Comprendre le rendu JavaScript dans les moteurs de recherche IA
Le rendu JavaScript pour l’IA fait référence à la manière dont les crawlers d’intelligence artificielle traitent et interprètent le contenu généré par JavaScript sur les sites web. Cela diffère fondamentalement de la façon dont les moteurs de recherche traditionnels comme Google gèrent le JavaScript. Alors que Google a massivement investi dans des capacités de rendu via des navigateurs Chrome sans tête, la plupart des crawlers IA, y compris GPTBot de ChatGPT, Perplexity et Claude, n’exécutent pas du tout de JavaScript. Ils ne voient que le HTML brut initialement servi lors du chargement d’une page. Cette distinction cruciale signifie que tout contenu injecté ou rendu dynamiquement via JavaScript devient totalement invisible pour les moteurs de recherche IA et les générateurs de réponses, ce qui peut coûter une visibilité significative à votre site dans les résultats de recherche alimentés par l’IA.
L’importance de comprendre le rendu JavaScript pour l’IA a augmenté de façon exponentielle, car les outils de recherche pilotés par l’IA deviennent des canaux de découverte principaux pour les utilisateurs. Lorsque les crawlers IA ne peuvent pas accéder à votre contenu à cause des limitations de rendu JavaScript, votre site devient effectivement invisible pour ces plateformes émergentes. Cela crée un déficit de visibilité où votre marque, vos produits et services peuvent ne pas apparaître dans les réponses générées par l’IA, même s’ils sont très pertinents pour les requêtes des utilisateurs. Le problème est particulièrement aigu pour les applications web modernes construites avec des frameworks comme React, Vue ou Angular qui reposent fortement sur le rendu côté client pour afficher le contenu.
La différence fondamentale entre la gestion du JavaScript par les crawlers IA et par Google provient de leurs approches architecturales et de leurs contraintes de ressources. Googlebot fonctionne grâce à un système sophistiqué de rendu en deux vagues conçu pour gérer la complexité des applications web modernes. Lors de la première vague, Googlebot récupère le HTML brut et les ressources statiques sans exécuter de scripts. Dans la seconde vague, les pages sont mises en file d’attente pour le rendu via une version sans tête de Chromium, où JavaScript est exécuté, le DOM est entièrement construit et le contenu dynamique traité. Cette approche en deux étapes permet à Google d’indexer finalement le contenu dépendant de JavaScript, même s’il peut y avoir un délai avant que ce contenu n’apparaisse dans les résultats de recherche.
En contraste frappant, les crawlers IA comme GPTBot, ChatGPT-User et OAI-SearchBot fonctionnent avec des contraintes de ressources significatives et des délais très courts de seulement 1 à 5 secondes. Ces crawlers récupèrent la réponse HTML initiale et en extraient le contenu textuel sans attendre ou exécuter de JavaScript. Selon la documentation d’OpenAI et de multiples analyses techniques, ces crawlers ne lancent pas les fichiers JavaScript, même s’ils peuvent les télécharger. Cela signifie que tout contenu chargé dynamiquement via le rendu côté client — tels que les listes de produits, prix, avis ou éléments interactifs — reste complètement caché aux systèmes IA. Cette différence architecturale reflète des priorités distinctes : Google privilégie une indexation exhaustive de tout le contenu, tandis que les crawlers IA privilégient la vitesse et l’efficacité pour collecter des données d’entraînement et des informations en temps réel.
| Fonctionnalité | Crawler Google | Crawlers IA (ChatGPT, Perplexity, Claude) |
|---|
| Exécution JavaScript | Oui, avec Chrome sans tête | Non, HTML statique uniquement |
| Capacité de rendu | Rendu complet du DOM | Extraction de texte depuis le HTML brut |
| Temps de traitement | Plusieurs vagues, peut attendre | Délai de 1 à 5 secondes |
| Visibilité du contenu | Contenu dynamique indexé au final | Seul le contenu HTML initial visible |
| Fréquence de crawl | Régulière, basée sur l’autorité | Peu fréquent, sélectif, guidé par la qualité |
| Objectif principal | Classement et indexation de recherche | Données d’entraînement et réponses en temps réel |
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Quel contenu devient invisible pour les crawlers IA
Lorsque votre site dépend de JavaScript pour afficher du contenu, plusieurs éléments essentiels deviennent totalement invisibles pour les crawlers IA. Les informations produits dynamiques comme les prix, disponibilités, variantes et promotions chargées via des API JavaScript ne sont pas vues par les systèmes IA. C’est particulièrement problématique pour les sites e-commerce où les détails produits sont récupérés des systèmes backend après le chargement de la page. Le contenu lazy-loadé comme les images, avis clients, témoignages et commentaires qui n’apparaissent qu’au défilement ou à l’interaction de l’utilisateur sont aussi ignorés par les crawlers IA. Ceux-ci ne simulent pas l’interaction utilisateur comme le scroll ou le clic, donc tout contenu caché derrière ces actions reste inaccessible.
Les éléments interactifs comme les carrousels, onglets, modales, sliders et sections extensibles nécessitant JavaScript pour fonctionner sont invisibles pour les systèmes IA. Si vos informations clés sont dissimulées derrière un onglet qu’il faut cliquer pour révéler, les crawlers IA ne verront jamais ce contenu. Le texte rendu côté client dans les applications monopages (SPA) construites avec React, Vue ou Angular aboutit souvent à ce que les crawlers IA reçoivent une page vide ou un squelette de HTML au lieu du contenu entièrement affiché. En effet, ces frameworks envoient typiquement un HTML minimal au début et remplissent la page via JavaScript après chargement. De plus, le contenu derrière des murs de connexion, paywalls ou des mécanismes anti-bots n’est pas accessible aux crawlers IA, même si ce contenu serait utile pour des réponses générées par IA.
L’impact business des problèmes de rendu JavaScript
L’incapacité des crawlers IA à accéder au contenu rendu par JavaScript a des implications business importantes dans de nombreux secteurs. Pour les entreprises e-commerce, cela signifie que les listes de produits, informations de prix, disponibilité et offres promotionnelles peuvent ne pas apparaître dans les assistants d’achat IA ou les moteurs de réponses. Lorsque les utilisateurs demandent à des IA comme ChatGPT des recommandations de produits ou des informations de prix, vos produits peuvent être totalement absents si leur affichage dépend du rendu JavaScript. Cela a un impact direct sur la visibilité, le trafic et les opportunités de vente dans un univers de découverte de plus en plus piloté par l’IA.
Les entreprises SaaS et plateformes logicielles utilisant des interfaces riches en JavaScript font face aux mêmes défis. Si les fonctionnalités de vos services, vos niveaux de tarification ou les descriptions de vos fonctions clés sont chargés dynamiquement via JavaScript, les crawlers IA ne les verront pas. Cela signifie que lorsqu’un prospect interroge une IA sur votre solution, elle peut fournir une information incomplète, erronée, voire aucune information. Les sites à contenu important avec des informations fréquemment mises à jour, comme les sites d’actualités, blogs avec éléments dynamiques ou bases de connaissance interactives, souffrent également d’une visibilité réduite côté IA. La généralisation des IA Overviews dans les résultats de recherche — présents désormais sur plus de 54% des requêtes — fait que l’invisibilité pour les crawlers IA impacte directement la capacité à être cité et recommandé par ces systèmes.
L’impact financier va au-delà de la simple perte de trafic. Si les systèmes IA n’accèdent pas à vos informations produit, tarifs ou différenciateurs clés, les utilisateurs risquent de recevoir une information incomplète ou trompeuse sur vos offres. Cela peut nuire à la confiance et à la crédibilité de la marque. De plus, à mesure que la découverte alimentée par l’IA devient centrale dans l’acquisition client, les sites n’optimisant pas l’accessibilité pour les crawlers IA perdront du terrain face à la concurrence ayant relevé ces défis techniques.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Solutions pour rendre le contenu JavaScript accessible aux crawlers IA
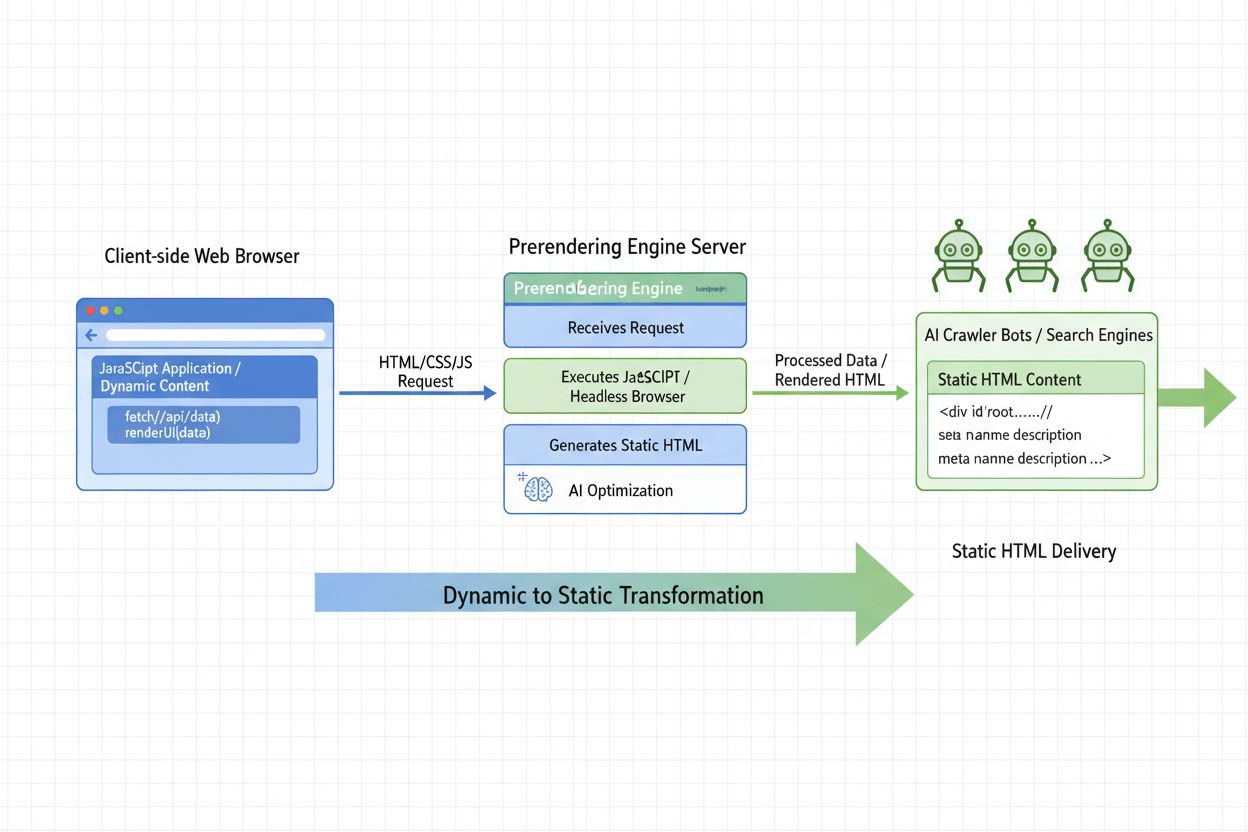
Le rendu côté serveur (SSR) est l’une des solutions les plus efficaces pour rendre le contenu JavaScript accessible aux crawlers IA. Avec le SSR, votre application exécute JavaScript sur le serveur et délivre une page HTML entièrement rendue au client. Les frameworks comme Next.js et Nuxt.js prennent en charge le SSR par défaut, vous permettant de rendre des applications React et Vue côté serveur. Lorsqu’un crawler IA demande votre page, il reçoit un HTML complet avec tout le contenu déjà rendu, rendant tout visible. L’avantage du SSR est que les utilisateurs comme les crawlers voient le même contenu complet sans dépendre de l’exécution JavaScript côté client. Cependant, le SSR demande plus de ressources serveur et une maintenance continue par rapport au rendu côté client.
La génération de site statique (SSG) ou le pré-rendu est une autre approche puissante, particulièrement pour les sites dont le contenu change peu. Cette technique consiste à construire des fichiers HTML entièrement rendus lors du déploiement, créant des snapshots statiques de vos pages. Des outils comme Next.js, Astro, Hugo et Gatsby permettent la génération statique et produisent des fichiers HTML statiques pour toutes vos pages à la compilation. Lorsque les crawlers IA visitent votre site, ils reçoivent ces fichiers pré-rendus avec tout le contenu en place. Cette approche est idéale pour les blogs, sites de documentation, pages produits à contenu stable et sites marketing. L’avantage est que les fichiers statiques sont très rapides à servir et requièrent peu de ressources serveur.
L’hydratation représente une approche hybride combinant les avantages du SSR et du rendu côté client. Avec l’hydratation, votre application est d’abord pré-rendue côté serveur puis envoyée en HTML complet au client. Le JavaScript « hydrate » ensuite la page dans le navigateur, ajoutant interactivité et fonctionnalités dynamiques sans nécessiter un nouveau rendu du contenu initial. Ainsi, les crawlers IA voient le HTML complet tandis que les utilisateurs bénéficient de fonctionnalités interactives. Des frameworks comme Next.js supportent l’hydratation par défaut, en faisant une solution adaptée aux applications web modernes.
Les services de pré-rendu comme Prerender.io offrent une autre solution en générant des snapshots HTML entièrement rendus de vos pages avant que les crawlers ne les demandent. Ces services rendent automatiquement vos pages riches en JavaScript et en mettent le résultat en cache, servant la version pré-rendue aux crawlers IA tout en servant la version dynamique aux utilisateurs classiques. Cette approche requiert peu de modifications à votre architecture existante et peut être mise en œuvre sans changer le code de votre application. Le service intercepte les requêtes des crawlers IA connus et leur sert la version pré-rendue, assurant une visibilité complète tout en maintenant l’expérience dynamique pour vos utilisateurs.
Bonnes pratiques pour optimiser le contenu JavaScript pour la visibilité IA
Pour garantir la visibilité de votre site auprès des crawlers IA, commencez par auditer votre contenu riche en JavaScript afin d’identifier quelles parties de votre site se chargent de façon dynamique. Utilisez des outils comme SEO Spider de Screaming Frog en mode « Texte seul », Oncrawl ou les outils développeur de Chrome pour visualiser le code source de vos pages et repérer le contenu qui n’apparaît qu’après exécution de JavaScript. Cherchez les descriptions produits manquantes, le balisage schema, le contenu de blog ou toute information critique absente du HTML brut. Cet audit vous aidera à prioriser les pages à optimiser.
Priorisez le contenu critique dans votre HTML en veillant à ce que les informations clés — titres, détails produits, prix, descriptions, liens internes — soient présentes dès la réponse HTML initiale. Évitez de cacher des contenus importants derrière des onglets, modales ou des mécanismes de lazy-loading nécessitant JavaScript pour s’afficher. Si vous devez utiliser des éléments interactifs, assurez-vous que les informations principales soient accessibles sans interaction. Implémentez un balisage sémantique structuré via le vocabulaire schema.org pour aider les crawlers IA à mieux comprendre votre contenu. Placez les balises schema pour produits, articles, organisations et autres entités pertinentes directement dans votre HTML, et non dans du contenu injecté par JavaScript.
Testez votre site tel que le voient les crawlers IA en désactivant JavaScript dans votre navigateur ou en utilisant la commande curl -s https://votredomaine.com | less pour voir le HTML brut. Si votre contenu principal n’est pas visible ainsi, les crawlers IA ne le verront pas non plus. Minimisez le rendu côté client pour le contenu critique et privilégiez le rendu côté serveur ou la génération statique pour les pages devant être visibles par les crawlers IA. Pour les sites e-commerce, assurez-vous que les informations produits, prix et disponibilité soient présentes dans le HTML initial et non chargées dynamiquement. Évitez les mécanismes anti-bots tels que des limites de taux agressives, des CAPTCHA ou de la détection de bots basée sur JavaScript qui pourraient empêcher les crawlers IA d’accéder à votre contenu.
L’avenir du rendu JavaScript dans la recherche IA
Le paysage du rendu JavaScript pour l’IA évolue rapidement. Le navigateur Comet d’OpenAI (utilisé par ChatGPT) et le navigateur Atlas de Perplexity représentent des évolutions potentielles dans la manière dont les systèmes IA traitent le contenu web. Les premiers indices laissent penser que ces navigateurs pourraient intégrer des capacités de rendu se rapprochant davantage de l’expérience utilisateur humaine, incluant potentiellement un rendu en cache ou partiel des pages basées sur JavaScript. Cependant, les détails restent limités et ces technologies pourraient n’offrir qu’un compromis entre le scraping HTML brut et un rendu complet sans tête, plutôt qu’un vrai support de l’exécution JavaScript.
À mesure que la recherche et la découverte pilotées par l’IA prennent de l’importance, la pression sur les plateformes IA pour améliorer leurs capacités de crawl et de rendu va probablement augmenter. Cependant, miser sur de futures améliorations reste risqué. L’approche la plus sûre consiste à optimiser dès maintenant votre site pour que le contenu clé soit accessible en HTML statique, quelle que soit la façon dont il est rendu pour les utilisateurs. Cela anticipe sur les limites actuelles des crawlers IA et assure la compatibilité avec les futures méthodes de rendu qui seront adoptées. En mettant en œuvre dès aujourd’hui le rendu côté serveur, la génération statique ou le pré-rendu, vous garantissez la visibilité de votre contenu pour les systèmes IA présents et à venir.