Taux de crawl
Le taux de crawl est la vitesse à laquelle les moteurs de recherche explorent votre site web. Découvrez comment il affecte l’indexation, la performance SEO et c...
12 min de lecture
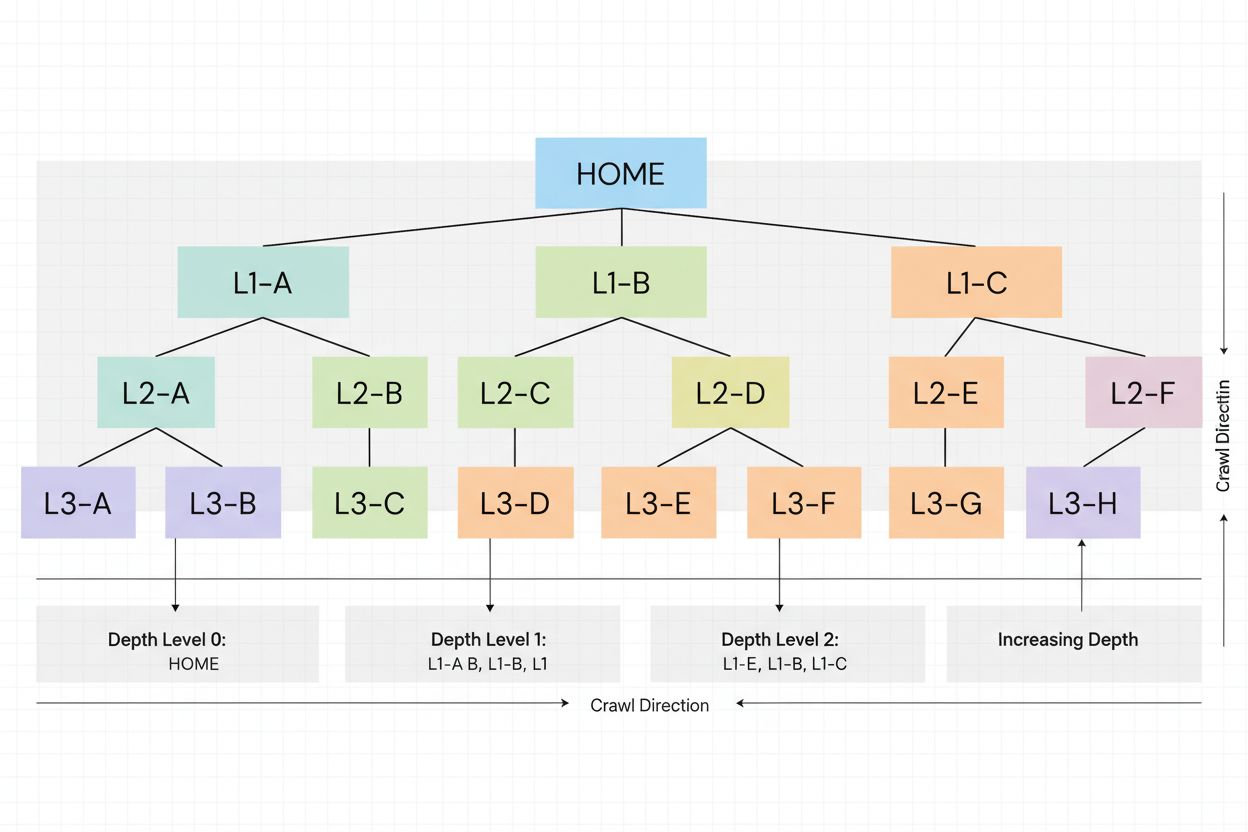
La profondeur de crawl fait référence à la distance à laquelle les robots d’exploration des moteurs de recherche peuvent atteindre dans la structure hiérarchique d’un site web lors d’une session d’exploration unique. Elle mesure le nombre de clics ou d’étapes nécessaires depuis la page d’accueil pour atteindre une page spécifique, impactant directement les pages qui seront indexées et la fréquence à laquelle elles sont explorées dans le cadre du budget de crawl alloué au site.
La profondeur de crawl fait référence à la distance à laquelle les robots d’exploration des moteurs de recherche peuvent atteindre dans la structure hiérarchique d’un site web lors d’une session d’exploration unique. Elle mesure le nombre de clics ou d’étapes nécessaires depuis la page d’accueil pour atteindre une page spécifique, impactant directement les pages qui seront indexées et la fréquence à laquelle elles sont explorées dans le cadre du budget de crawl alloué au site.
La profondeur de crawl est un concept fondamental du SEO technique qui désigne la distance à laquelle les robots d’exploration des moteurs de recherche peuvent naviguer dans la structure hiérarchique d’un site web lors d’une session d’exploration unique. Plus précisément, elle mesure le nombre de clics ou d’étapes nécessaires depuis la page d’accueil pour atteindre une page spécifique au sein de la structure de liens internes de votre site. Un site avec une profondeur de crawl élevée signifie que les robots des moteurs de recherche peuvent accéder et indexer de nombreuses pages sur l’ensemble du site, tandis qu’un site avec une profondeur de crawl faible indique que les robots risquent de ne pas atteindre les pages profondes avant d’épuiser leurs ressources allouées. Ce concept est crucial car il détermine directement quelles pages sont indexées, la fréquence à laquelle elles sont explorées, et in fine, leur visibilité dans les pages de résultats des moteurs de recherche (SERP).
L’importance de la profondeur de crawl s’est renforcée ces dernières années avec la croissance exponentielle du contenu web. L’index de Google contient plus de 400 milliards de documents et le volume croissant de contenus générés par l’IA impose aux moteurs de recherche des limitations inédites sur leurs ressources de crawl. Ainsi, les sites mal optimisés pour la profondeur de crawl risquent de voir leurs pages importantes non indexées ou peu explorées, ce qui impacte fortement leur visibilité organique. Comprendre et optimiser la profondeur de crawl est donc essentiel pour toute organisation qui souhaite maximiser sa présence sur les moteurs de recherche.
Le concept de profondeur de crawl est issu du fonctionnement des robots d’exploration des moteurs de recherche (aussi appelés spiders ou bots). Lorsque Googlebot ou d’autres robots visitent un site, ils suivent un processus systématique : ils commencent à la page d’accueil et suivent les liens internes pour découvrir d’autres pages. Le robot alloue un temps et des ressources finis à chaque site, appelé budget de crawl. Ce budget dépend de deux facteurs : la capacité de crawl (ce que le robot peut gérer sans surcharger le serveur) et la demande de crawl (l’importance et la fréquence de mise à jour du site). Plus les pages sont enfouies dans la structure du site, moins les robots ont de chances de les atteindre avant d’épuiser le budget de crawl.
Historiquement, les sites étaient relativement simples, avec la plupart des contenus importants à 2 ou 3 clics de la page d’accueil. Mais à mesure que les sites e-commerce, portails d’actualités et plateformes riches en contenu se sont développés, beaucoup d’organisations ont créé des structures très imbriquées avec des pages à 5, 6, voire 10 niveaux de profondeur. Des études de seoClarity et d’autres outils SEO montrent que les pages à une profondeur supérieure à 3 ont généralement de moins bons résultats organiques que celles proches de la page d’accueil. Cet écart s’explique car les robots privilégient les pages proches de la racine, qui accumulent aussi plus d’équité de liens (puissance de classement) via le maillage interne. Le lien entre profondeur de crawl et taux d’indexation est particulièrement marqué sur les grands sites, où le budget de crawl devient un facteur limitant.
L’émergence des moteurs de recherche IA comme Perplexity, ChatGPT et Google AI Overviews a ajouté une nouvelle dimension à l’optimisation de la profondeur de crawl. Ces systèmes IA ont leurs propres robots spécialisés (PerplexityBot, GPTBot, etc.) avec des schémas et priorités d’exploration différents des moteurs traditionnels. Mais le principe reste le même : les pages facilement accessibles et bien intégrées dans la structure du site ont plus de chances d’être découvertes, crawlées et citées comme sources dans les réponses générées par l’IA. Cela rend l’optimisation de la profondeur de crawl aussi pertinente pour le SEO traditionnel que pour la visibilité IA et la générative engine optimization (GEO).
| Concept | Définition | Perspective | Mesure | Impact SEO |
|---|---|---|---|---|
| Profondeur de crawl | Jusqu’où les robots explorent la hiérarchie du site selon les liens internes et la structure des URL | Vue du robot d’exploration | Nombre de clics/étapes depuis l’accueil | Influence la fréquence et la couverture d’indexation |
| Profondeur de clic | Nombre de clics nécessaires à un utilisateur pour atteindre une page depuis l’accueil par le chemin le plus court | Perspective utilisateur | Clics réels nécessaires | Impacte l’expérience utilisateur et la navigation |
| Profondeur de page | Position d’une page dans la hiérarchie du site | Vue structurelle | Niveau d’imbrication de l’URL | Influence la distribution de l’équité de liens |
| Budget de crawl | Ensemble des ressources (temps/bande passante) allouées à l’exploration d’un site | Allocation de ressources | Pages explorées par jour | Détermine le nombre de pages indexées |
| Efficacité du crawl | Capacité des robots à explorer et indexer efficacement le contenu du site | Vue optimisation | Pages indexées vs budget consommé | Maximise l’indexation dans les limites du budget |
Comprendre le fonctionnement de la profondeur de crawl implique d’examiner la façon dont les robots de moteurs de recherche naviguent sur les sites. Quand Googlebot ou un autre robot visite votre site, il commence à la page d’accueil (profondeur 0) et suit les liens internes pour découvrir d’autres pages. Chaque page liée depuis l’accueil est en profondeur 1, celles liées par ces pages sont en profondeur 2, etc. Le robot ne suit pas forcément un chemin linéaire : il découvre plusieurs pages à chaque niveau avant d’aller plus loin. Cependant, son exploration est limitée par le budget de crawl, qui restreint le nombre de pages visitées dans un délai donné.
Plusieurs facteurs techniques régissent la relation entre profondeur de crawl et indexation. D’abord, la priorisation du crawl est cruciale : les moteurs de recherche ne crawlent pas toutes les pages de manière égale. Ils privilégient les pages perçues comme importantes, fraîches et pertinentes. Les pages avec plus de liens internes, une autorité supérieure ou des mises à jour récentes sont crawlées plus souvent. Ensuite, la structure des URL influence la profondeur de crawl : une page à /categorie/sous-categorie/produit/ a une profondeur de crawl plus élevée qu’une page à /produit/, même si les deux sont liées depuis l’accueil. Enfin, les chaînes de redirections et liens cassés sont des obstacles qui gaspillent le budget de crawl. Une chaîne de redirections force le robot à suivre plusieurs redirections avant d’atteindre la page finale, consommant des ressources qui pourraient servir à d’autres pages.
L’optimisation technique de la profondeur de crawl repose sur plusieurs stratégies clés. L’architecture de liens internes est primordiale : en liant stratégiquement les pages importantes depuis l’accueil ou des pages à forte autorité, vous réduisez leur profondeur effective et augmentez leur fréquence d’exploration. Les sitemaps XML fournissent aux robots une cartographie directe de la structure du site, leur permettant de découvrir plus efficacement les pages sans dépendre uniquement des liens. La vitesse du site est aussi cruciale : des pages plus rapides permettent aux robots d’en explorer davantage dans le budget imparti. Enfin, le robots.txt et les balises noindex permettent de contrôler les pages à prioriser, évitant de gaspiller le budget sur des pages à faible valeur (contenus dupliqués, administration…).
Les implications pratiques de la profondeur de crawl dépassent les métriques SEO techniques : elles ont un impact direct sur les résultats business. Pour les sites e-commerce, une mauvaise optimisation de la profondeur de crawl signifie que les pages produits enfouies dans les arborescences ne seront pas indexées ou le seront rarement. Cela réduit la visibilité organique, le nombre d’impressions de produits dans les résultats de recherche, et donc les ventes. Une étude seoClarity a montré que les pages à grande profondeur de crawl ont des taux d’indexation bien inférieurs, celles en profondeur 4+ étant jusqu’à 50 % moins explorées que celles en profondeur 1 ou 2. Pour les grands distributeurs, cela peut représenter des millions d’euros de chiffre d’affaires organique perdu.
Pour les sites riches en contenu (actualités, blogs, bases de connaissances), l’optimisation de la profondeur de crawl affecte directement la découvrabilité des contenus. Les articles publiés profondément dans la structure risquent de ne jamais atteindre l’index de Google, générant ainsi zéro trafic organique, quel que soit leur intérêt. C’est particulièrement problématique pour les sites d’actualité où la fraîcheur est cruciale : si les nouveaux articles ne sont pas crawlés et indexés rapidement, ils ratent la fenêtre pour se positionner sur des sujets tendances. Les éditeurs qui optimisent la profondeur de crawl voient une nette augmentation du nombre de pages indexées et du trafic organique.
La relation entre profondeur de crawl et distribution de l’équité de liens a aussi des conséquences business. L’équité de liens (PageRank) circule via les liens internes depuis la page d’accueil. Les pages proches de l’accueil accumulent plus d’équité, augmentant leurs chances de se positionner sur des mots-clés concurrentiels. En optimisant la profondeur de crawl et en gardant les pages importantes à 2 ou 3 clics de l’accueil, les entreprises concentrent l’équité sur leurs pages les plus stratégiques (produits, services, contenus piliers), ce qui améliore considérablement leur classement.
De plus, l’optimisation de la profondeur de crawl impacte l’efficacité du budget de crawl, qui devient critique à mesure que les sites grandissent. Les sites à millions de pages font face à des contraintes sévères : en optimisant la profondeur, en éliminant les doublons, liens cassés et chaînes de redirections, ils s’assurent que les robots consacrent leur budget à du contenu de valeur, pas à des pages inutiles. C’est particulièrement vital pour les sites d’envergure et grandes plateformes e-commerce, où la gestion du budget de crawl détermine si 80 % des pages seront indexées… ou 40 %.
L’essor des moteurs de recherche IA et des systèmes génératifs IA introduit de nouveaux enjeux pour la profondeur de crawl. ChatGPT (OpenAI) utilise GPTBot pour découvrir et indexer le web. Perplexity utilise PerplexityBot, et Google AI Overviews (ex-SGE) s’appuie sur ses propres robots pour générer des synthèses. Claude (Anthropic) crawl aussi des contenus pour l’entraînement et la récupération d’information. Chacun a des schémas, priorités et contraintes différents des moteurs classiques.
La principale conclusion est que les principes de profondeur de crawl s’appliquent aussi aux moteurs IA. Les pages facilement accessibles, bien liées et structurellement mises en avant sont plus susceptibles d’être découvertes et citées dans les résultats IA. Des recherches menées par AmICited et d’autres outils montrent que les sites optimisés voient leur taux de citation augmenter dans la recherche IA, car ces systèmes privilégient les sources faisant autorité, accessibles et régulièrement mises à jour—des caractéristiques liées à une faible profondeur de crawl et un bon maillage interne.
Cependant, il existe des différences de comportement : les robots IA peuvent être plus agressifs, consommer plus de bande passante, ou accorder plus d’importance à la fraîcheur. Certains systèmes IA priorisent les contenus récents plus fortement que les moteurs classiques, rendant l’optimisation de la profondeur encore plus stratégique. De plus, certains robots IA ne respectent pas toujours les directives comme le robots.txt ou les balises noindex, même si cela évolue pour se rapprocher des standards SEO.
Pour les entreprises qui visent la visibilité IA et la GEO, optimiser la profondeur de crawl remplit un double objectif : améliorer le SEO classique et augmenter les chances que les systèmes IA découvrent, crawlent et citent vos contenus. L’optimisation de la profondeur de crawl devient ainsi une stratégie de base pour la visibilité sur tous les moteurs—classiques comme IA.
L’optimisation de la profondeur de crawl nécessite une démarche structurée, à la fois sur l’architecture et la technique. Voici les meilleures pratiques éprouvées sur des milliers de sites :
Pour les sites d’entreprise avec des milliers ou millions de pages, l’optimisation de la profondeur de crawl devient complexe et critique. L’allocation du budget de crawl est stratégique : il faut déterminer quelles pages méritent les ressources selon la valeur business. Les pages à forte valeur (produits, services, piliers) doivent rester peu profondes et très liées, tandis que les pages à faible valeur (archives, doublons, contenus « minces ») doivent être noindex ou dépriorisées.
Une autre stratégie avancée est le maillage interne dynamique : grâce à l’analyse des données, identifiez les pages nécessitant plus de liens internes pour améliorer leur profondeur. Des outils comme l’Internal Link Analysis de seoClarity repèrent les pages trop profondes ou peu liées, révélant ainsi des opportunités d’optimisation. De plus, l’analyse des logs serveurs permet de visualiser le parcours exact des robots, de détecter les goulets d’étranglement et d’améliorer la structure de crawl. Cette analyse révèle les pages crawlées de façon inefficace—et donc à rendre plus accessibles.
Pour les sites multilingues ou internationaux, l’optimisation de la profondeur de crawl est encore plus cruciale. Les balises hreflang et la structure d’URL adaptée à chaque langue impactent l’efficacité du crawl. Assurez-vous que chaque version linguistique présente une profondeur optimisée pour maximiser l’indexation dans tous les marchés. De même, l’indexation mobile-first impose d’optimiser la profondeur aussi bien sur desktop que sur mobile.
L’importance de la profondeur de crawl évolue avec les avancées technologiques. Avec la montée des moteurs IA et des systèmes génératifs, l’optimisation de la profondeur concerne un public bien plus large que les seuls professionnels SEO. À mesure que les systèmes IA se raffinent, ils pourraient développer des schémas de crawl inédits, rendant la profondeur de crawl encore plus essentielle. Par ailleurs, la multiplication des contenus générés par l’IA accentue la pression sur l’index Google, rendant la gestion du budget de crawl plus cruciale que jamais.
À l’avenir, plusieurs tendances se dessinent : d’abord, les outils d’optimisation IA du crawl gagneront en sophistication, utilisant le machine learning pour identifier les structures de profondeur optimales selon le type de site. Ensuite, le suivi en temps réel du crawl deviendra la norme, permettant aux propriétaires de sites d’ajuster immédiatement leur structure. Enfin, les métriques de profondeur de crawl seront intégrées aux plateformes SEO et analytics, facilitant la compréhension et l’optimisation pour les non-techniciens.
Le lien entre profondeur de crawl et visibilité IA deviendra un enjeu majeur pour les professionnels SEO. À mesure que l’utilisateur se tourne vers la recherche IA, il faudra optimiser non seulement pour Google, mais aussi pour la découvrabilité par l’IA. Ainsi, la profondeur de crawl s’intégrera dans une stratégie GEO globale, couvrant SEO traditionnel et visibilité IA. Les organisations qui maîtrisent tôt ce levier prendront un avantage durable dans la recherche pilotée par l’IA.
Enfin, la notion de profondeur de crawl pourrait évoluer avec les technologies de recherche. Les moteurs de demain pourraient explorer et indexer différemment, mais le principe restera : un contenu accessible et bien structuré a plus de chances d’être découvert et classé. Investir dans l’optimisation de la profondeur de crawl reste donc un pari sûr pour la visibilité sur les moteurs actuels… et futurs.
La profondeur de crawl mesure jusqu’où les robots des moteurs de recherche naviguent dans la hiérarchie de votre site en se basant sur les liens internes et la structure des URL, tandis que la profondeur de clic mesure le nombre de clics nécessaires pour qu’un utilisateur atteigne une page depuis la page d’accueil. Une page peut avoir une profondeur de clic de 1 (liée dans le pied de page) mais une profondeur de crawl de 3 (imbriquée dans la structure des URL). La profondeur de crawl est du point de vue du moteur de recherche, tandis que la profondeur de clic est du point de vue de l’utilisateur.
La profondeur de crawl n’impacte pas directement le classement, mais elle influence fortement la possibilité qu’une page soit indexée. Les pages enfouies profondément dans la structure du site sont moins susceptibles d’être explorées dans le budget de crawl alloué, ce qui signifie qu’elles risquent de ne pas être indexées ou mises à jour fréquemment. Cette réduction de l’indexation et de la fraîcheur peut nuire indirectement au classement. Les pages proches de la page d’accueil reçoivent généralement plus d’attention des robots et de l’équité de liens, leur donnant un meilleur potentiel de classement.
La plupart des experts SEO recommandent de maintenir les pages importantes à moins de 3 clics de la page d’accueil. Cela garantit qu’elles sont facilement découvrables par les moteurs de recherche et les utilisateurs. Pour les sites volumineux avec des milliers de pages, une certaine profondeur est nécessaire, mais il faut viser à garder les pages critiques aussi peu profondes que possible. Les pages au-delà de la profondeur 3 ont généralement de moins bonnes performances dans les résultats de recherche à cause d’une fréquence de crawl et d’une distribution d’équité de liens réduites.
La profondeur de crawl a un impact direct sur l’utilisation efficace de votre budget de crawl. Google alloue un budget de crawl spécifique à chaque site selon la capacité de crawl et la demande. Si votre site présente une profondeur de crawl excessive avec de nombreuses pages enfouies, les robots peuvent épuiser leur budget avant d’atteindre toutes les pages importantes. En optimisant la profondeur de crawl et en réduisant les couches inutiles, vous vous assurez que votre contenu le plus précieux soit exploré et indexé dans le budget alloué.
Oui, il est possible d’améliorer l’efficacité du crawl sans restructurer tout votre site. Le maillage interne stratégique est la méthode la plus efficace : faites des liens vers des pages profondes importantes depuis la page d’accueil, les pages de catégories ou des contenus à forte autorité. Mettre à jour régulièrement votre sitemap XML, corriger les liens cassés et réduire les chaînes de redirections aide aussi les robots à atteindre les pages plus efficacement. Ces actions améliorent la profondeur de crawl sans changement architectural.
Les moteurs de recherche IA comme Perplexity, ChatGPT et Google AI Overviews utilisent leurs propres robots spécialisés (PerplexityBot, GPTBot, etc.) qui peuvent avoir des schémas d’exploration différents de Googlebot. Ces robots IA respectent tout de même les principes de la profondeur de crawl : les pages facilement accessibles et bien liées ont plus de chances d’être découvertes et utilisées comme sources. Optimiser la profondeur de crawl bénéficie aussi bien aux moteurs de recherche traditionnels qu’aux systèmes IA, augmentant votre visibilité sur toutes les plateformes de recherche.
Des outils comme Google Search Console, Screaming Frog SEO Spider, seoClarity et Hike SEO proposent des analyses et visualisations de la profondeur de crawl. Google Search Console affiche les statistiques et la fréquence de crawl, tandis que des crawlers SEO spécialisés visualisent la structure hiérarchique de votre site et identifient les pages avec une profondeur excessive. Ces outils vous aident à repérer les opportunités d’optimisation et à suivre les améliorations de l’efficacité du crawl dans le temps.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
Le taux de crawl est la vitesse à laquelle les moteurs de recherche explorent votre site web. Découvrez comment il affecte l’indexation, la performance SEO et c...

La fréquence de crawl correspond à la fréquence à laquelle les moteurs de recherche et les crawleurs d’IA visitent votre site. Découvrez ce qui influence les ta...
Découvrez des stratégies éprouvées pour augmenter la fréquence à laquelle les crawlers IA visitent votre site web, améliorer la découvrabilité du contenu dans C...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.