
Content Relevance Scoring
Learn how content relevance scoring uses AI algorithms to measure how well content matches user queries and intent. Understand BM25, TF-IDF, and how search engi...
7 min read

AI Retrieval Scoring is the process of quantifying the relevance and quality of retrieved documents or passages in relation to a user query. It employs sophisticated algorithms to evaluate semantic meaning, contextual appropriateness, and information quality, determining which sources are passed to language models for answer generation in RAG systems.
AI Retrieval Scoring is the process of quantifying the relevance and quality of retrieved documents or passages in relation to a user query. It employs sophisticated algorithms to evaluate semantic meaning, contextual appropriateness, and information quality, determining which sources are passed to language models for answer generation in RAG systems.
AI Retrieval Scoring is the process of quantifying the relevance and quality of retrieved documents or passages in relation to a user query or task. Unlike simple keyword matching, which only identifies surface-level term overlap, retrieval scoring employs sophisticated algorithms to evaluate semantic meaning, contextual appropriateness, and information quality. This scoring mechanism is fundamental to Retrieval-Augmented Generation (RAG) systems, where it determines which sources are passed to language models for answer generation. In modern LLM applications, retrieval scoring directly impacts answer accuracy, hallucination reduction, and user satisfaction by ensuring that only the most relevant information reaches the generation stage. The quality of retrieval scoring is therefore a critical component of overall system performance and reliability.
Retrieval scoring employs multiple algorithmic approaches, each with distinct strengths for different use cases. Semantic similarity scoring uses embedding models to measure the conceptual alignment between queries and documents in vector space, capturing meaning beyond surface-level keywords. BM25 (Best Matching 25) is a probabilistic ranking function that considers term frequency, inverse document frequency, and document length normalization, making it highly effective for traditional text retrieval. TF-IDF (Term Frequency-Inverse Document Frequency) weights terms based on their importance within documents and across collections, though it lacks semantic understanding. Hybrid approaches combine multiple methods—such as merging BM25 and semantic scores—to leverage both lexical and semantic signals. Beyond scoring methods, evaluation metrics like Precision@k (percentage of top-k results that are relevant), Recall@k (percentage of all relevant documents found in top-k), NDCG (Normalized Discounted Cumulative Gain, which accounts for ranking position), and MRR (Mean Reciprocal Rank) provide quantitative measures of retrieval quality. Understanding the strengths and weaknesses of each approach—such as BM25’s efficiency versus semantic scoring’s deeper understanding—is essential for selecting appropriate methods for specific applications.
| Scoring Method | How It Works | Best For | Key Advantage |
|---|---|---|---|
| Semantic Similarity | Compares embeddings using cosine similarity or other distance metrics | Conceptual meaning, synonyms, paraphrases | Captures semantic relationships beyond keywords |
| BM25 | Probabilistic ranking considering term frequency and document length | Exact phrase matching, keyword-based queries | Fast, efficient, proven in production systems |
| TF-IDF | Weights terms by frequency in document and rarity across collection | Traditional information retrieval | Simple, interpretable, lightweight |
| Hybrid Scoring | Combines semantic and keyword-based approaches with weighted fusion | General-purpose retrieval, complex queries | Leverages strengths of multiple methods |
| LLM-based Scoring | Uses language models to judge relevance with custom prompts | Complex context evaluation, domain-specific tasks | Captures nuanced semantic relationships |
In RAG systems, retrieval scoring operates at multiple levels to ensure generation quality. The system typically scores individual chunks or passages within documents, allowing fine-grained relevance assessment rather than treating entire documents as atomic units. This per-chunk relevance scoring enables the system to extract only the most pertinent information segments, reducing noise and irrelevant context that could confuse the language model. RAG systems often implement scoring thresholds or cutoff mechanisms that filter out low-scoring results before they reach the generation stage, preventing poor-quality sources from influencing the final answer. The quality of retrieved context directly correlates with generation quality—high-scoring, relevant passages lead to more accurate, grounded responses, while low-quality retrievals introduce hallucinations and factual errors. Monitoring retrieval scores provides early warning signals for system degradation, making it a key metric for AI answer monitoring and quality assurance in production systems.
Re-ranking serves as a second-pass filtering mechanism that refines initial retrieval results, often improving ranking accuracy significantly. After an initial retriever generates candidate results with preliminary scores, a re-ranker applies more sophisticated scoring logic to reorder or filter these candidates, typically using more computationally expensive models that can afford deeper analysis. Reciprocal Rank Fusion (RRF) is a popular technique that combines rankings from multiple retrievers by assigning scores based on result position, then fusing these scores to produce a unified ranking that often outperforms individual retrievers. Score normalization becomes critical when combining results from different retrieval methods, as raw scores from BM25, semantic similarity, and other approaches operate on different scales and must be calibrated to comparable ranges. Ensemble retriever approaches leverage multiple retrieval strategies simultaneously, with re-ranking determining the final ordering based on combined evidence. This multi-stage approach significantly improves ranking accuracy and robustness compared to single-stage retrieval, particularly in complex domains where different retrieval methods capture complementary relevance signals.
Precision@k: Measures the proportion of relevant documents within the top-k results; useful for assessing whether retrieved results are trustworthy (e.g., Precision@5 = 4/5 means 80% of top-5 results are relevant)
Recall@k: Calculates the percentage of all relevant documents found within the top-k results; important for ensuring comprehensive coverage of available relevant information
Hit Rate: Binary metric indicating whether at least one relevant document appears in the top-k results; useful for quick quality checks in production systems
NDCG (Normalized Discounted Cumulative Gain): Accounts for ranking position by assigning higher value to relevant documents appearing earlier; ranges from 0-1 and is ideal for evaluating ranking quality
MRR (Mean Reciprocal Rank): Measures the average position of the first relevant result across multiple queries; particularly useful for assessing whether the most relevant document ranks highly
F1 Score: Harmonic mean of precision and recall; provides balanced evaluation when both false positives and false negatives carry equal importance
MAP (Mean Average Precision): Averages precision values at each position where a relevant document is found; comprehensive metric for overall ranking quality across multiple queries
LLM-based relevance scoring leverages language models themselves as judges of document relevance, offering a flexible alternative to traditional algorithmic approaches. In this paradigm, carefully crafted prompts instruct an LLM to evaluate whether a retrieved passage answers a given query, producing either binary relevance scores (relevant/not relevant) or numerical scores (e.g., 1-5 scale indicating relevance strength). This approach captures nuanced semantic relationships and domain-specific relevance that traditional algorithms might miss, particularly for complex queries requiring deep understanding. However, LLM-based scoring introduces challenges including computational cost (LLM inference is expensive compared to embedding similarity), potential inconsistency across different prompts and models, and the need for calibration with human labels to ensure scores align with actual relevance. Despite these limitations, LLM-based scoring has proven valuable for evaluating RAG system quality and for creating training data for specialized scoring models, making it an important tool in the AI monitoring toolkit for assessing answer quality.
Implementing effective retrieval scoring requires careful consideration of multiple practical factors. Method selection depends on use case requirements: semantic scoring excels at capturing meaning but requires embedding models, while BM25 offers speed and efficiency for lexical matching. The trade-off between speed and accuracy is critical—embedding-based scoring provides superior relevance understanding but incurs latency costs, while BM25 and TF-IDF are faster but less semantically sophisticated. Computational cost considerations include model inference time, memory requirements, and infrastructure scaling needs, particularly important for high-volume production systems. Parameter tuning involves adjusting thresholds, weights in hybrid approaches, and re-ranking cutoffs to optimize performance for specific domains and use cases. Continuous monitoring of scoring performance through metrics like NDCG and Precision@k helps identify degradation over time, enabling proactive system improvements and ensuring consistent answer quality in production RAG systems.
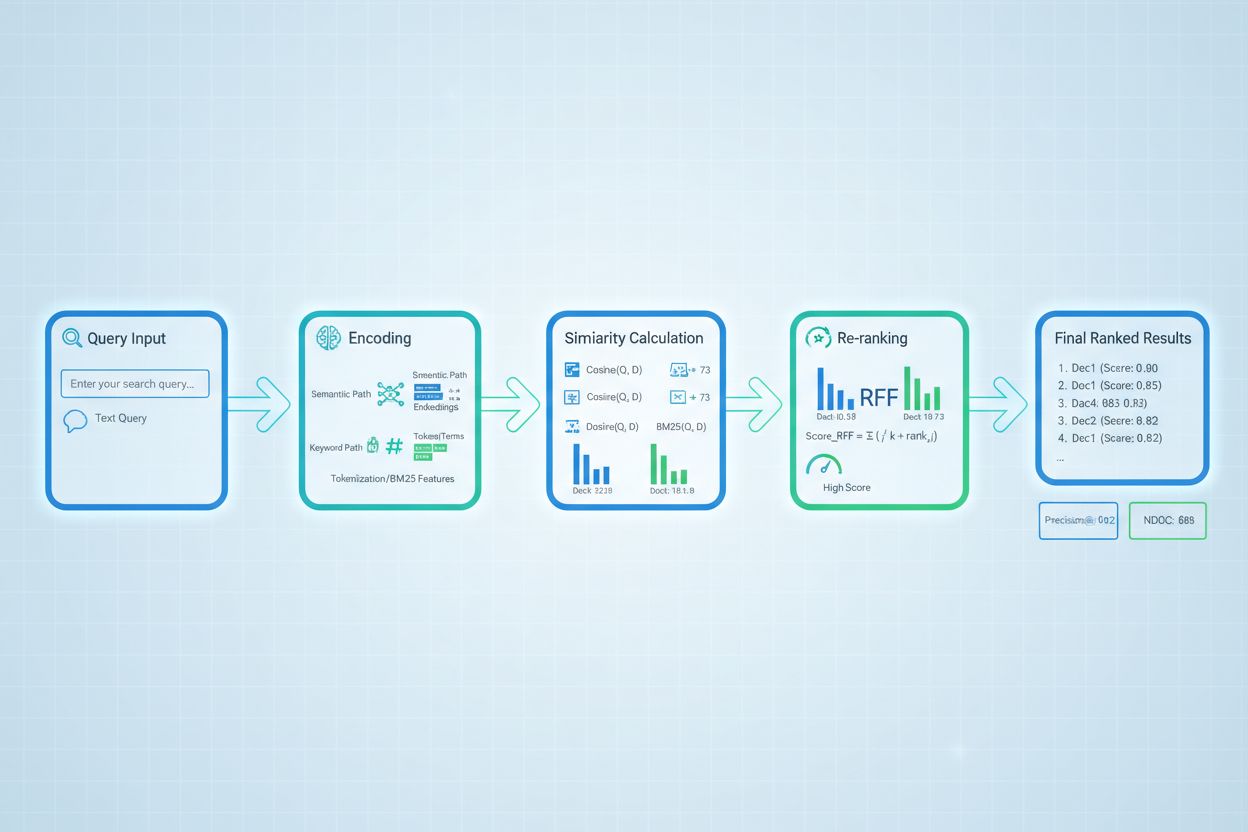
Advanced retrieval scoring techniques push beyond basic relevance assessment to capture complex contextual relationships. Query rewriting can improve scoring by reformulating user queries into multiple semantically equivalent forms, allowing the retriever to find relevant documents that might be missed by literal query matching. Hypothetical Document Embeddings (HyDE) generate synthetic relevant documents from queries, then use these hypotheticals to improve retrieval scoring by finding real documents similar to the idealized relevant content. Multi-query approaches submit multiple query variations to retrievers and aggregate their scores, improving robustness and coverage compared to single-query retrieval. Domain-specific scoring models trained on labeled data from particular industries or knowledge domains can achieve superior performance compared to general-purpose models, particularly valuable for specialized applications like medical or legal AI systems. Contextual scoring adjustments account for factors like document recency, source authority, and user context, enabling more sophisticated relevance assessment that goes beyond pure semantic similarity to incorporate real-world relevance factors critical for production AI systems.
Retrieval scoring assigns numerical relevance values to documents based on their relationship to a query, while ranking orders documents based on these scores. Scoring is the evaluation process, ranking is the ordering result. Both are essential for RAG systems to deliver accurate answers.
Retrieval scoring determines which sources reach the language model for answer generation. High-quality scoring ensures relevant information is selected, reducing hallucinations and improving answer accuracy. Poor scoring leads to irrelevant context and unreliable AI responses.
Semantic scoring uses embeddings to understand conceptual meaning and captures synonyms and related concepts. Keyword-based scoring (like BM25) matches exact terms and phrases. Semantic scoring is better for understanding intent, while keyword scoring excels at finding specific information.
Key metrics include Precision@k (accuracy of top results), Recall@k (coverage of relevant documents), NDCG (ranking quality), and MRR (position of first relevant result). Choose metrics based on your use case: Precision@k for quality-focused systems, Recall@k for comprehensive coverage.
Yes, LLM-based scoring uses language models as judges to evaluate relevance. This approach captures nuanced semantic relationships but is computationally expensive. It's valuable for evaluating RAG quality and creating training data, though it requires calibration with human labels.
Re-ranking applies a second-pass filtering using more sophisticated models to refine initial results. Techniques like Reciprocal Rank Fusion combine multiple retrieval methods, improving accuracy and robustness. Re-ranking significantly outperforms single-stage retrieval in complex domains.
BM25 and TF-IDF are fast and lightweight, suitable for real-time systems. Semantic scoring requires embedding model inference, adding latency. LLM-based scoring is most expensive. Choose based on your latency requirements and computational resources available.
Consider your priorities: semantic scoring for meaning-focused tasks, BM25 for speed and efficiency, hybrid approaches for balanced performance. Evaluate on your specific domain using metrics like NDCG and Precision@k. Test multiple methods and measure their impact on final answer quality.
Track how AI systems like ChatGPT, Perplexity, and Google AI reference your brand and evaluate the quality of their source retrieval and ranking. Ensure your content is properly cited and ranked by AI systems.
Learn how content relevance scoring uses AI algorithms to measure how well content matches user queries and intent. Understand BM25, TF-IDF, and how search engi...

Learn what readability scores mean for AI search visibility. Discover how Flesch-Kincaid, sentence structure, and content formatting impact AI citations in Chat...
Learn how RAG combines LLMs with external data sources to generate accurate AI responses. Understand the five-stage process, components, and why it matters for ...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.