
Affinage de requête
L’affinage de requête est le processus itératif d’optimisation des requêtes de recherche pour de meilleurs résultats dans les moteurs de recherche IA. Découvrez...
15 min de lecture
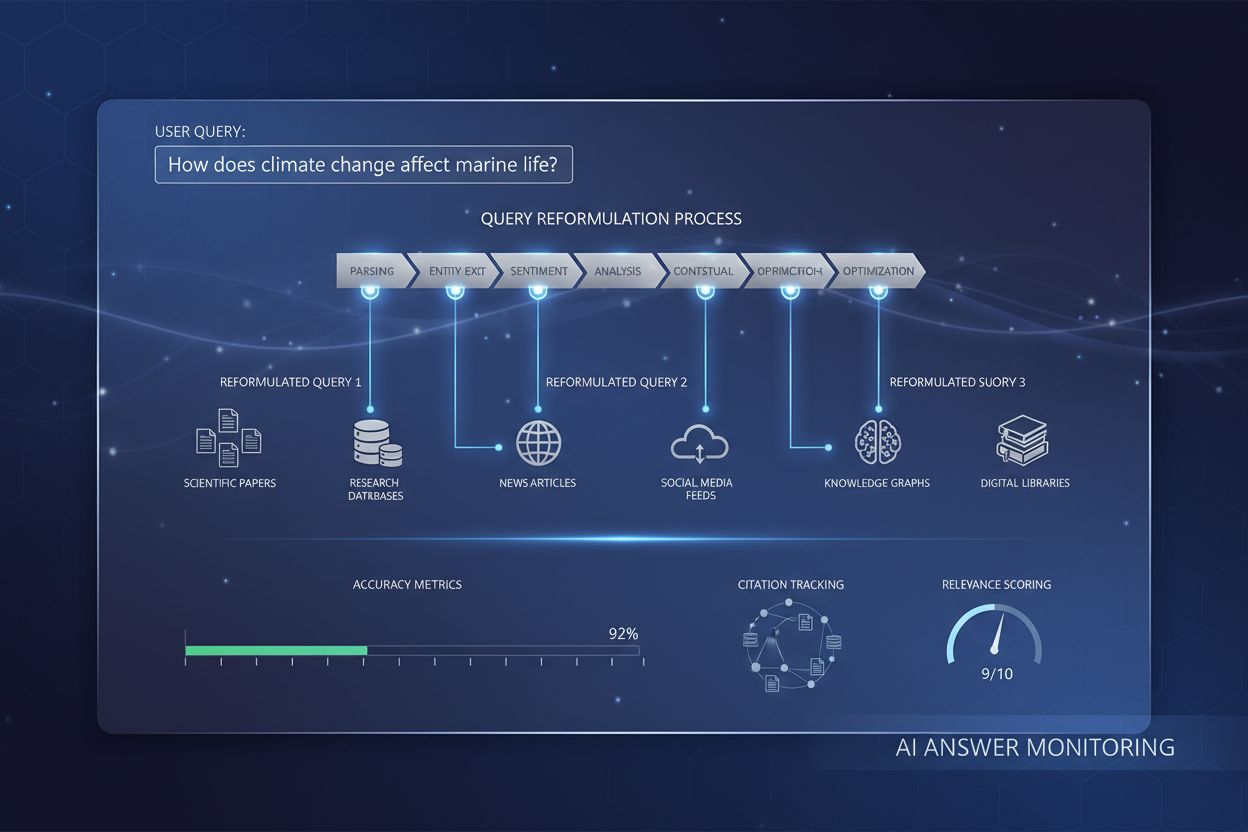
La reformulation de requête est le processus par lequel les systèmes d’IA interprètent, restructurent et enrichissent les requêtes des utilisateurs afin d’améliorer la précision et la pertinence de la recherche d’informations. Elle transforme des entrées simples ou ambiguës en versions plus détaillées et enrichies de contexte, alignées sur la compréhension du système d’IA, permettant des réponses plus précises et complètes.
La reformulation de requête est le processus par lequel les systèmes d’IA interprètent, restructurent et enrichissent les requêtes des utilisateurs afin d’améliorer la précision et la pertinence de la recherche d’informations. Elle transforme des entrées simples ou ambiguës en versions plus détaillées et enrichies de contexte, alignées sur la compréhension du système d’IA, permettant des réponses plus précises et complètes.
La reformulation de requête est le processus de transformation, d’expansion ou de réécriture de la requête de recherche originale d’un utilisateur afin de mieux l’aligner sur les capacités du système de recherche d’informations sous-jacent et sur l’intention réelle de l’utilisateur. Dans le contexte de l’intelligence artificielle et du traitement du langage naturel (NLP), la reformulation de requête comble le fossé critique entre la façon dont les utilisateurs expriment naturellement leurs besoins en information et la manière dont les systèmes d’IA interprètent et traitent ces demandes. Cette technique est essentielle dans les systèmes IA modernes car les utilisateurs formulent souvent leurs requêtes de manière imprécise, utilisent de façon incohérente une terminologie spécifique au domaine ou omettent des informations contextuelles qui amélioreraient la précision de la recherche. La reformulation de requête se situe à l’intersection de la recherche d’informations, de la compréhension sémantique et de l’apprentissage automatique, permettant aux systèmes de générer des résultats plus pertinents en réinterprétant les requêtes sous différents angles—que ce soit par expansion de synonymes, enrichissement contextuel ou réorganisation structurelle. En reformulant intelligemment les requêtes, les systèmes d’IA peuvent considérablement améliorer la qualité des réponses, réduire l’ambiguïté et s’assurer que l’information récupérée correspond plus fidèlement à l’intention de l’utilisateur.
Les systèmes de reformulation de requête fonctionnent généralement à travers cinq composants interdépendants qui transforment l’entrée brute de l’utilisateur en requêtes de recherche optimisées. L’analyse de l’entrée décompose la requête originale en ses parties constitutives, identifiant mots-clés, expressions et éléments structurels. L’extraction d’entités identifie les entités nommées (personnes, lieux, organisations, produits) et les concepts spécifiques au domaine qui portent du sens. L’analyse de sentiment préserve le ton émotionnel ou l’attitude évaluative de la requête originale, garantissant que les versions reformulées gardent la perspective initiale de l’utilisateur. L’analyse contextuelle intègre l’historique de session, les informations du profil utilisateur et la connaissance du domaine pour enrichir la requête avec une signification implicite. La génération de questions convertit les phrases déclaratives ou fragments en questions bien formées que les systèmes de recherche peuvent traiter plus efficacement.
| Composant | Rôle | Exemple |
|---|---|---|
| Analyse de l’entrée | Découpe et segmente la requête en unités significatives | “meilleures bibliothèques Python” → [“meilleures”, “Python”, “bibliothèques”] |
| Extraction d’entités | Identifie entités nommées et concepts du domaine | “dernier iPhone d’Apple” → Entité : Apple (entreprise), iPhone (produit) |
| Analyse de sentiment | Préserve le ton évaluatif et la perspective utilisateur | “service client terrible” → Maintien du sentiment négatif dans la reformulation |
| Analyse contextuelle | Intègre historique de session et connaissance du domaine | Recherche précédente sur “apprentissage automatique” informe la requête actuelle “réseaux neuronaux” |
| Génération de questions | Transforme des fragments en questions structurées | “débogage Python” → “Comment déboguer du code Python ?” |
Le processus de reformulation de requête suit une méthodologie systématique en six étapes visant à améliorer progressivement la qualité et la pertinence de la requête :
Analyse et normalisation de l’entrée
Extraction d’entités et de concepts
Préservation du sentiment et de l’intention
Enrichissement contextuel
Expansion de requête et génération de synonymes
Optimisation et évaluation
La reformulation de requête fait appel à des techniques variées, allant des approches lexicales traditionnelles aux méthodes neuronales de pointe. L’expansion basée sur les synonymes utilise des ressources établies comme WordNet, des embeddings de mots tels que Word2Vec et GloVe, ou des modèles contextuels comme BERT pour identifier des termes sémantiquement similaires. La relaxation de requête assouplit progressivement les contraintes de la requête pour accroître le rappel lorsque les résultats initiaux sont insuffisants—par exemple en supprimant des termes rares ou en élargissant les intervalles de dates. L’intégration des retours utilisateur et du contexte de session permet aux systèmes d’apprendre des interactions pour affiner les reformulations selon les résultats jugés pertinents par l’utilisateur. Les réécrivains basés sur des transformeurs comme T5 (Text-to-Text Transfer Transformer) et les modèles GPT génèrent de toutes nouvelles formulations en apprenant à partir de grands jeux de données de paires de requêtes. Les approches hybrides combinent plusieurs techniques—par exemple, expansion de synonymes basée sur des règles pour les termes à forte confiance et modèles neuronaux pour les expressions ambiguës. Les implémentations réelles emploient souvent des méthodes d’ensemble qui génèrent plusieurs reformulations et les classent via des modèles de pertinence appris. Ainsi, des plateformes e-commerce peuvent combiner des dictionnaires de synonymes spécifiques au domaine avec des embeddings BERT pour gérer à la fois la terminologie standardisée des produits et le langage usuel des utilisateurs, tandis que des systèmes de recherche médicale utilisent des ontologies spécialisées en plus de modèles transformeurs pour garantir l’exactitude clinique.
La reformulation de requête apporte des améliorations substantielles sur de nombreux aspects, tant pour la performance des systèmes d’IA que pour l’expérience utilisateur :
Précision de recherche améliorée : Les requêtes reformulées captent plus précisément l’intention utilisateur, produisant des documents récupérés de meilleure qualité et des réponses IA plus pertinentes. En élargissant les requêtes avec des synonymes et concepts associés, les systèmes trouvent des documents qui utilisent une terminologie différente de celle de la requête initiale, augmentant considérablement la probabilité de découvrir des informations réellement pertinentes.
Rappel et couverture élargis : L’expansion de requête augmente le nombre de documents pertinents récupérés en explorant les variations sémantiques et concepts liés. Ceci est particulièrement précieux dans les domaines spécialisés où la terminologie varie fortement, évitant à l’utilisateur de manquer des informations à cause des différences de vocabulaire.
Ambiguïté réduite et clarification : Le processus de reformulation permet de lever l’ambiguïté des requêtes vagues en intégrant du contexte et en générant plusieurs interprétations. Les systèmes peuvent ainsi traiter des requêtes comme “apple” (fruit vs entreprise) en générant des reformulations spécifiques au contexte pour obtenir des résultats appropriés.
Meilleure expérience et satisfaction utilisateur : Les utilisateurs reçoivent des résultats plus pertinents plus rapidement, ce qui réduit les itérations de raffinement de requête. Moins de recherches infructueuses et plus de résultats pertinents dès la première fois améliorent directement la satisfaction et réduisent la charge cognitive.
Scalabilité et efficacité : La reformulation permet de gérer des populations d’utilisateurs variées avec des vocabulaires, niveaux d’expertise et contextes linguistiques différents. Un unique moteur de reformulation peut servir plusieurs domaines et langues, améliorant l’évolutivité du système sans augmenter proportionnellement l’infrastructure.
Amélioration continue et apprentissage : Les systèmes de reformulation peuvent être entraînés sur les données d’interaction des utilisateurs, améliorant en continu leurs stratégies selon les reformulations qui aboutissent à des résultats réussis. Un cercle vertueux s’instaure avec des performances qui progressent à mesure que les données utilisateurs s’accumulent.
Adaptation et spécialisation par domaine : Les techniques de reformulation peuvent être ajustées pour des domaines spécifiques (médical, juridique, technique) en s’entraînant sur des paires de requêtes propres au domaine et en intégrant des ontologies dédiées. Cela permet aux systèmes spécialisés de gérer la terminologie avec plus de précision qu’une approche générique.
Robustesse face aux variations de requêtes : Les systèmes deviennent résilients aux fautes de frappe, erreurs grammaticales et langage familier en reformulant les requêtes sous une forme standardisée. Cette robustesse est particulièrement précieuse pour les interfaces vocales et la recherche mobile où la qualité de la saisie varie grandement.
La reformulation de requête joue un rôle crucial dans la précision et la fiabilité des réponses générées par l’IA, ce qui en fait un enjeu essentiel pour les plateformes de surveillance des réponses IA comme AmICited.com. Lorsque les systèmes d’IA reformulent les requêtes avant de générer des réponses, la qualité de ces reformulations détermine directement si l’IA retrouve les bonnes sources et produit des réponses exactes et correctement citées. Des reformulations mal faites peuvent amener l’IA à récupérer des documents non pertinents, produisant alors des réponses sans fondement solide ou citant des sources inappropriées. Dans le cadre de la surveillance IA et du suivi des citations, comprendre comment les requêtes sont reformulées est crucial pour vérifier que les systèmes d’IA répondent réellement à la question souhaitée par l’utilisateur, et non à une interprétation déformée de celle-ci. AmICited.com suit la façon dont les systèmes d’IA reformulent les requêtes afin de garantir que les sources citées dans les réponses générées par IA sont bien pertinentes pour la question d’origine, et non simplement pour une reformulation mal interprétée. Cette capacité de surveillance est d’autant plus importante que la reformulation de requête est invisible pour l’utilisateur final—il ne voit que la réponse finale et les citations, sans savoir comment la requête a été transformée. En analysant les schémas de reformulation, les plateformes de surveillance IA peuvent identifier quand les systèmes génèrent des réponses sur la base de requêtes reformulées qui s’écartent de manière significative de l’intention de l’utilisateur, signalant ainsi d’éventuels problèmes de précision avant qu’ils n’atteignent les utilisateurs. De plus, comprendre la reformulation aide les plateformes à évaluer si les systèmes d’IA gèrent correctement les requêtes ambiguës en générant plusieurs reformulations et en synthétisant les informations obtenues, ou s’ils font des suppositions injustifiées sur l’intention utilisateur.
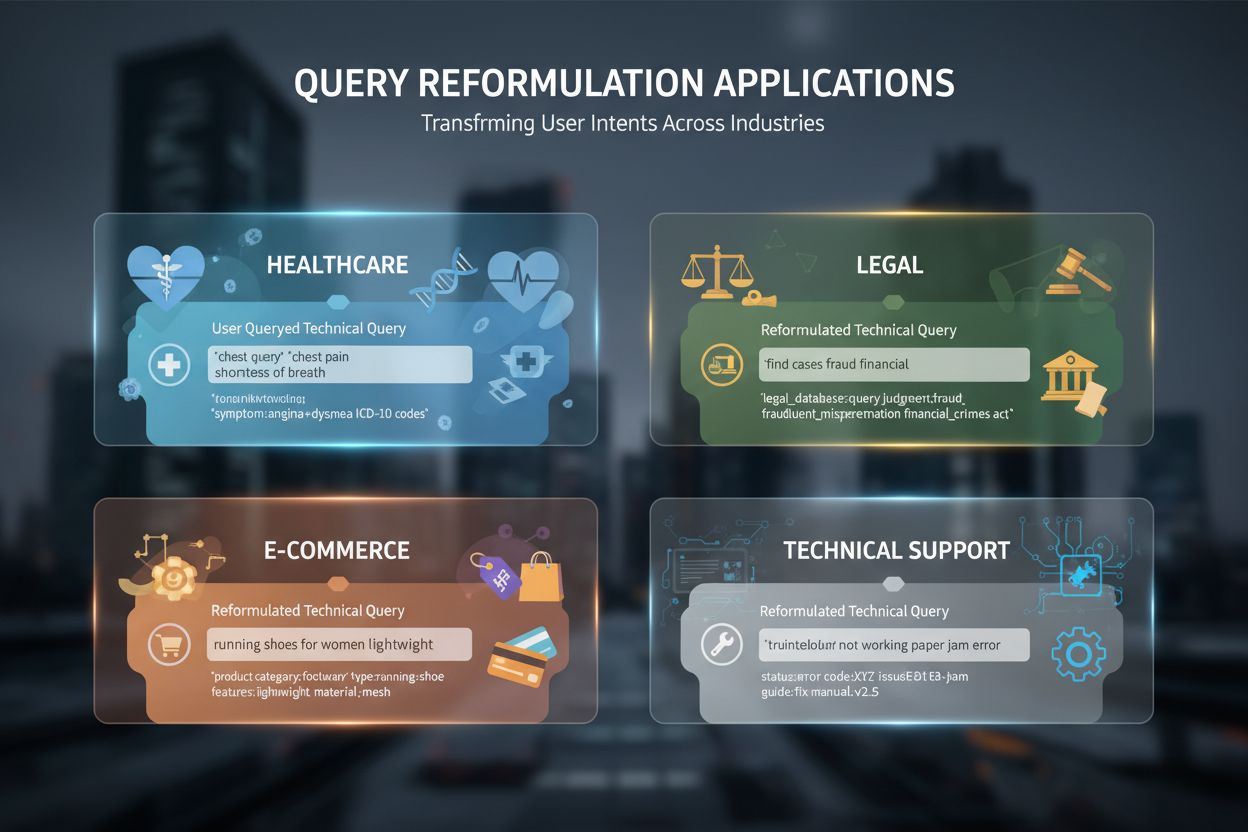
La reformulation de requête est devenue indispensable dans de nombreuses applications et industries pilotées par l’IA. En santé et recherche médicale, elle permet de gérer la complexité de la terminologie : par exemple, les patients cherchent “crise cardiaque” tandis que la littérature clinique utilise “infarctus du myocarde”—la reformulation comble ce fossé pour retrouver l’information clinique appropriée. Les systèmes d’analyse documentaire juridique utilisent la reformulation pour traiter le langage juridique précis ou archaïque tout en s’adaptant à la terminologie de recherche moderne, permettant aux avocats de trouver des précédents pertinents quelle que soit la formulation de leur requête. Les systèmes d’assistance technique reformulent les requêtes utilisateur pour les faire correspondre aux articles de la base de connaissances, en transformant des descriptions familières (“mon ordinateur est lent”) en termes techniques (“dégradation des performances du système”) pour retrouver les guides de dépannage adaptés. L’optimisation de la recherche e-commerce s’appuie sur la reformulation pour traiter les recherches produits où l’utilisateur tape “chaussures de course” tandis que le catalogue mentionne “chaussures de sport” ou des marques spécifiques, garantissant que le client trouve les produits souhaités malgré les différences de vocabulaire. Les IA conversationnelles et chatbots utilisent la reformulation pour maintenir le contexte sur plusieurs tours de conversation, reformulant les questions de suivi avec le contexte implicite des échanges précédents. Les systèmes de génération augmentée par récupération (RAG) reposent fortement sur la reformulation pour s’assurer que les documents de contexte récupérés sont réellement pertinents pour la question de l’utilisateur, impactant directement la qualité des réponses générées. Par exemple, un système RAG répondant à “Comment optimiser les requêtes de base de données ?” pourra reformuler en plusieurs variantes telles que “optimisation des performances de requêtes de base de données”, “techniques d’optimisation SQL” et “plans d’exécution de requêtes” pour obtenir un contexte complet avant de générer une réponse détaillée.
Malgré ses bénéfices, la reformulation de requête présente plusieurs défis majeurs à bien gérer. La complexité computationnelle augmente fortement lorsqu’il s’agit de générer et classer de multiples reformulations selon leur pertinence—chaque reformulation nécessite un traitement, et il faut équilibrer le gain de qualité avec la latence, surtout dans les applications en temps réel. La qualité des données d’entraînement détermine directement l’efficacité des reformulations ; des systèmes entraînés sur des paires de requêtes de mauvaise qualité ou biaisées propageront ces biais, risquant d’aggraver les problèmes au lieu de les résoudre. Le risque de sur-reformulation survient lorsque trop de variantes sont générées, au point de perdre de vue l’intention initiale et de récupérer des résultats de plus en plus périphériques, créant la confusion plutôt que la clarté. L’adaptation spécifique au domaine demande un effort important—les modèles entraînés sur des requêtes web génériques sont souvent inadaptés aux domaines spécialisés (médical, juridique) sans un retrainement et un ajustement conséquent. L’équilibre précision/rappel constitue un compromis fondamental : une expansion agressive augmente le rappel mais peut réduire la précision par récupération de résultats non pertinents, tandis qu’une reformulation conservatrice maintient la précision mais risque de manquer des documents pertinents. L’introduction potentielle de biais peut survenir lorsque les systèmes de reformulation encodent les préjugés présents dans les données d’entraînement, amplifiant la discrimination dans les résultats ou les réponses IA—par exemple, la reformulation de requêtes sur “infirmière” pourrait récupérer de façon disproportionnée des résultats associés à un genre si les données d’entraînement reflètent des biais historiques.
La reformulation de requête évolue rapidement avec les progrès de l’IA et l’émergence de nouvelles techniques. Les avancées en reformulation basée sur les grands modèles de langage (LLM) permettent des transformations plus sophistiquées et contextuelles, à mesure que ces modèles deviennent capables de comprendre des intentions nuancées et de générer des reformulations naturelles et riches sémantiquement. L’intégration d’IA multimodale étendra la reformulation de requête au-delà du texte, pour gérer des requêtes en images, audio ou vidéo, en transformant les recherches visuelles en descriptions textuelles traitables par les systèmes de recherche. La personnalisation et l’apprentissage rendront les systèmes de reformulation capables de s’adapter aux préférences, au vocabulaire et aux habitudes de chaque utilisateur, générant des reformulations de plus en plus personnalisées. La reformulation adaptative en temps réel permettra de reformuler dynamiquement les requêtes selon les résultats intermédiaires, créant des boucles de rétroaction où les premières reformulations informent les suivantes. L’intégration de graphes de connaissances permettra d’ancrer les reformulations sur des représentations structurées d’entités et de relations, générant des reformulations sémantiquement précises. L’émergence de standards pour l’évaluation et le benchmarking de la reformulation facilitera la comparaison entre systèmes et stimulera l’amélioration de la qualité et de la cohérence de la reformulation à l’échelle de l’industrie.
La reformulation de requête est le processus global de transformation d’une requête pour améliorer la recherche, tandis que l’expansion de requête est une technique spécifique à l’intérieur de la reformulation qui ajoute des synonymes et des termes associés. L’expansion de requête vise à élargir le champ de recherche, alors que la reformulation englobe plusieurs techniques comme l’analyse syntaxique, l’extraction d’entités, l’analyse de sentiment et l’enrichissement contextuel pour améliorer fondamentalement la qualité de la requête.
La reformulation de requête aide les systèmes d’IA à mieux comprendre l’intention de l’utilisateur en clarifiant les termes ambigus, en ajoutant du contexte et en générant plusieurs interprétations de la requête originale. Cela permet de récupérer des documents sources plus pertinents, ce qui conduit l’IA à générer des réponses plus précises, bien fondées et avec des citations appropriées.
Oui, la reformulation de requête peut servir de couche de sécurité en standardisant et en assainissant les entrées utilisateur avant qu’elles n’atteignent le système d’IA principal. Un agent de reformulation spécialisé peut détecter et neutraliser les entrées potentiellement dangereuses, filtrer les motifs suspects et transformer les requêtes en formats sûrs et standardisés, réduisant ainsi la vulnérabilité aux attaques par injection de prompt.
Dans les systèmes de génération augmentée par récupération (RAG), la reformulation de requête est essentielle pour garantir que les documents de contexte récupérés sont véritablement pertinents pour la question de l’utilisateur. En reformulant les requêtes en plusieurs variantes, les systèmes RAG peuvent obtenir un contexte plus complet et diversifié, améliorant directement la qualité et la précision des réponses générées.
L’implémentation implique généralement de sélectionner des techniques adaptées à votre cas d’usage : utilisez l’expansion basée sur les synonymes avec BERT ou Word2Vec pour la similarité sémantique, appliquez des modèles transformeurs comme T5 ou GPT pour la reformulation neuronale, intégrez des ontologies spécifiques au domaine pour les champs spécialisés et mettez en place des boucles de rétroaction pour améliorer continuellement les reformulations selon les interactions utilisateur et les indicateurs de réussite de la récupération.
Les coûts de calcul varient selon la technique : une simple expansion de synonymes est légère, tandis que la reformulation basée sur des transformeurs requiert d’importantes ressources GPU. Cependant, l’utilisation de petits modèles spécialisés pour la reformulation et de modèles plus grands uniquement pour la génération finale de la réponse peut optimiser les coûts. De nombreux systèmes utilisent la mise en cache et le traitement par lots pour amortir les dépenses de calcul sur plusieurs requêtes.
La reformulation de requête influe directement sur la précision des citations, car la requête reformulée détermine quels documents sont récupérés et cités. Si la reformulation s’éloigne significativement de l’intention initiale de l’utilisateur, l’IA peut citer des sources pertinentes pour la requête reformulée plutôt que pour la question d’origine. Les plateformes de surveillance IA comme AmICited suivent ces transformations pour garantir que les citations sont vraiment pertinentes par rapport à ce que les utilisateurs ont réellement demandé.
Oui, la reformulation de requête peut amplifier les biais existants si les données d’entraînement reflètent des préjugés sociétaux. Par exemple, la reformulation de certaines requêtes pourrait récupérer de façon disproportionnée des résultats associés à des groupes démographiques particuliers. Pour atténuer cela, il faut une curation attentive des jeux de données, des mécanismes de détection de biais, des exemples d’entraînement diversifiés et une surveillance continue des sorties de reformulation pour l’équité et la représentativité.
La reformulation de requête influence la façon dont les systèmes d’IA comprennent et citent votre contenu. AmICited suit ces transformations pour garantir que votre marque obtienne une attribution correcte dans les réponses générées par l’IA.
L’affinage de requête est le processus itératif d’optimisation des requêtes de recherche pour de meilleurs résultats dans les moteurs de recherche IA. Découvrez...
Découvrez comment l'optimisation de l'expansion de requête améliore les résultats de recherche IA en comblant les écarts de vocabulaire. Découvrez les technique...
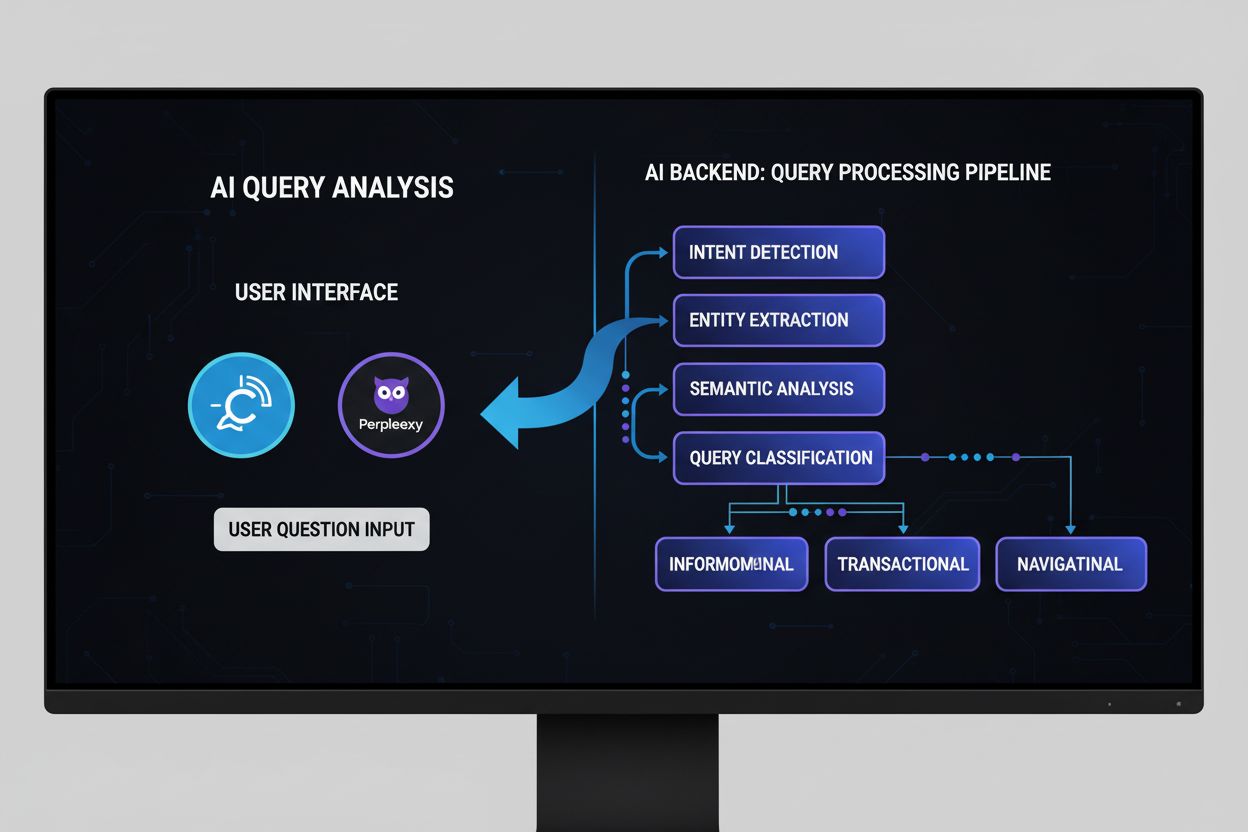
Découvrez ce qu'est l'Analyse des requêtes IA, son fonctionnement et son importance pour la visibilité sur les moteurs de recherche IA. Comprenez la classificat...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.