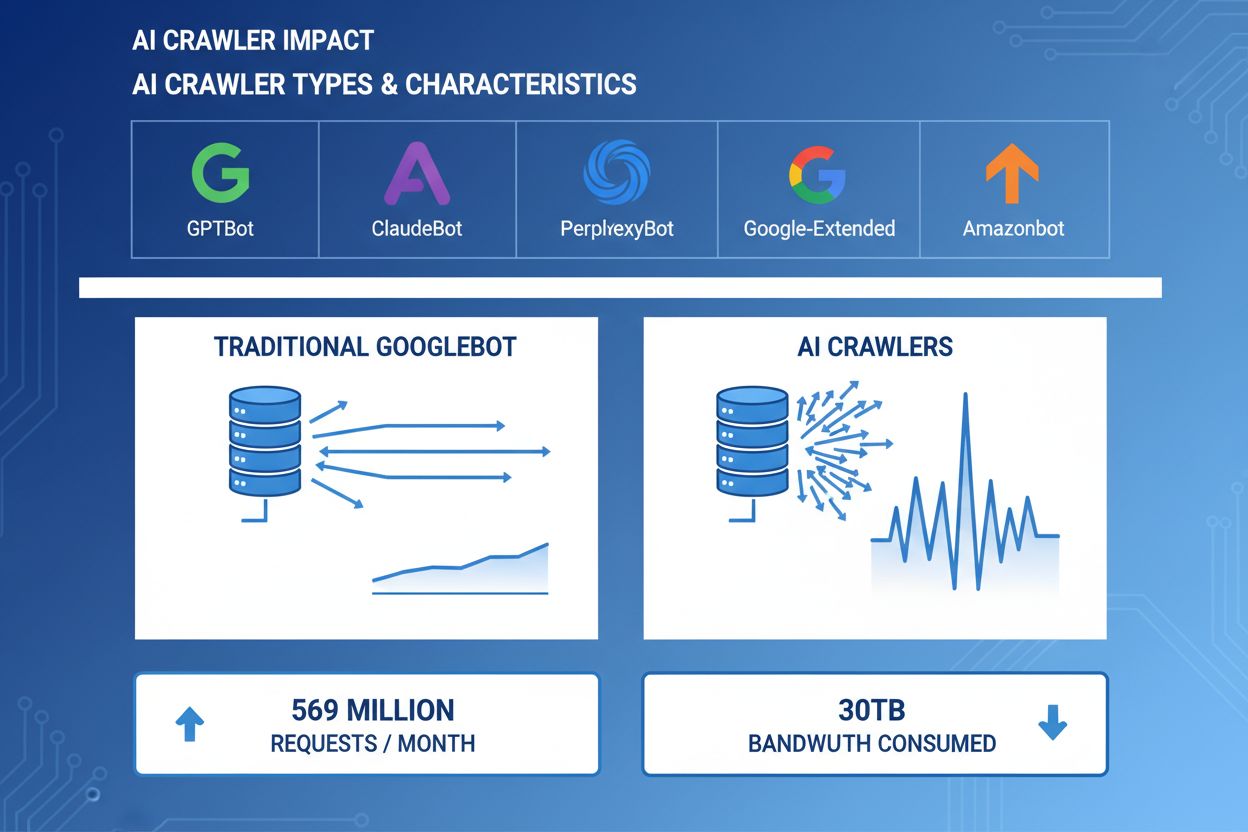
Les crawlers IA consomment des ressources serveur sur plusieurs axes, avec un impact mesurable sur la performance de l’infrastructure. L’utilisation CPU peut grimper de 300 % ou plus lors des pics d’activité crawler, les serveurs devant traiter des milliers de requêtes simultanées et analyser le contenu HTML. La consommation de bande passante est l’un des coûts les plus visibles : un site populaire peut ainsi servir plusieurs gigaoctets de données aux crawlers chaque jour. La mémoire augmente sensiblement, les serveurs maintenant des pools de connexions et des tampons de données importants. Les requêtes base de données se multiplient lorsque les crawlers consultent des pages générant du contenu dynamique, ajoutant une pression supplémentaire sur l’I/O. L’I/O disque devient un goulet d’étranglement lorsque le serveur doit lire le stockage pour répondre aux crawlers, notamment sur les sites riches en contenu.
| Ressource | Impact | Exemple réel |
|---|---|---|
| CPU | Pics de 200-300 % lors des explorations | Charge serveur passant de 2.0 à 8.0 |
| Bande passante | 15-40 % de l’utilisation mensuelle | Site de 500 Go servant 150 Go aux crawlers/mois |
| Mémoire | Augmentation de 20-30 % de la RAM | Serveur 8 Go nécessitant 10 Go durant l’activité crawler |
| Base de données | Charge de requêtes multipliée par 2 à 5 | Temps de réponse passant de 50ms à 250ms |
| I/O disque | Lecture soutenue à haute fréquence | Utilisation disque de 30 % à 85 % |
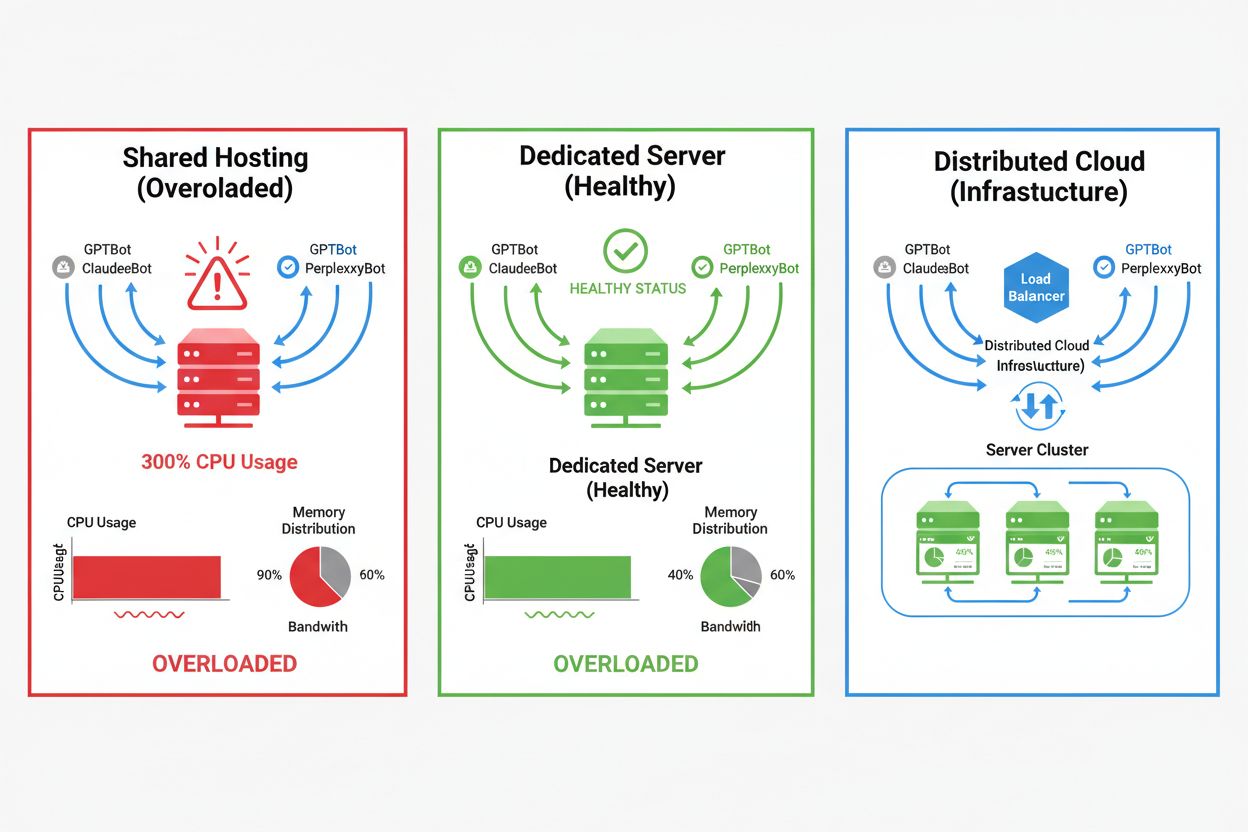
L’impact des crawlers IA varie fortement selon l’environnement d’hébergement, les environnements mutualisés subissant les conséquences les plus sévères. En mutualisé, le « syndrome du voisin bruyant » est particulièrement problématique : lorsqu’un site attire un trafic crawler important, il consomme des ressources au détriment des autres sites hébergés, dégradant la performance globale. Les serveurs dédiés et le cloud offrent une meilleure isolation et des garanties de ressources, permettant d’absorber la charge des crawlers sans affecter les autres services. Cependant, même en dédié, une surveillance attentive et une montée en charge réfléchie sont nécessaires pour faire face au cumul de plusieurs crawlers IA simultanés.
Principales différences entre environnements d’hébergement :
L’impact financier du trafic crawler IA va bien au-delà du coût simple de la bande passante, englobant des dépenses directes et cachées pouvant affecter considérablement votre rentabilité. Les frais directs incluent la hausse de la facture bande passante chez l’hébergeur, pouvant représenter plusieurs centaines ou milliers d’euros par mois selon le trafic et l’intensité crawler. Les coûts cachés découlent de besoins d’infrastructure accrus : passage à des offres d’hébergement supérieures, mise en place de caches additionnels, ou investissement dans un CDN spécifiquement pour absorber le trafic crawler. Le calcul du ROI devient complexe, car les crawlers IA apportent peu de valeur directe à l’entreprise tout en consommant les ressources susceptibles de mieux servir des clients ou d’améliorer l’expérience utilisateur. De nombreux propriétaires de sites constatent que le coût d’accueil des crawlers dépasse largement tout bénéfice potentiel lié à l’entraînement IA ou à la visibilité dans les résultats IA.
Le trafic crawler IA dégrade directement l’expérience des visiteurs légitimes en consommant des ressources serveur qui pourraient accélérer le service aux humains. Les indicateurs Core Web Vitals se dégradent sensiblement, avec le Largest Contentful Paint (LCP) augmentant de 200 à 500 ms et le Time to First Byte (TTFB) se dégradant de 100 à 300 ms pendant les pics d’activité crawler. Ces dégradations engendrent des effets en cascade : pages plus lentes, engagement utilisateur en baisse, taux de rebond en hausse, et, au final, une baisse du taux de conversion pour l’e-commerce ou la génération de leads. Le référencement souffre également, Google intégrant les Core Web Vitals dans son algorithme de classement : le trafic crawler peut donc indirectement nuire au SEO. Les utilisateurs confrontés à des temps de chargement longs abandonnent plus facilement le site, impactant directement le chiffre d’affaires et la perception de la marque.
La gestion efficace du trafic crawler IA commence par une surveillance et une détection complètes, permettant de cerner l’ampleur du problème avant toute action. La plupart des serveurs web enregistrent les chaînes user-agent identifiant le crawler pour chaque requête : base de toute analyse et filtrage. Les logs serveur, plateformes analytics et outils spécialisés permettent de parser ces user-agents pour identifier et quantifier les schémas de trafic crawler.
Méthodes et outils clés pour la détection :
La première défense contre l’excès de trafic crawler IA consiste à configurer un fichier robots.txt adapté, pour contrôler explicitement l’accès crawler à votre site. Ce fichier texte simple à la racine du site permet d’interdire certains crawlers, de limiter la fréquence d’exploration, ou de pointer vers un sitemap dédié. La limitation de débit (rate limiting) au niveau applicatif ou serveur ajoute une couche de protection, en ralentissant les requêtes de certaines IP ou user-agents pour éviter l’épuisement des ressources. Ces solutions sont non bloquantes et réversibles, idéales comme premières mesures avant des actions plus strictes.
# robots.txt - Bloquer les crawlers IA tout en autorisant les moteurs de recherche légitimes
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Autoriser Google et Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Délai d’exploration pour les autres bots
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Les Web Application Firewalls (WAF) et Content Delivery Networks (CDN) offrent des protections sophistiquées de niveau entreprise contre le trafic crawler non désiré via l’analyse comportementale et le filtrage intelligent. Cloudflare et d’autres CDN proposent des fonctionnalités natives de gestion des bots capables d’identifier et bloquer les crawlers IA selon leurs schémas de comportement, la réputation IP ou les caractéristiques des requêtes, sans configuration manuelle. Les règles WAF permettent de défier les requêtes suspectes, de limiter le débit pour certains user-agents ou de bloquer les IPs de crawlers connues. Ces solutions filtrent le trafic en périphérie, protégeant le serveur d’origine et réduisant drastiquement la charge sur l’infrastructure. Leur avantage est de s’adapter en continu à l’apparition de nouveaux crawlers ou schémas d’attaque, sans intervention sur la configuration.
Décider de bloquer ou non les crawlers IA nécessite d’arbitrer entre la protection des ressources serveur et la préservation de la visibilité dans les résultats IA ou applications alimentées par l’IA. Bloquer tous les crawlers IA empêche votre contenu d’apparaître dans la recherche ChatGPT, les réponses Perplexity ou autres mécanismes de découverte IA, ce qui peut réduire le trafic de référence ou la visibilité de la marque. À l’inverse, autoriser sans restriction les crawlers consomme d’importantes ressources et peut dégrader l’expérience utilisateur sans bénéfice tangible. La stratégie optimale dépend de chaque situation : un site à fort trafic avec des ressources abondantes pourra laisser passer les crawlers, tandis qu’un site limité devra privilégier l’expérience utilisateur en bloquant ou limitant l’accès crawler. Le choix doit reposer sur votre secteur, votre audience, le type de contenu et vos objectifs business, et non sur une approche unique.
Pour les sites choisissant d’accepter le trafic crawler IA, l’évolution de l’infrastructure permet de maintenir la performance malgré la charge accrue. Le scaling vertical — ajouter CPU, RAM ou bande passante — est la solution la plus simple mais coûteuse, avec des limites physiques. Le scaling horizontal — répartir le trafic sur plusieurs serveurs via des load balancers — offre une meilleure évolutivité sur le long terme. Les plateformes cloud comme AWS, Google Cloud ou Azure proposent l’auto-scaling : des ressources sont ajoutées automatiquement lors des pics de trafic, puis réduites pour optimiser les coûts. Les CDN permettent de mettre en cache le contenu statique en périphérie, déchargeant le serveur d’origine et accélérant le service aussi bien pour les visiteurs que pour les crawlers. L’optimisation des bases de données, la mise en cache des requêtes et les améliorations applicatives réduisent également la consommation de ressources par requête, améliorant l’efficacité sans investissement matériel.
Une surveillance continue et une optimisation régulière sont indispensables pour préserver la performance face au trafic crawler IA. Les outils spécialisés offrent une visibilité sur l’activité crawler, la consommation de ressources et les métriques de performance, permettant d’adapter vos stratégies sur la base de données concrètes. Mettre en place une surveillance complète dès le départ permet d’établir des bases de référence, d’identifier les tendances et de mesurer l’efficacité des mesures de mitigation dans la durée.
Outils et pratiques essentiels :
La gestion des crawlers IA évolue rapidement, avec de nouveaux standards et des initiatives sectorielles redéfinissant les relations entre sites web et entreprises IA. Le standard llms.txt propose une nouvelle approche pour transmettre aux sociétés IA des informations structurées sur les droits et préférences d’utilisation de contenu, offrant une alternative plus nuancée que le blocage global. Les discussions autour de modèles de rémunération laissent entrevoir que les entreprises IA pourraient bientôt rémunérer les sites pour l’accès aux données d’entraînement, bouleversant l’économie du trafic crawler. Préparer l’avenir suppose de rester informé des nouveaux standards, de suivre l’actualité du secteur et de maintenir de la souplesse dans vos politiques de gestion crawler. Nouer le dialogue avec les entreprises IA, participer aux discussions et défendre des modèles de rémunération équitables seront de plus en plus importants à mesure que l’IA deviendra centrale dans la découverte web et la consommation de contenu. Les sites qui prospéreront dans ce nouvel écosystème seront ceux qui concilient innovation et pragmatisme, protégeant leurs ressources tout en restant ouverts aux opportunités de visibilité et de partenariat.
Les crawlers IA (GPTBot, ClaudeBot) extraient du contenu pour entraîner des LLM, sans nécessairement générer de trafic de retour. Les crawlers de recherche (Googlebot) indexent du contenu pour la visibilité dans la recherche et envoient généralement du trafic de référencement. Les crawlers IA opèrent de manière plus agressive, avec des requêtes en lots plus importantes et ignorent souvent les consignes d’économie de bande passante.
Des exemples concrets montrent plus de 30 To par mois pour un seul crawler. La consommation dépend de la taille du site, du volume de contenu et de la fréquence des crawlers. GPTBot d’OpenAI a généré à lui seul 569 millions de requêtes en un mois sur le réseau de Vercel.
Bloquer les crawlers d’entraînement IA (GPTBot, ClaudeBot) n’affectera pas le classement Google. Cependant, bloquer les crawlers de recherche IA peut réduire la visibilité dans les résultats de recherche alimentés par l’IA, comme Perplexity ou la recherche ChatGPT.
Surveillez les pics inexpliqués de CPU (300 %+), l’augmentation de la bande passante sans plus de visiteurs humains, le ralentissement du chargement des pages et la présence de chaînes user-agent inhabituelles dans les logs serveur. Les métriques Core Web Vitals peuvent aussi se dégrader fortement.
Pour les sites subissant un trafic important de crawlers, l’hébergement dédié offre une meilleure isolation des ressources, plus de contrôle et une prévisibilité des coûts. L’hébergement mutualisé souffre du « syndrome du voisin bruyant » : le trafic crawler d’un site affecte tous les autres sites hébergés.
Utilisez Google Search Console pour les données Googlebot, les logs d’accès serveur pour une analyse détaillée, les outils d’analytique CDN (Cloudflare), et des plateformes spécialisées comme AmICited.com pour un suivi complet des crawlers IA.
Oui, via les directives robots.txt, les règles WAF et le filtrage IP. Vous pouvez autoriser les crawlers utiles comme Googlebot et bloquer les crawlers IA d’entraînement gourmands en ressources via des règles spécifiques user-agent.
Comparez les métriques serveur avant et après la mise en place de contrôles des crawlers. Surveillez les Core Web Vitals (LCP, TTFB), les temps de chargement, l’utilisation CPU et les métriques d’expérience utilisateur. Des outils comme Google PageSpeed Insights et des plateformes de monitoring serveur fournissent des analyses détaillées.
Obtenez des analyses en temps réel sur la manière dont les modèles IA accèdent à votre contenu et impactent vos ressources serveur grâce à la plateforme de suivi spécialisée d’AmICited.
Découvrez comment prendre des décisions stratégiques concernant le blocage des crawlers IA. Évaluez le type de contenu, les sources de trafic, les modèles de re...

Comprenez comment fonctionnent les crawlers IA comme GPTBot et ClaudeBot, leurs différences avec les crawlers de recherche traditionnels, et comment optimiser v...

Découvrez quels crawlers IA autoriser ou bloquer dans votre robots.txt. Guide complet couvrant GPTBot, ClaudeBot, PerplexityBot et plus de 25 crawlers IA avec e...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.