Le guide complet pour bloquer (ou autoriser) les crawlers IA
Apprenez à bloquer ou autoriser les crawlers IA comme GPTBot et ClaudeBot grâce à robots.txt, au blocage serveur et à des méthodes de protection avancées. Guide technique complet avec exemples.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
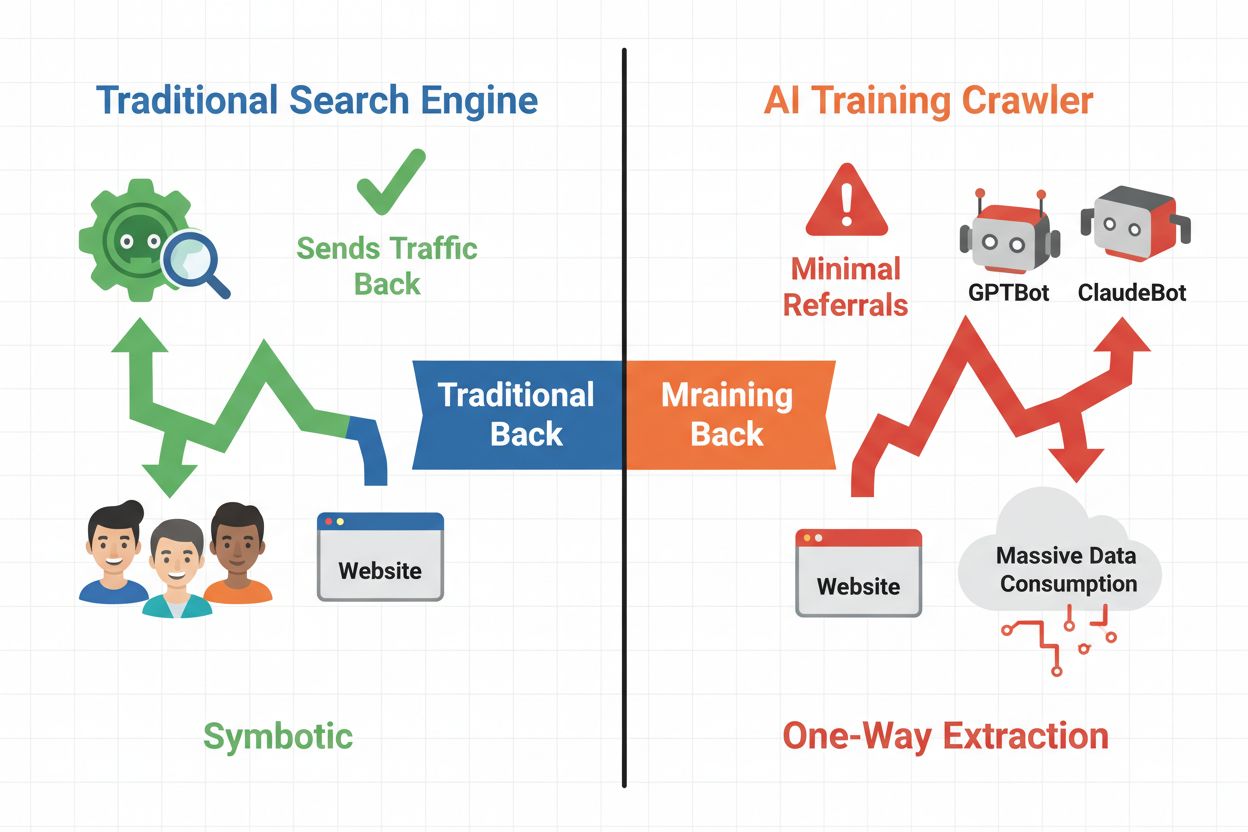
Le paysage numérique a fondamentalement évolué du référencement traditionnel vers la gestion d’une toute nouvelle catégorie de visiteurs automatisés : les crawlers IA. Contrairement aux bots de recherche classiques qui ramènent du trafic vers votre site via les résultats de recherche, les crawlers d’entraînement IA consomment votre contenu pour construire de grands modèles de langage sans nécessairement vous renvoyer du trafic référent. Cette distinction a des conséquences majeures pour les éditeurs, créateurs de contenu et entreprises qui dépendent du trafic web comme source de revenus. L’enjeu est de taille : contrôler quels systèmes IA accèdent à votre contenu impacte directement votre avantage concurrentiel, la confidentialité de vos données et vos résultats financiers.
Comprendre les types de crawlers IA
Les crawlers IA se répartissent en trois catégories distinctes, chacune ayant des objectifs et des impacts sur le trafic différents. Les crawlers d’entraînement sont utilisés par les entreprises IA pour construire et améliorer leurs modèles de langage, opérant généralement à grande échelle avec un trafic référent minimal. Les crawlers de recherche et de citation indexent le contenu pour les moteurs de recherche et systèmes de citation IA, générant souvent un certain trafic référent vers les éditeurs. Les crawlers déclenchés par l’utilisateur récupèrent le contenu à la demande lorsque les utilisateurs interagissent avec des applications IA, représentant un segment plus petit mais en croissance. Comprendre ces catégories vous aide à prendre des décisions éclairées sur les crawlers à autoriser ou à bloquer selon votre modèle économique.
L’écosystème des crawlers IA inclut les robots des plus grandes entreprises technologiques mondiales, chacun avec des agents utilisateur et des objectifs distincts. Le GPTBot d’OpenAI (user agent : GPTBot/1.0) crawle pour entraîner ChatGPT et d’autres modèles, tandis que le ClaudeBot d’Anthropic (user agent : Claude-Web/1.0) remplit un rôle similaire pour Claude. Le Googlebot-Extended de Google (user agent : Mozilla/5.0 ... Googlebot-Extended) indexe le contenu pour AI Overviews et Bard, alors que le Meta-ExternalFetcher de Meta crawle pour leurs initiatives IA. D’autres acteurs majeurs incluent :
Bytespider (ByteDance) - L’un des crawlers les plus agressifs, utilisé pour entraîner des modèles IA chinois
Amazonbot (Amazon) - Crawl pour Alexa et les services IA d’AWS
Applebot-Extended (Apple) - Indexe le contenu pour Siri et les fonctionnalités Apple Intelligence
Perplexity Bot - Crawler pour leur moteur de recherche IA (connu pour ignorer robots.txt)
CCBot (Common Crawl) - Construit des jeux de données ouverts utilisés par de nombreuses entreprises IA
Chaque crawler agit à des échelles différentes et respecte les directives de blocage de manière plus ou moins rigoureuse.
Comment bloquer les crawlers IA avec robots.txt
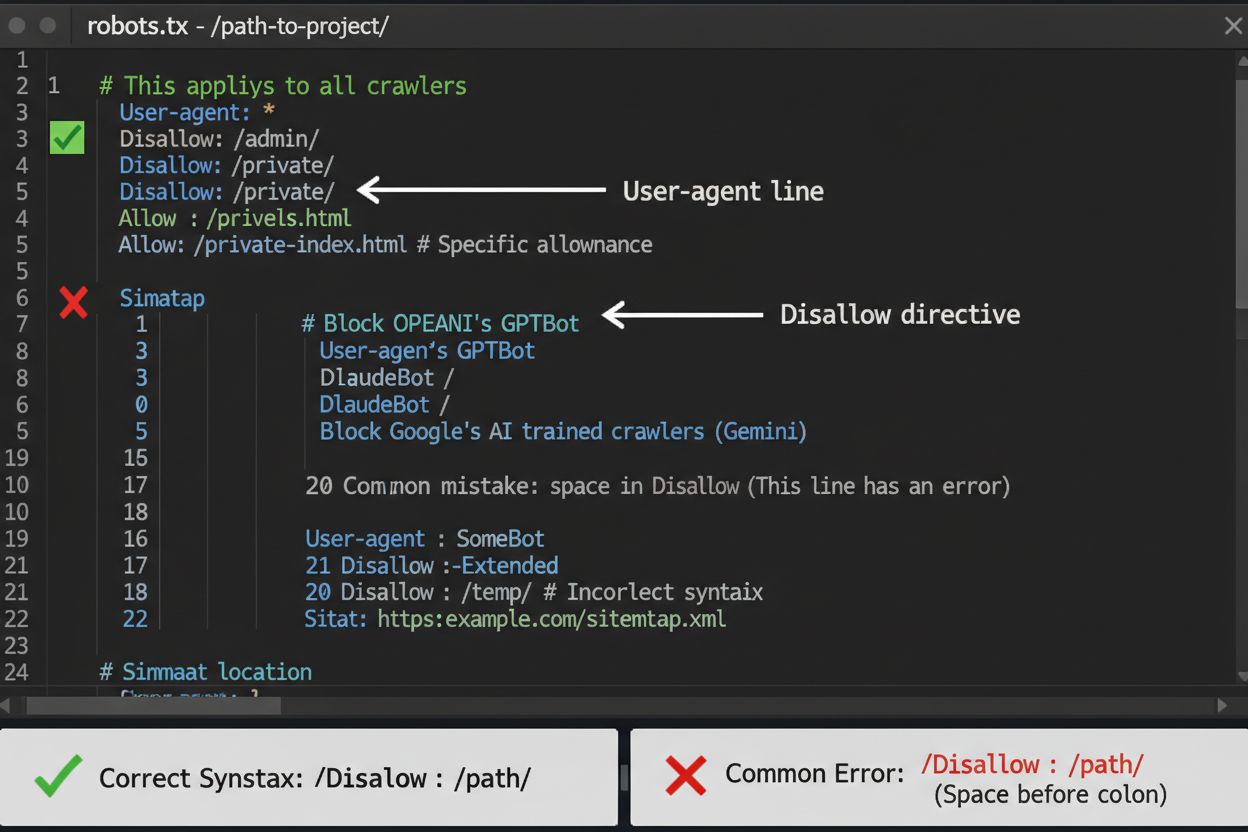
Le fichier robots.txt est votre première ligne de défense pour contrôler l’accès des crawlers IA, bien qu’il soit important de comprendre qu’il est indicatif et non juridiquement contraignant. Placé à la racine de votre domaine (par exemple, votresite.com/robots.txt), ce fichier utilise une syntaxe simple pour indiquer aux crawlers les zones à éviter. Pour bloquer tous les crawlers IA de façon globale, ajoutez les règles suivantes :
Une erreur fréquente consiste à utiliser des règles trop larges comme Disallow: * qui peuvent perturber les parsers, ou à oublier de spécifier les crawlers individuels lorsque vous ne souhaitez en bloquer que certains. Les grandes entreprises comme OpenAI, Anthropic et Google respectent généralement les directives de robots.txt, bien que certains crawlers comme Perplexity aient été documentés pour ignorer totalement ces règles.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Au-delà de robots.txt – méthodes de protection renforcées
Lorsque robots.txt ne suffit pas, plusieurs méthodes de protection plus robustes offrent un contrôle supplémentaire sur l’accès des crawlers IA. Le blocage basé sur les IP consiste à identifier les plages d’adresses IP des crawlers IA et à les bloquer au niveau du pare-feu ou du serveur—c’est très efficace mais nécessite une maintenance régulière car les plages d’IP changent. Le blocage serveur via des fichiers .htaccess (Apache) ou la configuration Nginx apporte un contrôle plus fin et est plus difficile à contourner que robots.txt. Pour les serveurs Apache, appliquez cette règle de blocage :
Le blocage par meta tag utilisant <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> empêche l’indexation mais n’arrête pas les crawlers d’entraînement. La vérification des en-têtes de requête permet de s’assurer que les crawlers proviennent bien de leur source déclarée via la vérification du reverse DNS et des certificats SSL. Utilisez le blocage au niveau serveur si vous voulez une certitude absolue que les crawlers n’accéderont pas à votre contenu, et combinez plusieurs méthodes pour une protection maximale.
Le choix stratégique – Bloquer ou autoriser
Décider de bloquer ou non les crawlers IA nécessite de mettre en balance plusieurs intérêts contradictoires. Bloquer les crawlers d’entraînement (GPTBot, ClaudeBot, Bytespider) empêche que votre contenu soit utilisé pour entraîner des modèles IA, protégeant ainsi votre propriété intellectuelle et votre avantage concurrentiel. Toutefois, autoriser les crawlers de recherche (Googlebot-Extended, Perplexity) peut générer du trafic référent et accroître la visibilité dans les résultats de recherche IA—un canal de découverte en pleine expansion. Le compromis est plus complexe quand on considère que certaines entreprises IA ont un ratio crawl/référent très faible : les crawlers d’Anthropic génèrent environ 38 000 requêtes pour chaque visite référente, tandis que le ratio d’OpenAI est d’environ 400:1. La charge serveur et la bande passante sont un autre facteur—les crawlers IA consomment beaucoup de ressources, et leur blocage peut réduire les coûts d’infrastructure. Votre décision doit être alignée sur votre modèle d’affaires : les médias et éditeurs peuvent bénéficier du trafic référent, tandis que les entreprises SaaS et créateurs de contenu propriétaire préfèrent généralement bloquer.
Surveillance et vérification
Mettre en place des blocages de crawlers n’est que la moitié du travail—vous devez vérifier que les crawlers respectent réellement vos directives. L’analyse des logs serveur est votre principal outil de vérification ; examinez vos logs d’accès pour repérer les agents utilisateur et adresses IP des crawlers qui tentent d’accéder à votre site après le blocage. Utilisez grep pour rechercher dans vos logs :
Cette commande compte combien de fois ces crawlers ont accédé à votre site. Les outils de test comme curl peuvent simuler les requêtes des crawlers pour vérifier que vos règles de blocage fonctionnent correctement :
curl -A "GPTBot/1.0" https://votresite.com/robots.txt
Surveillez vos logs chaque semaine le premier mois après la mise en place des blocages, puis chaque trimestre par la suite. Si vous détectez des crawlers qui ignorent votre robots.txt, passez au blocage serveur ou contactez l’équipe d’abus du crawler concerné.
Garder votre liste de blocage à jour
Le paysage des crawlers IA évolue rapidement au fil des lancements de nouveaux produits IA et des changements de chaînes d’agent utilisateur et de plages IP. Des révisions trimestrielles de votre liste de blocage garantissent que vous ne manquez pas de nouveaux crawlers ou que vous ne bloquez pas accidentellement du trafic légitime. L’écosystème des crawlers est fragmenté et décentralisé, rendant impossible une liste de blocage vraiment permanente. Surveillez ces ressources pour rester à jour :
La documentation officielle d’OpenAI pour les changements de GPTBot
Les communications publiques d’Anthropic sur le comportement de ClaudeBot
Les forums communautaires et discussions Reddit où les développeurs partagent les nouveaux crawlers découverts
Vos propres logs serveur pour les agents utilisateur inconnus pouvant être de nouveaux crawlers IA
Les publications spécialisées et blogs de sécurité qui suivent l’activité émergente des crawlers IA
Programmez des rappels pour revoir votre robots.txt et vos règles serveur tous les 90 jours, et abonnez-vous à des listes de diffusion sécurité qui suivent les nouveaux déploiements de crawlers.
Comment AmICited aide à surveiller les références IA
Si bloquer les crawlers IA les empêche d’accéder à votre contenu, AmICited répond au défi complémentaire : surveiller si les systèmes IA citent et référencent votre marque et votre contenu dans leurs résultats. AmICited suit les mentions de votre organisation dans les réponses générées par l’IA, vous donnant une visibilité sur l’influence de votre contenu sur les modèles IA et l’apparition de votre marque dans les résultats de recherche IA. Cela crée une stratégie IA complète : vous contrôlez ce que les crawlers peuvent accéder via robots.txt et le blocage serveur, tandis qu’AmICited vous assure de comprendre l’impact en aval de votre contenu sur les systèmes IA. Ensemble, ces outils vous donnent une visibilité et un contrôle total sur votre présence dans l’écosystème IA—de la prévention de l’utilisation non désirée de vos données pour l’entraînement à la mesure des citations et références générées par votre contenu sur les plateformes IA.
Questions fréquemment posées
Bloquer les bots IA nuit-il à mon référencement SEO ?
Non. Bloquer les crawlers IA d'entraînement comme GPTBot, ClaudeBot et Bytespider n'affecte pas votre classement Google ou Bing. Les moteurs de recherche traditionnels utilisent des crawlers différents (Googlebot, Bingbot) qui fonctionnent indépendamment. Ne bloquez ceux-ci que si vous souhaitez disparaître complètement des résultats de recherche.
Quels bots IA respectent réellement robots.txt ?
Les principaux crawlers d'OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) et Perplexity (PerplexityBot) déclarent officiellement respecter les directives robots.txt. Cependant, des bots plus petits ou moins transparents peuvent ignorer votre configuration, d'où l'existence de stratégies de protection en couches.
Dois-je bloquer tous les crawlers IA ou seulement ceux d'entraînement ?
Cela dépend de votre stratégie. Bloquer uniquement les crawlers d'entraînement (GPTBot, ClaudeBot, Bytespider) protège votre contenu de l'entraînement des modèles tout en permettant aux crawlers axés sur la recherche de vous aider à apparaître dans les résultats de recherche IA. Le blocage total vous retire complètement des écosystèmes IA.
À quelle fréquence dois-je mettre à jour mon robots.txt pour les nouveaux bots IA ?
Examinez votre configuration au moins chaque trimestre. Les entreprises IA introduisent régulièrement de nouveaux crawlers. Anthropic a fusionné ses bots 'anthropic-ai' et 'Claude-Web' en 'ClaudeBot', donnant temporairement un accès non restreint au nouveau bot sur les sites qui n'avaient pas mis à jour leurs règles.
Quelle est la différence entre bloquer et autoriser les crawlers IA ?
Le blocage empêche complètement les crawlers d'accéder à votre contenu, le protégeant de la collecte pour l'entraînement ou l'indexation. L'autorisation donne l'accès mais peut entraîner l'utilisation de votre contenu pour l'entraînement des modèles ou son apparition dans les résultats de recherche IA avec peu de trafic référent.
Les crawlers IA peuvent-ils contourner les directives robots.txt ?
Oui, robots.txt est indicatif plutôt que juridiquement contraignant. Les crawlers bienveillants des grandes entreprises respectent généralement les directives robots.txt, mais certains crawlers les ignorent. Pour une protection renforcée, appliquez un blocage serveur via .htaccess ou des règles de pare-feu.
Comment savoir si mon robots.txt fonctionne ?
Vérifiez les journaux de votre serveur pour les chaînes d'agent utilisateur des crawlers bloqués. Si vous voyez des requêtes de crawlers que vous avez bloqués, ils ne respectent peut-être pas robots.txt. Utilisez des outils de test comme le testeur robots.txt de Google Search Console ou des commandes curl pour vérifier votre configuration.
Quel est l'impact sur le trafic de mon site si je bloque les crawlers IA ?
Le blocage des crawlers d'entraînement a généralement un impact direct minimal sur le trafic puisqu'ils génèrent peu de trafic référent. Cependant, bloquer les crawlers de recherche peut réduire la visibilité surles plateformes de découverte alimentées par l'IA. Surveillez vos analyses pendant 30 jours après la mise en place des blocages pour mesurer l'impact réel.
Surveillez comment les systèmes IA référencent votre marque
Bien que vous contrôliez l'accès des crawlers avec robots.txt, AmICited vous aide à suivre comment les systèmes IA citent et référencent votre contenu dans leurs résultats. Obtenez une visibilité complète sur votre présence dans l'IA.
Fiche de Référence des Crawlers IA : Tous les Bots en un Coup d’Œil
Guide complet de référence des crawlers IA et bots. Identifiez GPTBot, ClaudeBot, Google-Extended et plus de 20 autres crawlers IA avec leurs user agents, fréqu...
Comment identifier les crawlers IA dans les logs serveur : Guide complet de détection
Découvrez comment identifier et surveiller les crawlers IA comme GPTBot, PerplexityBot et ClaudeBot dans vos logs serveur. Découvrez les chaînes user-agent, les...
Comment identifier les crawlers IA dans vos journaux de serveur
Apprenez à identifier et surveiller les crawlers IA comme GPTBot, ClaudeBot et PerplexityBot dans vos journaux de serveur. Guide complet avec chaînes user-agent...
10 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.