Optimisation des données d'entraînement vs récupération en temps réel : stratégies d'optimisation
Comparez l’optimisation des données d’entraînement et les stratégies de récupération en temps réel pour l’IA. Découvrez quand utiliser le fine-tuning vs RAG, les implications en termes de coûts et les approches hybrides pour des performances d’IA optimales.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
L’optimisation des données d’entraînement et la récupération en temps réel représentent des approches fondamentalement différentes pour doter les modèles d’IA de connaissances. L’optimisation des données d’entraînement consiste à intégrer directement les connaissances dans les paramètres du modèle via le fine-tuning sur des ensembles de données spécifiques au domaine, créant une connaissance statique qui reste figée après la fin de l’entraînement. La récupération en temps réel, au contraire, maintient les connaissances à l’extérieur du modèle et récupère dynamiquement les informations pertinentes lors de l’inférence, permettant l’accès à des informations dynamiques susceptibles de changer entre les requêtes. La distinction essentielle réside dans le moment où la connaissance est intégrée au modèle : l’optimisation des données d’entraînement intervient avant le déploiement, tandis que la récupération en temps réel s’effectue à chaque appel d’inférence. Cette différence fondamentale a des répercussions sur tous les aspects de la mise en œuvre, des besoins d’infrastructure aux caractéristiques de précision en passant par les considérations de conformité. Comprendre cette distinction est essentiel pour les organisations qui souhaitent choisir la stratégie d’optimisation la mieux adaptée à leurs cas d’usage et à leurs contraintes.
Fonctionnement de l’optimisation des données d’entraînement
L’optimisation des données d’entraînement fonctionne en ajustant systématiquement les paramètres internes d’un modèle grâce à l’exposition à des ensembles de données sélectionnés et spécifiques au domaine pendant le processus de fine-tuning. Lorsqu’un modèle rencontre à plusieurs reprises des exemples d’entraînement, il internalise progressivement les schémas, la terminologie et l’expertise du domaine via la rétropropagation et les mises à jour de gradient qui modifient ses mécanismes d’apprentissage. Ce processus permet aux organisations d’encoder des connaissances spécialisées—qu’il s’agisse de terminologie médicale, de cadres juridiques ou de logique métier propriétaire—directement dans les poids et biais du modèle. Le modèle résultant devient hautement spécialisé pour son domaine cible, atteignant souvent des performances comparables à des modèles beaucoup plus grands ; des recherches de Snorkel AI ont démontré que des petits modèles fine-tunés peuvent égaler des modèles 1 400 fois plus volumineux. Les principales caractéristiques de l’optimisation des données d’entraînement incluent :
Intégration permanente des connaissances : une fois entraînées, les connaissances font partie du modèle et ne nécessitent aucune consultation externe
Latence d’inférence réduite : aucune surcharge de récupération lors de la prédiction, ce qui permet des temps de réponse plus rapides
Style et formatage cohérents : les modèles apprennent les schémas et conventions de communication spécifiques au domaine
Capacité de fonctionnement hors ligne : les modèles fonctionnent de manière autonome sans sources de données externes
Coût en calcul initial élevé : nécessite d’importantes ressources GPU et la préparation de données annotées
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
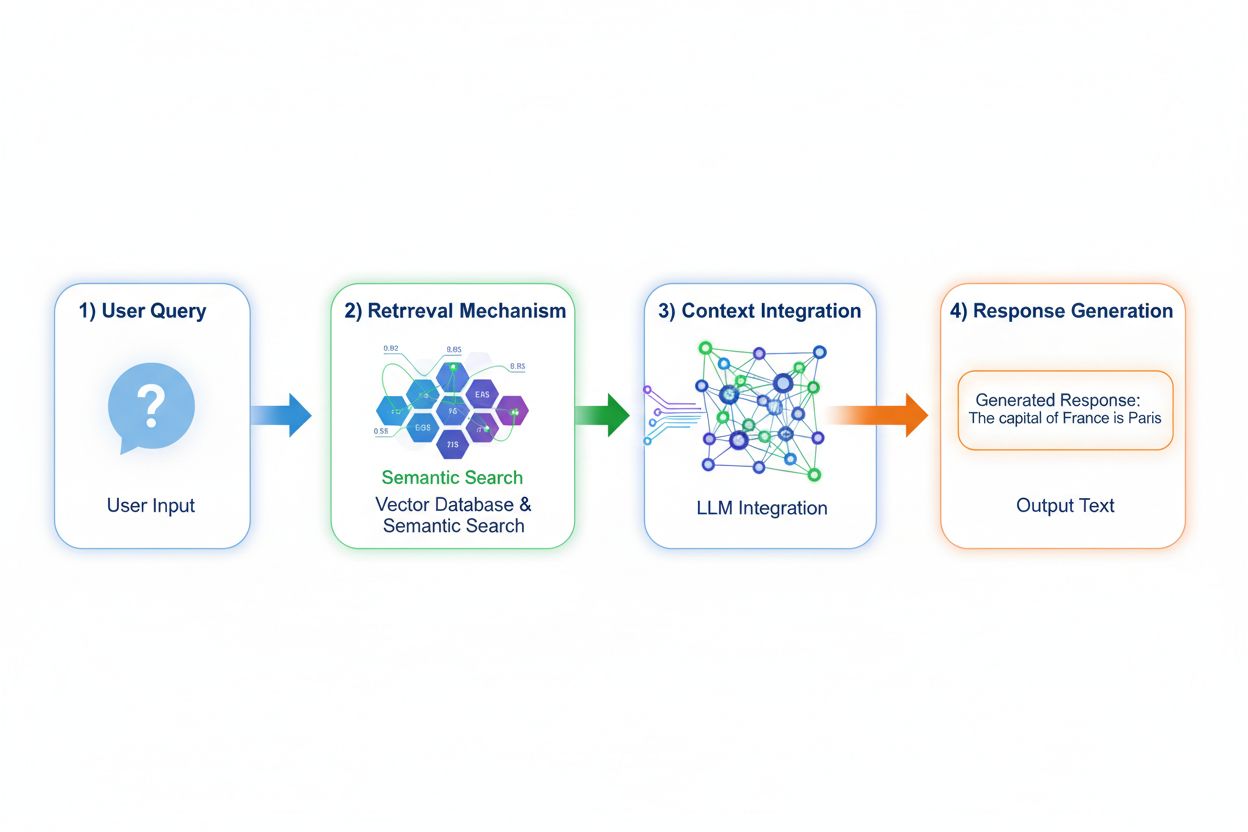
Retrieval Augmented Generation (RAG) modifie fondamentalement la manière dont les modèles accèdent aux connaissances en mettant en œuvre un processus en quatre étapes : encodage de la requête, recherche sémantique, classement du contexte et génération avec ancrage. Lorsqu’un utilisateur soumet une requête, le RAG la convertit d’abord en une représentation vectorielle dense à l’aide de modèles d’embedding, puis recherche dans une base de données vectorielle contenant des documents ou sources de connaissances indexés. L’étape de récupération utilise la recherche sémantique pour trouver des passages contextuellement pertinents plutôt qu’un simple appariement de mots-clés, en classant les résultats par scores de pertinence. Enfin, le modèle génère des réponses tout en maintenant des références explicites aux sources récupérées, ancrant sa sortie dans des données réelles plutôt que dans des paramètres appris. Cette architecture permet aux modèles d’accéder à des informations inexistantes lors de l’entraînement, rendant le RAG particulièrement utile pour les applications nécessitant des informations actuelles, des données propriétaires ou des bases de connaissances fréquemment mises à jour. Le mécanisme RAG transforme essentiellement le modèle d’un réservoir de connaissances statique en un synthétiseur d’informations dynamique capable d’intégrer de nouvelles données sans réentraînement.
Comparaison des performances et de la précision
Les profils de précision et d’hallucination de ces approches diffèrent de façon significative, ce qui impacte le déploiement réel. L’optimisation des données d’entraînement produit des modèles dotés d’une compréhension approfondie du domaine mais d’une capacité limitée à reconnaître les limites de leurs connaissances ; lorsqu’un modèle fine-tuné rencontre des questions hors de sa distribution d’entraînement, il peut générer avec assurance des informations plausibles mais incorrectes. Le RAG réduit considérablement les hallucinations en ancrant les réponses dans des documents récupérés—le modèle ne peut pas revendiquer d’informations absentes de son matériel source, ce qui crée des contraintes naturelles sur la fabrication. Cependant, le RAG introduit d’autres risques de précision : si la phase de récupération échoue à trouver des sources pertinentes ou classe des documents non pertinents en tête, le modèle génère des réponses à partir d’un contexte médiocre. La fraîcheur des données devient essentielle pour les systèmes RAG ; l’optimisation des données d’entraînement capture un instantané statique des connaissances au moment de l’entraînement, tandis que le RAG reflète en continu l’état actuel des documents sources. L’attribution de source constitue une autre différence : le RAG permet intrinsèquement la citation et la vérification des affirmations, tandis que les modèles fine-tunés ne peuvent pas indiquer de sources précises, ce qui complique la vérification des faits et la conformité.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Conséquences en matière de coûts et d’infrastructure
Les profils économiques de ces approches créent des structures de coûts distinctes que les organisations doivent évaluer avec soin. L’optimisation des données d’entraînement nécessite un coût computationnel substantiel en amont : clusters GPU fonctionnant pendant des jours ou des semaines pour affiner les modèles, services d’annotation de données pour créer des jeux d’entraînement labellisés, et expertise en ingénierie ML pour concevoir des pipelines d’entraînement efficaces. Une fois entraînée, l’utilisation coûte relativement peu, car l’inférence ne nécessite qu’une infrastructure standard de service du modèle sans consultations externes. Les systèmes RAG inversent cette structure de coûts : coûts d’entraînement initiaux plus faibles car il n’y a pas de fine-tuning, mais dépenses d’infrastructure continues pour maintenir des bases de données vectorielles, des modèles d’embedding, des services de récupération et des pipelines d’indexation de documents. Les principaux facteurs de coût incluent :
Fine-tuning : heures GPU (10 000 $ à plus de 100 000 $ par modèle), annotation de données (0,50 $ à 5 $ par exemple), temps d’ingénierie
Infrastructure RAG : licence de base de données vectorielle, service de modèles d’embedding, stockage et indexation de documents, optimisation de la latence de récupération
Scalabilité : les modèles fine-tunés évoluent linéairement avec le volume d’inférences ; les systèmes RAG évoluent avec le volume d’inférences et la taille de la base de connaissances
Maintenance : le fine-tuning nécessite des réentraînements périodiques ; le RAG requiert des mises à jour continues des documents et de l’index
Considérations de sécurité et de conformité
Les implications en matière de sécurité et de conformité diffèrent considérablement selon les approches, impactant les organisations dans les secteurs réglementés. Les modèles fine-tunés créent des défis en matière de protection des données car les données d’entraînement sont intégrées dans les poids du modèle ; extraire ou auditer les connaissances contenues dans le modèle nécessite des techniques sophistiquées, et des préoccupations de confidentialité surgissent lorsque des données sensibles d’entraînement influencent le comportement du modèle. La conformité avec des réglementations comme le RGPD devient complexe, car le modèle « se souvient » des données d’entraînement d’une façon qui résiste à la suppression ou à la modification. Les systèmes RAG offrent un profil de sécurité différent : les connaissances restent dans des sources de données externes et auditées plutôt que dans les paramètres du modèle, permettant des contrôles de sécurité et des restrictions d’accès simples. Les organisations peuvent appliquer des droits d’accès fins sur les sources de récupération, auditer les documents consultés par le modèle pour chaque réponse, et supprimer rapidement des informations sensibles en mettant à jour les documents sources sans réentraînement. Toutefois, le RAG introduit des risques liés à la protection de la base vectorielle, à la sécurité du modèle d’embedding et à la prévention de la fuite d’informations sensibles dans les documents récupérés. Les organismes de santé soumis à la HIPAA et les entreprises européennes soumises au RGPD privilégient souvent la transparence et l’auditabilité du RAG, tandis que les organisations axées sur la portabilité du modèle et le fonctionnement hors ligne favorisent l’approche autonome du fine-tuning.
Cadre décisionnel pratique
Le choix entre ces approches nécessite d’évaluer les contraintes organisationnelles spécifiques et les caractéristiques du cas d’usage. Les organisations devraient privilégier le fine-tuning lorsque les connaissances sont stables et peu susceptibles de changer fréquemment, lorsque la latence d’inférence est critique, lorsque les modèles doivent fonctionner hors ligne ou dans des environnements isolés, ou lorsque le style cohérent et le formatage spécifique au domaine sont essentiels. La récupération en temps réel devient préférable lorsque les connaissances évoluent régulièrement, lorsque l’attribution de source et l’auditabilité sont essentiels pour la conformité, lorsque la base de connaissances est trop volumineuse pour être efficacement encodée dans les paramètres du modèle, ou lorsque l’organisation a besoin de mettre à jour l’information sans réentraînement. Des cas d’usage concrets illustrent ces distinctions :
Fine-tuning : bots de service client pour informations produit stables, assistants spécialisés en diagnostic médical, analyse de documents juridiques sur de la jurisprudence établie
RAG : systèmes de synthèse d’actualités nécessitant des événements récents, support client avec catalogues produits fréquemment mis à jour, assistants de recherche accédant à la littérature scientifique dynamique
Cadre de décision : évaluer la stabilité des connaissances, les exigences de conformité, les contraintes de latence, la fréquence de mise à jour et les capacités d’infrastructure
Approches hybrides et stratégies combinées
Les approches hybrides combinent fine-tuning et RAG pour tirer parti des avantages des deux stratégies tout en atténuant leurs limites individuelles. Les organisations peuvent affiner les modèles sur les fondamentaux et les schémas de communication du domaine tout en utilisant le RAG pour accéder à des informations actuelles et détaillées—le modèle apprend comment raisonner sur un domaine tout en récupérant quelles informations spécifiques à intégrer. Cette stratégie combinée s’avère particulièrement efficace pour les applications nécessitant à la fois une expertise spécialisée et des informations à jour : un bot de conseil financier fine-tuné sur les principes et la terminologie de l’investissement peut récupérer des données de marché et des résultats d’entreprise en temps réel via le RAG. Les implémentations hybrides réelles incluent des systèmes de santé fine-tunés sur les connaissances médicales et protocoles tout en récupérant les données spécifiques des patients via le RAG, et des plateformes juridiques fine-tunées sur le raisonnement juridique tout en accédant à la jurisprudence actuelle via récupération. Les bénéfices synergiques incluent la réduction des hallucinations (ancrage dans les sources récupérées), une meilleure compréhension du domaine (fine-tuning), une inférence plus rapide sur les requêtes courantes (connaissances fine-tunées en cache) et la flexibilité de mettre à jour les informations spécialisées sans réentraînement. Les organisations adoptent de plus en plus cette optimisation à mesure que les ressources computationnelles deviennent plus accessibles et que la complexité des applications réelles exige à la fois profondeur et actualité.
Surveillance des réponses de l’IA et suivi des citations
La capacité à surveiller les réponses de l’IA en temps réel devient de plus en plus cruciale à mesure que les organisations déploient ces stratégies d’optimisation à grande échelle, en particulier pour comprendre quelle approche donne de meilleurs résultats selon le cas d’usage. Les systèmes de surveillance de l’IA suivent les sorties des modèles, la qualité de la récupération et les indicateurs de satisfaction des utilisateurs, permettant d’évaluer si les modèles fine-tunés ou les systèmes RAG servent mieux leurs applications. Le suivi des citations révèle des différences cruciales entre les approches : les systèmes RAG génèrent naturellement des citations et références sources, créant une piste d’audit des documents ayant influencé chaque réponse, tandis que les modèles fine-tunés n’offrent aucun mécanisme inhérent de surveillance des réponses ou d’attribution. Cette distinction est particulièrement importante pour la sécurité de la marque et l’intelligence concurrentielle—les organisations doivent comprendre comment les systèmes d’IA citent leurs concurrents, référencent leurs produits ou attribuent les informations à leurs sources. Des outils comme AmICited.com répondent à ce besoin en surveillant la façon dont les systèmes d’IA citent les marques et entreprises selon différentes stratégies d’optimisation, offrant un suivi en temps réel des schémas et de la fréquence des citations. En mettant en œuvre une surveillance complète, les organisations peuvent mesurer si leur stratégie d’optimisation choisie (fine-tuning, RAG ou hybride) améliore réellement la précision des citations, réduit les hallucinations sur les concurrents et maintient une attribution appropriée aux sources autorisées. Cette approche fondée sur les données permet d’affiner en continu les stratégies d’optimisation sur la base de la performance réelle plutôt que d’attentes théoriques.
Tendances futures et schémas émergents
Le secteur évolue vers des approches hybrides et adaptatives plus sophistiquées qui sélectionnent dynamiquement la stratégie d’optimisation en fonction des caractéristiques des requêtes et des besoins en connaissances. Les meilleures pratiques émergentes incluent la mise en œuvre du fine-tuning augmenté par la récupération, où les modèles sont fine-tunés sur la façon d’utiliser efficacement l’information récupérée plutôt que de mémoriser des faits, et des systèmes d’aiguillage adaptatifs qui dirigent les requêtes vers les modèles fine-tunés pour les connaissances stables et vers les systèmes RAG pour l’information dynamique. Les tendances indiquent une adoption croissante de modèles d’embedding spécialisés et de bases de données vectorielles optimisées pour des domaines spécifiques, permettant une recherche sémantique plus précise et réduisant le bruit lors de la récupération. Les organisations développent des schémas d’amélioration continue des modèles combinant des mises à jour périodiques de fine-tuning avec une augmentation RAG en temps réel, créant des systèmes qui s’améliorent tout en maintenant l’accès à l’information actuelle. L’évolution des stratégies d’optimisation reflète la reconnaissance croissante dans l’industrie qu’aucune approche unique ne répond de façon optimale à tous les cas d’usage ; les systèmes futurs mettront probablement en œuvre des mécanismes de sélection intelligents choisissant dynamiquement entre fine-tuning, RAG et approches hybrides selon le contexte de la requête, la stabilité des connaissances, les exigences de latence et les contraintes de conformité. À mesure que ces technologies mûrissent, l’avantage concurrentiel passera du choix d’une approche à la mise en œuvre experte de systèmes adaptatifs tirant parti des atouts de chaque stratégie.
Questions fréquemment posées
Quelle est la principale différence entre l'optimisation des données d'entraînement et la récupération en temps réel ?
L'optimisation des données d'entraînement intègre les connaissances directement dans les paramètres d'un modèle via le fine-tuning, créant ainsi une connaissance statique qui reste figée après l'entraînement. La récupération en temps réel conserve les connaissances à l'extérieur et récupère dynamiquement les informations pertinentes lors de l'inférence, permettant l'accès à des informations dynamiques qui peuvent changer entre les requêtes. La distinction fondamentale réside dans le moment où la connaissance est intégrée : l'optimisation des données d'entraînement se fait avant le déploiement, tandis que la récupération en temps réel s'effectue à chaque appel d'inférence.
Quand dois-je utiliser le fine-tuning plutôt que le RAG ?
Utilisez le fine-tuning lorsque les connaissances sont stables et peu susceptibles de changer fréquemment, lorsque la latence d'inférence est critique, lorsque les modèles doivent fonctionner hors ligne, ou lorsque le style cohérent et le formatage spécifique au domaine sont essentiels. Le fine-tuning est idéal pour des tâches spécialisées comme le diagnostic médical, l'analyse de documents juridiques ou le service client avec des informations produits stables. Cependant, le fine-tuning nécessite d'importantes ressources de calcul initiales et devient peu pratique lorsque l'information change fréquemment.
Puis-je combiner l'optimisation des données d'entraînement avec la récupération en temps réel ?
Oui, les approches hybrides combinent le fine-tuning et le RAG pour tirer parti des avantages des deux stratégies. Les organisations peuvent affiner les modèles sur les fondamentaux du domaine tout en utilisant le RAG pour accéder à des informations actuelles et détaillées. Cette approche est particulièrement efficace pour les applications nécessitant à la fois une expertise spécialisée et des informations à jour, comme les bots de conseil financier ou les systèmes de santé qui ont besoin à la fois de connaissances médicales et de données spécifiques aux patients.
Comment le RAG réduit-il les hallucinations par rapport au fine-tuning ?
Le RAG réduit considérablement les hallucinations en ancrant les réponses dans des documents récupérés—le modèle ne peut pas revendiquer des informations qui n'apparaissent pas dans son matériel source, créant ainsi des contraintes naturelles sur la fabrication. Les modèles fine-tunés, en revanche, peuvent générer avec assurance des informations plausibles mais incorrectes lorsqu'ils rencontrent des questions hors de leur distribution d'entraînement. L'attribution de la source par RAG permet également de vérifier les affirmations, tandis que les modèles fine-tunés ne peuvent pas indiquer de sources précises pour leurs connaissances.
Quelles sont les implications en termes de coûts de chaque approche ?
Le fine-tuning nécessite des coûts initiaux importants : heures de GPU (10 000 $ à plus de 100 000 $ par modèle), annotation de données (0,50 $ à 5 $ par exemple) et temps d'ingénierie. Une fois entraîné, le coût de service reste relativement faible. Les systèmes RAG ont des coûts initiaux plus bas mais des dépenses d'infrastructure continues pour les bases de données vectorielles, les modèles d'embedding et les services de récupération. Les modèles fine-tunés évoluent linéairement avec le volume d'inférences, tandis que les systèmes RAG évoluent à la fois avec le volume d'inférences et la taille de la base de connaissances.
Comment la récupération en temps réel aide-t-elle au suivi des citations de l'IA ?
Les systèmes RAG génèrent naturellement des citations et des références sources, créant une piste d'audit des documents ayant influencé chaque réponse. Ceci est crucial pour la sécurité de la marque et l'intelligence concurrentielle—les organisations peuvent suivre comment les systèmes d'IA citent leurs concurrents et référencent leurs produits. Des outils comme AmICited.com surveillent la façon dont les systèmes d'IA citent les marques selon différentes stratégies d'optimisation, offrant un suivi en temps réel des schémas et de la fréquence des citations.
Quelle approche est la meilleure pour les secteurs fortement réglementés ?
Le RAG est généralement préférable pour les secteurs fortement réglementés comme la santé et la finance. Les connaissances restent dans des sources de données externes et auditées plutôt que dans les paramètres du modèle, permettant des contrôles de sécurité et des restrictions d'accès simples. Les organisations peuvent mettre en œuvre des autorisations fines, auditer les documents consultés par le modèle et supprimer rapidement des informations sensibles sans réentraînement. Les organismes de santé soumis à la HIPAA et les organisations soumises au RGPD préfèrent souvent la transparence et l'auditabilité du RAG.
Comment surveiller l'efficacité de la stratégie d'optimisation choisie ?
Mettez en place des systèmes de surveillance de l'IA qui suivent les sorties des modèles, la qualité de la récupération et les indicateurs de satisfaction des utilisateurs. Pour les systèmes RAG, surveillez la précision de la récupération et la qualité des citations. Pour les modèles fine-tunés, suivez la précision sur les tâches spécifiques au domaine et le taux d'hallucination. Utilisez des outils comme AmICited.com pour surveiller la façon dont vos systèmes d'IA citent l'information et comparez les performances entre différentes stratégies d'optimisation sur la base des résultats réels.
Surveillez comment les systèmes d'IA citent votre marque
Suivez les citations en temps réel sur GPTs, Perplexity et Google AI Overviews. Comprenez quelles stratégies d'optimisation utilisent vos concurrents et comment ils sont référencés dans les réponses de l'IA.
Données d'entraînement vs Recherche en direct : Comment les systèmes d'IA accèdent à l'information
Comprenez la différence entre les données d'entraînement de l'IA et la recherche en direct. Découvrez comment les limites de connaissance, le RAG et la récupéra...
Comment optimiser votre contenu pour les données d’entraînement de l’IA et les moteurs de recherche IA
Apprenez à optimiser votre contenu pour l’inclusion dans les données d’entraînement de l’IA. Découvrez les meilleures pratiques pour rendre votre site web décou...
Découvrez l'adaptation de l'IA en temps réel - la technologie qui permet aux systèmes d'IA d'apprendre en continu à partir des événements et des données actuels...
9 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.