
Multimodal AI Search: Optimizing for Image and Voice Queries
Master multimodal AI search optimization. Learn how to optimize images and voice queries for AI-powered search results, featuring strategies for GPT-4o, Gemini,...
9 min read

AI systems that process and respond to queries involving text, images, audio, and video simultaneously, enabling more comprehensive understanding and context-aware responses across multiple data types.
AI systems that process and respond to queries involving text, images, audio, and video simultaneously, enabling more comprehensive understanding and context-aware responses across multiple data types.
Multimodal AI search refers to artificial intelligence systems that process and integrate information from multiple data types or modalities—such as text, images, audio, and video—simultaneously to deliver more comprehensive and contextually relevant results. Unlike unimodal AI, which relies on a single type of input (for example, text-only search engines), multimodal systems leverage the complementary strengths of different data formats to achieve deeper understanding and more accurate outcomes. This approach mirrors human cognition, where we naturally combine visual, auditory, and textual information to comprehend our environment. By processing diverse input types together, multimodal AI search systems can capture nuances and relationships that would be invisible to single-modality approaches.
Multimodal AI search operates through sophisticated fusion techniques that combine information from different modalities at various processing stages. The system first extracts features from each modality independently, then strategically merges these representations to create a unified understanding. The timing and method of fusion significantly impact performance, as illustrated in the following comparison:
| Fusion Type | When Applied | Advantages | Disadvantages |
|---|---|---|---|
| Early Fusion | Input stage | Captures low-level correlations | Less robust with misaligned data |
| Mid Fusion | Preprocessing stages | Balanced approach | More complex |
| Late Fusion | Output level | Modular design | Reduced context cohesiveness |
Early fusion combines raw data immediately, capturing fine-grained interactions but struggling with misaligned inputs. Mid-fusion applies fusion during intermediate processing stages, offering a balanced compromise between complexity and performance. Late fusion operates at the output level, allowing independent modality processing but potentially losing important cross-modal context. The choice of fusion strategy depends on the specific application requirements and the nature of the data being processed.
Several key technologies power modern multimodal AI search systems, enabling them to process and integrate diverse data types effectively:
These technologies work synergistically to create systems capable of understanding complex relationships between different types of information.
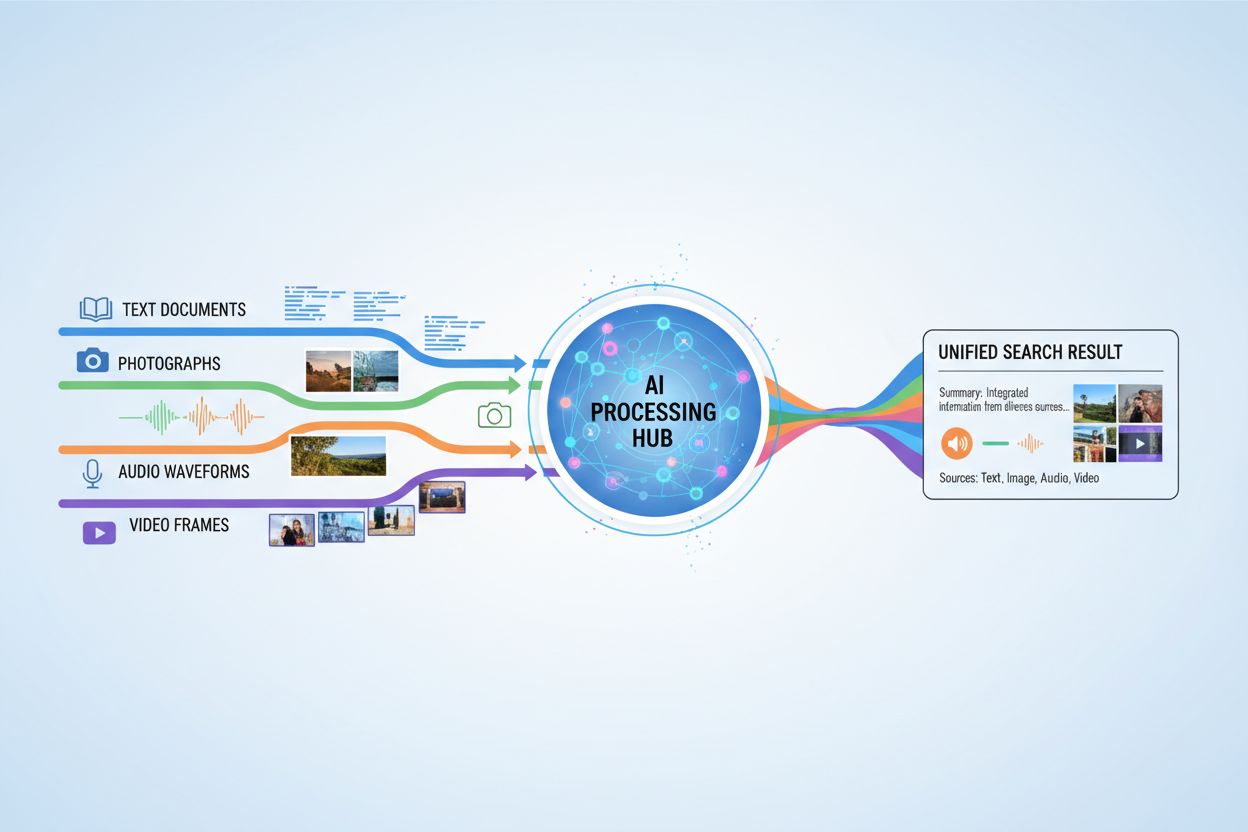
Multimodal AI search has transformative applications across numerous industries and domains. In healthcare, systems analyze medical images alongside patient records and clinical notes to improve diagnostic accuracy and treatment recommendations. E-commerce platforms use multimodal search to enable customers to find products by combining text descriptions with visual references or even sketches. Autonomous vehicles rely on multimodal fusion of camera feeds, radar data, and sensor inputs to navigate safely and make real-time decisions. Content moderation systems combine image recognition, text analysis, and audio processing to identify harmful content more effectively than single-modality approaches. Additionally, multimodal search enhances accessibility by allowing users to search using their preferred input method—voice, image, or text—while the system understands the intent across all formats.

Multimodal AI search delivers substantial benefits that justify its increased complexity and computational requirements. Improved accuracy results from leveraging complementary information sources, reducing errors that single-modality systems might make. Enhanced contextual understanding emerges when visual, textual, and auditory information combine to provide richer semantic meaning. Superior user experience is achieved through more intuitive search interfaces that accept diverse input types and deliver more relevant results. Cross-domain learning becomes possible as knowledge from one modality can inform understanding in another, enabling transfer learning across different data types. Increased robustness means the system maintains performance even when one modality is degraded or unavailable, as other modalities can compensate for missing information.
Despite its advantages, multimodal AI search faces significant technical and practical challenges. Data alignment and synchronization remains difficult, as different modalities often have different temporal characteristics and quality levels that must be carefully managed. Computational complexity increases substantially when processing multiple data streams simultaneously, requiring significant computational resources and specialized hardware. Bias and fairness concerns emerge when training data contains imbalances across modalities or when certain groups are underrepresented in specific data types. Privacy and security become more complex with multiple data streams, increasing the surface area for potential breaches and requiring careful handling of sensitive information. Massive data requirements mean that training effective multimodal systems demands substantially larger and more diverse datasets than unimodal alternatives, which can be expensive and time-consuming to acquire and annotate.
Multimodal AI search intersects importantly with AI monitoring and citation tracking, particularly as AI systems increasingly generate answers that reference or synthesize information from multiple sources. Platforms like AmICited.com focus on monitoring how AI systems cite and attribute information to original sources, ensuring transparency and accountability in AI-generated responses. Similarly, FlowHunt.io tracks AI content generation and helps organizations understand how their branded content is being processed and referenced by multimodal AI systems. As multimodal AI search becomes more prevalent, tracking how these systems cite brands, products, and original sources becomes crucial for businesses seeking to understand their visibility in AI-generated results. This monitoring capability helps organizations verify that their content is being accurately represented and properly attributed when multimodal AI systems synthesize information across text, images, and other modalities.
The future of multimodal AI search points toward increasingly unified and seamless integration of diverse data types, moving beyond current fusion approaches toward more holistic models that process all modalities as inherently interconnected. Real-time processing capabilities will expand, enabling multimodal search to operate on live video streams, continuous audio, and dynamic text simultaneously without latency constraints. Advanced data augmentation techniques will address current data scarcity challenges by synthetically generating multimodal training examples that maintain semantic consistency across modalities. Emerging developments include foundation models trained on vast multimodal datasets that can be efficiently adapted to specific tasks, neuromorphic computing approaches that more closely mimic biological multimodal processing, and federated multimodal learning that enables training across distributed data sources while preserving privacy. These advances will make multimodal AI search more accessible, efficient, and capable of handling increasingly complex real-world scenarios.
Track how multimodal AI search engines cite and attribute your content across text, images, and other modalities with AmICited's comprehensive monitoring platform.
Master multimodal AI search optimization. Learn how to optimize images and voice queries for AI-powered search results, featuring strategies for GPT-4o, Gemini,...

Learn what multi-modal content for AI is, how it works, and why it matters. Explore examples of multi-modal AI systems and their applications across industries.

Learn how to optimize text, images, and video for multimodal AI systems. Discover strategies to improve AI citations and visibility across ChatGPT, Gemini, and ...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.