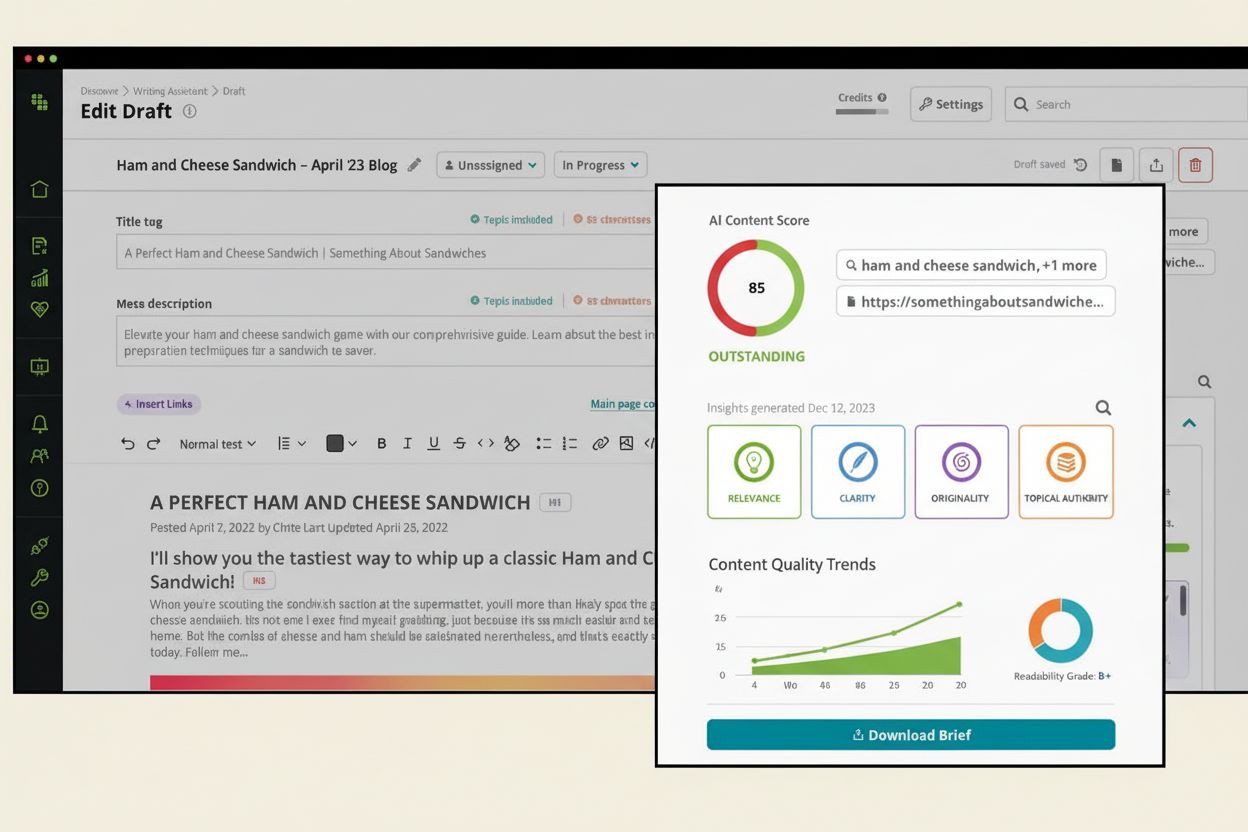
Comprendre les seuils de qualité du contenu IA
Un seuil de qualité du contenu IA est un repère ou une norme prédéfinie qui détermine si le contenu généré par l’IA répond aux critères minimaux acceptables pour la publication, la distribution ou l’utilisation dans des applications spécifiques. Ces seuils servent de mécanismes de contrôle essentiels à l’ère de l’IA générative, où les organisations doivent équilibrer la rapidité et l’efficacité de la génération automatisée de contenu avec la nécessité de préserver l’intégrité de la marque, l’exactitude et la confiance des utilisateurs. Le seuil agit comme une barrière de qualité, garantissant que seul le contenu répondant aux normes établies parvient à votre audience, que ce soit via des moteurs de réponses IA comme ChatGPT, Perplexity ou d’autres plateformes alimentées par l’IA.
Les seuils de qualité ne sont pas des chiffres arbitraires mais plutôt des repères scientifiquement fondés élaborés à partir de cadres d’évaluation qui analysent plusieurs dimensions de la performance du contenu. Ils représentent l’intersection entre métriques techniques, jugement humain et objectifs business, créant un système complet d’assurance qualité dans les écosystèmes de contenu pilotés par l’IA.
Dimensions essentielles de la qualité du contenu IA
Exactitude et véracité des faits
L’exactitude est la base de tout système de seuil de qualité. Cette dimension mesure si l’information présentée dans le contenu généré par l’IA est factuellement correcte et vérifiable à partir de sources fiables. Dans des domaines à enjeux élevés comme la santé, la finance ou le journalisme, les seuils d’exactitude sont particulièrement stricts, exigeant souvent des taux de justesse de 95 à 99 %. Le défi avec les systèmes IA est qu’ils peuvent produire des hallucinations — des informations plausibles mais entièrement inventées — rendant l’évaluation de l’exactitude cruciale.
L’évaluation de l’exactitude implique généralement de comparer les sorties IA aux données de référence, à la vérification par des experts ou à des bases de connaissances établies. Par exemple, lors de la surveillance de la présence de votre marque dans les réponses IA, les seuils d’exactitude garantissent que toute citation ou référence à votre contenu est correcte et correctement attribuée. Les organisations mettant en place des seuils de qualité fixent souvent des scores d’exactitude minimale de 85-90 % pour le contenu général et 95 % ou plus pour les domaines spécialisés.
Pertinence et alignement avec l’intention
La pertinence mesure dans quelle mesure le contenu généré par l’IA répond à l’intention réelle et à la demande de l’utilisateur. Une réponse peut être grammaticalement parfaite et factuellement correcte mais échouer si elle ne répond pas directement à la question posée. Les seuils de qualité pour la pertinence évaluent généralement si la structure, le ton et la hiérarchie de l’information correspondent à l’intention de recherche sous-jacente.
Les systèmes modernes de scoring de contenu IA analysent la pertinence sous plusieurs angles : couverture thématique (répond-elle à tous les aspects de la question ?), alignement avec le public (est-ce adapté au niveau visé ?), et adéquation avec l’étape du parcours utilisateur (correspond-elle au fait que l’utilisateur recherche, compare ou décide ?). Les seuils de pertinence vont souvent de 70 à 85 %, reconnaissant qu’une information périphérique peut être acceptable selon le contexte.
Cohérence et lisibilité
La cohérence se réfère à la qualité structurelle et au fil logique du contenu. Les systèmes IA doivent générer un texte qui s’enchaîne naturellement, avec des phrases claires, un ton cohérent et une progression logique des idées. Les métriques de lisibilité évaluent la facilité de compréhension du contenu par un humain, généralement mesurée par des scores comme Flesch-Kincaid ou Gunning Fog Index.
Les seuils de qualité pour la cohérence spécifient souvent des scores de lisibilité minimaux adaptés au public cible. Pour le grand public, un score de Flesch Reading Ease de 60-70 est typique, tandis que des publics techniques peuvent accepter des scores plus bas (40-50) si le contenu est suffisamment spécialisé. Les seuils de cohérence examinent également la structure des paragraphes, la qualité des transitions et la présence de titres et de mises en forme clairs.
Originalité et détection de plagiat
L’originalité garantit que le contenu généré par l’IA ne se contente pas de copier ou de paraphraser du matériel existant sans attribution. Cette dimension est particulièrement importante pour préserver la voix de la marque et éviter les problèmes de droits d’auteur. Les seuils de qualité exigent généralement des scores d’originalité de 85 à 95 %, c’est-à-dire que 85 à 95 % du contenu doit être unique ou largement réécrit.
Les outils de détection de plagiat mesurent le pourcentage de contenu correspondant à des sources existantes. Toutefois, les seuils doivent prendre en compte la réutilisation légitime de phrases courantes, de terminologie sectorielle et d’informations factuelles qui ne peuvent être formulées autrement. L’essentiel est de distinguer le paraphrasage acceptable de la copie problématique.
Cohérence avec la voix de la marque
La cohérence de la voix de la marque mesure si le contenu généré par l’IA respecte le ton, le style et les lignes directrices propres à votre organisation. Cette dimension est cruciale pour maintenir la reconnaissance et la confiance dans la marque à tous les points de contact, y compris les réponses générées par l’IA qui apparaissent dans les moteurs de recherche et les plateformes de réponses.
Les seuils de qualité pour la voix de marque sont souvent qualitatifs mais peuvent être opérationnalisés via des critères spécifiques : choix du vocabulaire, structures de phrases, tonalité émotionnelle et respect des principes de communication de la marque. Les organisations fixent généralement des seuils exigeant une conformité de 80 à 90 % avec les directives existantes, permettant une certaine flexibilité tout en préservant l’identité centrale.
Sécurité éthique et détection des biais
La sécurité éthique couvre plusieurs aspects : absence de stéréotypes nuisibles, de langage offensant, de présupposés biaisés et de contenu pouvant être détourné ou causer du tort. Cette dimension prend de plus en plus d’importance à mesure que les organisations reconnaissent leur responsabilité de prévenir l’amplification des biais sociétaux par l’IA ou la génération de contenu nuisible.
Les seuils de qualité pour la sécurité éthique sont souvent binaires ou quasi-binaires (95-100 % requis) car même de faibles quantités de biais ou de contenu nuisible peuvent nuire à la réputation et enfreindre des principes éthiques. Les méthodes d’évaluation incluent des outils automatisés de détection des biais, des revues humaines par des évaluateurs diversifiés et des tests sur différents contextes démographiques.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Méthodes de mesure et systèmes de scoring
Métriques automatisées et scoring
Les systèmes modernes de seuils de qualité s’appuient sur plusieurs métriques automatisées pour évaluer le contenu IA à grande échelle. Parmi elles :
| Type de métrique | Ce qu’elle mesure | Plage du seuil | Cas d’usage |
|---|
| Scores BLEU/ROUGE | Recoupement n-grammes avec texte de référence | 0,3-0,7 | Traduction automatique, résumé |
| BERTScore | Similarité sémantique via embeddings | 0,7-0,9 | Qualité générale du contenu |
| Perplexité | Confiance du modèle de langage | Plus bas est mieux | Évaluation de la fluidité |
| Scores de lisibilité | Difficulté de compréhension du texte | 60-70 (grand public) | Évaluation accessibilité |
| Détection de plagiat | Pourcentage d’originalité | 85-95 % unique | Conformité droit d’auteur |
| Scores de toxicité | Détection langage nocif | <0,1 (échelle 0-1) | Garantie de sécurité |
| Détection des biais | Évaluation stéréotypes & équité | >0,9 équité | Conformité éthique |
Ces métriques automatisées offrent une évaluation quantitative et scalable mais présentent des limites. Les métriques classiques comme BLEU et ROUGE peinent avec la nuance sémantique des sorties LLM, tandis que des métriques récentes comme BERTScore capturent mieux le sens mais peuvent manquer des problèmes qualitatifs spécifiques au domaine.
Évaluation LLM-as-a-Judge
Une approche plus sophistiquée consiste à utiliser les grands modèles de langage eux-mêmes comme évaluateurs, tirant parti de leur raisonnement avancé. Cette méthode, appelée LLM-as-a-Judge, s’appuie sur des cadres comme G-Eval et DAG (Deep Acyclic Graph) pour évaluer la qualité du contenu via des rubriques en langage naturel.
G-Eval fonctionne en générant des étapes d’évaluation par raisonnement en chaîne avant d’attribuer un score. Par exemple, évaluer la cohérence du contenu consiste à : (1) définir les critères de cohérence, (2) générer les étapes d’évaluation, (3) appliquer ces étapes au contenu, et (4) attribuer un score de 1 à 5. Cette approche atteint une meilleure corrélation avec le jugement humain (souvent 0,8-0,95 de corrélation de Spearman) comparé aux métriques traditionnelles.
L’évaluation basée sur DAG utilise des arbres de décision pilotés par le jugement LLM, où chaque nœud représente un critère d’évaluation spécifique et les branches représentent les choix. Cette méthode est particulièrement utile lorsque les seuils de qualité ont des exigences claires et déterministes (ex : « le contenu doit inclure des sections spécifiques dans le bon ordre »).
Évaluation humaine et revue experte
Malgré les progrès de l’automatisation, l’évaluation humaine demeure essentielle pour juger des aspects nuancés comme la créativité, la résonance émotionnelle et l’adéquation contextuelle. Les systèmes de seuils de qualité intègrent généralement une revue humaine à plusieurs niveaux :
- Revue experte sectorielle pour le contenu spécialisé (médical, juridique, financier)
- Évaluation par la foule pour l’appréciation générale de la qualité
- Vérification aléatoire des scores automatisés pour valider leur fiabilité
- Analyse des cas limites pour le contenu proche des seuils
Les évaluateurs humains jugent généralement le contenu à l’aide de rubriques précises et de grilles de scoring, assurant la cohérence entre évaluateurs. La fiabilité inter-évaluateurs (mesurée avec Kappa de Cohen ou Fleiss) doit dépasser 0,70 pour que les seuils de qualité soient considérés comme fiables.
Définir des seuils adaptés
Normes dépendant du contexte
Les seuils de qualité ne sont pas universels. Ils doivent être adaptés aux contextes, secteurs et cas d’usage spécifiques. Une FAQ rapide pourra naturellement obtenir un score plus bas qu’un guide complet, ce qui est parfaitement acceptable si les seuils sont bien paramétrés.
Chaque domaine impose ses propres standards :
- Santé/Médical : exactitude requise de 95-99 % ; sécurité éthique à 99 %+
- Finance/Juridique : exactitude de 90-95 % ; vérification conformité obligatoire
- Actualité/Journalisme : exactitude de 90-95 % ; attribution des sources exigée
- Marketing/Création : exactitude de 75-85 % acceptable ; voix de marque 85 %+
- Documentation technique : exactitude 95 %+ ; clarté et structure essentielles
- Information générale : exactitude 80-85 % ; pertinence 75-80 %
La règle des 5 métriques
Plutôt que de suivre des dizaines de métriques, les systèmes de seuils efficaces se concentrent généralement sur 5 métriques principales : 1 à 2 métriques personnalisées selon votre cas d’usage et 3 à 4 métriques génériques alignées avec votre architecture de contenu. Cette approche équilibre exhaustivité et simplicité.
Par exemple, un système de surveillance de la marque dans les réponses IA pourra utiliser :
- Exactitude (personnalisé) : véracité des mentions de la marque (seuil : 90 %)
- Qualité d’attribution (personnalisé) : citation correcte des sources (seuil : 95 %)
- Pertinence (générique) : contenu répond à l’intention utilisateur (seuil : 80 %)
- Cohérence (générique) : texte logique et fluide (seuil : 75 %)
- Sécurité éthique (générique) : absence de stéréotypes nuisibles (seuil : 99 %)
Plages de seuils et flexibilité
Les seuils de qualité opèrent généralement sur une échelle de 0 à 100, mais leur interprétation demande de la nuance. Un score de 78 n’est pas intrinsèquement « mauvais » — tout dépend de vos standards et du contexte. Les organisations établissent souvent des plages de seuils plutôt que des coupures fixes :
- Publication immédiate : 85-100 (toutes les normes de qualité sont atteintes)
- Révision et publication potentielle : 70-84 (acceptable avec révisions mineures)
- Révision importante requise : 50-69 (problèmes fondamentaux présents)
- Rejet et régénération : 0-49 (ne répond pas aux critères minimaux)
Ces plages permettent une gouvernance flexible tout en maintenant les standards. Certaines organisations fixent un seuil minimal de 80 avant publication, d’autres utilisent 70 comme base pour une révision, selon l’appétence au risque et le type de contenu.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Surveiller la qualité du contenu IA dans les moteurs de réponses
Pourquoi les seuils comptent pour la surveillance de marque
Lorsque votre marque, domaine ou URL apparaît dans des réponses générées par IA comme ChatGPT, Perplexity ou plateformes similaires, les seuils de qualité sont essentiels pour la protection de la marque. Des citations de mauvaise qualité, des représentations inexactes ou un contenu mal attribué peuvent nuire à votre réputation et induire les utilisateurs en erreur.
Les seuils de qualité pour la surveillance de marque ciblent généralement :
- Exactitude des citations : votre marque/URL est-elle correctement citée ? (seuil : 95 %+)
- Adéquation contextuelle : votre contenu est-il utilisé dans un contexte pertinent ? (seuil : 85 %+)
- Clarté de l’attribution : la source est-elle clairement identifiée ? (seuil : 90 %+)
- Exactitude de l’information : les faits concernant votre marque sont-ils corrects ? (seuil : 90 %+)
- Alignement du ton : la représentation par l’IA correspond-elle à la voix de votre marque ? (seuil : 80 %+)
Mettre en place des seuils de qualité pour la surveillance IA
Les organisations mettant en place des systèmes de seuils pour la surveillance des réponses IA doivent :
- Définir des métriques de base adaptées à votre secteur et marque
- Établir des valeurs de seuil claires avec justification documentée
- Mettre en place un suivi automatisé pour contrôler les métriques en continu
- Réaliser des audits réguliers pour valider la pertinence des seuils
- Ajuster les seuils selon les données de performance et objectifs business
- Documenter tous les changements pour garantir cohérence et traçabilité
Cette approche systématique garantit que votre marque maintient ses standards de qualité sur toutes les plateformes IA où elle apparaît, protégeant votre réputation et assurant une représentation fidèle aux utilisateurs qui s’appuient sur les réponses générées par IA.
Conclusion
Un seuil de qualité du contenu IA est bien plus qu’un simple score — c’est un cadre complet garantissant que le contenu généré par l’IA répond aux standards de votre organisation en matière d’exactitude, de pertinence, de cohérence, d’originalité, d’alignement avec la marque et de sécurité éthique. En combinant métriques automatisées, évaluation par LLM et jugement humain, les organisations peuvent établir des seuils fiables qui s’adaptent à leur production de contenu tout en préservant l’intégrité qualitative. Que vous génériez du contenu en interne ou surveilliez la présence de votre marque dans les moteurs de réponses IA, comprendre et mettre en œuvre des seuils adaptés est essentiel pour maintenir la confiance, protéger votre réputation et garantir que le contenu IA sert efficacement votre audience.