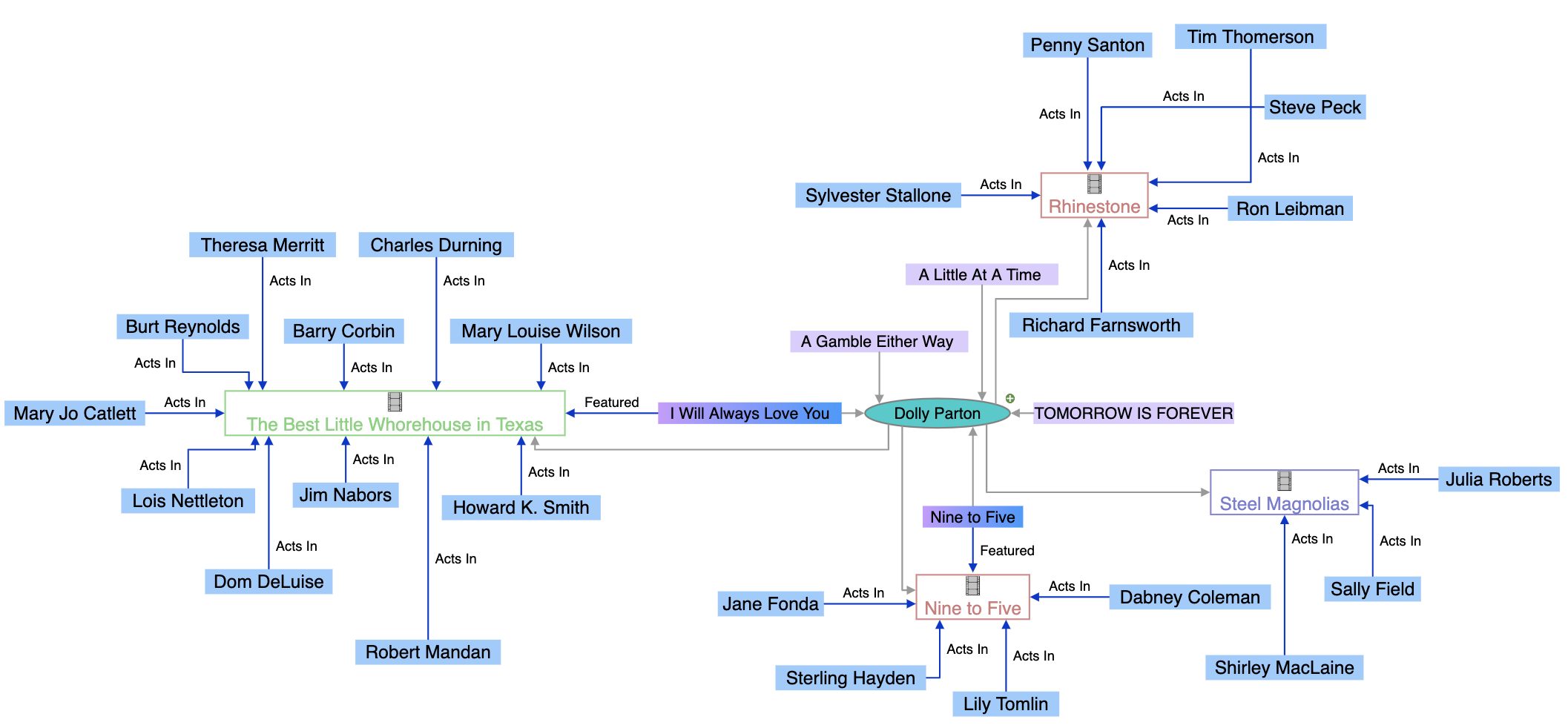
Définition du graphe de connaissances
Un graphe de connaissances est une base de données d’informations interconnectées qui représente des entités du monde réel—telles que des personnes, des lieux, des organisations et des concepts—et illustre les relations sémantiques entre elles. Contrairement aux bases de données traditionnelles qui organisent l’information dans des formats tabulaires rigides, les graphes de connaissances structurent les données comme des réseaux de nœuds (entités) et d’arêtes (relations), permettant aux systèmes de comprendre le sens et le contexte plutôt que de simplement faire correspondre des mots-clés. Le graphe de connaissances de Google, lancé en 2012, a révolutionné la recherche en introduisant une compréhension basée sur les entités, permettant au moteur de répondre à des questions factuelles telles que « Quelle est la hauteur de la tour Eiffel ? » ou « Où ont eu lieu les Jeux olympiques d’été 2016 ? » en comprenant ce que recherchent réellement les utilisateurs, et pas seulement les mots qu’ils emploient. En mai 2024, le graphe de connaissances de Google contient plus de 1,6 billion de faits sur 54 milliards d’entités, soit une expansion massive par rapport à 500 milliards de faits sur 5 milliards d’entités en 2020. Cette croissance reflète l’importance croissante des connaissances structurées et sémantiques pour alimenter la recherche moderne, les systèmes d’IA et les applications intelligentes dans tous les secteurs.
Contexte et développement historique
Le concept de graphe de connaissances est issu de décennies de recherche en intelligence artificielle, technologies du web sémantique et représentation des connaissances. Toutefois, le terme s’est largement démocratisé lorsque Google a introduit son graphe de connaissances en 2012, changeant fondamentalement la façon dont les moteurs de recherche restituent les résultats. Avant le graphe de connaissances, les moteurs de recherche utilisaient principalement la correspondance de mots-clés—si vous cherchiez « seal », Google vous proposait tous les sens possibles du mot sans savoir vraiment à quelle entité vous vouliez vous référer. Le graphe de connaissances a renversé ce paradigme en appliquant à grande échelle les principes de l’ontologie—un cadre formel pour définir les entités, leurs attributs et leurs relations. Ce passage des « chaînes de caractères aux choses » a marqué une avancée technologique majeure, permettant aux algorithmes de comprendre que « seal » peut désigner un mammifère marin, un artiste de musique, une unité militaire, ou un dispositif de sécurité, et de déterminer le sens le plus pertinent selon le contexte. Le marché mondial des graphes de connaissances reflète cette importance, avec des prévisions de croissance de 1,49 milliard de dollars en 2024 à 6,94 milliards d’ici 2030, soit un taux de croissance annuel composé d’environ 35 %. Cette croissance explosive est portée par l’adoption en entreprise dans la finance, la santé, le commerce et la gestion de la chaîne d’approvisionnement, où la compréhension des relations entre entités devient cruciale pour la prise de décision, la détection de fraude et l’efficacité opérationnelle.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Fonctionnement des graphes de connaissances : architecture technique
Les graphes de connaissances reposent sur une combinaison sophistiquée de structures de données, de technologies sémantiques et d’algorithmes d’apprentissage automatique. Au cœur du système, les graphes de connaissances utilisent un modèle de données structuré en graphe composé de trois éléments fondamentaux : les nœuds (représentant des entités comme des personnes, des organisations ou des concepts), les arêtes (représentant les relations entre entités), et les libellés (décrivant la nature de ces relations). Par exemple, dans un graphe de connaissances simple, « Seal » peut être un nœud, « est-un » un libellé d’arête, et « Artiste musical » un autre nœud, créant la relation sémantique « Seal est-un artiste musical ». Cette structure diffère fondamentalement des bases de données relationnelles, qui imposent des schémas prédéfinis en lignes et colonnes. Les graphes de connaissances sont construits soit à l’aide de graphes de propriétés étiquetées (qui stockent les propriétés directement sur les nœuds et arêtes), soit de triple stores RDF (Resource Description Framework) (qui représentent toute l’information sous forme de triplets sujet-prédicat-objet). La puissance des graphes de connaissances réside dans leur capacité à intégrer des données provenant de sources multiples aux structures et formats différents. Lorsqu’une donnée est ingérée dans un graphe de connaissances, des processus d’enrichissement sémantique exploitent le traitement du langage naturel (NLP) et l’apprentissage automatique pour identifier les entités, extraire les relations et comprendre le contexte. Cela permet aux graphes de connaissances de reconnaître automatiquement que « IBM », « International Business Machines » et « Big Blue » désignent la même entité, et de comprendre comment cette entité est reliée à d’autres comme « Watson », « Cloud Computing » et « Intelligence artificielle ». Cette structure interconnectée permet des requêtes sophistiquées et du raisonnement qui seraient impossibles dans des bases de données traditionnelles, les systèmes pouvant ainsi répondre à des questions complexes en parcourant les relations et en déduisant de nouvelles connaissances à partir des connexions existantes.
Graphe de connaissances vs bases de données traditionnelles : tableau comparatif
| Aspect | Graphe de connaissances | Base de données relationnelle traditionnelle | Base de données graphe |
|---|
| Structure des données | Nœuds, arêtes et libellés représentant entités et relations | Tables, lignes et colonnes avec schémas prédéfinis | Nœuds et arêtes optimisés pour le parcours des relations |
| Flexibilité du schéma | Très flexible ; évolue avec la découverte de nouvelles informations | Rigide ; nécessite un schéma défini avant l’entrée des données | Flexible ; prend en charge l’évolution dynamique du schéma |
| Gestion des relations | Prise en charge native des relations complexes et multi-niveaux | Nécessite des jointures entre plusieurs tables ; coûteux en calcul | Optimisé pour des requêtes de relations efficaces |
| Langage de requête | SPARQL (pour RDF), Cypher (pour graphes de propriétés), ou API personnalisées | SQL | Cypher, Gremlin ou SPARQL |
| Compréhension sémantique | Met l’accent sur le sens et le contexte via les ontologies | Se concentre sur le stockage et la récupération des données | Se concentre sur un parcours efficace et la recherche de motifs |
| Cas d’usage | Recherche sémantique, découverte de connaissances, systèmes d’IA, résolution d’entités | Transactions commerciales, reporting, systèmes OLTP | Moteurs de recommandation, détection de fraude, analyse de réseaux |
| Intégration des données | Excelle dans l’intégration de données hétérogènes de sources multiples | Requiert beaucoup d’ETL et de transformation des données | Bon pour les données connectées mais moins axé sur la sémantique |
| Scalabilité | Évolue à des milliards d’entités et de faits | Évolue bien pour des données transactionnelles structurées | Évolue bien pour les requêtes riches en relations |
| Capacités d’inférence | Raisonnement avancé et dérivation de connaissances via ontologies | Limité ; nécessite une programmation explicite | Limité ; se concentre sur la recherche de motifs |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Le rôle des graphes de connaissances dans le SEO et la visibilité dans l’IA
Les graphes de connaissances sont devenus centraux dans les stratégies SEO modernes et de visibilité dans l’IA car ils déterminent fondamentalement la façon dont l’information apparaît dans les résultats de recherche et les réponses générées par l’IA. Lorsque Google traite une requête, l’une de ses premières tâches est d’identifier l’entité recherchée, puis d’extraire de l’information pertinente du graphe de connaissances pour alimenter les fonctionnalités de la SERP. Cette approche basée sur les entités a conduit à l’émergence de la recherche sémantique—la capacité de Google à comprendre le sens et le contexte des requêtes plutôt que de simplement faire correspondre des mots-clés. Le graphe de connaissances alimente plusieurs fonctionnalités très visibles de la SERP qui impactent directement les taux de clics et la visibilité des marques. Les panneaux de connaissances apparaissent en bonne place sur ordinateur et mobile, affichant des faits sélectionnés sur l’entité recherchée issus du graphe de connaissances. Les Aperçus IA (anciennement Search Generative Experience) synthétisent de l’information depuis de multiples sources identifiées par les relations du graphe de connaissances, fournissant des réponses complètes qui relèguent souvent les résultats organiques plus bas dans la page. Les boîtes Autres questions posées exploitent les relations d’entités pour suggérer des recherches et sujets associés. Comprendre ces fonctionnalités est crucial pour les marques car elles représentent des emplacements stratégiques dans les résultats de recherche, souvent au-dessus des résultats organiques traditionnels. Pour les organisations qui surveillent leur présence dans des systèmes d’IA comme Perplexity, ChatGPT, Claude et Google AI Overviews, l’optimisation du graphe de connaissances devient essentielle. Ces systèmes d’IA s’appuient de plus en plus sur l’information structurée des entités et les relations sémantiques pour générer des réponses précises et contextuelles. Une marque ayant optimisé correctement sa présence d’entité dans les graphes de connaissances—via le balisage de données structurées, des panneaux de connaissances revendiqués et une information cohérente sur l’ensemble des sources—est plus susceptible d’apparaître dans les réponses générées par l’IA sur des sujets pertinents. À l’inverse, les marques avec des informations d’entité incomplètes ou incohérentes risquent d’être ignorées ou mal représentées dans les systèmes d’IA, impactant directement leur visibilité et leur réputation.
Sources de données et construction du graphe de connaissances
Le graphe de connaissances de Google s’appuie sur un écosystème diversifié de sources de données, chacune apportant des types d’informations différents et répondant à des usages variés. Les données ouvertes et projets communautaires comme Wikipedia et Wikidata constituent la base de la plupart des contenus du graphe. Wikipedia fournit des descriptions narratives et des informations synthétiques qui apparaissent souvent dans les panneaux de connaissances, tandis que Wikidata—base de connaissances structurée associée à Wikipedia—apporte des données d’entités et relations lisibles par machine. Google utilisait auparavant Freebase, sa propre base communautaire, mais a migré vers Wikidata après la fermeture de Freebase en 2016. Les sources de données gouvernementales fournissent des informations faisant autorité, notamment pour des requêtes factuelles. La CIA World Factbook offre des données sur les pays, zones géographiques et organisations. Data Commons, projet de données publiques structurées de Google, agrège des données d’organismes gouvernementaux ou pluri-gouvernementaux comme les Nations Unies ou l’Union européenne, fournissant statistiques et informations démographiques. Les données météo et qualité de l’air proviennent d’agences météorologiques nationales et internationales, permettant les fonctionnalités météo en temps réel de Google. Les données privées sous licence complètent le graphe avec des informations fréquemment mises à jour ou nécessitant une expertise spécialisée. Google acquiert des données de marché financier auprès de fournisseurs comme Morningstar, S&P Global ou Intercontinental Exchange pour alimenter les fonctionnalités de cours et marchés boursiers. Les données sportives proviennent de partenariats avec des ligues, équipes ou agrégateurs comme Stats Perform, fournissant scores en temps réel et statistiques historiques. Les données structurées issues des sites web contribuent significativement à l’enrichissement du graphe. Lorsque les sites utilisent le balisage Schema.org, ils fournissent une information sémantique explicite que Google peut extraire et intégrer. C’est pourquoi la mise en œuvre d’une donnée structurée adéquate—schéma Organization, LocalBusiness, FAQPage, etc.—est cruciale pour les marques souhaitant influencer leur représentation dans le graphe. Les données Google Books issues de plus de 40 millions de livres numérisés apportent contexte historique, informations biographiques et descriptions détaillées qui enrichissent la connaissance des entités. Les retours utilisateurs et panneaux de connaissances revendiqués permettent aux individus et organisations d’influencer directement les informations du graphe. Lorsque des utilisateurs soumettent des retours sur les panneaux ou que des représentants autorisés revendiquent et mettent à jour ces panneaux, ces informations peuvent être prises en compte et entraîner des mises à jour du graphe. Cette approche humaine dans la boucle garantit que le graphe reste précis et représentatif, même si ce sont les systèmes automatisés de Google qui valident in fine l’affichage.
Graphes de connaissances et E-E-A-T : construire l’autorité et la confiance
Google a explicitement déclaré qu’il privilégie les sources démontrant un haut niveau d’E-E-A-T (Expérience, Expertise, Autorité et Fiabilité) lors de la construction et la mise à jour de son graphe de connaissances. Ce lien entre E-E-A-T et inclusion dans le graphe n’est pas anodin—il reflète l’engagement de Google à mettre en avant des informations fiables et faisant autorité. Si le contenu de votre site apparaît dans les fonctionnalités de la SERP alimentées par le graphe de connaissances, c’est souvent un signal fort que Google reconnaît votre site comme source de référence sur le sujet. À l’inverse, si votre contenu n’apparaît pas dans ces fonctionnalités, cela peut révéler des problèmes d’E-E-A-T à corriger. Construire l’E-E-A-T pour la visibilité dans le graphe nécessite une approche multifacette. L’expérience implique de démontrer que vous ou vos contributeurs avez une expérience réelle du sujet. Pour un site santé, cela peut signifier mettre en avant des contenus rédigés par des professionnels médicaux diplômés. Pour une entreprise technologique, il s’agit de valoriser l’expertise d’ingénieurs ou de chercheurs à l’origine des produits évoqués. L’expertise consiste à créer un contenu pointu, complet et précis, allant au-delà de la simple vulgarisation pour démontrer une compréhension fine des nuances et concepts avancés. L’autorité se construit par la reconnaissance dans votre domaine : récompenses, certifications, citations médiatiques, interventions publiques, références par d’autres sources reconnues. Pour une organisation, cela signifie asseoir sa marque comme leader reconnu de son secteur. La fiabilité s’appuie sur les trois autres piliers et se démontre par la transparence, l’exactitude, la citation des sources, la clarté de l’auteur et un service client réactif. Les organisations qui excellent sur ces signaux E-E-A-T voient leurs informations plus souvent intégrées au graphe de connaissances et apparaître dans les réponses générées par l’IA, créant un cercle vertueux où l’autorité renforce la visibilité, qui à son tour renforce l’autorité.
Graphes de connaissances dans les systèmes d’IA et la recherche générative
L’émergence des grands modèles de langage (LLM) et de l’IA générative a donné une nouvelle importance aux graphes de connaissances dans l’écosystème de l’IA. Bien que les LLM comme ChatGPT, Claude ou Perplexity ne soient pas entraînés directement sur le graphe propriétaire de Google, ils s’appuient de plus en plus sur des connaissances structurées et une compréhension sémantique similaires. De nombreux systèmes d’IA utilisent des approches de génération augmentée par récupération (RAG), où le modèle interroge des graphes de connaissances ou bases structurées lors de l’inférence pour ancrer les réponses dans les faits et réduire les hallucinations. Des graphes publics comme Wikidata sont utilisés pour affiner les modèles ou injecter des connaissances structurées, améliorant leur capacité à comprendre les relations d’entités et à restituer une information fiable. Pour les marques et organisations, cela signifie que l’optimisation pour les graphes de connaissances a des implications au-delà de la recherche Google. Lorsque les utilisateurs interrogent des systèmes d’IA sur votre secteur, vos produits ou votre organisation, la capacité du système à fournir une information correcte dépend en partie de la qualité de la représentation de votre entité dans les sources structurées. Une organisation disposant d’une fiche Wikidata à jour, d’un panneau de connaissances Google revendiqué et de données structurées cohérentes sur son site sera mieux représentée dans les réponses générées par l’IA. À l’inverse, des organisations avec une information incomplète ou contradictoire risquent d’être mal représentées ou ignorées dans les réponses IA. Cela ouvre une nouvelle dimension de monitoring de la visibilité IA—il ne s’agit plus seulement de surveiller la place de votre marque dans les résultats de recherche, mais aussi son image dans les réponses générées par l’IA sur plusieurs plateformes. Les outils et plateformes qui surveillent la présence de marque dans les systèmes d’IA s’intéressent de plus en plus à la compréhension des relations d’entités et à la représentation dans les graphes de connaissances, reconnaissant que ces facteurs influencent directement la visibilité dans l’IA.
Mise en œuvre pratique : optimiser pour les graphes de connaissances
Les organisations souhaitant optimiser leur présence dans les graphes de connaissances doivent suivre une démarche systématique qui s’appuie sur les fondamentaux du SEO tout en ajoutant des stratégies spécifiques aux entités. La première étape consiste à mettre en œuvre un balisage de données structurées avec le vocabulaire Schema.org. Cela signifie ajouter du balisage JSON-LD, Microdata ou RDFa à votre site web pour décrire explicitement votre organisation, produits, personnes et autres entités pertinentes. Les types de schémas clés incluent Organization (pour les informations sur l’entreprise), LocalBusiness (pour les informations locales), Person (pour les profils individuels), Product (pour les produits) et FAQPage (pour les questions fréquentes). Après avoir mis en place le schéma, il est essentiel de tester et valider votre balisage avec l’outil de test de données structurées de Google pour s’assurer qu’il est correctement formaté et reconnu. La deuxième étape consiste à auditer et optimiser les informations Wikidata et Wikipedia. Si votre organisation ou vos entités clés disposent de pages Wikipedia, assurez-vous qu’elles soient exactes, complètes et correctement sourcées. Pour Wikidata, vérifiez l’existence de votre entité et la justesse de ses propriétés et relations. Cependant, éditer Wikipedia ou Wikidata exige un respect strict des politiques et normes communautaires—l’auto-promotion directe ou les conflits d’intérêts non déclarés peuvent entraîner l’annulation des modifications et nuire à votre image. La troisième étape est de revendiquer et optimiser votre fiche Google Business (pour les entreprises locales) et vos panneaux de connaissances (pour les personnes et organisations). Un panneau de connaissances revendiqué vous donne plus de contrôle sur la façon dont votre entité apparaît dans la recherche et permet de proposer des modifications plus rapidement. La quatrième étape consiste à garantir la cohérence sur toutes vos propriétés—site web, fiche Google Business, profils sociaux et annuaires tiers. Des informations contradictoires brouillent les systèmes de Google et peuvent empêcher une représentation correcte dans le graphe. La cinquième étape est de créer du contenu centré sur les entités plutôt que sur les mots-clés. Au lieu d’écrire des articles autour de mots-clés, structurez votre stratégie de contenu autour des entités et de leurs relations. Par exemple, au lieu de rédiger des articles séparés sur « meilleur logiciel CRM », « fonctionnalités Salesforce » et « tarifs HubSpot », créez un cluster de contenu complet qui établit des relations claires : Salesforce est une plateforme CRM, elle concurrence HubSpot, elle s’intègre à Slack, etc. Cette approche centrée sur l’entité aide les graphes de connaissances à saisir le sens sémantique et les relations de votre contenu.
Points clés de l’optimisation et de la mise en œuvre des graphes de connaissances
- Implémentation de données structurées : Ajoutez le balisage Schema.org à toutes les pages pertinentes, dont Organization, LocalBusiness, Product, Person et FAQPage, et validez-le avec les outils de test Google
- Cohérence des entités : Maintenez des informations identiques (nom, adresse, téléphone, description) sur votre site, votre fiche Google Business, vos réseaux sociaux et les annuaires tiers pour éviter les signaux contradictoires
- Revendiquer le panneau de connaissances : Revendiquez votre panneau pour contrôler directement les informations d’entité et proposer des modifications traitées plus rapidement par Google
- Optimisation Wikidata : Assurez-vous que votre organisation ou vos entités clés disposent de fiches Wikidata précises, complètes et correctement reliées, dans le respect des règles communautaires
- Signaux E-E-A-T : Renforcez votre autorité via du contenu expert, les qualifications des auteurs, la reconnaissance sectorielle, des prix, des mentions dans les médias et des sources transparentes pour accroître l’inclusion dans le graphe
- Stratégie de contenu basée sur les entités : Structurez le contenu autour des entités et de leurs relations plutôt que des mots-clés, en créant des clusters complets établissant des connexions sémantiques
- Profils sur les réseaux sociaux : Créez et optimisez des profils sur les plateformes reconnues par Google (Facebook, Instagram, LinkedIn, YouTube, TikTok, X, Pinterest, Snapchat) et liez-les avec la propriété “sameAs” du schéma
- Profils sur des annuaires tiers : Maintenez des profils sur des annuaires d’entreprise reconnus tels que Crunchbase, Forbes et Fortune, utilisés par Google pour le graphe
- Surveillance de la précision des données : Auditez régulièrement vos informations d’entité sur toutes les sources et corrigez les données obsolètes ou erronées, y compris en contactant les sites tiers si nécessaire
- Soumission de retours : Utilisez les mécanismes de feedback Google dans les panneaux et résultats de recherche pour signaler les inexactitudes et suggérer des améliorations du graphe
- Suivi de la visibilité IA : Surveillez la façon dont votre marque apparaît dans les réponses générées par l’IA sur Perplexity, ChatGPT, Claude et Google AI Overviews pour comprendre votre représentation d’entité dans les systèmes d’IA
L’avenir des graphes de connaissances : évolution et implications stratégiques
Les graphes de connaissances évoluent rapidement sous l’effet des avancées en intelligence artificielle, des changements dans les comportements de recherche et de l’émergence de nouvelles plateformes et technologies. Une tendance majeure est l’essor des graphes de connaissances multimodaux intégrant texte, images, audio et vidéo. Avec la montée de la recherche vocale et visuelle, les graphes s’adaptent pour comprendre et représenter l’information sur plusieurs modalités. Les travaux de Google sur la recherche multimodale avec des produits comme Google Lens illustrent cette évolution—le système doit interpréter non seulement les requêtes textuelles mais aussi les entrées visuelles, nécessitant des graphes capables de relier l’information entre différents médias. Une autre évolution importante est la sophistication croissante de l’enrichissement sémantique et du traitement du langage naturel dans la construction des graphes. À mesure que les capacités NLP progressent, les graphes peuvent extraire des relations sémantiques plus fines à partir de textes non structurés, réduisant la dépendance à la curation manuelle ou au balisage explicite. Cela signifie que les organisations produisant un contenu de qualité verront leurs informations intégrées aux graphes, même sans balisage structuré, bien que ce dernier reste important pour une représentation optimale. L’intégration des graphes de connaissances avec les grands modèles de langage et l’IA générative représente peut-être l’évolution la plus significative. À mesure que l’IA devient centrale dans la découverte d’information, l’optimisation pour les graphes de connaissances dépasse la recherche classique pour inclure la visibilité sur l’IA multi-plateformes. Les organisations qui comprennent et optimisent leur présence dans ces graphes auront un avantage en recherche et dans les réponses générées par l’IA. Par ailleurs, la montée des graphes de connaissances d’entreprise traduit la reconnaissance croissante du potentiel des graphes pour la gestion interne du savoir : briser les silos de données, faciliter la prise de décision et permettre de meilleures applications d’IA. Cette tendance suggère que la maîtrise des graphes de connaissances deviendra un atout clé pour les dirigeants, data scientists et marketeurs. Enfin, les questions réglementaires et éthiques autour des graphes de connaissances prennent de l’importance. Puisque ces graphes influencent la présentation de l’information auprès de milliards d’utilisateurs, des questions d’exactitude, de biais, de représentation et de contrôle sont de plus en plus débattues. Les organisations doivent être conscientes que leur représentation dans les graphes de connaissances a des conséquences réelles sur leur visibilité, leur réputation et leurs résultats, et doivent aborder ce sujet avec la même rigueur et éthique que les autres aspects de leur présence digitale.