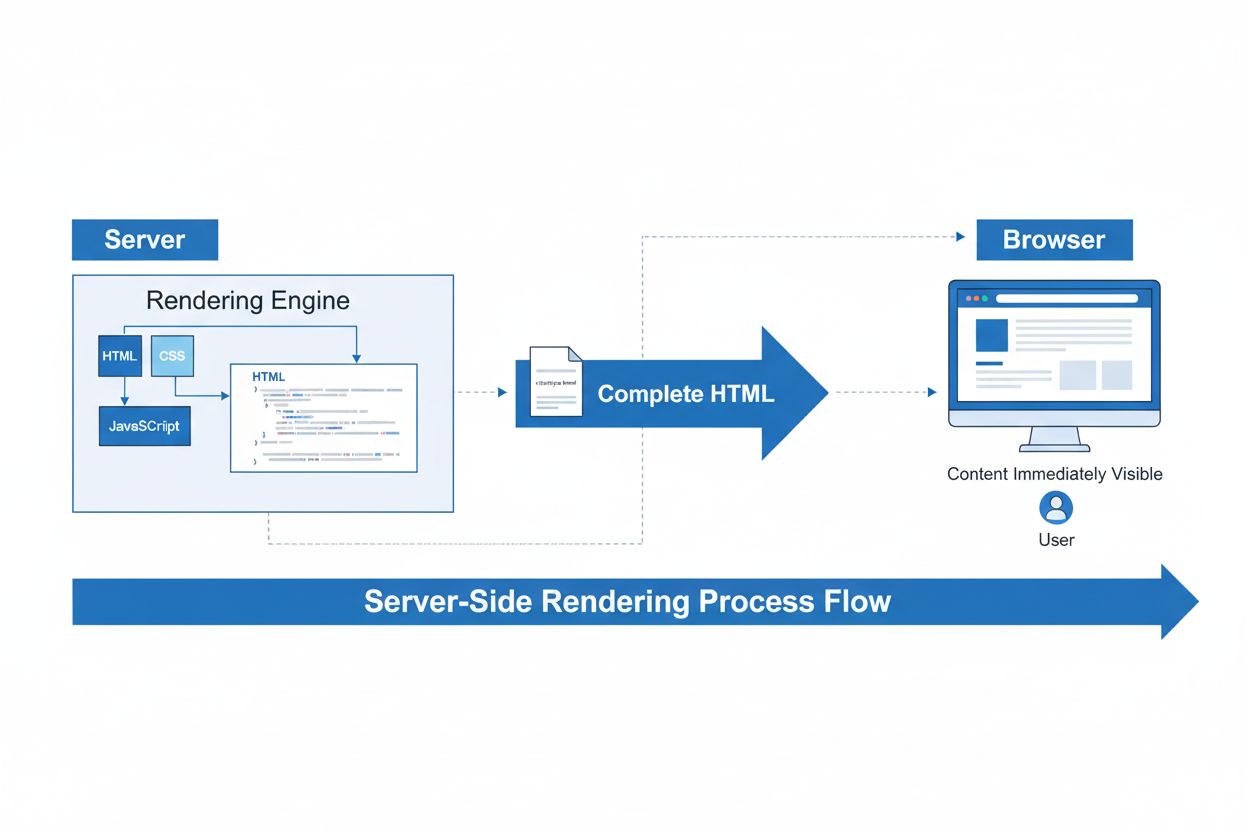
Rendu côté serveur (SSR)
Le rendu côté serveur (SSR) est une technique web où les serveurs rendent des pages HTML complètes avant de les envoyer aux navigateurs. Découvrez comment le SS...
14 min de lecture

Découvrez comment le rendu côté serveur permet un traitement efficace de l’IA, le déploiement de modèles et l’inférence en temps réel pour des applications alimentées par l’IA et des charges de travail LLM.
Le rendu côté serveur pour l'IA est une approche architecturale où les modèles d'intelligence artificielle et le traitement d'inférence s'effectuent sur le serveur plutôt que sur les appareils clients. Cela permet de gérer efficacement les tâches d'IA intensives en calcul, d'assurer des performances constantes pour tous les utilisateurs et de simplifier le déploiement et la mise à jour des modèles.
Le rendu côté serveur pour l’IA fait référence à un modèle architectural où les modèles d’intelligence artificielle, le traitement d’inférence et les tâches computationnelles s’exécutent sur des serveurs backend plutôt que sur les appareils clients comme les navigateurs ou les téléphones portables. Cette approche diffère fondamentalement du rendu traditionnel côté client, où JavaScript s’exécute dans le navigateur de l’utilisateur pour générer du contenu. Dans les applications IA, le rendu côté serveur signifie que les grands modèles de langage (LLM), l’inférence d’apprentissage automatique et la génération de contenu pilotée par l’IA se produisent de manière centralisée sur une infrastructure serveur puissante avant que les résultats ne soient envoyés aux utilisateurs. Ce changement architectural est devenu de plus en plus important à mesure que les capacités de l’IA sont devenues plus exigeantes en calcul et centrales dans les applications web modernes.
Le concept est né de la reconnaissance d’un décalage critique entre ce que les applications IA modernes exigent et ce que les appareils clients peuvent réellement fournir. Les frameworks de développement web traditionnels comme React, Angular et Vue.js ont popularisé le rendu côté client tout au long des années 2010, mais cette approche crée des défis majeurs lorsqu’elle est appliquée à des charges de travail intensives en IA. Le rendu côté serveur pour l’IA répond à ces défis en tirant parti de matériel spécialisé, d’une gestion centralisée des modèles et d’une infrastructure optimisée que les appareils clients ne peuvent tout simplement pas égaler. Cela représente un changement de paradigme fondamental dans la manière dont les développeurs architecturent les applications alimentées par l’IA.
Les exigences computationnelles des systèmes IA modernes rendent le rendu côté serveur non seulement bénéfique mais souvent nécessaire. Les appareils clients, en particulier les smartphones et les ordinateurs portables d’entrée de gamme, manquent de la puissance de traitement nécessaire pour gérer efficacement l’inférence IA en temps réel. Lorsque les modèles d’IA s’exécutent sur les appareils clients, les utilisateurs subissent des délais perceptibles, une décharge accrue de la batterie et des performances incohérentes selon les capacités de leur matériel. Le rendu côté serveur élimine ces problèmes en centralisant le traitement IA sur une infrastructure équipée de GPU, TPU et accélérateurs IA spécialisés qui offrent des performances nettement supérieures à celles des appareils grand public.
Au-delà des performances, le rendu côté serveur pour l’IA apporte des avantages essentiels en matière de gestion des modèles, de sécurité et de cohérence. Lorsque les modèles d’IA s’exécutent sur des serveurs, les développeurs peuvent les mettre à jour, les affiner et déployer de nouvelles versions instantanément sans que les utilisateurs aient à télécharger des mises à jour ou à gérer différents modèles localement. C’est particulièrement important pour les grands modèles de langage et les systèmes d’apprentissage automatique qui évoluent rapidement avec des améliorations fréquentes et des correctifs de sécurité. De plus, garder les modèles IA sur les serveurs empêche les accès non autorisés, l’extraction de modèles et le vol de propriété intellectuelle qui deviennent possibles lorsque les modèles sont distribués aux appareils clients.
| Aspect | IA côté client | IA côté serveur |
|---|---|---|
| Lieu de traitement | Navigateur ou appareil de l’utilisateur | Serveurs backend |
| Exigences matérielles | Limitées aux capacités de l’appareil | GPU, TPU, accélérateurs IA spécialisés |
| Performance | Variable, dépend de l’appareil | Cohérente, optimisée |
| Mises à jour des modèles | Nécessite des téléchargements utilisateurs | Déploiement instantané |
| Sécurité | Modèles exposés à l’extraction | Modèles protégés sur les serveurs |
| Latence | Dépend de la puissance de l’appareil | Infrastructure optimisée |
| Scalabilité | Limitée par appareil | Très évolutif entre utilisateurs |
| Complexité de développement | Élevée (fragmentation des appareils) | Moindre (gestion centralisée) |
La surcharge réseau et la latence représentent des défis majeurs dans les applications IA. Les systèmes IA modernes nécessitent une communication constante avec les serveurs pour les mises à jour de modèles, la récupération de données d’entraînement et des scénarios de traitement hybride. Ironiquement, le rendu côté client augmente les requêtes réseau par rapport aux applications traditionnelles, réduisant les avantages de performance supposés du traitement côté client. Le rendu côté serveur consolide ces communications, réduisant les délais d’aller-retour et permettant aux fonctionnalités IA en temps réel comme la traduction instantanée, la génération de contenu et le traitement de vision par ordinateur de fonctionner sans les pénalités de latence de l’inférence côté client.
La complexité de synchronisation apparaît lorsque les applications IA doivent maintenir une cohérence d’état entre plusieurs services IA simultanément. Les applications modernes utilisent souvent des services d’embedding, des modèles de complétion, des modèles fine-tunés et des moteurs d’inférence spécialisés qui doivent se coordonner. Gérer cet état distribué sur les appareils clients introduit une grande complexité et engendre des risques d’incohérences de données, surtout dans les fonctionnalités collaboratives IA en temps réel. Le rendu côté serveur centralise cette gestion d’état, garantissant que tous les utilisateurs voient des résultats cohérents et éliminant la charge d’ingénierie de la synchronisation complexe côté client.
La fragmentation des appareils génère des défis de développement considérables pour l’IA côté client. Différents appareils offrent des capacités IA variées, incluant des unités de traitement neuronal, l’accélération GPU, la prise en charge de WebGL et des contraintes de mémoire. Créer des expériences IA cohérentes sur cet écosystème fragmenté nécessite un effort d’ingénierie important, des stratégies de dégradation progressive et de multiples chemins de code selon les capacités des appareils. Le rendu côté serveur élimine entièrement cette fragmentation en assurant à tous les utilisateurs un accès à la même infrastructure IA optimisée, quelle que soit la spécification de leur appareil.
Le rendu côté serveur permet des architectures d’applications IA plus simples et plus faciles à entretenir en centralisant les fonctionnalités critiques. Plutôt que de distribuer les modèles et la logique d’inférence IA sur des milliers d’appareils clients, les développeurs maintiennent une implémentation unique et optimisée sur les serveurs. Cette centralisation offre des avantages immédiats comme des cycles de déploiement plus rapides, un débogage simplifié et une optimisation des performances plus directe. Lorsqu’un modèle IA nécessite une amélioration ou lorsqu’un bug est détecté, les développeurs le corrigent une seule fois sur le serveur, au lieu de tenter de pousser des mises à jour à des millions d’appareils clients au taux d’adoption variable.
L’efficacité des ressources s’améliore considérablement avec le rendu côté serveur. L’infrastructure serveur permet un partage efficace des ressources entre tous les utilisateurs, grâce au pooling de connexions, aux stratégies de mise en cache et à l’équilibrage de charge qui optimisent l’utilisation du matériel. Un seul GPU sur un serveur peut traiter des requêtes d’inférence de milliers d’utilisateurs de façon séquentielle, alors que distribuer cette même capacité sur les appareils clients nécessiterait des millions de GPU. Cette efficacité se traduit par des coûts opérationnels réduits, un impact environnemental moindre et une meilleure évolutivité à mesure que les applications grandissent.
La sécurité et la protection de la propriété intellectuelle deviennent bien plus simples avec le rendu côté serveur. Les modèles IA représentent des investissements considérables en recherche, données d’entraînement et ressources informatiques. Garder les modèles sur les serveurs prévient les attaques d’extraction de modèles, les accès non autorisés et le vol de propriété intellectuelle qui deviennent possibles quand les modèles sont distribués aux appareils clients. De plus, le traitement côté serveur permet un contrôle d’accès granulaire, une journalisation des accès et une surveillance de la conformité impossibles à appliquer sur des appareils clients distribués.
Les frameworks modernes ont évolué pour prendre en charge efficacement le rendu côté serveur pour les charges de travail IA. Next.js est à la pointe de cette évolution avec les Server Actions qui permettent un traitement IA transparent directement depuis les composants serveur. Les développeurs peuvent appeler des API IA, traiter de grands modèles de langage et diffuser les réponses vers les clients avec un minimum de code standard. Le framework gère la complexité de la communication serveur-client, permettant aux développeurs de se concentrer sur la logique IA plutôt que sur les préoccupations d’infrastructure.
SvelteKit propose une approche axée sur la performance du rendu IA côté serveur avec ses fonctions de chargement qui s’exécutent sur le serveur avant le rendu. Cela permet le prétraitement des données IA, la génération de recommandations et la préparation de contenu enrichi par l’IA avant d’envoyer le HTML aux clients. Les applications ainsi obtenues possèdent une empreinte JavaScript minimale tout en conservant l’ensemble des capacités IA, garantissant une expérience utilisateur extrêmement rapide.
Des outils spécialisés comme le Vercel AI SDK abstraient la complexité du streaming des réponses IA, de la gestion du comptage des tokens et de la prise en charge des différents fournisseurs d’API IA. Ces outils permettent aux développeurs de bâtir des applications IA sophistiquées sans expertise poussée en infrastructure. Des options d’infrastructure telles que Vercel Edge Functions, Cloudflare Workers et AWS Lambda fournissent un traitement IA côté serveur distribué mondialement, réduisant la latence en traitant les requêtes au plus près des utilisateurs tout en maintenant une gestion centralisée des modèles.
Un rendu IA côté serveur efficace nécessite des stratégies de cache sophistiquées pour maîtriser les coûts computationnels et la latence. Le cache Redis stocke les réponses IA fréquemment demandées et les sessions utilisateurs, éliminant le traitement redondant pour des requêtes similaires. Le cache CDN distribue le contenu IA statique généré à l’échelle mondiale, assurant aux utilisateurs des réponses depuis des serveurs géographiquement proches. Les stratégies de cache en périphérie propagent le contenu traité par l’IA à travers les réseaux edge, offrant des réponses ultra-rapides tout en maintenant une gestion centralisée des modèles.
Ces approches de cache fonctionnent de concert pour créer des systèmes IA efficaces qui s’adaptent à des millions d’utilisateurs sans augmentation proportionnelle des coûts informatiques. En mettant en cache les réponses IA à plusieurs niveaux, les applications peuvent répondre à la majorité des requêtes depuis le cache et ne calculer de nouvelles réponses que pour les requêtes réellement inédites. Cela réduit considérablement les coûts d’infrastructure tout en améliorant l’expérience utilisateur grâce à des temps de réponse plus rapides.
L’évolution vers le rendu côté serveur représente une maturation des pratiques de développement web en réponse aux exigences de l’IA. À mesure que l’IA devient centrale dans les applications web, les réalités computationnelles imposent des architectures centrées sur le serveur. L’avenir repose sur des approches hybrides sophistiquées qui décident automatiquement où effectuer le rendu selon le type de contenu, les capacités de l’appareil, les conditions réseau et les besoins en traitement IA. Les frameworks enrichiront progressivement les applications de fonctionnalités IA, garantissant que le cœur de l’application fonctionne partout tout en améliorant l’expérience là où c’est possible.
Ce changement de paradigme intègre les leçons de l’ère des Single Page Application tout en relevant les défis des applications natives IA. Les outils et frameworks sont prêts pour permettre aux développeurs de tirer parti des bénéfices du rendu côté serveur à l’ère de l’IA, ouvrant la voie à la prochaine génération d’applications web intelligentes, réactives et efficaces.
Suivez comment votre domaine et votre marque apparaissent dans les réponses générées par l'IA sur ChatGPT, Perplexity et d'autres moteurs de recherche IA. Obtenez des informations en temps réel sur votre visibilité IA.
Le rendu côté serveur (SSR) est une technique web où les serveurs rendent des pages HTML complètes avant de les envoyer aux navigateurs. Découvrez comment le SS...
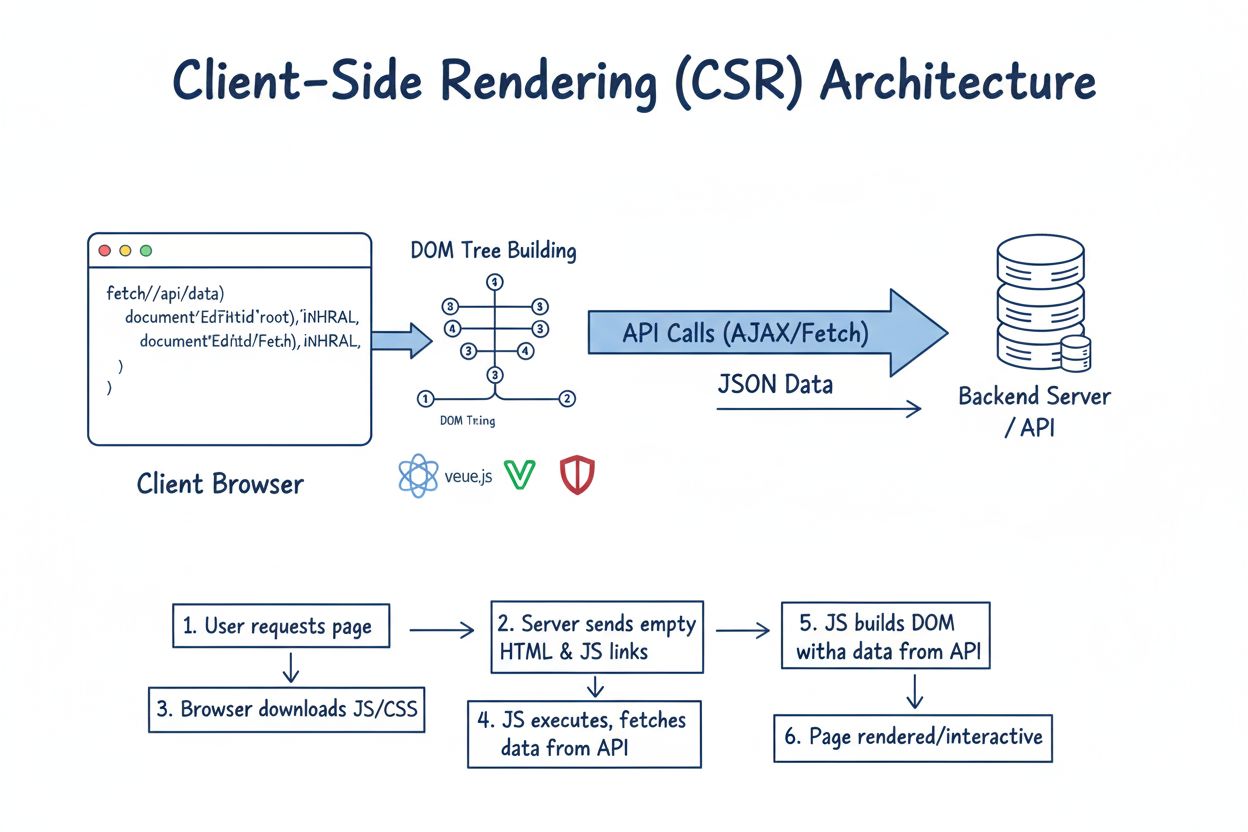
Découvrez ce qu’est le rendu côté client (CSR), comment il fonctionne, ses avantages et inconvénients, ainsi que son impact sur le SEO, l’indexation par l’IA et...
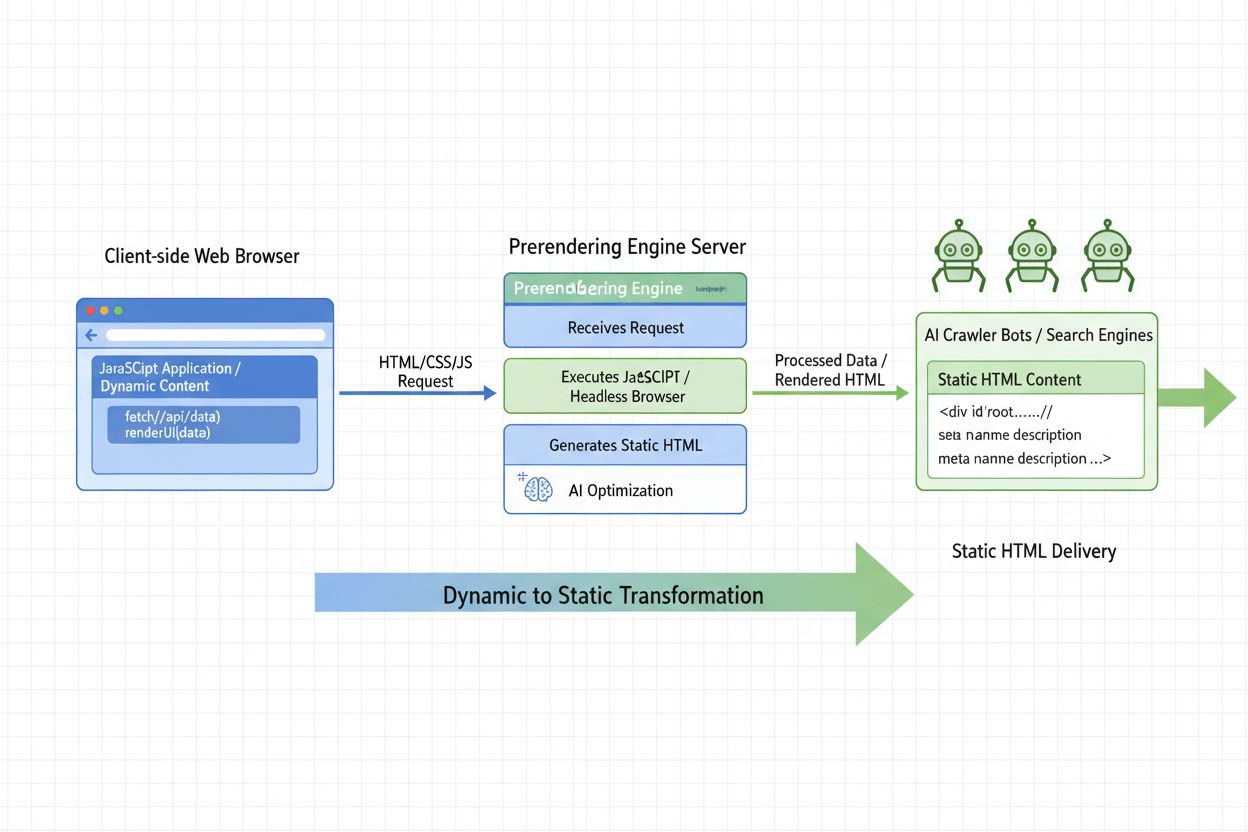
Découvrez ce qu'est le prérendu IA et comment les stratégies de rendu côté serveur optimisent la visibilité de votre site web pour les crawlers d'IA. Découvrez ...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.