
Jeton
Découvrez ce que sont les jetons dans les modèles de langage. Les jetons sont des unités fondamentales du traitement du texte dans les systèmes d'IA, représenta...
13 min de lecture

Découvrez comment les limites de jetons affectent les performances de l’IA et apprenez des stratégies pratiques pour l’optimisation du contenu, y compris RAG, le découpage (chunking) et les techniques de résumé.
Les jetons sont les blocs de construction fondamentaux qu’utilisent les modèles d’IA pour traiter et comprendre l’information. Plutôt que de travailler avec des mots ou des phrases entières, les grands modèles de langage décomposent le texte en unités plus petites appelées jetons, qui peuvent être des caractères individuels, des sous-mots ou des mots complets selon l’algorithme de tokenisation. À chaque jeton est attribué un identifiant numérique unique que le modèle utilise en interne pour les calculs. Ce processus de tokenisation est essentiel car il permet aux systèmes d’IA de traiter efficacement des entrées de longueur variable et de maintenir un traitement cohérent sur différents types de contenus. Comprendre les jetons est crucial pour toute personne travaillant avec des systèmes IA, car ils impactent directement les performances, les coûts et la qualité des résultats obtenus.
Différents modèles d’IA ont des limites de jetons très variables, qui définissent la quantité maximale d’information qu’ils peuvent traiter en une seule requête. Ces limites ont évolué de façon spectaculaire ces dernières années, les modèles récents supportant des fenêtres de contexte beaucoup plus larges. La limite de jetons englobe à la fois les jetons d’entrée (votre prompt et vos données) et les jetons de sortie (la réponse du modèle), créant un budget partagé qu’il faut gérer avec soin. Comprendre ces limites est essentiel pour choisir le modèle adapté à votre cas d’usage et planifier l’architecture de votre application en conséquence.
| Modèle | Limite de jetons | Cas d’utilisation principal | Niveau de coût |
|---|---|---|---|
| GPT-3.5 Turbo | 4 096 | Conversations courtes, tâches rapides | Faible |
| GPT-4 | 8 192 | Applications classiques, complexité modérée | Moyen |
| GPT-4 Turbo | 128 000 | Documents longs, analyses complexes | Élevé |
| Claude 3.5 Sonnet | 200 000 | Documents étendus, analyses approfondies | Élevé |
| Gemini 1.5 Pro | 1 000 000 | Jeux de données massifs, livres entiers, analyse vidéo | Très élevé |
Points clés lors de l’évaluation des limites de jetons :
Les limites de jetons créent des contraintes importantes qui affectent directement la précision, la fiabilité et la rentabilité des applications IA. Si vous dépassez la limite de jetons d’un modèle, l’application échoue totalement — il n’y a ni dégradation progressive ni traitement partiel. Même en restant sous la limite, des méthodes naïves comme la troncature simple peuvent fortement dégrader la performance en supprimant un contexte essentiel dont le modèle a besoin pour générer des réponses précises. Cela pose particulièrement problème dans des domaines comme l’analyse juridique, la recherche médicale ou l’ingénierie logicielle, où la perte d’un détail important peut conduire à des conclusions erronées. Le défi est encore plus complexe lorsqu’on considère que différents types de contenus consomment les jetons à des rythmes différents : des données structurées comme du code ou du JSON requièrent bien plus de jetons que du texte en anglais courant à cause des symboles et de la mise en forme.
La troncature est la méthode la plus simple pour gérer les limites de jetons : vous coupez simplement le contenu excédentaire quand il dépasse la capacité du modèle. Bien que facile à mettre en œuvre, cette approche comporte de sérieux risques. En tronquant du texte, vous perdez inévitablement de l’information, et le modèle ne peut pas savoir ce qui a été supprimé. Cela peut conduire à des analyses incomplètes, une perte de contexte et des hallucinations où le modèle génère des informations plausibles mais incorrectes pour combler les lacunes dans sa compréhension.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Une stratégie de troncature plus sophistiquée distingue le contenu essentiel du contenu optionnel. Vous pouvez donner la priorité aux éléments indispensables comme la requête utilisateur en cours et les instructions principales, puis n’ajouter le contexte optionnel (historique de conversation, etc.) que si la place le permet. Cette approche préserve les informations critiques tout en respectant les limites de jetons.
Plutôt que de tronquer, le découpage (chunking) divise votre contenu en morceaux plus petits et gérables pouvant être traités indépendamment ou de façon sélective. Le découpage à taille fixe segmente le texte en parties uniformes, tandis que le découpage sémantique utilise des embeddings pour identifier les points de rupture naturels basés sur le sens plutôt que sur un nombre arbitraire de jetons. Les fenêtres glissantes avec recouvrement préservent le contexte entre les segments, garantissant que les informations importantes à cheval sur deux fragments ne soient pas perdues.
Le découpage hiérarchique crée plusieurs niveaux d’abstraction — des paragraphes individuels au niveau le plus fin, des sections au niveau intermédiaire, et des chapitres au niveau le plus global. Cette méthode permet des stratégies de récupération sophistiquées pour identifier rapidement les sections pertinentes sans traiter l’ensemble du document. Combiné à des bases de données vectorielles et à la recherche sémantique, le découpage devient un outil puissant pour gérer de vastes bases de connaissances tout en maintenant la pertinence et la précision.
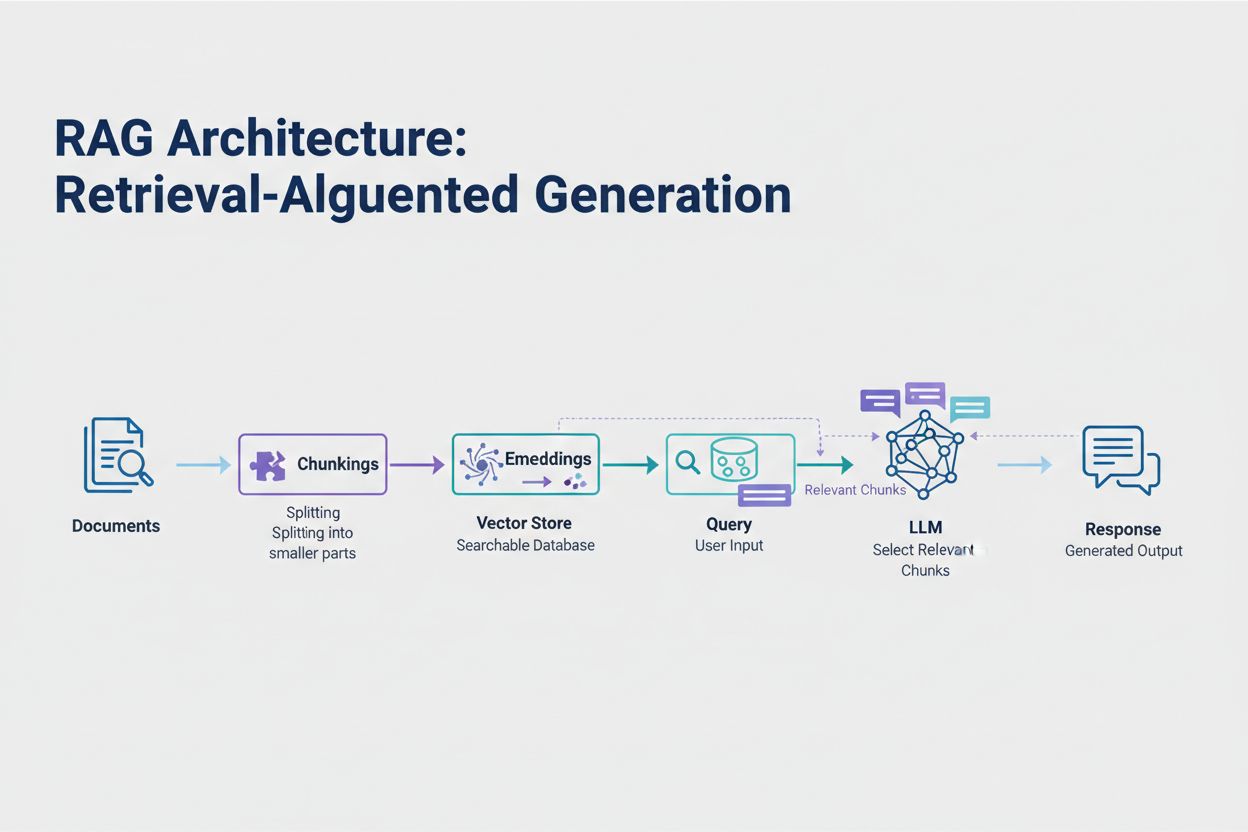
La génération augmentée par récupération (RAG) est aujourd’hui l’approche la plus efficace pour gérer les limites de jetons. Au lieu de tenter d’insérer toutes vos données dans la fenêtre de contexte du modèle, RAG ne récupère qu’au moment de la requête les informations les plus pertinentes. Le processus commence par la conversion de vos documents en embeddings — des représentations numériques capturant le sens sémantique. Ces embeddings sont stockés dans une base de vecteurs, permettant des recherches de similarité rapides.
Lorsqu’un utilisateur soumet une requête, le système l’encode en embedding et récupère les fragments de documents les plus pertinents dans la base vectorielle. Seuls ces fragments sont injectés dans le prompt avec la question de l’utilisateur, réduisant considérablement la consommation de jetons tout en améliorant la précision. Par exemple, analyser un contrat de 100 pages avec RAG peut ne nécessiter que 3 à 5 clauses clés dans le prompt, contre plusieurs milliers de jetons pour inclure l’intégralité du document.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Le résumé condense les contenus volumineux tout en préservant l’essentiel, ce qui permet de réduire efficacement la consommation de jetons. Le résumé extractif sélectionne les phrases clés du texte d’origine, tandis que le résumé abstrait génère un texte nouveau et concis capturant les idées principales. Le résumé hiérarchique crée plusieurs niveaux de synthèse : d’abord en résumant chaque section, puis en combinant ces résumés pour obtenir des vues d’ensemble. Cette approche fonctionne particulièrement bien pour les documents structurés comme les articles de recherche ou les rapports techniques.
La compression de contexte adopte une autre méthode en supprimant la redondance et le contenu superflu tout en maintenant la formulation d’origine. Les approches de graphe de connaissances extraient les entités et les relations du texte, puis reconstruisent le contexte en ne conservant que les faits les plus pertinents. Ces techniques permettent de réduire de 40 à 60 % le nombre de jetons tout en maintenant la précision sémantique, ce qui les rend précieuses pour l’optimisation des coûts en production.
La gestion des jetons impacte directement les coûts de votre application IA. Chaque jeton consommé lors de l’inférence entraîne une facturation, et les coûts augmentent linéairement avec leur usage. Surveiller la consommation de jetons est essentiel pour comprendre votre structure de coûts et repérer des opportunités d’optimisation. De nombreuses plateformes IA proposent aujourd’hui des utilitaires de comptage de jetons et des tableaux de bord en temps réel pour suivre les usages, vous aidant à identifier quelles requêtes ou fonctionnalités consomment le plus.
Un suivi efficace révèle les opportunités d’optimisation : certaines requêtes dépassent systématiquement les limites de jetons, ou certaines fonctionnalités consomment des ressources disproportionnées. En observant ces tendances, vous pouvez prendre des décisions éclairées sur la stratégie à adopter. Certaines applications bénéficient du routage des requêtes volumineuses vers des modèles plus puissants (mais plus coûteux), d’autres tirent meilleur parti de RAG ou du résumé. L’essentiel est de mesurer les performances et les coûts réels pour valider vos choix d’optimisation.
Le choix de la bonne stratégie de gestion des jetons dépend de votre cas d’usage, de vos exigences de performance et de vos contraintes budgétaires. Les applications exigeant une grande précision avec des réponses sourcées bénéficient le plus de RAG, qui préserve la fidélité de l’information tout en maîtrisant la consommation de jetons. Les applications conversationnelles de longue durée profitent de techniques de mémoire tampon qui résument l’historique tout en conservant les décisions et contextes clés. Les applications orientées documents, comme l’analyse juridique ou les outils de recherche, tirent souvent parti du résumé hiérarchique combiné au découpage sémantique.
Les tests et la validation sont cruciaux avant tout déploiement en production. Créez des cas de test dépassant les limites de jetons de votre modèle, puis évaluez comment chaque stratégie affecte la précision, la latence et le coût. Mesurez des métriques telles que la pertinence des réponses, la précision factuelle et l’efficacité des jetons pour vous assurer que votre approche répond à vos besoins. Les pièges courants incluent un résumé trop agressif qui fait perdre des détails importants, des systèmes de récupération passant à côté d’informations pertinentes, ou des stratégies de découpage brisant le contenu à des endroits sémantiquement inappropriés.
Les limites de jetons continuent de s’élargir à mesure que les modèles gagnent en sophistication et en efficacité. Des techniques émergentes comme les mécanismes d’attention clairsemée et les transformers efficaces promettent de réduire le coût du traitement de larges fenêtres de contexte. Les modèles multimodaux traitant texte, images, audio et vidéo simultanément introduisent de nouveaux défis et opportunités en matière de tokenisation. Les jetons de raisonnement — des jetons spéciaux utilisés par les modèles pour “réfléchir” à des problèmes complexes — constituent une nouvelle catégorie de consommation, permettant des résolutions plus avancées mais nécessitant une gestion attentive.
La trajectoire est claire : à mesure que les fenêtres de contexte s’élargissent et que le traitement des jetons s’optimise, le principal goulot d’étranglement se déplace de la capacité brute vers la sélection intelligente du contenu. L’avenir appartient aux systèmes capables d’identifier et de récupérer efficacement l’information la plus pertinente d’immenses bases de connaissances, plutôt qu’aux systèmes se contentant de traiter toujours plus de données. Cela fait de RAG et de la recherche sémantique des techniques clés pour construire des applications IA évolutives et rentables.
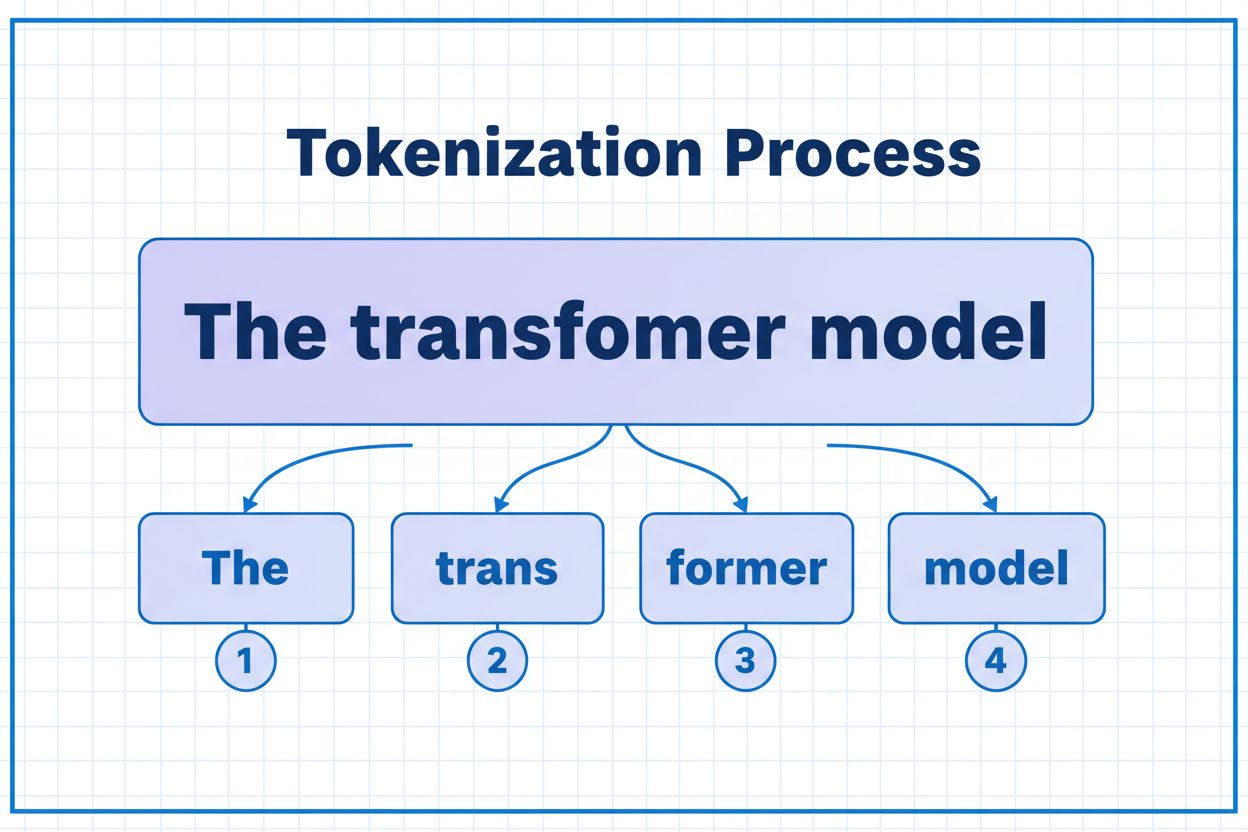
Un jeton est la plus petite unité de données qu’un modèle d’IA traite. Les jetons peuvent être des caractères individuels, des sous-mots ou des mots entiers selon l’algorithme de tokenisation. Par exemple, le mot « transformer » peut être découpé en « trans » et « former » comme deux jetons distincts. Chaque jeton reçoit un identifiant numérique unique que le modèle utilise en interne pour le calcul.
Les limites de jetons définissent la quantité maximale d’informations que votre modèle d’IA peut traiter en une seule requête. Si vous dépassez cette limite, votre application échoue complètement. Même en restant dans les limites, des approches naïves comme la troncature peuvent réduire la précision en supprimant des contextes critiques. Les limites de jetons ont aussi un impact direct sur les coûts, car vous payez généralement par jeton consommé.
Les jetons d’entrée sont ceux de votre prompt et des données que vous envoyez au modèle, tandis que les jetons de sortie sont ceux que le modèle génère dans sa réponse. Ils partagent un budget commun défini par la fenêtre de contexte du modèle. Si votre entrée utilise 90% d’une fenêtre de 128 000 jetons, il ne vous reste que 10% pour la sortie du modèle.
La troncature est simple à mettre en œuvre mais risquée. Elle supprime des informations sans que le modèle sache ce qui a été perdu, ce qui conduit à des analyses incomplètes et à des hallucinations potentielles. Utile en dernier recours, il vaut mieux privilégier des approches comme RAG, le découpage ou le résumé, qui préservent la fidélité de l’information tout en gérant plus efficacement la consommation de jetons.
La génération augmentée par récupération (RAG) ne récupère qu’au moment de la requête les informations les plus pertinentes au lieu d’inclure des documents entiers. Vos documents sont convertis en embeddings et stockés dans une base de vecteurs. Lors d’une requête, le système extrait uniquement les fragments pertinents et les injecte dans le prompt, réduisant considérablement la consommation de jetons tout en améliorant la précision.
La plupart des plateformes IA proposent des utilitaires de comptage de jetons et des tableaux de bord en temps réel pour suivre les usages. Surveillez quelles requêtes ou fonctionnalités consomment le plus de jetons, puis appliquez des stratégies comme RAG pour les applications à base documentaire, le résumé pour les longues conversations, ou le routage vers des modèles plus grands pour les tâches complexes. Mesurez les performances réelles et les coûts pour valider vos choix.
Les services IA facturent généralement à chaque jeton consommé. Les coûts augmentent linéairement avec l’usage des jetons, donc leur optimisation impacte directement vos dépenses. Une réduction de 20% du nombre de jetons consommés équivaut à 20% d’économies. Comprendre l’efficacité des jetons vous aide à choisir la bonne stratégie selon vos contraintes budgétaires.
Les limites de jetons continuent de s’élargir à mesure que les modèles deviennent plus sophistiqués. Des techniques émergentes comme les mécanismes d’attention clairsemée promettent de réduire les coûts informatiques du traitement de grands contextes. L’avenir se concentre sur la sélection et la récupération intelligente du contenu plutôt que sur la capacité brute de traitement — rendant des techniques comme RAG de plus en plus essentielles pour des applications IA évolutives.
Comprenez l’efficacité des jetons et suivez comment les modèles d’IA citent votre marque grâce à la plateforme complète de surveillance des citations IA d’AmICited.
Découvrez ce que sont les jetons dans les modèles de langage. Les jetons sont des unités fondamentales du traitement du texte dans les systèmes d'IA, représenta...

Découvrez comment les modèles d'IA traitent le texte grâce à la tokenisation, aux embeddings, aux blocs transformeurs et aux réseaux neuronaux. Comprenez toute ...

Guide fondé sur la recherche pour déterminer la longueur optimale des passages pour les citations d’IA. Découvrez pourquoi 75-150 mots est idéal, comment les je...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.