
Optimisation Meta AI : l’assistant IA de Facebook et Instagram
Découvrez comment l’optimisation Meta AI transforme la publicité sur Facebook et Instagram grâce à l’automatisation par l’IA, les enchères en temps réel et un c...
8 min de lecture
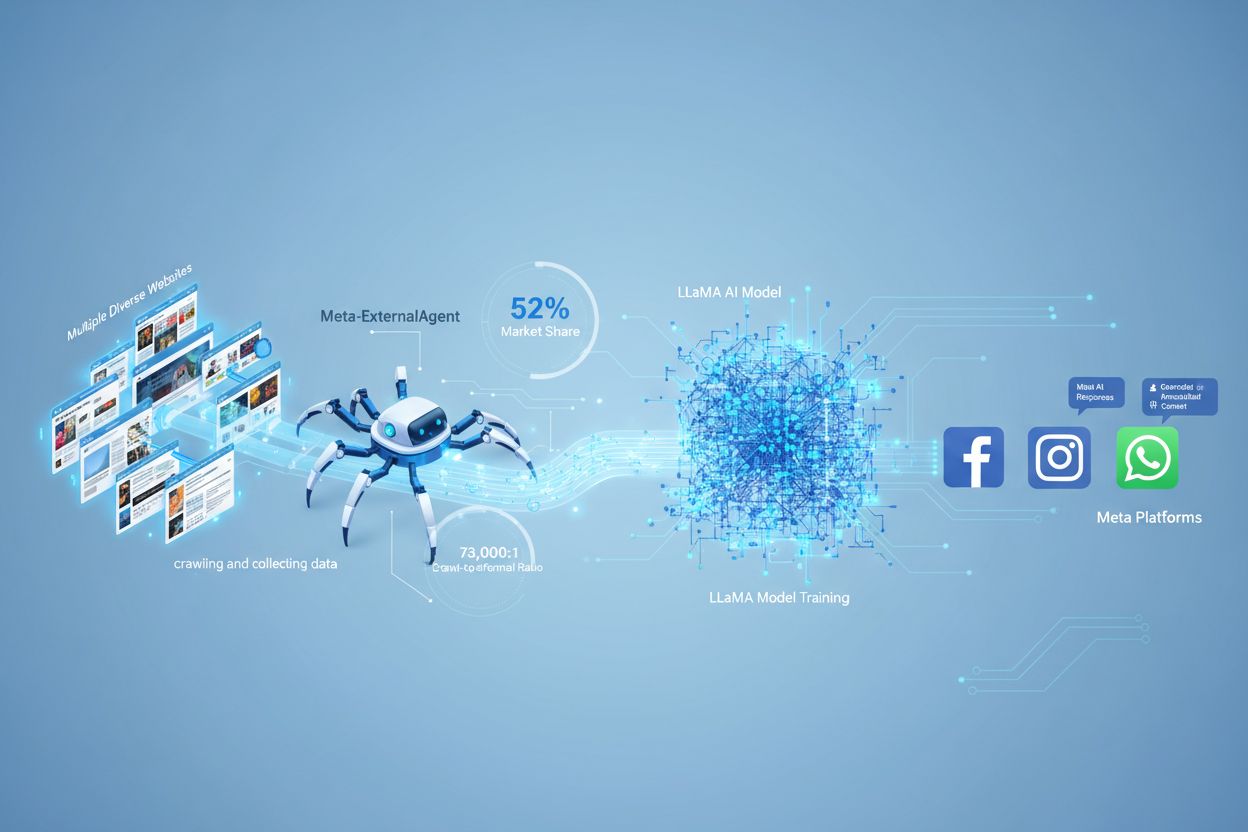
Meta-ExternalAgent est le robot d’exploration web de Meta, lancé en juillet 2024 pour collecter du contenu public afin d’entraîner des modèles d’IA comme LLaMA. Il s’identifie par la chaîne User-Agent meta-externalagent/1.1 et contrôle l’apparition du contenu dans les réponses de Meta AI sur Facebook, Instagram et WhatsApp. Les éditeurs peuvent le bloquer via robots.txt ou des configurations serveur, mais le respect de ces règles est volontaire et n’a pas de force contraignante.
Meta-ExternalAgent est le robot d’exploration web de Meta, lancé en juillet 2024 pour collecter du contenu public afin d’entraîner des modèles d’IA comme LLaMA. Il s’identifie par la chaîne User-Agent meta-externalagent/1.1 et contrôle l’apparition du contenu dans les réponses de Meta AI sur Facebook, Instagram et WhatsApp. Les éditeurs peuvent le bloquer via robots.txt ou des configurations serveur, mais le respect de ces règles est volontaire et n’a pas de force contraignante.
Meta-ExternalAgent est un robot d’exploration web exploité par Meta Platforms, lancé en juillet 2024 pour collecter des données destinées à l’entraînement de modèles d’intelligence artificielle. Identifié par le User-Agent meta-externalagent/1.1, ce robot se distingue de l’ancien robot facebookexternalhit de Meta, principalement utilisé pour les aperçus de liens et les fonctionnalités de partage social. Meta-ExternalAgent marque un changement important dans la manière dont Meta collecte des données d’entraînement pour ses initiatives IA, notamment les modèles de langage LLaMA et le chatbot Meta AI intégré à Facebook, Instagram et WhatsApp. Contrairement aux précédents robots de Meta, cet agent fonctionne avec une transparence minimale et a été déployé sans annonce publique formelle.

Meta-ExternalAgent agit comme un robot automatisé qui explore systématiquement les sites web sur Internet pour extraire des textes et du contenu à des fins d’entraînement de modèles d’IA. Le robot envoie des requêtes HTTP aux serveurs web, s’identifie par son en-tête User-Agent unique, et télécharge le contenu des pages pour traitement. Une fois le contenu collecté, les systèmes de Meta analysent et tokenisent les textes pour en faire des données d’entraînement permettant d’améliorer les capacités de leurs grands modèles de langage. Le robot respecte le fichier robots.txt sur une base volontaire, ce qui relève d’un système d’honneur et non d’une obligation légale. Selon les données Cloudflare, Meta-ExternalAgent représente environ 52 % de tout le trafic des robots d’IA sur Internet, ce qui en fait l’une des opérations de collecte de données les plus agressives dans l’industrie de l’IA. Le robot fonctionne en continu, certains éditeurs rapportant des fréquences de crawl qui suggèrent que Meta privilégie une couverture exhaustive du contenu web plutôt qu’une collecte sélective et ciblée.
| Nom du robot | User-Agent String | Objectif principal | Date de lancement | Usage des données |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | Entraînement des modèles IA (LLaMA, Meta AI) | Juillet 2024 | Données d’entraînement pour l’IA générative |
| facebookexternalhit | facebookexternalhit/1.1 | Aperçus de liens et partage social | ~2010 | Métadonnées Open Graph, vignettes |
| Facebot | facebot/1.0 | Vérification du contenu des applications Facebook | ~2015 | Validation de contenu pour applications mobiles |
| Applebot | Applebot/0.1 | Indexation pour Siri et la recherche Apple | ~2015 | Indexation pour la recherche et assistant vocal |
| Googlebot | Googlebot/2.1 | Indexation pour la recherche Google | ~1998 | Construction de l’index du moteur de recherche |
Meta-ExternalAgent représente une préoccupation majeure pour les créateurs de contenu et les éditeurs car il opère à une échelle sans précédent tout en offrant une visibilité minimale sur l’usage du contenu collecté. Selon les recherches de Cloudflare, Meta-ExternalAgent compte pour 52 % de tout le trafic des robots d’IA, dépassant largement des concurrents comme GPTBot d’OpenAI ou les robots IA de Google. Cette position dominante signifie que Meta collecte plus de données d’entraînement que toute autre entreprise d’IA, alors que les éditeurs ne reçoivent ni compensation ni attribution lorsque leur contenu sert à entraîner les modèles IA de Meta. Le ratio de crawl de 73 000:1 démontre que Meta extrait d’énormes quantités de contenu sans renvoyer pratiquement aucun trafic vers les sites sources — un déséquilibre fondamental dans l’échange de valeur. Malgré ces préoccupations, seuls 2 % des sites web bloquent activement Meta-ExternalAgent, contre 25 % qui bloquent GPTBot, ce qui suggère que beaucoup d’éditeurs ignorent la présence du robot ou ses implications. Avec un investissement de 40 milliards de dollars dans l’infrastructure IA, l’engagement de Meta dans la collecte agressive de données devrait s’intensifier, rendant essentiel pour les éditeurs de comprendre et de gérer activement leur relation avec ce robot.
Les éditeurs peuvent contrôler l’accès de Meta-ExternalAgent via le fichier robots.txt, mais il est important de comprendre que ce mécanisme fonctionne sur une base volontaire et n’est pas juridiquement contraignant. Pour bloquer Meta-ExternalAgent, ajoutez la directive suivante à votre fichier robots.txt :
User-agent: meta-externalagent
Disallow: /
Alternativement, si vous souhaitez autoriser le robot mais restreindre son accès à certains répertoires, vous pouvez utiliser :
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Cependant, certains éditeurs constatent que Meta-ExternalAgent continue d’explorer leurs sites même après la mise en place de blocs dans robots.txt, ce qui suggère que Meta ne respecte pas toujours ces directives. Pour une protection plus complète, les éditeurs peuvent mettre en place des blocages basés sur les entêtes HTTP ou utiliser des règles CDN pour identifier et rejeter les requêtes de Meta-ExternalAgent selon la chaîne User-Agent. De plus, les éditeurs peuvent surveiller les journaux de leur serveur pour la chaîne User-Agent meta-externalagent/1.1 afin de vérifier si le robot accède à leur contenu. Des outils comme AmICited.com aident les éditeurs à suivre si leur contenu est cité ou référencé dans les réponses de Meta AI, offrant ainsi une visibilité sur la manière dont leur travail est utilisé par les systèmes IA de Meta.

Lorsque les utilisateurs interagissent avec les chatbots Meta AI sur Facebook, Instagram ou WhatsApp, les réponses générées reposent en partie sur du contenu collecté par Meta-ExternalAgent. Cependant, les réponses de Meta AI n’incluent généralement pas de citation visible ni d’attribution aux sites sources, ce qui signifie que les utilisateurs ignorent quels éditeurs ont contribué à la réponse reçue. Ce manque de transparence constitue un défi majeur pour les créateurs de contenu qui souhaitent comprendre la valeur que leur travail apporte aux systèmes IA de Meta. Contrairement à certains concurrents qui incluent des citations dans les réponses générées par IA, l’approche de Meta privilégie l’expérience utilisateur plutôt que l’attribution éditeur. L’absence de citation visible rend également difficile pour les éditeurs de suivre la fréquence à laquelle leur contenu influence les réponses de Meta AI, ce qui complique l’évaluation de l’impact business du contenu utilisé pour l’entraînement IA. Cette lacune de visibilité est l’une des principales raisons de l’importance croissante des solutions de surveillance pour les éditeurs cherchant à comprendre leur rôle dans l’écosystème IA.
Les éditeurs peuvent vérifier l’activité de Meta-ExternalAgent grâce à l’analyse des journaux serveurs, qui révèlent les adresses IP du robot, ses schémas de requêtes et la fréquence d’accès au contenu. En examinant les logs d’accès, les éditeurs peuvent repérer les requêtes portant le User-Agent meta-externalagent/1.1 et déterminer quelles pages sont les plus explorées. Des outils de surveillance avancés permettent de suivre les schémas d’exploration dans le temps, révélant si Meta priorise certains types de contenus ou sections d’un site. Les éditeurs doivent également surveiller leur consommation de bande passante, car une exploration agressive par Meta-ExternalAgent peut mobiliser d’importantes ressources serveur, surtout pour les sites riches en contenu. Par ailleurs, des solutions comme AmICited.com permettent de vérifier si leur contenu figure dans les réponses de Meta AI et de suivre les schémas de citation sur les plateformes Meta. La mise en place d’alertes en cas d’activité de crawl inhabituelle aide à détecter des changements dans le comportement de collecte de données de Meta et à réagir de façon proactive. Des audits réguliers des logs serveurs devraient faire partie de toute stratégie de gestion des robots IA pour garantir une bonne visibilité sur l’accès et l’utilisation du contenu.
Le statut légal de Meta-ExternalAgent demeure contesté : des créateurs, artistes et éditeurs intentent des actions en justice contre Meta, contestant son droit d’utiliser leur travail pour l’entraînement IA sans consentement explicite ni compensation. Meta soutient que l’exploration web relève du fair use, tandis que les critiques estiment que l’ampleur et la finalité commerciale de la collecte, combinées à l’absence d’attribution, constituent une violation du droit d’auteur. Le fichier robots.txt, bien que largement reconnu comme standard de l’industrie, n’a aucune force juridique, ce qui implique que Meta n’est pas légalement tenu de respecter les directives de blocage. Plusieurs juridictions développent des réglementations sur la collecte de données pour l’entraînement IA, l’AI Act de l’Union européenne ou d’autres projets législatifs pouvant imposer des exigences plus strictes à des entreprises comme Meta. Sur le plan éthique, la question fondamentale est de savoir si les créateurs doivent avoir le droit de contrôler l’usage de leur travail pour l’entraînement commercial des IA, et si le système actuel compense suffisamment la valeur de leur contenu. Les éditeurs devraient se tenir informés de l’évolution des cadres juridiques et envisager de consulter un avocat concernant leurs droits et obligations liés à l’accès des robots IA. L’équilibre entre l’innovation IA et la protection des droits des créateurs reste incertain et fait l’objet de développements juridiques et réglementaires actifs.
Le paysage de la gestion des robots IA évolue rapidement à mesure que les éditeurs, régulateurs et entreprises d’IA négocient les modalités de collecte et d’utilisation des données. Le déploiement agressif de Meta-ExternalAgent montre que les principaux acteurs technologiques considèrent le contenu web comme essentiel à l’entraînement de leurs systèmes IA compétitifs, une tendance appelée à s’accélérer avec le rôle central de l’IA dans les stratégies business. Les évolutions à venir pourraient inclure une protection juridique renforcée pour les créateurs, des cadres de licence obligatoires pour les données d’entraînement IA, et des standards techniques facilitant le contrôle et la monétisation de l’utilisation du contenu dans les systèmes IA. L’apparition d’outils comme AmICited.com reflète une demande croissante de transparence et de responsabilité dans la façon dont les systèmes IA exploitent les contenus publiés, suggérant que la surveillance et la vérification deviendront une pratique standard pour les créateurs. À mesure que l’industrie de l’IA mûrit, on peut s’attendre à des négociations plus sophistiquées entre créateurs et entreprises IA, menant potentiellement à de nouveaux modèles économiques compensant équitablement les éditeurs pour leur contribution à l’entraînement des IA.
Meta-ExternalAgent est le robot dédié à l’entraînement de l’IA de Meta lancé en juillet 2024, identifié par le User-Agent meta-externalagent/1.1. Il diffère de facebookexternalhit, qui génère des aperçus de liens pour le partage social. Meta-ExternalAgent collecte spécifiquement du contenu pour l’entraînement des modèles LLaMA et Meta AI, tandis que facebookexternalhit est utilisé pour les fonctionnalités sociales depuis environ 2010.
Vous pouvez bloquer Meta-ExternalAgent en ajoutant des directives dans votre fichier robots.txt. Ajoutez 'User-agent: meta-externalagent' suivi de 'Disallow: /' pour le bloquer entièrement. Pour une protection plus complète, mettez en place un blocage au niveau du serveur via .htaccess (Apache) ou des règles de configuration Nginx. Cependant, robots.txt repose sur la bonne volonté et n’a pas de force juridique, certains éditeurs constatant une exploration continue malgré les blocages.
Non, bloquer Meta-ExternalAgent n’affectera pas les aperçus de liens Facebook. Le robot facebookexternalhit gère les aperçus de liens et les fonctionnalités sociales. Vous pouvez bloquer meta-externalagent tout en autorisant facebookexternalhit à continuer de générer des aperçus attractifs lorsque votre contenu est partagé sur les plateformes Meta.
Meta-ExternalAgent présente un ratio crawl-to-referral d’environ 73 000:1, ce qui signifie que Meta extrait du contenu à très grande échelle sans renvoyer de trafic vers les sites sources. Cela représente un déséquilibre fondamental par rapport aux moteurs de recherche traditionnels, qui explorent le contenu en échange de trafic référent.
robots.txt fonctionne sur la base de la confiance et n’est pas juridiquement contraignant. Si beaucoup de robots respectent les directives de robots.txt, certains éditeurs rapportent que Meta-ExternalAgent continue d’explorer leurs sites malgré un blocage explicite. Pour une protection garantie, mettez en place un blocage au niveau du serveur via des entêtes HTTP, des règles CDN ou des configurations de pare-feu.
Vérifiez les journaux d’accès de votre serveur à la recherche de requêtes avec le User-Agent 'meta-externalagent/1.1'. Vous pouvez aussi utiliser des outils comme AmICited.com pour suivre l’apparition de votre contenu dans les réponses de Meta AI. Des solutions comme Dark Visitors et Cloudflare Analytics offrent des informations complémentaires sur l’activité des robots d’IA sur votre site.
Selon les données de Cloudflare, Meta-ExternalAgent représente environ 52 % de tout le trafic des robots d’IA sur Internet, ce qui en fait l’opération de collecte de données d’IA la plus agressive. Cela dépasse largement les concurrents comme GPTBot d’OpenAI et les robots d’IA de Google, indiquant la position dominante de Meta dans la collecte de contenu web pour l’entraînement de l’IA.
La décision dépend de vos priorités business. Si le trafic Meta AI est précieux pour votre audience, vous pouvez l’autoriser. Cependant, gardez à l’esprit que Meta ne propose ni compensation ni attribution pour le contenu utilisé à des fins d’entraînement IA. Beaucoup d’éditeurs choisissent des stratégies de blocage sélectif pour stopper l’entraînement IA tout en préservant les aperçus de liens pour le partage social.
Suivez comment votre contenu apparaît dans les réponses Meta AI sur Facebook, Instagram et WhatsApp. Obtenez une visibilité sur les citations de l’IA et comprenez la présence de votre marque dans les réponses générées par l’IA.
Découvrez comment l’optimisation Meta AI transforme la publicité sur Facebook et Instagram grâce à l’automatisation par l’IA, les enchères en temps réel et un c...
Meta AI est l'assistant IA de Meta intégré à Facebook, Instagram, WhatsApp et Messenger. Découvrez son fonctionnement, ses capacités et son rôle dans la veille ...

Découvrez comment implémenter les balises meta noai et noimageai pour contrôler l'accès des crawlers IA au contenu de votre site web. Guide complet sur les en-t...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.