Comment les LLM choisissent quoi citer : comprendre la sélection des sources par l’IA
Découvrez comment les grands modèles de langage sélectionnent et citent les sources grâce à la pondération des preuves, la reconnaissance d’entités et les données structurées. Apprenez le processus de décision de citation en 7 phases et optimisez votre contenu pour la visibilité dans l’IA.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
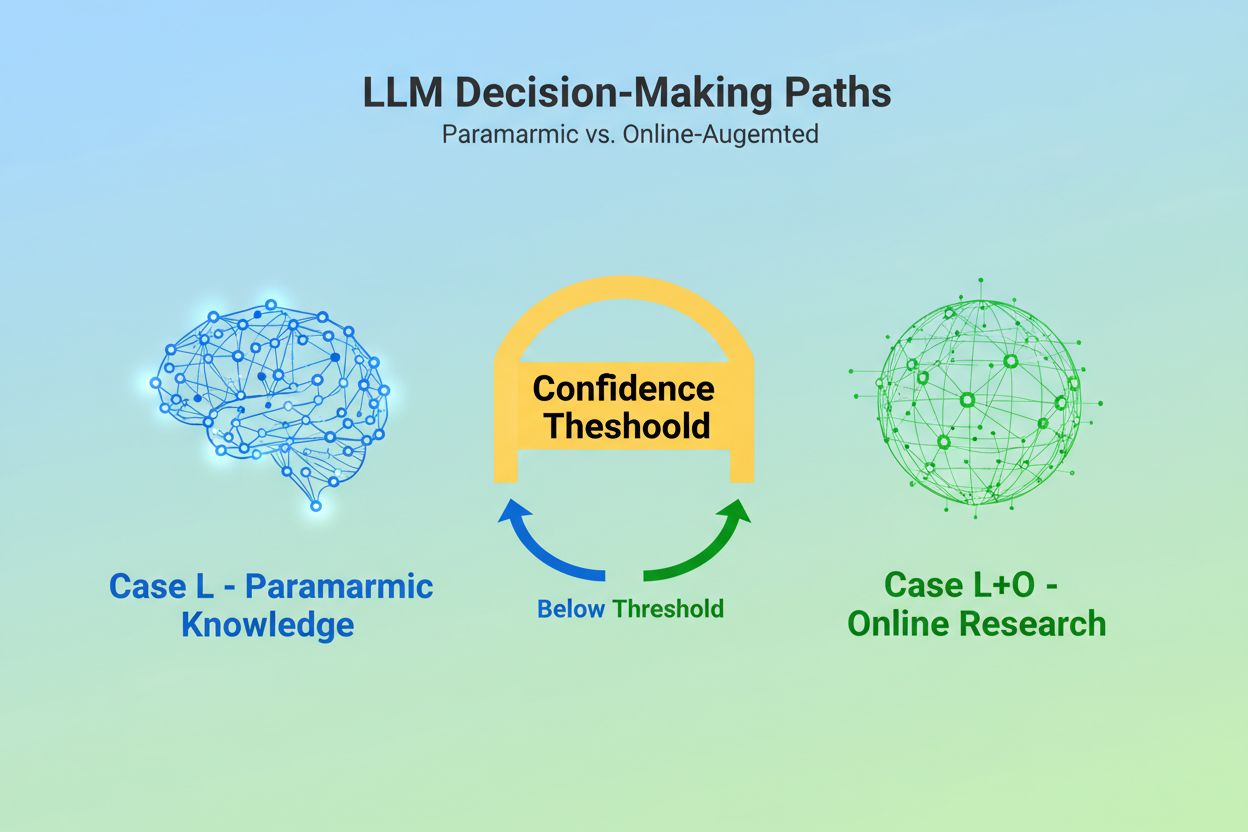
Lorsqu’un grand modèle de langage reçoit une requête, il doit prendre une décision fondamentale : doit-il s’appuyer uniquement sur les connaissances intégrées lors de l’entraînement, ou doit-il rechercher des informations à jour sur le web ? Ce choix binaire—ce que les chercheurs appellent Cas L (données d’apprentissage uniquement) contre Cas L+O (données d’apprentissage plus recherche en ligne)—détermine si un LLM va citer des sources ou non. En mode Cas L, le modèle puise exclusivement dans sa base de connaissances paramétrique, une représentation condensée des schémas appris lors de l’entraînement qui reflète généralement des informations datant de plusieurs mois à plus d’un an avant la sortie du modèle. En mode Cas L+O, le modèle active un seuil de confiance qui déclenche une recherche externe, ouvrant ce que les chercheurs appellent « l’espace candidat » d’URLs et de sources. Ce point de décision est invisible pour la plupart des outils de surveillance, mais c’est là que débute tout le mécanisme de citation—car sans déclencher la phase de recherche, aucune source externe ne peut être évaluée ou citée.
Comprendre la pondération des preuves
Dès qu’un LLM décide de rechercher des sources externes, il entre dans la phase la plus critique pour la sélection des citations : la pondération des preuves. C’est ici que se fait la différence entre une simple mention et une recommandation autoritaire. Le modèle ne compte pas simplement combien de fois une source apparaît ou son classement dans les résultats de recherche ; il évalue l’intégrité structurelle des preuves elles-mêmes. Il analyse l’architecture du document—si les sources contiennent des relations de données claires, des identifiants récurrents et des liens référencés—interprétant cela comme des signes de fiabilité. Le modèle construit ce que les chercheurs appellent un « graphe de preuves », où les nœuds représentent des entités et les arêtes les relations entre documents. Chaque source est pondérée non seulement pour la pertinence du contenu mais aussi selon la cohérence des faits confirmés dans plusieurs documents, la pertinence thématique de l’information, et le caractère autoritaire du domaine. Cette évaluation multidimensionnelle crée ce qu’on appelle une matrice de preuves, une évaluation complète qui détermine quelles sources sont suffisamment fiables pour être citées. Fait crucial, cette phase opère dans la couche de raisonnement du LLM, la rendant invisible aux outils GEO classiques qui ne mesurent que les signaux de récupération.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Les données structurées—en particulier le JSON-LD, le balisage Schema.org et le RDFa—agissent comme un multiplicateur dans le processus de pondération des preuves. Les sources qui mettent en place des données structurées appropriées reçoivent un poids 2 à 3 fois supérieur dans la matrice de preuves par rapport au contenu non structuré. Ce n’est pas parce que les LLM préfèrent l’esthétique des données formatées ; c’est parce que les données structurées permettent la liaison d’entités, le processus qui relie les mentions dans plusieurs documents via des identifiants lisibles par machine comme @id, sameAs et Q-IDs (identifiants Wikidata). Lorsqu’un LLM rencontre une source avec un Q-ID pour une organisation, il peut immédiatement vérifier cette entité dans plusieurs documents, créant ce que les chercheurs appellent la « coréférence inter-documents d’entités ». Ce processus de vérification augmente considérablement la confiance dans la fiabilité de la source.
Format de données
Précision de la citation
Liaison d’entités
Vérification inter-documents
Texte non structuré
62%
Aucune
Inférence manuelle
Balisage HTML de base
71%
Limitée
Correspondance partielle
RDFa/Microdata
81%
Bonne
Basée sur les schémas
JSON-LD avec Q-IDs
94%
Excellente
Liens vérifiés
Format graphe de connaissances
97%
Parfaite
Vérification automatique
L’impact des données structurées s’opère sur deux axes temporels. Transitoirement, lorsqu’un LLM recherche en ligne, il lit le JSON-LD et le balisage Schema.org en temps réel, intégrant immédiatement ces informations structurées dans la pondération des preuves pour la réponse en cours. De façon persistante, les données structurées qui restent cohérentes dans le temps sont intégrées à la base de connaissances paramétrique du modèle lors des futurs cycles d’entraînement, influençant la façon dont le modèle reconnaît et évalue les entités même sans recherche en ligne. Ce double mécanisme signifie que les marques mettant en place des données structurées appropriées obtiennent à la fois une visibilité de citation immédiate et une autorité à long terme dans l’espace de connaissance interne du modèle.
Reconnaissance et désambiguïsation des entités
Avant qu’un LLM puisse citer une source, il doit d’abord comprendre de quoi parle cette source et qui elle représente. C’est le travail de la reconnaissance d’entités, un processus qui transforme le langage humain flou en entités lisibles par machine. Lorsqu’un document mentionne « Apple », le LLM doit déterminer s’il s’agit d’Apple Inc., du fruit ou d’autre chose. Le modèle y parvient grâce à des schémas d’entités appris à partir de Wikipedia, Wikidata et Common Crawl, associés à l’analyse contextuelle du texte environnant. En mode Cas L+O, ce processus devient plus sophistiqué : le modèle vérifie les entités via des données structurées externes, recherchant les attributs @id, les liens sameAs et les Q-IDs qui fournissent une identification définitive. Cette étape de vérification est cruciale car les références ambigües ou incohérentes d’entités se perdent dans le bruit du raisonnement du modèle. Une marque qui utilise des conventions de nommage incohérentes, n’établit pas d’identifiants clairs ou n’implémente pas Schema.org devient sémantiquement floue pour la machine—apparaissant comme plusieurs entités différentes plutôt qu’une source unique et cohérente. À l’inverse, les organisations dotées d’entités stables et référencées de façon constante dans plusieurs documents sont reconnues comme des nœuds fiables dans le graphe de connaissances du LLM, augmentant considérablement leur probabilité d’être citées.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Le processus de décision de citation
Le chemin de la requête à la citation suit un processus structuré en sept phases que les chercheurs ont cartographié en analysant le comportement des LLM. Phase 0 : Analyse de l’intention commence lorsque le modèle tokenize l’entrée utilisateur, effectue une analyse sémantique et crée un vecteur d’intention—une représentation abstraite de ce que l’utilisateur demande réellement. Cette phase détermine quels sujets, entités et relations sont pertinents à considérer. Phase 1 : Récupération des connaissances internes accède à la connaissance paramétrique du modèle et calcule un score de confiance. Si ce score dépasse un seuil, le modèle reste en mode Cas L ; sinon, il passe à la recherche externe. Phase 2 : Génération de requêtes élargies (Cas L+O uniquement) crée plusieurs requêtes de recherche sémantiquement variées—généralement de 1 à 6 tokens chacune—destinées à ouvrir au maximum l’espace candidat. Phase 3 : Extraction de preuves récupère des URLs et extraits des résultats de recherche, analyse le HTML et extrait le JSON-LD, le RDFa et les microdonnées. C’est ici que les données structurées deviennent visibles pour le mécanisme de citation. Phase 4 : Liaison d’entités identifie les entités dans les documents récupérés et les vérifie via des identifiants externes, créant un graphe de connaissances temporaire des relations. Phase 5 : Pondération des preuves évalue la solidité des preuves de toutes les sources, en considérant l’architecture des documents, la diversité des sources, la fréquence des confirmations et la cohérence entre les sources. Phase 6 : Raisonnement et synthèse combine les preuves internes et externes, résout les contradictions et détermine si chaque source mérite une mention ou une recommandation. Phase 7 : Construction de la réponse finale traduit les preuves pondérées en langage naturel, en intégrant les citations là où cela est pertinent. Chaque phase alimente la suivante, avec des boucles de rétroaction permettant au modèle d’affiner sa recherche ou de réévaluer les preuves si des incohérences apparaissent.
Génération augmentée par récupération (RAG)
Les LLM modernes utilisent de plus en plus la génération augmentée par récupération (RAG), une technique qui modifie fondamentalement la façon dont les citations sont sélectionnées et justifiées. Plutôt que de s’appuyer uniquement sur la connaissance paramétrique, les systèmes RAG récupèrent activement des documents pertinents, extraient des preuves et fondent leurs réponses sur des sources spécifiques. Cette approche transforme la citation, qui était un sous-produit implicite de l’entraînement, en un processus explicite et traçable. Les implémentations RAG utilisent généralement une recherche hybride, combinant la récupération basée sur les mots-clés avec la recherche par similarité vectorielle pour maximiser le rappel. Une fois les documents candidats récupérés, le classement sémantique réévalue les résultats selon leur sens et non uniquement la correspondance de mots, garantissant que les sources les plus pertinentes apparaissent en tête. Ce mécanisme explicite rend le processus de citation plus transparent et auditable—chaque source citée pouvant être reliée à des passages précis ayant justifié son inclusion. Pour les organisations qui surveillent leur visibilité IA, les systèmes RAG sont particulièrement importants car ils créent des schémas de citation mesurables. Des outils comme AmICited suivent la façon dont les systèmes RAG font référence à votre marque sur différentes plateformes IA, offrant une visibilité sur votre statut de source citée ou de simple matériau de fond dans la phase de récupération des preuves.
Mention vs recommandation
Toutes les citations ne se valent pas. Un LLM peut mentionner une source comme contexte alors qu’il en recommande une autre comme preuve faisant autorité—et cette distinction est entièrement déterminée par la pondération des preuves, non par la réussite de la récupération. Une source peut apparaître dans l’espace candidat (phases 2-3) mais ne pas atteindre le statut de recommandation si son score de preuve est insuffisant. Cette séparation entre mention et recommandation est là où les métriques GEO classiques échouent. Les outils de surveillance standards mesurent l’apparition de votre contenu dans les résultats de recherche (fan-out), mais ils ne peuvent pas savoir si le LLM considère réellement votre contenu comme suffisamment fiable pour être recommandé. Une mention pourrait ressembler à « Certaines sources suggèrent… » tandis qu’une recommandation s’exprime par « Selon [Source], les preuves montrent que… » La différence réside dans le score de la matrice de preuves de la phase 5. Les sources avec des Q-IDs cohérents, une architecture documentaire bien structurée et une confirmation par plusieurs sources indépendantes atteignent le statut de recommandation. Les sources aux références d’entités ambiguës, à la cohérence structurelle faible ou aux affirmations isolées restent des mentions. Pour les marques, cette distinction est cruciale : être récupéré n’est pas la même chose qu’être cité comme autoritaire. Le passage de la récupération à la recommandation requiert clarté sémantique, intégrité structurelle et densité de preuves—des facteurs que l’optimisation SEO traditionnelle ne prend pas en compte.
Implications pratiques pour les créateurs de contenu
Comprendre comment les LLM sélectionnent les sources a des implications immédiates et concrètes pour la stratégie de contenu. Premièrement, implémentez systématiquement le balisage Schema.org sur votre site, en particulier pour les informations sur l’organisation, les articles et les entités clés. Utilisez le format JSON-LD avec des attributs @id appropriés et des liens sameAs vers Wikidata, Wikipedia ou d’autres sources autoritaires. Ces données structurées augmentent directement votre poids de preuve à la phase 5. Deuxièmement, établissez des identifiants d’entité clairs pour votre organisation, vos produits et concepts clés. Adoptez des conventions de nommage cohérentes, évitez les abréviations qui créent de l’ambiguïté et reliez les entités via des relations hiérarchiques (isPartOf, about, mentions). Troisièmement, créez des preuves lisibles par machine en publiant des données structurées sur vos affirmations, références et relations. Ne vous contentez pas d’écrire « Nous sommes le leader de X »—structurez cette affirmation avec des données de support, des citations et des relations vérifiables. Quatrièmement, assurez la cohérence du contenu sur plusieurs plateformes et périodes. Les LLM évaluent la densité de preuve en vérifiant si les affirmations sont confirmées par des sources indépendantes ; des affirmations isolées sur une seule plateforme pèsent moins lourd. Cinquièmement, comprenez que les métriques SEO classiques ne prédisent pas la citation IA. Un bon classement dans la recherche ne garantit pas la recommandation par un LLM ; concentrez-vous plutôt sur la clarté sémantique et l’intégrité structurelle. Sixièmement, surveillez vos schémas de citation avec des outils comme AmICited, qui suivent la façon dont différents systèmes IA font référence à votre marque. Cela révèle si vous atteignez le statut de mention ou de recommandation, et quels types de contenus déclenchent des citations. Enfin, comprenez que la visibilité IA est un investissement à long terme. Les données structurées que vous implémentez aujourd’hui influencent à la fois la probabilité de citation immédiate (effet transitoire) et la base de connaissances interne du modèle lors des futurs cycles d’entraînement (effet persistant).
L’avenir de la citation IA
À mesure que les LLM évoluent, les mécanismes de citation deviennent de plus en plus sophistiqués et transparents. Les modèles futurs implémenteront probablement des graphes de citation—des cartographies explicites montrant non seulement les sources citées, mais aussi comment elles ont influencé des affirmations précises dans la réponse. Certains systèmes avancés expérimentent déjà des scores de confiance probabilistes associés aux citations, indiquant à quel point le modèle est sûr de la pertinence et de la fiabilité de la source. Une autre tendance émergente est la vérification humaine dans la boucle, où les utilisateurs peuvent contester des citations et fournir des retours qui affinent la pondération des preuves lors de futures requêtes. L’intégration des données structurées dans les cycles d’entraînement signifie que les organisations qui mettent en place une infrastructure sémantique appropriée aujourd’hui construisent en réalité leur autorité à long terme dans les systèmes IA. Contrairement aux classements des moteurs de recherche, qui fluctuent selon les mises à jour d’algorithme, l’effet persistant des données structurées crée une base plus stable pour la visibilité IA. Ce passage de la visibilité traditionnelle (être trouvé) à l’autorité sémantique (être digne de confiance) représente un changement fondamental dans la façon dont les marques doivent aborder la communication digitale. Les gagnants dans ce nouveau paysage ne seront pas ceux qui ont le plus de contenu ou le meilleur classement, mais ceux qui structurent leur information de manière à ce que les machines puissent la comprendre, la vérifier et la recommander de façon fiable.
Questions fréquemment posées
Quelle est la différence entre le cas L et le cas L+O dans la citation des LLM ?
Le cas L utilise uniquement les données d’entraînement de la base de connaissances paramétrique du modèle, tandis que le cas L+O complète cela par une recherche web en temps réel. Le seuil de confiance du modèle détermine quel chemin est suivi. Cette distinction est cruciale car elle détermine si des sources externes peuvent être évaluées et citées ou non.
Pourquoi certaines sources sont-elles citées alors que d’autres sont seulement mentionnées ?
La pondération des preuves détermine cette distinction. Les sources avec des données structurées, des identifiants cohérents et une confirmation inter-documents sont élevées au rang de « recommandations » plutôt qu’à celui de simples mentions. Une source peut apparaître dans les résultats de recherche mais ne pas atteindre le statut de recommandation si son score de preuve est insuffisant.
Comment les données structurées comme Schema.org influencent-elles la sélection des citations ?
Les données structurées (JSON-LD, @id, sameAs, Q-IDs) reçoivent un poids 2 à 3 fois plus élevé dans les matrices de preuves. Ce balisage permet la liaison d’entités et la vérification inter-documents, augmentant considérablement le score de fiabilité de la source. Les sources avec une implémentation Schema.org correcte ont beaucoup plus de chances d’être citées comme sources autoritaires.
Qu’est-ce que la reconnaissance d’entités et pourquoi est-ce important pour les citations ?
La reconnaissance d’entités est la façon dont les LLM identifient et distinguent différentes entités (organisations, personnes, concepts). Une identification claire des entités via des noms cohérents et des identifiants structurés évite la confusion et augmente la probabilité de citation. Les références d’entités ambiguës se perdent dans le raisonnement du modèle.
Comment le RAG (Retrieval-Augmented Generation) modifie-t-il les pratiques de citation ?
Les systèmes RAG recherchent activement et classent les sources en temps réel, rendant la sélection des citations plus transparente et fondée sur les preuves que la connaissance purement paramétrique. Ce mécanisme de récupération explicite crée des schémas de citation mesurables qui peuvent être suivis et analysés grâce à des outils de surveillance comme AmICited.
Puis-je optimiser mon contenu pour être cité par les LLM ?
Oui. Implémentez systématiquement le balisage Schema.org, établissez des identifiants clairs pour les entités, créez des preuves lisibles par machine, assurez la cohérence du contenu sur les plateformes et surveillez vos schémas de citation. Ces facteurs influencent directement si votre contenu atteint le statut de mention ou de recommandation dans les réponses des LLM.
Quelle est la différence entre la visibilité IA et la visibilité dans la recherche traditionnelle ?
La visibilité traditionnelle mesure la portée et le classement dans les résultats de recherche. La visibilité IA mesure si votre contenu est reconnu comme preuve autoritaire dans les processus de raisonnement des LLM. Être récupéré n’est pas la même chose qu’être cité comme fiable—cela exige une clarté sémantique et une intégrité structurelle.
Comment AmICited aide-t-il à surveiller les citations des LLM ?
AmICited suit la façon dont les systèmes IA font référence à votre marque dans les GPT, Perplexity et Google AI Overviews. Il révèle si vous atteignez le statut de mention ou de recommandation, quels types de contenus déclenchent des citations, et comment vos schémas de citation se comparent sur différentes plateformes IA.
Surveillez vos citations IA dès aujourd’hui
Comprenez comment les LLM font référence à votre marque dans ChatGPT, Perplexity et Google AI Overviews. Suivez les schémas de citation et optimisez votre visibilité IA avec AmICited.
Comment les grands modèles de langage génèrent-ils des réponses ? | FAQ sur la surveillance de l'IA
Découvrez comment les LLMs génèrent des réponses grâce à la tokenisation, l'architecture des transformeurs, les mécanismes d'attention et la prédiction probabil...
Qu'est-ce que l'optimisation des grands modèles de langage (LLMO) ? Guide complet
Découvrez ce qu'est la LLMO, comment elle fonctionne et pourquoi elle est essentielle pour la visibilité de l'IA. Découvrez des techniques d'optimisation pour q...
Cibler les sites sources des LLM pour obtenir des backlinks
Découvrez comment identifier et cibler les sites sources des LLM pour des backlinks stratégiques. Découvrez quelles plateformes d'IA citent le plus de sources e...
11 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.