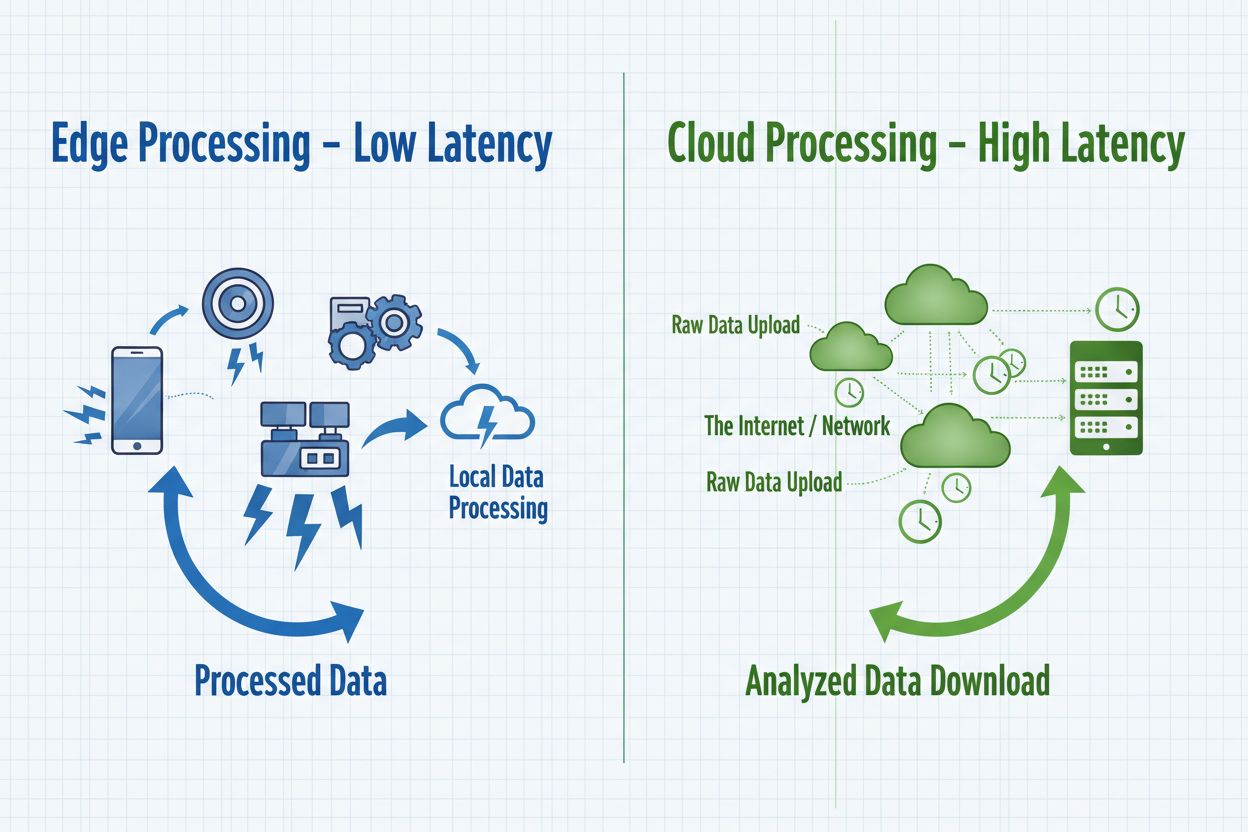
Le traitement IA en périphérie fait référence au déploiement d’algorithmes d’intelligence artificielle directement sur des appareils locaux ou des serveurs en périphérie, permettant le traitement et l’analyse des données en temps réel sans dépendance constante à l’infrastructure cloud. Cette approche réduit la latence, améliore la confidentialité des données et permet une prise de décision immédiate pour des applications telles que la surveillance de marque, les appareils IoT et les systèmes autonomes.
Traitement IA en périphérie (Edge AI Processing)
Le traitement IA en périphérie fait référence au déploiement d’algorithmes d’intelligence artificielle directement sur des appareils locaux ou des serveurs en périphérie, permettant le traitement et l’analyse des données en temps réel sans dépendance constante à l’infrastructure cloud. Cette approche réduit la latence, améliore la confidentialité des données et permet une prise de décision immédiate pour des applications telles que la surveillance de marque, les appareils IoT et les systèmes autonomes.
Définition principale et fondamentaux
Le traitement IA en périphérie représente un changement de paradigme dans le déploiement de l’intelligence artificielle, où les tâches de calcul s’exécutent directement sur des appareils en périphérie—tels que smartphones, capteurs IoT, caméras et systèmes embarqués—plutôt que de s’appuyer exclusivement sur des serveurs cloud centralisés. Cette approche traite les données à la source, permettant une analyse et une prise de décision immédiates sans transmettre d’informations brutes à des centres de données distants. Contrairement à l’IA cloud traditionnelle, qui envoie les données vers des serveurs distants pour traitement puis retourne les résultats après une latence liée au réseau, l’IA en périphérie amène l’intelligence à la frontière des réseaux, là où les données sont générées. Le traitement s’effectue sur le matériel local avec des modèles de machine learning embarqués, permettant aux appareils de fonctionner de façon autonome et de prendre des décisions en temps réel. L’Edge AI combine des réseaux neuronaux légers, des algorithmes optimisés et des accélérateurs matériels spécialisés pour fournir des capacités IA dans des environnements à ressources limitées. Ce modèle d’intelligence distribuée modifie fondamentalement la façon dont les organisations abordent la confidentialité des données, la réactivité des systèmes et les coûts d’infrastructure. En traitant localement les informations sensibles, l’Edge AI élimine la nécessité de transmettre des données potentiellement confidentielles sur les réseaux, répondant aux préoccupations croissantes sur la confidentialité dans les secteurs réglementés.
Différences clés – Edge AI vs Cloud AI
L’Edge AI et le Cloud AI représentent des approches complémentaires du déploiement de l’intelligence artificielle, chacune présentant des avantages distincts adaptés à différents cas d’usage et besoins organisationnels. Le Cloud AI excelle dans la gestion de vastes ensembles de données, l’entraînement de modèles complexes et l’exécution de tâches computationnelles intensives qui bénéficient de la puissance centralisée et de l’évolutivité illimitée. Cependant, les solutions cloud introduisent une latence inhérente lorsque les données voyagent à travers les réseaux, les rendant inadaptées aux applications nécessitant des réponses immédiates. L’Edge AI privilégie la rapidité et la réactivité en traitant l’information localement, permettant une prise de décision en dessous de la milliseconde, essentielle pour les systèmes autonomes et la surveillance en temps réel. Le choix entre ces approches dépend des besoins spécifiques : le Cloud AI convient au traitement par lots, à l’entraînement de modèles et aux applications tolérant un léger délai, tandis que l’Edge AI s’adresse aux applications en temps réel, aux opérations sensibles à la confidentialité et aux scénarios à connectivité réseau peu fiable. Les organisations adoptent de plus en plus des architectures hybrides qui combinent les deux paradigmes—utilisant les appareils en périphérie pour le traitement immédiat et l’infrastructure cloud pour l’entraînement des modèles, l’analytique et le stockage à long terme. Comprendre ces différences fondamentales aide à architecturer des solutions équilibrant performance, sécurité et efficacité opérationnelle.
Aspect
Edge AI
Cloud AI
Latence
Temps de réponse inférieurs à la milliseconde ; traitement local immédiat
50-500 ms+ dus à la transmission réseau et au traitement serveur
Bande passante
Transmission minimale de données ; traitement local
Besoin élevé en bande passante ; transmission continue de données brutes
Sécurité & Confidentialité
Données restent locales ; exposition réduite aux violations
Données transitent par les réseaux ; stockage centralisé, point de défaillance unique
Puissance de calcul
Limitée par le matériel de l’appareil ; modèles légers optimisés
Évolutivité illimitée ; gestion de modèles complexes et de vastes ensembles de données
Scalabilité
S’étend horizontalement sur des appareils distribués
S’étend verticalement avec l’infrastructure serveur ; gestion centralisée
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Les systèmes Edge AI se composent de quatre éléments techniques essentiels qui coopèrent pour fournir une intelligence en périphérie du réseau. Le moteur d’inférence exécute des modèles de machine learning pré-entraînés sur les appareils en périphérie, réalisant des prédictions et des classifications sans connexion cloud. Ces moteurs s’appuient sur des frameworks optimisés comme TensorFlow Lite, ONNX Runtime et PyTorch Mobile qui compressent les modèles pour tenir dans la mémoire de l’appareil tout en maintenant un niveau de précision satisfaisant. Les accélérateurs matériels—y compris les GPU, TPU et puces IA spécialisées—fournissent la puissance de calcul nécessaire à l’exécution efficace des réseaux neuronaux sur des appareils à ressources limitées. Les appareils de périphérie utilisent des techniques d’optimisation de modèles telles que la quantification, l’élagage et la distillation des connaissances pour réduire la taille des modèles et les besoins en calcul sans compromettre significativement la performance. La couche de gestion des données gère la collecte locale, le prétraitement et la transmission sélective des informations pertinentes vers le cloud pour agrégation et analyses à long terme. Enfin, le module de connectivité gère les connexions réseau intermittentes, permettant aux appareils de fonctionner hors ligne tout en synchronisant les données dès que la connexion est disponible.
Moteur d’inférence : Exécute localement des modèles ML pré-entraînés avec des frameworks optimisés (TensorFlow Lite, ONNX Runtime, PyTorch Mobile) pour des prédictions en temps réel sans dépendance cloud
Accélérateurs matériels : Processeurs spécialisés (GPU, TPU, puces IA) assurant l’efficacité de calcul pour l’exécution de réseaux neuronaux sur les appareils en périphérie
Optimisation des modèles : Techniques incluant quantification, élagage et distillation des connaissances pour compresser les modèles selon les contraintes de l’appareil tout en préservant la précision
Gestion des données & connectivité : Traitement local des données avec synchronisation sélective vers le cloud, permettant un fonctionnement hors ligne et une utilisation efficace de la bande passante
Recommandations de marque et surveillance en temps réel
Le traitement IA en périphérie donne des capacités inédites en matière de recommandations de marque en temps réel et de surveillance des résultats IA, répondant directement au besoin des organisations de suivre et valider les décisions IA au point d’exécution. Les applications de vente au détail exploitent l’Edge AI pour fournir instantanément des recommandations personnalisées lors de la navigation client, en analysant localement les comportements sans transmettre de données sensibles vers des serveurs externes. La surveillance en temps réel des résultats IA devient possible lorsque l’inférence s’effectue sur les appareils en périphérie, permettant de détecter immédiatement des anomalies, des prédictions biaisées ou une dérive des modèles avant que les recommandations n’atteignent les clients. Ce traitement localisé crée des pistes d’audit et des journaux de décision qui facilitent la conformité et permettent aux marques de comprendre précisément pourquoi certaines recommandations ont été faites. Les systèmes de surveillance IA en périphérie peuvent signaler des schémas suspects—comme des recommandations favorisant disproportionnellement certains produits ou groupes démographiques—permettant une intervention rapide et l’ajustement des modèles. Pour la sécurité de la marque et la gestion de la réputation, la surveillance IA en périphérie garantit que les systèmes automatisés fonctionnent dans des paramètres définis et en accord avec les valeurs de la marque avant le déploiement vers le client. La capacité de surveiller en temps réel les résultats IA à la périphérie transforme la manière dont les organisations maintiennent le contrôle qualité des décisions algorithmiques, soutenant la transparence et renforçant la confiance client grâce à une gouvernance IA vérifiable.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Avantages et bénéfices
Le traitement IA en périphérie offre des avantages significatifs sur de multiples plans pour répondre aux défis organisationnels dans les environnements numériques modernes. La réduction de la latence constitue le principal bénéfice, permettant les applications nécessitant des réponses immédiates—véhicules autonomes prenant des décisions de navigation en une fraction de seconde, robots industriels réagissant à des dangers, ou dispositifs médicaux détectant des situations critiques. La confidentialité renforcée est un second avantage, puisque les données sensibles restent sur les appareils locaux au lieu de traverser les réseaux ou d’être stockées dans le cloud, conforme au RGPD, HIPAA et à d’autres réglementations. L’optimisation de la bande passante réduit la congestion réseau et les coûts associés en traitant localement les données et en ne transmettant que les informations pertinentes au lieu des flux bruts. La fonctionnalité hors ligne permet aux appareils de continuer à fonctionner et à prendre des décisions intelligentes même en cas de perte de connexion, ce qui est essentiel pour les sites isolés et les applications critiques. La fiabilité accrue découle du traitement distribué—une panne sur un appareil n’entraîne pas l’ensemble de l’infrastructure, et le traitement local se poursuit indépendamment de la disponibilité du cloud. L’efficacité des coûts résulte de la diminution des dépenses cloud, les organisations traitant les données localement plutôt que de payer pour une infrastructure cloud continue et la transmission des données. Les avantages de scalabilité diffèrent de ceux du cloud ; l’Edge AI se déploie horizontalement sur plusieurs appareils sans nécessiter d’expansion centralisée, ce qui le rend idéal pour les déploiements IoT à grande échelle.
Applications industrielles et cas d’usage
Le traitement IA en périphérie transforme les opérations dans de nombreux secteurs en permettant la prise de décision intelligente au point de génération des données. Les usines de fabrication utilisent l’Edge AI pour la maintenance prédictive, analysant localement les vibrations et températures des équipements afin de prédire les pannes et réduire l’arrêt et les coûts de maintenance. Les prestataires de santé emploient l’Edge AI dans les dispositifs d’imagerie médicale qui réalisent une analyse préliminaire sur place, accélérant le diagnostic tout en protégeant la vie privée du patient grâce à la conservation locale des données sensibles. Le commerce de détail met en œuvre l’Edge AI pour la gestion des stocks, l’analyse du comportement client et les recommandations personnalisées instantanées sans latence cloud. Les véhicules autonomes dépendent entièrement de l’Edge AI, traitant localement les données des capteurs (caméras, lidar, radar) pour prendre des décisions de navigation et de sécurité en quelques millisecondes. Les systèmes de maison intelligente s’appuient sur l’Edge AI pour la reconnaissance vocale, la détection d’intrusions et l’automatisation des routines sans transmettre d’audio ou de vidéo au cloud. Les applications de sécurité et de surveillance utilisent l’Edge AI pour détecter des anomalies, identifier des menaces et déclencher des alertes localement, réduisant les faux positifs grâce à un filtrage intelligent avant transmission vers les centres de surveillance. L’agriculture exploite l’Edge AI sur des capteurs IoT pour surveiller l’état des sols, la météo et la santé des cultures, prenant des décisions d’irrigation et de fertilisation localement tout en minimisant les coûts de transmission dans les zones rurales à faible connectivité.
Défis et limites
Malgré ses avantages, le traitement IA en périphérie présente des défis techniques et opérationnels majeurs à prendre en compte lors de la mise en œuvre. La consommation d’énergie est une contrainte clé, car l’exécution de réseaux neuronaux sur des appareils à batterie épuise rapidement l’énergie, limitant la durée de déploiement et nécessitant une optimisation fine des modèles pour équilibrer précision et efficacité. Les limitations de calcul restreignent la complexité des modèles déployables sur les appareils en périphérie ; il faut choisir entre des modèles simplifiés moins précis ou des temps d’inférence plus longs sur un matériel limité. La gestion des modèles devient complexe dans les environnements distribués, car la mise à jour sur des milliers d’appareils exige un versioning robuste, des capacités de retour arrière et des mécanismes pour garantir la cohérence sur l’ensemble du parc. L’hétérogénéité des données pose problème lorsque les appareils fonctionnent dans des contextes variés, pouvant engendrer des performances dégradées des modèles entraînés sur des ensembles centralisés. Le débogage et la surveillance sont rendus difficiles par la nature distribuée du système, compliquant le diagnostic des pannes, la compréhension du comportement des modèles et la collecte de métriques sur des appareils dispersés. Les vulnérabilités de sécurité sur les appareils créent de nouveaux vecteurs d’attaque, car des appareils compromis pourraient exécuter du code malveillant ou manipuler les modèles locaux, nécessitant des mesures de sécurité renforcées et des mises à jour régulières. La complexité d’intégration avec l’infrastructure cloud existante demande une architecture soignée pour garantir la bonne communication entre la périphérie et les pipelines centralisés d’analyse et d’entraînement des modèles.
Edge AI et la surveillance IA
L’intersection du traitement IA en périphérie et de la surveillance IA offre de puissantes capacités aux organisations souhaitant garder le contrôle sur la prise de décision algorithmique à grande échelle. Les approches traditionnelles de surveillance IA peinent avec les systèmes cloud où la latence et les coûts de transmission limitent la visibilité en temps réel sur les résultats ; la surveillance IA en périphérie permet une analyse locale des prédictions avant qu’elles n’impactent les clients. Les systèmes de vérification des résultats déployés sur les appareils peuvent immédiatement valider les prédictions selon les règles métier, détecter les anomalies et signaler les décisions nécessitant une revue humaine avant exécution. Cette surveillance localisée répond aux enjeux de sécurité de marque en garantissant que les recommandations, décisions de contenu et interactions client générées par l’IA s’alignent sur les valeurs et exigences de conformité de l’organisation. Les systèmes de surveillance en périphérie génèrent des pistes d’audit détaillées expliquant les décisions prises, soutenant la transparence et permettant l’analyse a posteriori du comportement algorithmique. Les mécanismes de détection de biais à la périphérie peuvent identifier lorsque les modèles produisent des résultats disproportionnés selon les groupes démographiques, permettant une intervention rapide avant que des recommandations biaisées n’atteignent les clients. La combinaison Edge AI et surveillance crée une boucle de rétroaction où les journaux de décision locaux informent la ré-entrainement des modèles, assurant une amélioration continue tout en maintenant la supervision du comportement des systèmes. Les organisations qui adoptent la surveillance IA en périphérie bénéficient d’une visibilité sans précédent sur la prise de décision algorithmique, transformant l’IA en un système transparent et auditable, compatible à la fois avec l’optimisation de la performance et la gouvernance responsable de l’IA.
Tendances futures et croissance du marché
Le traitement IA en périphérie se trouve à l’avant-garde de l’évolution technologique, avec des tendances émergentes qui transforment la façon dont les organisations déploient et gèrent l’intelligence distribuée. L’apprentissage fédéré représente une approche révolutionnaire où les appareils collaborent à l’entraînement des modèles sans transmettre de données brutes vers un serveur central, permettant l’apprentissage automatique respectueux de la vie privée à grande échelle. L’expansion des réseaux 5G accélérera massivement l’adoption de l’Edge AI grâce à une connectivité fiable et à faible latence, permettant la synchronisation transparente entre la périphérie et le cloud tout en conservant les avantages du traitement local. Le développement de matériel spécialisé se poursuit, avec la création de puces IA toujours plus efficaces, optimisées pour des applications spécifiques en périphérie et améliorant le rapport performance/consommation, crucial pour les appareils sur batterie. Les prévisions de marché annoncent une croissance explosive, avec un marché mondial de l’Edge AI attendu à 15,7 milliards de dollars d’ici 2030, soit un taux de croissance annuel composé de 38,3 % entre 2023 et 2030. TinyML (apprentissage automatique sur microcontrôleurs) se profile comme une tendance majeure, apportant l’IA sur des appareils à mémoire et puissance limitées, ouvrant des cas d’usage jusqu’ici impossibles. Les technologies de conteneurisation et d’orchestration comme Kubernetes s’adaptent à la périphérie, permettant de gérer les déploiements Edge avec les mêmes outils que pour le cloud. La convergence de ces tendances laisse entrevoir un avenir où le traitement intelligent se déroule de façon fluide sur l’ensemble du réseau, les appareils en périphérie gérant les décisions en temps réel tandis que le cloud fournit l’entraînement, l’agrégation et l’analytique sur le long terme.
Considérations de mise en œuvre
Le déploiement réussi du traitement IA en périphérie requiert une planification minutieuse sur plusieurs axes afin de garantir la performance attendue et la valeur métier. Le choix du modèle est une première étape critique, nécessitant d’évaluer les modèles pré-entraînés disponibles, d’analyser leur précision sur les cas d’usage ciblés et de déterminer si un développement sur-mesure est nécessaire. Les stratégies d’optimisation doivent équilibrer précision du modèle et contraintes de l’appareil, en employant quantification, élagage et recherche d’architecture pour obtenir des modèles adaptés aux capacités matérielles tout en maintenant une performance acceptable. Le choix du matériel dépend des besoins applicatifs, de la puissance de calcul requise et des contraintes énergétiques ; il convient d’examiner les options allant des processeurs généralistes aux accélérateurs IA spécialisés. Les mécanismes de déploiement nécessitent des processus robustes pour distribuer les modèles sur les appareils, gérer les versions et permettre un retour arrière en cas de problème. Les systèmes de monitoring et d’observabilité doivent suivre la performance des modèles, détecter la dérive des données, identifier les anomalies et générer des alertes en cas de déviation. Le renforcement de la sécurité protège les appareils contre les accès non autorisés, le vol de modèles et la manipulation malveillante grâce au chiffrement, à l’authentification et à des mises à jour régulières. La planification de l’intégration garantit une communication efficace avec l’infrastructure cloud pour la mise à jour des modèles, l’analyse et le stockage des données, construisant des architectures hybrides cohérentes tirant parti des deux paradigmes. Les organisations qui déploient l’Edge AI doivent établir des indicateurs de succès clairs, piloter d’abord à petite échelle avant un déploiement massif et garder la flexibilité d’ajuster la stratégie selon les retours terrain.
Questions fréquemment posées
Quelle est la principale différence entre Edge AI et Cloud AI ?
L’Edge AI traite les données localement sur les appareils avec des temps de réponse immédiats (latence inférieure à la milliseconde), tandis que le Cloud AI envoie les données vers des serveurs distants pour traitement, introduisant ainsi des délais réseau. L’Edge AI privilégie la rapidité et la confidentialité, tandis que le Cloud AI offre une puissance de calcul illimitée pour les tâches complexes.
Comment l’Edge AI améliore-t-il la confidentialité des données ?
L’Edge AI conserve les données sensibles sur les appareils locaux plutôt que de les transmettre sur les réseaux ou de les stocker sur des serveurs cloud centralisés. Cette approche réduit l’exposition aux violations, favorise la conformité au RGPD et à la HIPAA, et garantit que les informations personnelles restent sous le contrôle de l’organisation.
Quels sont les gains typiques de latence avec l’Edge AI ?
L’Edge AI atteint des temps de réponse inférieurs à la milliseconde en traitant les données localement, contre 50 à 500 ms ou plus pour les systèmes basés sur le cloud. Cette réduction spectaculaire de latence permet des applications en temps réel comme les véhicules autonomes, la robotique industrielle et les dispositifs médicaux nécessitant une prise de décision immédiate.
L’Edge AI peut-il fonctionner sans connexion Internet ?
Oui, les systèmes Edge AI peuvent fonctionner entièrement hors ligne puisque le traitement a lieu localement sur les appareils. Cette fonctionnalité hors ligne est essentielle pour les sites isolés à connectivité peu fiable et les applications critiques où une panne de réseau ne doit pas interrompre les opérations.
Quels types d’appareils peuvent exécuter l’Edge AI ?
L’Edge AI fonctionne sur des appareils variés, notamment les smartphones, capteurs IoT, équipements industriels, caméras de sécurité, montres connectées, véhicules autonomes et systèmes embarqués. Les appareils modernes en périphérie vont des microcontrôleurs aux ressources minimales jusqu’aux ordinateurs monocarte puissants dotés d’accélérateurs IA spécialisés.
Comment l’Edge AI réduit-il les coûts de bande passante ?
L’Edge AI traite les données localement et ne transmet que les informations pertinentes au lieu des flux bruts. Cette transmission sélective réduit considérablement la consommation de bande passante, abaissant les coûts réseau et améliorant la performance du système en minimisant la transmission de données à travers les réseaux.
Quel est le lien entre Edge AI et la surveillance de marque en temps réel ?
L’Edge AI permet la surveillance en temps réel des recommandations et décisions générées par l’IA au point d’exécution, permettant aux organisations de détecter immédiatement les anomalies, de vérifier la sécurité de la marque et de s’assurer que les résultats algorithmiques sont conformes aux valeurs de l’organisation avant d’atteindre les clients.
Quels sont les principaux défis de la mise en œuvre de l’Edge AI ?
Les principaux défis incluent la consommation énergétique sur les appareils alimentés par batterie, les limitations de calcul nécessitant une optimisation des modèles, la complexité de gestion des systèmes distribués, les vulnérabilités de sécurité sur les appareils en périphérie et les difficultés d’intégration avec l’infrastructure cloud existante.
Surveillez comment l’IA mentionne votre marque en temps réel
Le traitement IA en périphérie permet l’analyse instantanée des résultats IA et des citations de marque. AmICited suit la façon dont votre marque apparaît dans les contenus générés par l’IA sur GPTs, Perplexity et Google AI Overviews avec une précision en temps réel.
Comment obtenir des recommandations locales par l’IA ? Guide complet pour 2025
Découvrez comment faire recommander votre entreprise locale par les moteurs de recherche IA comme ChatGPT, Perplexity et Google Gemini. Découvrez des stratégies...
L'essor des assistants IA spécialisés : optimisation sectorielle
Découvrez comment l'IA verticale et les assistants IA spécialisés transforment les secteurs. Apprenez-en plus sur les tendances du marché, les acteurs clés et l...
Découvrez comment le rendu côté serveur permet un traitement efficace de l'IA, le déploiement de modèles et l'inférence en temps réel pour des applications alim...
9 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.