
Que sont les embeddings dans la recherche IA ?
Découvrez comment fonctionnent les embeddings dans les moteurs de recherche IA et les modèles de langage. Comprenez les représentations vectorielles, la recherc...
10 min de lecture

Découvrez comment les embeddings vectoriels permettent aux systèmes d’IA de comprendre la signification sémantique et de faire correspondre le contenu aux requêtes. Explorez la technologie derrière la recherche sémantique et la correspondance de contenu par l’IA.

Les embeddings vectoriels sont la base numérique qui alimente les systèmes d’intelligence artificielle modernes, transformant les données brutes en représentations mathématiques que les machines peuvent comprendre et traiter. Au cœur de ce procédé, les embeddings convertissent le texte, les images, l’audio et d’autres types de contenu en tableaux de nombres — généralement de quelques dizaines à plusieurs milliers de dimensions — qui capturent la signification sémantique et les relations contextuelles de ces données. Cette représentation numérique est fondamentale dans la façon dont les systèmes d’IA effectuent la correspondance de contenu, la recherche sémantique et les tâches de recommandation, permettant aux machines de comprendre non seulement quels mots ou images sont présents, mais ce qu’ils signifient réellement. Sans embeddings, les systèmes d’IA auraient du mal à saisir les relations nuancées entre les concepts, ce qui fait de ces outils une infrastructure essentielle pour toute application d’IA moderne.
La transformation des données brutes en embeddings vectoriels est accomplie à l’aide de modèles de réseaux neuronaux sophistiqués entraînés sur d’énormes ensembles de données afin d’apprendre des motifs et des relations significatifs. Lorsque vous saisissez un texte dans un modèle d’embedding, il traverse plusieurs couches de réseaux neuronaux qui extraient progressivement des informations sémantiques, produisant finalement un vecteur de taille fixe représentant l’essence de ce contenu. Des modèles d’embeddings populaires comme Word2Vec, GloVE et BERT adoptent chacun des approches différentes — Word2Vec utilise des réseaux neuronaux peu profonds optimisés pour la rapidité, GloVE combine la factorisation de matrices globale avec des fenêtres de contexte local, tandis que BERT s’appuie sur une architecture de type transformer pour comprendre le contexte bidirectionnel.
| Modèle | Type de données | Dimensions | Cas d’usage principal | Avantage clé |
|---|---|---|---|---|
| Word2Vec | Texte (mots) | 100-300 | Relations entre mots | Rapide, efficace |
| GloVE | Texte (mots) | 100-300 | Relations sémantiques | Combine le contexte global et local |
| BERT | Texte (phrases/docs) | 768-1024 | Compréhension contextuelle | Sensibilité au contexte bidirectionnel |
| Sentence-BERT | Texte (phrases) | 384-768 | Similarité de phrases | Optimisé pour la recherche sémantique |
| Universal Sentence Encoder | Texte (phrases) | 512 | Tâches multilingues | Indépendant de la langue |
Ces modèles produisent des vecteurs à haute dimensionnalité (souvent de 300 à 1 536 dimensions), où chaque dimension capture différents aspects de la signification, allant des propriétés grammaticales aux relations conceptuelles. La beauté de cette représentation numérique est qu’elle permet des opérations mathématiques — vous pouvez additionner, soustraire et comparer des vecteurs pour découvrir des relations qui seraient invisibles dans le texte brut. Cette base mathématique est ce qui rend la recherche sémantique et la correspondance de contenu intelligente possible à grande échelle.
La véritable puissance des embeddings apparaît à travers la similarité sémantique, la capacité à reconnaître que différents mots ou expressions peuvent avoir essentiellement la même signification dans l’espace vectoriel. Lorsque les embeddings sont créés efficacement, des concepts sémantiquement proches se regroupent naturellement dans l’espace à haute dimension — « roi » et « reine » sont proches l’un de l’autre, tout comme « voiture » et « véhicule », même s’il s’agit de mots différents. Pour mesurer cette similarité, les systèmes d’IA utilisent des métriques de distance comme la similarité cosinus (mesurant l’angle entre les vecteurs) ou le produit scalaire (mesurant la magnitude et la direction), qui quantifient à quel point deux embeddings sont proches l’un de l’autre. Par exemple, une requête sur le « transport automobile » aura une forte similarité cosinus avec des documents parlant de « voyage en voiture », permettant au système de faire correspondre le contenu sur la base de la signification plutôt que d’une correspondance exacte de mots-clés. Cette compréhension sémantique est ce qui distingue la recherche IA moderne de la simple correspondance de mots-clés, permettant aux systèmes de comprendre l’intention de l’utilisateur et de fournir de véritables résultats pertinents.
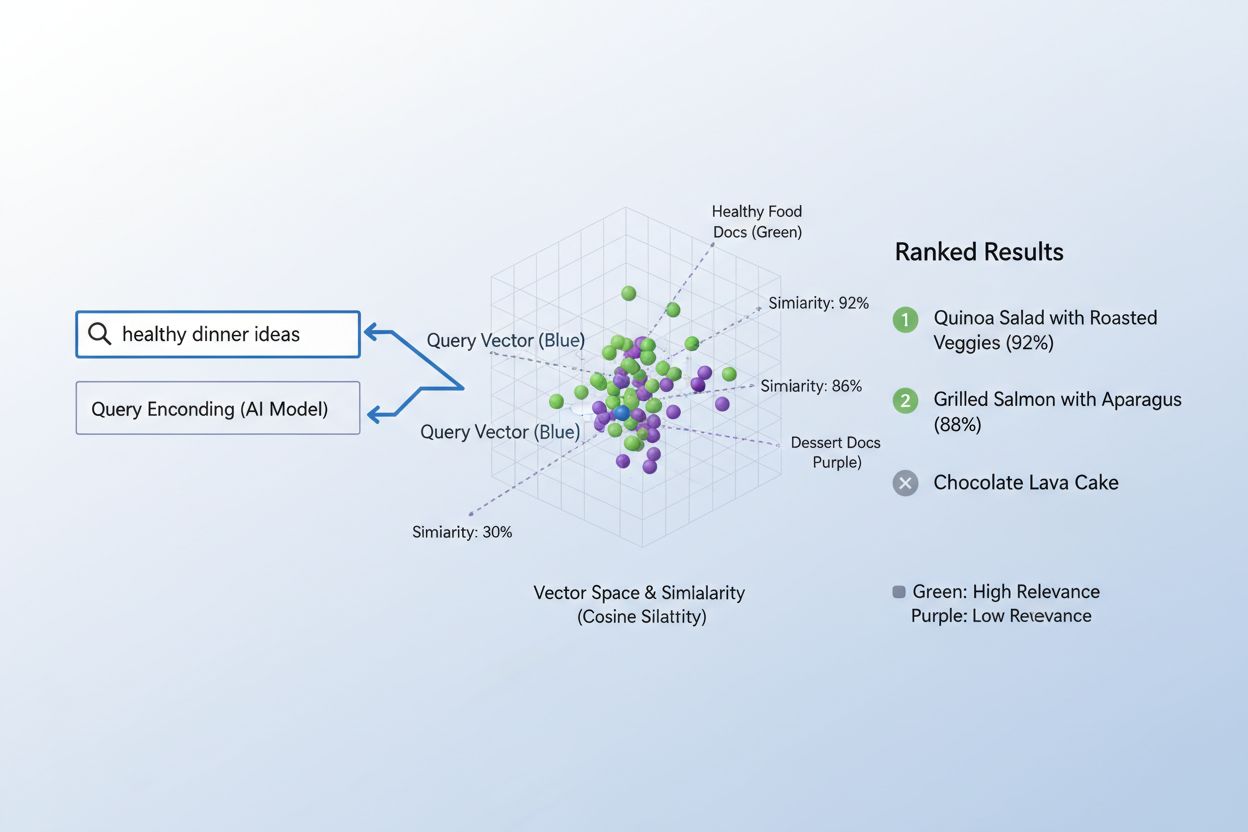
Le processus de correspondance du contenu aux requêtes à l’aide des embeddings suit un flux de travail élégant en deux étapes qui alimente tout, des moteurs de recherche aux systèmes de recommandation. D’abord, la requête de l’utilisateur et le contenu disponible sont indépendamment convertis en embeddings à l’aide du même modèle — une requête comme « meilleures pratiques pour l’apprentissage automatique » devient un vecteur, tout comme chaque article, document ou produit dans la base de données du système. Ensuite, le système calcule la similarité entre l’embedding de la requête et chaque embedding de contenu, généralement à l’aide de la similarité cosinus, ce qui produit un score indiquant la pertinence de chaque contenu par rapport à la requête. Ces scores de similarité sont ensuite classés, le contenu ayant le score le plus élevé étant présenté à l’utilisateur comme les résultats les plus pertinents. Dans un scénario réel de moteur de recherche, lorsque vous recherchez « comment entraîner des réseaux neuronaux », le système encode votre requête, la compare à des millions d’embeddings de documents et retourne des articles sur le deep learning, l’optimisation de modèles et les techniques d’entraînement — le tout sans nécessiter de correspondances exactes de mots-clés. Ce processus de correspondance se déroule en quelques millisecondes, ce qui le rend pratique pour des applications en temps réel servant des millions d’utilisateurs simultanément.
Différents types d’embeddings servent à des objectifs distincts selon ce que vous souhaitez faire correspondre ou comprendre. Les embeddings de mots capturent la signification des mots individuels et conviennent aux tâches nécessitant une compréhension sémantique fine, tandis que les embeddings de phrases et embeddings de documents agrègent la signification sur des textes plus longs, ce qui les rend idéaux pour faire correspondre des requêtes entières à des articles ou documents complets. Les embeddings d’images représentent numériquement le contenu visuel, permettant aux systèmes de trouver des images visuellement similaires ou de faire correspondre des images à des descriptions textuelles, tandis que les embeddings utilisateur et embeddings de produits saisissent des schémas comportementaux et des caractéristiques, alimentant des systèmes de recommandation qui suggèrent des éléments basés sur les préférences des utilisateurs. Le choix entre ces types d’embeddings implique des compromis : les embeddings de mots sont efficaces en termes de calcul mais perdent le contexte, tandis que les embeddings de documents préservent toute la signification mais nécessitent plus de puissance de traitement. Les embeddings spécifiques à un domaine, ajustés sur des ensembles de données spécialisés comme la littérature médicale ou des documents juridiques, surpassent souvent les modèles généralistes pour des applications sectorielles, bien qu’ils exigent des données d’entraînement supplémentaires et une puissance de calcul accrue.
En pratique, les embeddings alimentent certaines des applications d’IA les plus influentes que nous utilisons au quotidien, des résultats de recherche que vous voyez aux produits qui vous sont recommandés en ligne. Les moteurs de recherche sémantique utilisent les embeddings pour comprendre l’intention des requêtes et mettre en avant le contenu pertinent quelle que soit la correspondance exacte des mots-clés, tandis que les systèmes de recommandation de Netflix, Amazon et Spotify exploitent les embeddings utilisateur et article pour prédire ce que vous voudrez regarder, acheter ou écouter ensuite. Les systèmes de modération de contenu utilisent les embeddings pour détecter le contenu nuisible en comparant les messages générés par les utilisateurs avec les embeddings d’infractions aux politiques connues, tandis que les systèmes de questions-réponses font correspondre les questions des utilisateurs à des articles pertinents de bases de connaissances en trouvant du contenu sémantiquement similaire. Les moteurs de personnalisation utilisent les embeddings pour comprendre les préférences des utilisateurs et adapter les expériences, et les systèmes de détection d’anomalies identifient des schémas inhabituels en reconnaissant quand de nouveaux points de données s’éloignent des groupes attendus d’embeddings. Chez AmICited, nous exploitons les embeddings pour surveiller comment les systèmes d’IA sont utilisés sur internet, en faisant correspondre les requêtes et le contenu afin de suivre où apparaissent les contenus générés ou assistés par l’IA, aidant les marques à comprendre leur empreinte IA et à garantir une attribution correcte.
Mettre en œuvre efficacement des embeddings nécessite une attention particulière à divers aspects techniques qui influencent à la fois les performances et le coût. Le choix du modèle est crucial — il faut équilibrer la qualité sémantique des embeddings avec les exigences computationnelles, les modèles plus volumineux comme BERT produisant des représentations plus riches mais nécessitant plus de puissance de calcul que les alternatives légères. La dimensionnalité présente un compromis clé : des embeddings à plus haute dimension capturent plus de nuances mais consomment plus de mémoire et ralentissent les calculs de similarité, tandis que des embeddings à basse dimension sont plus rapides mais peuvent perdre des informations sémantiques importantes. Pour gérer efficacement la correspondance à grande échelle, les systèmes utilisent des stratégies d’indexation spécialisées comme FAISS (Facebook AI Similarity Search) ou Annoy (Approximate Nearest Neighbors Oh Yeah), qui permettent de trouver des embeddings similaires en millisecondes plutôt qu’en secondes en organisant les vecteurs selon des structures d’arbres ou des schémas de hachage sensibles à la localité. L’ajustement des modèles d’embeddings sur des données spécifiques au domaine peut considérablement améliorer la pertinence pour des applications spécialisées, bien que cela nécessite des données d’entraînement annotées et un surcroît computationnel. Les organisations doivent continuellement arbitrer entre rapidité et précision, coût computationnel et qualité sémantique, et modèles généralistes et alternatives spécialisées selon leurs cas d’usage et contraintes spécifiques.
L’avenir des embeddings s’oriente vers plus de sophistication, d’efficacité et d’intégration avec des systèmes d’IA plus larges, promettant des capacités de correspondance et de compréhension de contenu toujours plus puissantes. Les embeddings multimodaux capables de traiter simultanément texte, images et audio émergent, permettant aux systèmes de faire des correspondances entre différents types de contenu — trouver des images pertinentes à partir de requêtes textuelles ou inversement — ouvrant de toutes nouvelles possibilités pour la découverte et la compréhension de contenu. Les chercheurs développent des modèles d’embeddings toujours plus efficaces qui offrent une qualité sémantique comparable avec beaucoup moins de paramètres, rendant les capacités avancées de l’IA accessibles aux petites organisations et aux dispositifs en périphérie. L’intégration des embeddings avec les grands modèles de langage crée des systèmes capables non seulement de faire des correspondances sémantiques mais aussi de comprendre le contexte, la nuance et l’intention à des niveaux jamais atteints. À mesure que les systèmes d’IA se généralisent sur internet, la capacité à suivre, surveiller et comprendre comment le contenu est associé et utilisé devient de plus en plus cruciale — c’est là qu’AmICited met à profit les embeddings pour aider les organisations à surveiller la présence de leur marque, suivre les usages de l’IA et garantir que leur contenu est correctement attribué et utilisé de façon appropriée. La convergence de meilleurs embeddings, de modèles plus efficaces et d’outils de surveillance sophistiqués dessine un avenir où les systèmes d’IA sont plus transparents, responsables et alignés sur les valeurs humaines.
Un embedding vectoriel est une représentation numérique de données (texte, images, audio) dans un espace à haute dimension qui capture la signification sémantique et les relations. Il convertit des données abstraites en tableaux de nombres que les machines peuvent traiter et analyser mathématiquement.
Les embeddings convertissent des données abstraites en nombres que les machines peuvent traiter, permettant à l’IA d’identifier des motifs, des similarités et des relations entre différents contenus. Cette représentation mathématique permet aux systèmes d’IA de comprendre la signification plutôt que de simplement faire correspondre des mots-clés.
La correspondance de mots-clés cherche des correspondances exactes de mots, tandis que la similarité sémantique comprend la signification. Cela permet aux systèmes de trouver du contenu lié même sans mots identiques — par exemple, faire correspondre « automobile » avec « voiture » sur la base d’une relation sémantique plutôt qu’une correspondance exacte de texte.
Oui, les embeddings peuvent représenter du texte, des images, de l’audio, des profils utilisateurs, des produits, et bien plus. Différents modèles d’embeddings sont optimisés pour différents types de données, de Word2Vec pour le texte aux CNN pour les images jusqu’aux spectrogrammes pour l’audio.
AmICited utilise les embeddings pour comprendre comment les systèmes d’IA font correspondre et référencent sémantiquement votre marque à travers différentes plateformes et réponses d’IA. Cela aide à suivre la présence de votre contenu dans les réponses générées par l’IA et à assurer une attribution appropriée.
Les principaux défis incluent le choix du bon modèle, la gestion des coûts computationnels, la manipulation des données à haute dimension, l’ajustement pour des domaines spécifiques, et l’équilibre entre rapidité et précision dans les calculs de similarité.
Les embeddings permettent la recherche sémantique, qui comprend l’intention de l’utilisateur et retourne des résultats pertinents basés sur la signification plutôt que sur de simples correspondances de mots-clés. Cela permet aux systèmes de recherche de trouver du contenu conceptuellement lié même s’il ne contient pas exactement les termes de la requête.
Les grands modèles de langage utilisent les embeddings en interne pour comprendre et générer du texte. Les embeddings sont fondamentaux dans la façon dont ces modèles traitent l’information, font correspondre le contenu et génèrent des réponses contextuellement appropriées.
Les embeddings vectoriels alimentent des systèmes d’IA comme ChatGPT, Perplexity et Google AI Overviews. AmICited suit comment ces systèmes citent et référencent votre contenu, vous aidant à comprendre la présence de votre marque dans les réponses générées par l’IA.
Découvrez comment fonctionnent les embeddings dans les moteurs de recherche IA et les modèles de langage. Comprenez les représentations vectorielles, la recherc...

Découvrez ce que sont les embeddings, comment ils fonctionnent et pourquoi ils sont essentiels pour les systèmes d’IA. Découvrez comment le texte se transforme ...
Découvrez comment la recherche vectorielle utilise des embeddings de machine learning pour trouver des éléments similaires en se basant sur la signification plu...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.