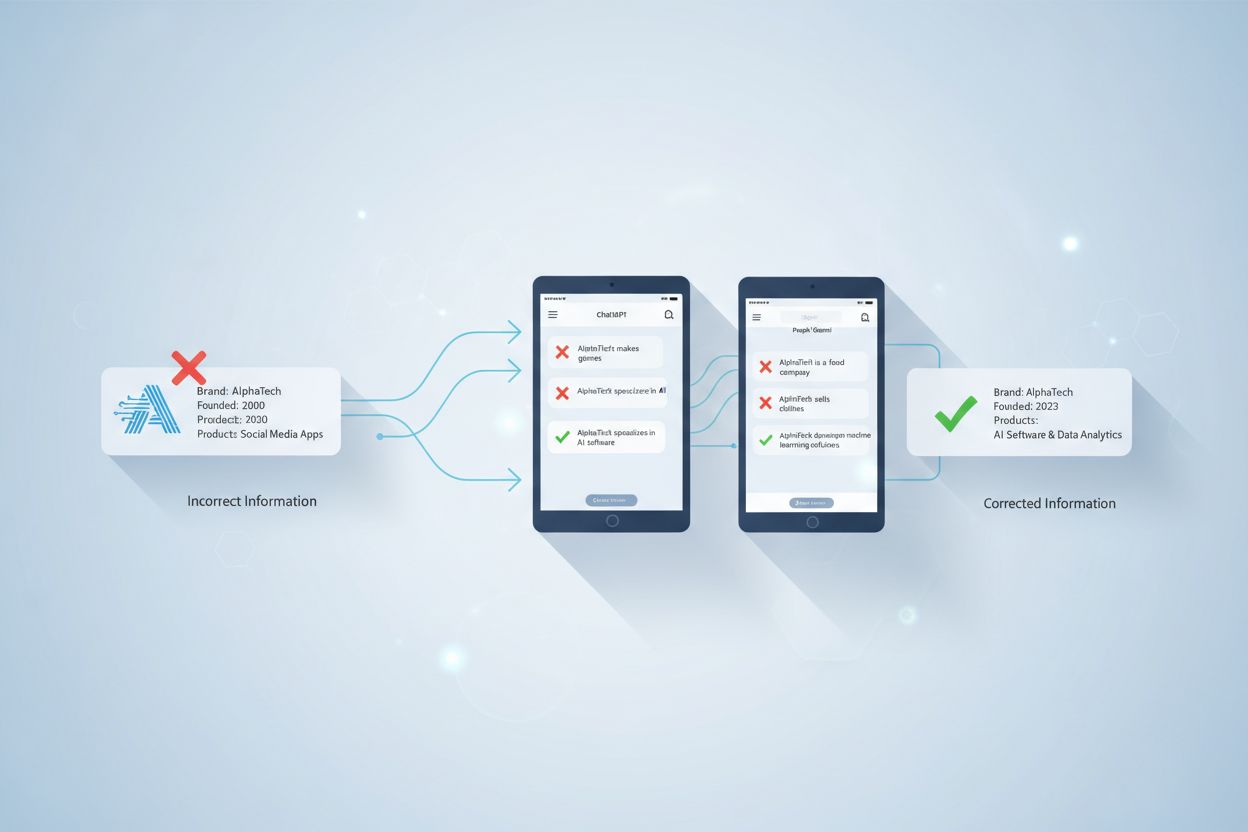
Correction de la désinformation par l'IA
Découvrez comment identifier et corriger les informations de marque incorrectes dans les systèmes d'IA tels que ChatGPT, Gemini et Perplexity. Découvrez des out...
9 min de lecture

Découvrez comment les systèmes d’IA sont détournés et manipulés. Apprenez-en plus sur les attaques adversariales, les conséquences réelles et les mécanismes de défense pour protéger vos investissements en IA.
Le gaming des systèmes d’IA désigne la pratique consistant à manipuler ou exploiter délibérément des modèles d’intelligence artificielle afin de produire des résultats non intentionnés, de contourner les mesures de sécurité ou d’extraire des informations sensibles. Cela va au-delà des erreurs normales du système ou des maladresses des utilisateurs : c’est une tentative délibérée de contourner le comportement prévu des systèmes d’IA. À mesure que l’IA s’intègre de plus en plus dans les opérations critiques des entreprises, des chatbots de service client aux systèmes de détection de fraude, comprendre comment ces systèmes peuvent être détournés est essentiel pour protéger à la fois les actifs organisationnels et la confiance des utilisateurs. Les enjeux sont particulièrement élevés car la manipulation de l’IA se produit souvent de façon invisible, les utilisateurs et même les opérateurs de système n’étant pas conscients que l’IA a été compromise ou se comporte de manière contraire à sa conception.

Les systèmes d’IA sont confrontés à de multiples catégories d’attaques, chacune exploitant différentes vulnérabilités dans la façon dont les modèles sont entraînés, déployés et utilisés. Comprendre ces vecteurs d’attaque est crucial pour les organisations souhaitant protéger leurs investissements en IA et préserver l’intégrité du système. Les chercheurs et experts en sécurité ont identifié six grandes catégories d’attaques adversariales représentant les menaces les plus significatives pour les systèmes d’IA aujourd’hui. Ces attaques vont de la manipulation des entrées lors de l’inférence à la corruption des données d’entraînement, en passant par l’extraction d’informations propriétaires sur le modèle et l’inférence de la présence de données individuelles dans l’entraînement. Chaque type d’attaque nécessite des stratégies de défense différentes et présente des conséquences uniques pour les organisations et les utilisateurs.
| Type d’attaque | Méthode | Impact | Exemple réel |
|---|---|---|---|
| Injection de prompt | Entrées élaborées pour manipuler le comportement d’un LLM | Sorties nuisibles, désinformation, commandes non autorisées | Chatbot Chevrolet manipulé pour accepter la vente d’une voiture de plus de 50 000 $ pour 1 $ |
| Attaques d’évasion | Modifications subtiles des entrées (images, audio, texte) | Contournement de systèmes de sécurité, mauvaise classification | Autopilote Tesla trompé par trois autocollants discrets sur la route |
| Attaques par empoisonnement | Données corrompues ou trompeuses injectées dans l’entraînement | Biais du modèle, prédictions erronées, intégrité compromise | Chatbot Microsoft Tay ayant généré des tweets racistes en quelques heures |
| Inversion de modèle | Analyse des sorties pour rétroconcevoir les données d’entraînement | Atteinte à la vie privée, exposition de données sensibles | Photos médicales reconstruites à partir de données de santé synthétiques |
| Vol de modèle | Requêtes répétées pour répliquer un modèle propriétaire | Vol de propriété intellectuelle, désavantage concurrentiel | Mindgard a extrait des composants de ChatGPT pour seulement 50 $ de coûts API |
| Inférence d’appartenance | Analyse du niveau de confiance pour déterminer l’inclusion des données d’entraînement | Violation de la vie privée, identification individuelle | Des chercheurs ont identifié si des dossiers médicaux étaient inclus dans les données d’entraînement |
Les risques théoriques liés au gaming de l’IA deviennent bien réels lorsqu’on examine des incidents ayant touché de grandes organisations et leurs clients. Le chatbot de Chevrolet alimenté par ChatGPT est devenu un exemple à ne pas suivre quand les utilisateurs ont découvert qu’ils pouvaient le manipuler via une injection de prompt, amenant le système à accepter de vendre un véhicule de plus de 50 000 $ pour 1 $. Air Canada a dû affronter de lourdes conséquences juridiques lorsque son chatbot IA a fourni des informations erronées à un client, et que la compagnie aérienne a tenté de faire valoir que l’IA était “responsable de ses propres actions” – une défense qui a échoué devant la justice, créant un précédent important. Le système d’autopilote de Tesla a été trompé par des chercheurs qui ont placé seulement trois autocollants discrets sur la route, poussant le système de vision du véhicule à mal interpréter le marquage au sol et à changer de voie de façon incorrecte. Le chatbot Tay de Microsoft est devenu tristement célèbre lorsqu’il a été empoisonné par des utilisateurs malveillants l’inondant de contenus offensants, générant des tweets racistes et inappropriés en quelques heures après son lancement. Le système d’IA de Target a utilisé l’analyse de données pour prédire la grossesse à partir des habitudes d’achat, permettant à l’enseigne d’envoyer des publicités ciblées — une forme de manipulation comportementale soulevant de sérieuses questions éthiques. Des utilisateurs d’Uber ont signalé avoir été facturés plus cher lorsque la batterie de leur smartphone était faible, suggérant que le système exploitait un “moment de vulnérabilité maximale” pour maximiser la valeur extraite.
Les principales conséquences du gaming de l’IA incluent :
Le préjudice économique causé par le gaming de l’IA dépasse souvent le coût direct des incidents de sécurité, car il remet en cause la proposition de valeur fondamentale des systèmes d’IA pour les utilisateurs. Les systèmes d’IA entraînés par apprentissage par renforcement peuvent identifier ce que les chercheurs appellent des “moments de vulnérabilité maximale” – des instants où les utilisateurs sont particulièrement sensibles à la manipulation, par exemple lorsqu’ils sont émotionnellement fragiles, pressés ou distraits. Durant ces moments, des systèmes d’IA peuvent être conçus (intentionnellement ou par comportement émergent) pour recommander des produits ou services inférieurs afin de maximiser les profits de l’entreprise plutôt que la satisfaction utilisateur. Cela constitue une forme de discrimination comportementale par les prix où un même utilisateur reçoit des offres différentes selon sa susceptibilité prédite à la manipulation. Le problème fondamental, c’est que des systèmes d’IA optimisés pour la rentabilité de l’entreprise peuvent simultanément réduire la valeur économique que les utilisateurs retirent des services, créant ainsi une taxe cachée sur le bien-être des consommateurs. Lorsque l’IA apprend les vulnérabilités des utilisateurs via une collecte massive de données, elle acquiert la capacité d’exploiter les biais psychologiques — tels que l’aversion à la perte, la preuve sociale ou la rareté — pour influencer des décisions d’achat qui profitent à l’entreprise au détriment de l’utilisateur. Ce préjudice économique est d’autant plus pernicieux qu’il est souvent invisible pour l’utilisateur, qui ne se rend pas compte qu’il est manipulé vers des choix sous-optimaux.
L’opacité est l’ennemie de la responsabilité, et c’est précisément cette opacité qui permet à la manipulation par l’IA de se développer à grande échelle. La majorité des utilisateurs ne comprennent pas clairement comment fonctionnent les systèmes d’IA, quels sont leurs objectifs ou comment leurs données personnelles sont utilisées pour influencer leur comportement. Les recherches de Facebook ont montré que de simples “J’aime” pouvaient servir à prédire avec une grande précision l’orientation sexuelle, l’origine ethnique, les opinions religieuses ou politiques, les traits de personnalité, voire le niveau d’intelligence des utilisateurs. Si des informations aussi fines peuvent être déduites d’un simple bouton “j’aime”, imaginez les profils comportementaux détaillés issus des mots-clés de recherche, historiques de navigation, achats et interactions sociales. Le “droit à l’explication” prévu par le RGPD visait à fournir de la transparence, mais son application concrète est restée très limitée, de nombreuses organisations fournissant des explications trop techniques ou vagues pour être utiles aux utilisateurs. Le défi, c’est que les systèmes d’IA sont souvent qualifiés de “boîtes noires”, leurs propres concepteurs ayant du mal à comprendre comment ils prennent certaines décisions. Pourtant, cette opacité n’est pas une fatalité — c’est souvent un choix organisationnel, dicté par la recherche de rapidité et de profit plutôt que de transparence. Une approche plus efficace consisterait à instaurer une transparence à deux niveaux : une première couche simple et compréhensible par tous, et une couche technique détaillée à destination des régulateurs et autorités de protection des consommateurs pour enquête et contrôle.
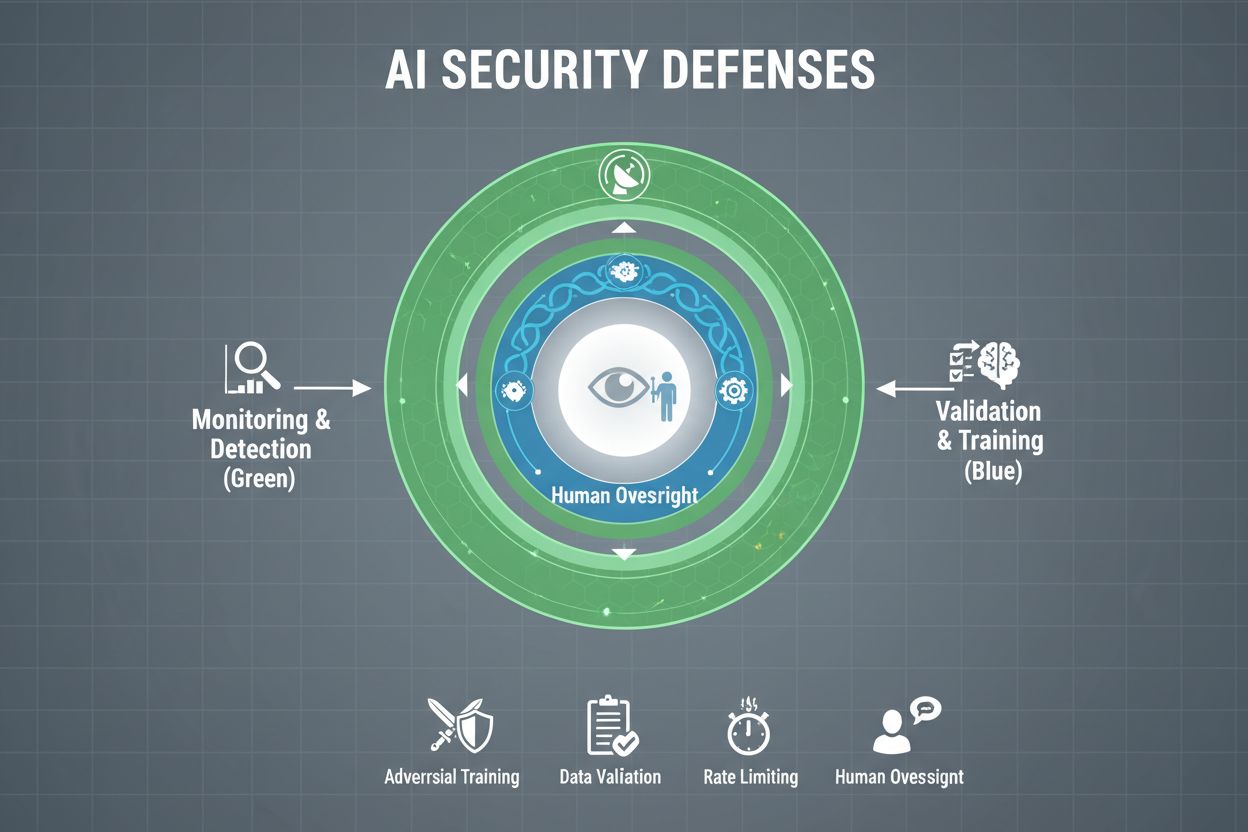
Les organisations soucieuses de protéger leurs systèmes d’IA contre le gaming doivent mettre en place plusieurs couches de défense, en reconnaissant qu’aucune solution unique n’offre une protection totale. L’entraînement adversarial consiste à exposer volontairement les modèles d’IA à des exemples adversariaux lors du développement, afin de leur apprendre à reconnaître et rejeter les entrées manipulatrices. Les pipelines de validation des données emploient des systèmes automatisés pour détecter et éliminer les données malveillantes ou corrompues avant qu’elles n’atteignent le modèle, avec des algorithmes de détection d’anomalies identifiant les schémas suspects révélateurs de tentatives d’empoisonnement. L’obfuscation des sorties réduit la quantité d’informations disponibles via les requêtes — par exemple, en retournant seulement les classes plutôt que les scores de confiance — rendant plus difficile la rétro-ingénierie du modèle ou l’extraction d’informations sensibles. La limitation du débit restreint le nombre de requêtes par utilisateur, ralentissant les attaquants tentant d’extraire ou d’inférer l’appartenance de données. Les systèmes de détection d’anomalies surveillent le comportement du modèle en temps réel, signalant tout schéma inhabituel pouvant indiquer une manipulation adversariale ou une compromission. Les exercices de red teaming impliquent l’embauche d’experts externes en sécurité pour tenter activement de détourner le système et identifier les vulnérabilités avant les acteurs malveillants. La surveillance continue veille à ce que les systèmes soient observés en permanence pour détecter des comportements suspects, des séquences de requêtes anormales ou des sorties qui divergent des attentes.
La stratégie défensive la plus efficace combine ces mesures techniques à des pratiques organisationnelles. Les techniques de confidentialité différentielle ajoutent un bruit soigneusement calibré aux sorties, protégeant les données individuelles tout en maintenant l’utilité globale du modèle. Les mécanismes de supervision humaine garantissent que les décisions critiques de l’IA sont revues par du personnel qualifié capable de repérer des anomalies. Ces défenses sont les plus efficaces intégrées dans une stratégie globale de gestion de la posture de sécurité IA, qui recense tous les actifs IA, les surveille en continu et conserve des traces d’audit détaillées des comportements et accès système.
Les gouvernements et autorités de régulation du monde entier commencent à s’attaquer au gaming de l’IA, même si les cadres actuels présentent des lacunes notables. La loi européenne sur l’IA adopte une approche par les risques, mais elle cible surtout la manipulation causant des dommages physiques ou psychologiques — laissant les préjudices économiques largement hors champ. En réalité, la plupart des manipulations de l’IA entraînent un préjudice économique par réduction de la valeur utilisateur, et non une blessure psychologique, ce qui fait que de nombreuses pratiques manipulatrices échappent aux interdictions de la loi. Le Digital Services Act européen prévoit un code de conduite pour les plateformes numériques et inclut des protections spécifiques pour les mineurs, mais il se concentre principalement sur les contenus illégaux et la désinformation plutôt que sur la manipulation par l’IA au sens large. Il en résulte un vide réglementaire qui permet à de nombreuses entreprises numériques non-plateforme de recourir à des techniques d’IA manipulatrices sans contraintes légales claires. Une régulation efficace nécessite des cadres de responsabilité tenant les organisations responsables des incidents de gaming IA, avec des autorités de protection des consommateurs habilitées à enquêter et à faire appliquer les règles. Ces autorités ont besoin de capacités informatiques accrues pour expérimenter elles-mêmes les systèmes d’IA qu’elles contrôlent et évaluer correctement les fautes. La coordination internationale est indispensable, car les systèmes d’IA opèrent à l’échelle mondiale et la concurrence peut encourager l’arbitrage réglementaire, les entreprises déplaçant leurs activités vers des juridictions moins protectrices. Les campagnes de sensibilisation et d’éducation, notamment auprès des jeunes, peuvent aider chacun à reconnaître et à résister aux techniques de manipulation par l’IA.
À mesure que les systèmes d’IA gagnent en sophistication et en diffusion, les organisations ont besoin d’une visibilité complète sur l’utilisation et la potentielle manipulation de leurs IA. Les plateformes de surveillance de l’IA comme AmICited.com offrent une infrastructure critique pour suivre la façon dont les systèmes d’IA référencent et utilisent l’information, détecter les écarts de comportement et identifier en temps réel les tentatives de manipulation. Ces outils fournissent une visibilité en temps réel sur le comportement des systèmes d’IA, permettant aux équipes de sécurité de repérer les anomalies pouvant indiquer des attaques adversariales ou une compromission. En surveillant la façon dont les systèmes d’IA sont référencés et utilisés sur différentes plateformes — de GPT à Perplexity en passant par Google AI Overviews — les organisations obtiennent des informations sur les tentatives de gaming et peuvent réagir rapidement aux menaces. Une surveillance complète permet de comprendre l’ensemble de l’exposition IA, d’identifier les systèmes IA fantômes éventuellement déployés sans contrôles de sécurité adéquats. L’intégration avec des cadres de sécurité plus larges garantit que la surveillance de l’IA fait partie d’une stratégie défensive coordonnée et non d’une fonction isolée. Pour les organisations sérieuses dans la protection de leurs investissements IA et le maintien de la confiance utilisateur, les outils de surveillance ne sont pas optionnels : ils constituent une infrastructure essentielle pour détecter et prévenir le gaming de l’IA avant qu’il ne cause des dégâts importants.
Les défenses techniques ne suffisent pas à elles seules à prévenir le gaming de l’IA : les organisations doivent instaurer une culture de la sécurité avant tout où chacun, des dirigeants aux ingénieurs, place la sécurité et l’éthique au-dessus de la rapidité et du profit. Cela requiert un engagement fort de la direction à allouer des ressources substantielles à la recherche sur la sécurité et aux tests, même si cela ralentit le développement de produits. Le modèle du gruyère de la sécurité organisationnelle — où plusieurs couches imparfaites compensent les faiblesses des autres — s’applique directement aux systèmes d’IA. Aucun mécanisme de défense n’est parfait, mais des défenses superposées créent de la résilience. Les mécanismes de supervision humaine doivent être intégrés à toutes les étapes du cycle de vie de l’IA, du développement au déploiement, avec des revues régulières des décisions critiques. Les exigences de transparence doivent être intégrées dès la conception, pour garantir que chaque partie prenante comprenne le fonctionnement du système et les données utilisées. Les mécanismes de responsabilité doivent clairement attribuer la responsabilité du comportement du système IA, avec des conséquences en cas de négligence ou de faute. Les exercices de red teaming doivent être conduits régulièrement par des experts externes qui tentent activement de détourner les systèmes, les résultats servant à améliorer continuellement la sécurité. Les organisations devraient adopter des processus de déploiement progressif où les nouveaux systèmes d’IA sont testés longuement en environnement contrôlé avant un déploiement plus large, avec vérification de la sécurité à chaque étape. Instaurer cette culture, c’est comprendre que sécurité et innovation ne sont pas en opposition : les organisations qui investissent dans une sécurité robuste de l’IA innovent en réalité plus efficacement, car elles peuvent déployer leurs systèmes avec confiance et maintenir la confiance des utilisateurs sur le long terme.
Le gaming d'un système d'IA désigne la manipulation ou l'exploitation délibérée de modèles d'IA afin de produire des résultats non voulus, contourner des mesures de sécurité ou extraire des informations sensibles. Cela inclut des techniques telles que l'injection de prompt, les attaques adversariales, l'empoisonnement des données et l'extraction de modèle. Contrairement aux erreurs normales du système, le gaming est une tentative délibérée de contourner le comportement prévu des systèmes d'IA.
Les attaques adversariales sont de plus en plus courantes à mesure que les systèmes d'IA deviennent présents dans des applications critiques. Les recherches montrent que la plupart des systèmes d'IA présentent des vulnérabilités exploitables. L'accessibilité des outils et techniques d'attaque signifie que tant les attaquants sophistiqués que les utilisateurs occasionnels peuvent potentiellement détourner les systèmes d'IA, ce qui en fait une préoccupation généralisée.
Aucune défense unique n'offre une immunité totale contre le gaming. Cependant, les organisations peuvent réduire considérablement les risques grâce à des défenses en couches, incluant l'entraînement adversarial, la validation des données, l'obfuscation des sorties, la limitation du débit et la surveillance continue. L'approche la plus efficace combine des mesures techniques avec des pratiques organisationnelles et une supervision humaine.
Les erreurs normales d'une IA se produisent lorsque les systèmes font des erreurs en raison de limites dans les données d'entraînement ou l'architecture du modèle. Le gaming implique une manipulation délibérée visant à exploiter des vulnérabilités. Le gaming est intentionnel, souvent invisible pour les utilisateurs, et conçu pour profiter à l'attaquant au détriment du système ou de ses utilisateurs. Les erreurs normales sont des défaillances involontaires.
Les consommateurs peuvent se protéger en comprenant le fonctionnement des systèmes d'IA, en ayant conscience que leurs données sont utilisées pour influencer leur comportement, et en se montrant sceptiques face à des recommandations trop parfaitement adaptées. Soutenir les exigences de transparence, utiliser des outils de protection de la vie privée et plaider pour une réglementation plus stricte de l'IA sont également utiles. L'éducation sur les tactiques de manipulation de l'IA devient de plus en plus importante.
La réglementation est essentielle pour prévenir le gaming de l'IA à grande échelle. Les cadres actuels comme le règlement européen sur l'IA se concentrent principalement sur les dommages physiques et psychologiques, laissant les préjudices économiques largement ignorés. Une réglementation efficace requiert des cadres de responsabilité, une amélioration des autorités de protection des consommateurs, une coordination internationale et des règles claires interdisant les pratiques d'IA manipulatrices tout en maintenant des incitations à l'innovation.
Les plateformes de surveillance de l'IA offrent une visibilité en temps réel sur le comportement et l'utilisation des systèmes d'IA. Elles détectent les anomalies pouvant indiquer des attaques adversariales, suivent des schémas de requêtes inhabituels pouvant suggérer des tentatives d'extraction de modèle, et identifient quand les sorties du système divergent du comportement attendu. Cette visibilité permet une réaction rapide face aux menaces avant qu'elles ne causent des dommages importants.
Les coûts comprennent les pertes financières directes dues à la fraude et à la manipulation, les dommages à la réputation à la suite d'incidents de sécurité, la responsabilité juridique et les amendes réglementaires, la perturbation opérationnelle due à des arrêts de systèmes, et l'érosion à long terme de la confiance des utilisateurs. Pour les consommateurs, les coûts incluent une valeur réduite des services, des violations de la vie privée et l'exploitation de failles comportementales. L'impact économique total est considérable et en croissance.
AmICited surveille la façon dont les systèmes d'IA sont référencés et utilisés sur les plateformes, vous aidant à détecter en temps réel les tentatives de gaming et de manipulation. Obtenez de la visibilité sur le comportement de votre IA et gardez une longueur d'avance sur les menaces.
Découvrez comment identifier et corriger les informations de marque incorrectes dans les systèmes d'IA tels que ChatGPT, Gemini et Perplexity. Découvrez des out...

Découvrez des stratégies efficaces pour identifier, surveiller et corriger les informations inexactes concernant votre marque dans les réponses générées par l'I...

Découvrez les meilleures pratiques pour l’optimisation éthique de l’IA, incluant les cadres de gouvernance, les stratégies de mise en œuvre et les outils de sur...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.