
Quali crawler AI dovrei autorizzare? Guida completa per il 2025
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...
12 min di lettura

Guida di riferimento completa ai crawler e bot AI. Identifica GPTBot, ClaudeBot, Google-Extended e oltre 20 altri crawler AI con user agent, frequenze di scansione e strategie di blocco.
I crawler AI sono fondamentalmente diversi dai tradizionali crawler dei motori di ricerca conosciuti da decenni. Mentre Googlebot e Bingbot indicizzano i contenuti per aiutare gli utenti a trovare informazioni tramite i risultati di ricerca, i crawler AI come GPTBot e ClaudeBot raccolgono dati specificamente per addestrare grandi modelli linguistici. Questa distinzione è cruciale: i crawler tradizionali creano percorsi per la scoperta umana, mentre i crawler AI alimentano le basi di conoscenza dei sistemi di intelligenza artificiale. Secondo dati recenti, i crawler AI ora rappresentano quasi l'80% di tutto il traffico bot verso i siti web, con i crawler di addestramento che consumano grandi quantità di contenuti inviando pochissimo traffico di riferimento agli editori. A differenza dei crawler tradizionali, che faticano con siti dinamici ricchi di JavaScript, i crawler AI utilizzano il machine learning avanzato per comprendere il contesto dei contenuti, proprio come farebbe un lettore umano. Possono interpretare il significato, il tono e lo scopo senza aggiornamenti manuali di configurazione. Questo rappresenta un salto quantico nella tecnologia di indicizzazione del web che richiede ai proprietari dei siti di ripensare completamente le strategie di gestione dei crawler.
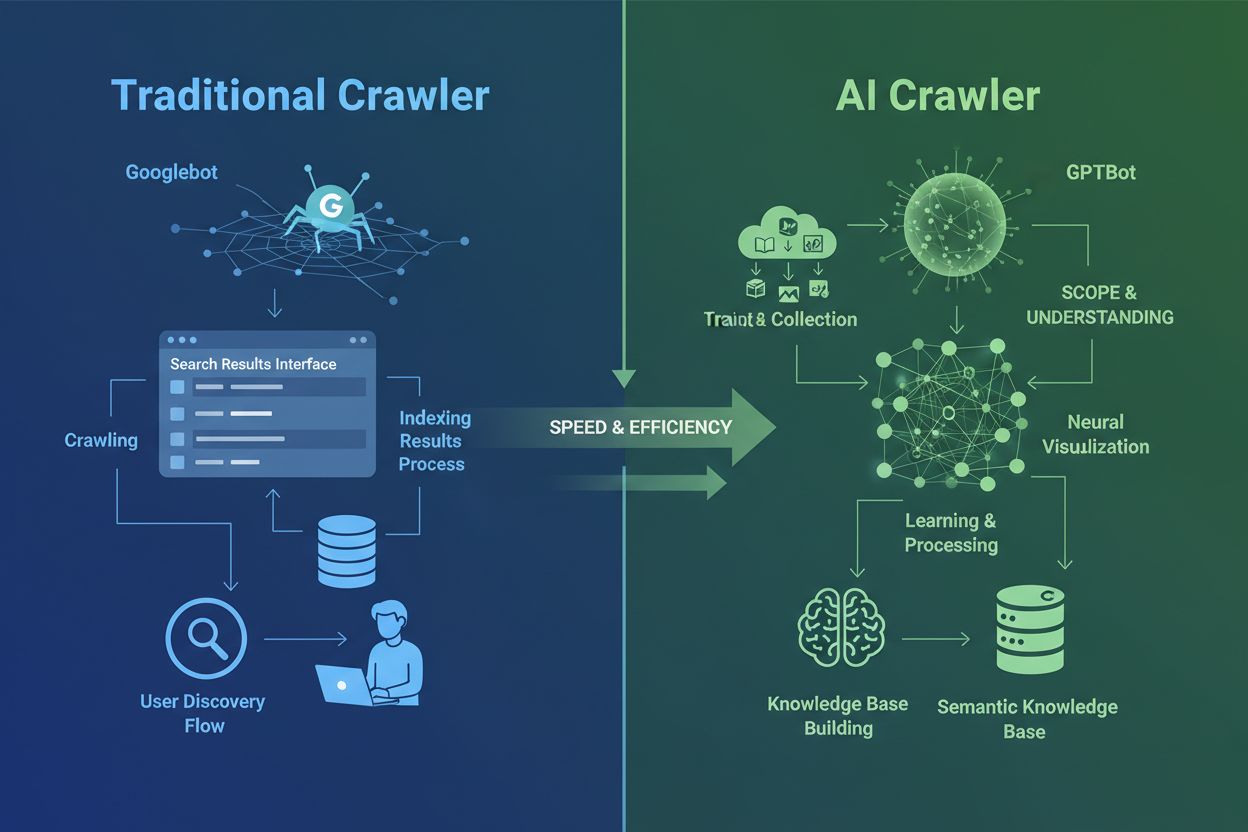
Il panorama dei crawler AI è diventato sempre più affollato man mano che le principali aziende tecnologiche si affrettano a costruire i propri grandi modelli linguistici. OpenAI, Anthropic, Google, Meta, Amazon, Apple e Perplexity gestiscono ciascuna diversi crawler specializzati, ognuno con funzioni distinte all’interno dei rispettivi ecosistemi AI. Le aziende implementano più crawler perché scopi diversi richiedono comportamenti diversi: alcuni crawler si concentrano sulla raccolta massiva di dati per l’addestramento, altri gestiscono l’indicizzazione di ricerca in tempo reale, altri ancora recuperano contenuti su richiesta quando richiesto dagli utenti. Comprendere questo ecosistema significa riconoscere tre principali categorie di crawler: crawler di addestramento che raccolgono dati per il miglioramento dei modelli, crawler di ricerca e citazione che indicizzano contenuti per esperienze di ricerca AI e fetcher attivati dall’utente che si attivano solo quando un utente richiede specificamente contenuti tramite assistenti AI. La tabella seguente offre una panoramica rapida dei principali attori:
| Azienda | Nome Crawler | Scopo Principale | Frequenza Scansione | Dati Addestramento |
|---|---|---|---|---|
| OpenAI | GPTBot | Addestramento modelli | 100 pagine/ora | Sì |
| OpenAI | ChatGPT-User | Richieste utente in tempo reale | 2400 pagine/ora | No |
| OpenAI | OAI-SearchBot | Indicizzazione ricerca | 150 pagine/ora | No |
| Anthropic | ClaudeBot | Addestramento modelli | 500 pagine/ora | Sì |
| Anthropic | Claude-User | Accesso web in tempo reale | <10 pagine/ora | No |
| Google-Extended | Addestramento Gemini AI | Variabile | Sì | |
| Gemini-Deep-Research | Funzione ricerca | <10 pagine/ora | No | |
| Meta | Meta-ExternalAgent | Addestramento modelli AI | 1100 pagine/ora | Sì |
| Amazon | Amazonbot | Miglioramento servizi | 1050 pagine/ora | Sì |
| Perplexity | PerplexityBot | Indicizzazione ricerca | 150 pagine/ora | No |
| Apple | Applebot-Extended | Addestramento AI | <10 pagine/ora | Sì |
| Common Crawl | CCBot | Dataset aperto | <10 pagine/ora | Sì |
OpenAI gestisce tre crawler distinti, ciascuno con ruoli specifici nell’ecosistema ChatGPT. Comprendere questi crawler è essenziale poiché GPTBot di OpenAI è uno dei crawler AI più aggressivi e diffusi su Internet:
GPTBot - Il principale crawler di addestramento di OpenAI che raccoglie sistematicamente dati pubblici per addestrare e migliorare i modelli GPT, inclusi ChatGPT e GPT-4o. Questo crawler opera a circa 100 pagine all’ora e rispetta le direttive di robots.txt. OpenAI pubblica gli indirizzi IP ufficiali su https://openai.com/gptbot.json per la verifica.
ChatGPT-User - Questo crawler appare quando un utente reale interagisce con ChatGPT e gli chiede di navigare una pagina web specifica. Opera a velocità molto più elevate (fino a 2400 pagine/ora) poiché viene attivato dalle azioni degli utenti e non dalla scansione sistematica. I contenuti accessibili tramite ChatGPT-User non vengono utilizzati per l’addestramento dei modelli, risultando utili per la visibilità in tempo reale nei risultati di ricerca di ChatGPT.
OAI-SearchBot - Progettato specificamente per la funzionalità di ricerca di ChatGPT, questo crawler indicizza i contenuti per risultati di ricerca in tempo reale senza raccogliere dati di addestramento. Opera a circa 150 pagine all’ora e aiuta i tuoi contenuti a comparire nei risultati di ricerca di ChatGPT quando gli utenti fanno domande pertinenti.
I crawler di OpenAI rispettano le direttive di robots.txt e operano da range IP verificati, risultando relativamente semplici da gestire rispetto a concorrenti meno trasparenti.
Anthropic, l’azienda dietro Claude AI, gestisce più crawler con diversi scopi e livelli di trasparenza. L’azienda è stata meno chiara nella documentazione rispetto a OpenAI, ma il comportamento dei suoi crawler è ben documentato tramite l’analisi dei log del server:
ClaudeBot - Il principale crawler di addestramento di Anthropic che raccoglie contenuti web per migliorare la base di conoscenza e le capacità di Claude. Opera a circa 500 pagine all’ora ed è il target principale se vuoi impedire che i tuoi contenuti vengano utilizzati per l’addestramento del modello Claude. La stringa completa dell’user agent è Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User - Attivato quando gli utenti Claude richiedono l’accesso web in tempo reale, questo crawler recupera contenuti su richiesta con un volume minimo. Rispetta l’autenticazione e non tenta di aggirare le restrizioni di accesso, risultando relativamente innocuo dal punto di vista delle risorse.
Claude-SearchBot - Supporta le capacità di ricerca interna di Claude, aiutando i tuoi contenuti a comparire nei risultati di ricerca di Claude quando gli utenti fanno domande. Opera a volumi molto bassi e serve principalmente per l’indicizzazione più che per l’addestramento.
Una preoccupazione critica con i crawler di Anthropic è il rapporto crawl-to-refer: i dati Cloudflare indicano che per ogni referral inviato da Anthropic a un sito web, i suoi crawler hanno già visitato circa 38.000-70.000 pagine. Questo squilibrio significa che i tuoi contenuti vengono consumati molto più aggressivamente di quanto vengono citati, sollevando importanti questioni sulla giusta compensazione per l’utilizzo dei contenuti.
L’approccio di Google al crawling AI differisce significativamente dai concorrenti perché l’azienda mantiene una separazione rigorosa tra indicizzazione della ricerca e addestramento AI. Google-Extended è il crawler specifico responsabile della raccolta dati per l’addestramento di Gemini (ex Bard) e altri prodotti AI Google, completamente separato dal tradizionale Googlebot:
La stringa user agent per Google-Extended è: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Questa separazione è intenzionale e vantaggiosa per i proprietari di siti web poiché puoi bloccare Google-Extended tramite robots.txt senza compromettere la visibilità su Google Search. Google dichiara ufficialmente che bloccare Google-Extended non ha alcun impatto sul ranking di ricerca o sulla presenza nei riassunti AI, anche se alcuni webmaster hanno segnalato preoccupazioni da monitorare. Gemini-Deep-Research è un altro crawler Google che supporta la funzione di ricerca di Gemini, operando a volumi molto bassi con impatto minimo sulle risorse del server. Un importante vantaggio tecnico dei crawler Google è la capacità di eseguire JavaScript e visualizzare contenuti dinamici, a differenza della maggior parte dei concorrenti. Questo significa che Google-Extended può scansionare efficacemente applicazioni React, Vue e Angular, mentre GPTBot di OpenAI e ClaudeBot di Anthropic non possono. Per i proprietari di siti con applicazioni ricche di JavaScript, questa distinzione è rilevante per la visibilità AI.
Oltre ai giganti tecnologici, numerose altre organizzazioni gestiscono crawler AI che meritano attenzione. Meta-ExternalAgent, lanciato silenziosamente a luglio 2024, estrae contenuti web per addestrare i modelli AI di Meta e migliorare prodotti come Facebook, Instagram e WhatsApp. Opera a circa 1100 pagine all’ora e ha ricevuto meno attenzione pubblica rispetto ai concorrenti nonostante il comportamento di crawling aggressivo. Bytespider, gestito da ByteDance (la società madre di TikTok), si è imposto come uno dei crawler più aggressivi su Internet dal suo lancio nell’aprile 2024. Monitoraggi di terze parti suggeriscono che Bytespider scansiona molto più aggressivamente di GPTBot o ClaudeBot, anche se i moltiplicatori esatti variano. Alcune segnalazioni indicano che potrebbe non rispettare sempre le direttive di robots.txt, rendendo il blocco basato su IP più affidabile.
I crawler di Perplexity includono PerplexityBot per l’indicizzazione di ricerca e Perplexity-User per il recupero di contenuti in tempo reale. Perplexity ha affrontato segnalazioni aneddotiche di mancato rispetto delle direttive di robots.txt, anche se l’azienda dichiara di rispettarle. Amazonbot alimenta le capacità di risposta di Alexa e rispetta il protocollo robots.txt, operando a circa 1050 pagine/ora. Applebot-Extended, introdotto a giugno 2024, determina come i contenuti già indicizzati da Applebot verranno usati per l’addestramento AI di Apple, anche se non esegue direttamente la scansione delle pagine web. CCBot, gestito da Common Crawl (organizzazione non-profit), costruisce archivi web aperti utilizzati da molteplici aziende AI tra cui OpenAI, Google, Meta e Hugging Face. Crawler emergenti di aziende come xAI (Grok), Mistral e DeepSeek stanno iniziando ad apparire nei log dei server, segnalando un’ulteriore espansione dell’ecosistema dei crawler AI.
Di seguito una tabella di riferimento completa dei crawler AI verificati, con i loro scopi, user agent e sintassi di blocco robots.txt. Questa tabella viene aggiornata regolarmente sulla base dell’analisi dei log e della documentazione ufficiale. Ogni voce è stata verificata rispetto alle liste IP ufficiali quando disponibili:
| Nome Crawler | Azienda | Scopo | User Agent | Frequenza Scan | Verifica IP | Sintassi robots.txt |
|---|---|---|---|---|---|---|
| GPTBot | OpenAI | Raccolta dati per addestramento | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) | 100/ora | ✓ Ufficiale | User-agent: GPTBot Disallow: / |
| ChatGPT-User | OpenAI | Richieste utente in tempo reale | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0 | 2400/ora | ✓ Ufficiale | User-agent: ChatGPT-User Disallow: / |
| OAI-SearchBot | OpenAI | Indicizzazione ricerca | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3 | 150/ora | ✓ Ufficiale | User-agent: OAI-SearchBot Disallow: / |
| ClaudeBot | Anthropic | Raccolta dati per addestramento | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | 500/ora | ✓ Ufficiale | User-agent: ClaudeBot Disallow: / |
| Claude-User | Anthropic | Accesso web in tempo reale | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0) | <10/ora | ✗ Non disponibile | User-agent: Claude-User Disallow: / |
| Claude-SearchBot | Anthropic | Indicizzazione ricerca | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0) | <10/ora | ✗ Non disponibile | User-agent: Claude-SearchBot Disallow: / |
| Google-Extended | Addestramento Gemini AI | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0) | Variabile | ✓ Ufficiale | User-agent: Google-Extended Disallow: / | |
| Gemini-Deep-Research | Funzione ricerca | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research) | <10/ora | ✓ Ufficiale | User-agent: Gemini-Deep-Research Disallow: / | |
| Bingbot | Microsoft | Bing search & Copilot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0) | 1300/ora | ✓ Ufficiale | User-agent: Bingbot Disallow: / |
| Meta-ExternalAgent | Meta | Addestramento modelli AI | meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) | 1100/ora | ✗ Non disponibile | User-agent: Meta-ExternalAgent Disallow: / |
| Amazonbot | Amazon | Miglioramento servizi | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1) | 1050/ora | ✓ Ufficiale | User-agent: Amazonbot Disallow: / |
| Applebot-Extended | Apple | Addestramento AI | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15; compatible; Applebot-Extended | <10/ora | ✓ Ufficiale | User-agent: Applebot-Extended Disallow: / |
| PerplexityBot | Perplexity | Indicizzazione ricerca | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0) | 150/ora | ✓ Ufficiale | User-agent: PerplexityBot Disallow: / |
| Perplexity-User | Perplexity | Recupero in tempo reale | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0) | <10/ora | ✓ Ufficiale | User-agent: Perplexity-User Disallow: / |
| Bytespider | ByteDance | Addestramento AI | Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36; compatible; Bytespider | <10/ora | ✗ Non disponibile | User-agent: Bytespider Disallow: / |
| CCBot | Common Crawl | Dataset aperto | CCBot/2.0 (https://commoncrawl.org/faq/ ) | <10/ora | ✓ Ufficiale | User-agent: CCBot Disallow: / |
| DuckAssistBot | DuckDuckGo | Ricerca AI | DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) | 20/ora | ✓ Ufficiale | User-agent: DuckAssistBot Disallow: / |
| Diffbot | Diffbot | Estrazione dati | Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.2) Gecko/20090729 Firefox/3.5.2 Diffbot/0.1 | <10/ora | ✗ Non disponibile | User-agent: Diffbot Disallow: / |
| MistralAI-User | Mistral | Recupero in tempo reale | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; MistralAI-User/1.0) | <10/ora | ✗ Non disponibile | User-agent: MistralAI-User Disallow: / |
| ICC-Crawler | NICT | Addestramento AI/ML | ICC-Crawler/3.0 (Mozilla-compatible; https://ucri.nict.go.jp/en/icccrawler.html ) | <10/ora | ✗ Non disponibile | User-agent: ICC-Crawler Disallow: / |
Non tutti i crawler AI servono lo stesso scopo e comprendere queste distinzioni è fondamentale per prendere decisioni informate su cosa bloccare. I crawler di addestramento rappresentano circa l’80% di tutto il traffico bot AI e raccolgono contenuti specificamente per costruire dataset per lo sviluppo di grandi modelli linguistici. Una volta che i tuoi contenuti entrano in un dataset di addestramento, fanno parte permanentemente della base di conoscenza del modello, riducendo potenzialmente la necessità degli utenti di visitare il tuo sito per risposte. I crawler di addestramento come GPTBot, ClaudeBot e Meta-ExternalAgent operano con alti volumi e schemi di scansione sistematici, restituendo pochissimo traffico di referenza agli editori.
I crawler di ricerca e citazione indicizzano contenuti per esperienze di ricerca AI e possono effettivamente inviare un po’ di traffico agli editori tramite citazioni. Quando gli utenti fanno domande in ChatGPT o Perplexity, questi crawler aiutano ad evidenziare fonti rilevanti. A differenza dei crawler di addestramento, i crawler di ricerca come OAI-SearchBot e PerplexityBot operano a volume moderato con comportamento orientato al recupero e possono includere attribuzioni e link. I fetcher attivati dall’utente si attivano solo quando gli utenti richiedono specificatamente contenuti tramite assistenti AI. Quando qualcuno incolla un URL in ChatGPT o chiede a Perplexity di analizzare una pagina specifica, questi fetcher recuperano il contenuto su richiesta. I fetcher attivati dall’utente operano a volume molto basso con richieste isolate e la maggior parte delle aziende AI conferma che non vengono usati per l’addestramento dei modelli. Comprendere queste categorie ti aiuta a prendere decisioni strategiche su quali crawler consentire e quali bloccare in base alle priorità aziendali.
Il primo passo nella gestione dei crawler AI è capire quali visitano effettivamente il tuo sito. I log di accesso del server contengono registrazioni dettagliate di ogni richiesta, inclusa la stringa user agent che identifica il crawler. La maggior parte dei pannelli di controllo di hosting offre strumenti di analisi log, ma puoi anche accedere direttamente ai log grezzi. Per i server Apache, i log si trovano tipicamente in /var/log/apache2/access.log, mentre per Nginx sono solitamente in /var/log/nginx/access.log. Puoi filtrare questi log con grep per trovare l’attività dei crawler:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Questo comando mostra le 20 richieste più recenti dai principali crawler AI. Google Search Console fornisce statistiche sui crawler Google, anche se mostra solo quelli di Google. Cloudflare Radar offre approfondimenti globali sui pattern di traffico bot AI e può aiutare a identificare i crawler più attivi. Per verificare se un crawler è legittimo o falsificato, controlla l’indirizzo IP della richiesta rispetto alle liste IP ufficiali pubblicate dalle principali aziende. OpenAI pubblica IP verificati su https://openai.com/gptbot.json, Amazon su https://developer.amazon.com/amazonbot/ip-addresses/, e altri mantengono elenchi simili. Un crawler falso che falsifica uno user agent legittimo da un IP non verificato dovrebbe essere bloccato immediatamente, poiché probabilmente rappresenta attività di scraping malevolo.
Il file robots.txt è il tuo strumento primario per controllare l’accesso dei crawler. Questo semplice file di testo, posizionato nella directory principale del sito, indica ai crawler quali parti del sito possono accedere. Per bloccare specifici crawler AI, aggiungi voci come queste:
# Blocca GPTBot di OpenAI
User-agent: GPTBot
Disallow: /
# Blocca ClaudeBot di Anthropic
User-agent: ClaudeBot
Disallow: /
# Blocca AI training di Google (non la ricerca)
User-agent: Google-Extended
Disallow: /
# Blocca Common Crawl
User-agent: CCBot
Disallow: /
Puoi anche consentire i crawler ma impostare limiti di velocità per prevenire il sovraccarico del server:
User-agent: GPTBot
Crawl-delay: 10
Disallow: /private/
Questo dice a GPTBot di attendere 10 secondi tra una richiesta e l’altra e di non accedere alla directory privata. Per un approccio bilanciato che consente i crawler di ricerca ma blocca quelli di addestramento:
# Consenti i motori di ricerca tradizionali
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Blocca tutti i crawler AI di addestramento
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Consenti i crawler di ricerca AI
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
La maggior parte dei crawler AI affidabili rispetta le direttive di robots.txt, anche se alcuni crawler aggressivi le ignorano completamente. Ecco perché robots.txt da solo non basta per una protezione totale.
Robots.txt è consultivo e non vincolante, quindi i crawler possono ignorare le tue direttive se lo desiderano. Per una protezione più robusta contro i crawler che non rispettano robots.txt, implementa il blocco basato su IP a livello di server. Questo approccio è più affidabile perché è più difficile falsificare un indirizzo IP rispetto a uno user agent. Puoi consentire solo IP verificati da fonti ufficiali e bloccare tutte le altre richieste che si presentano come crawler AI.
Per server Apache, usa regole .htaccess per bloccare i crawler a livello server:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|anthropic-ai|Bytespider|CCBot) [NC]
RewriteRule .* - [F,L]
</IfModule>
Questo restituisce una risposta 403 Forbidden agli user agent corrispondenti, indipendentemente dalle impostazioni di robots.txt. Le regole firewall offrono un ulteriore livello di protezione consentendo solo range IP verificati da fonti ufficiali. La maggior parte dei firewall applicativi web e dei fornitori di hosting ti permette di creare regole che permettono solo richieste da IP verificati bloccando le altre. I meta tag HTML offrono controllo granulare a livello di pagina. Amazon e altri crawler rispettano la direttiva noarchive:
<meta name="robots" content="noarchive">
Questo dice ai crawler di non utilizzare la pagina per l’addestramento dei modelli, pur permettendo altre attività di indicizzazione. Scegli il metodo di blocco in base alle tue capacità tecniche e ai crawler specifici da bloccare. Il blocco IP è il più affidabile ma richiede più configurazione tecnica, mentre robots.txt è il più semplice da implementare ma meno efficace contro i crawler non conformi.
Implementare blocchi ai crawler è solo metà del lavoro; devi verificare che funzionino davvero. Il monitoraggio regolare ti aiuta a individuare problemi e a identificare nuovi crawler che non avevi mai incontrato. Controlla i log del server settimanalmente per attività insolite di bot, cercando user agent che contengono “bot”, “crawler”, “spider” o nomi aziendali come “GPT”, “Claude” o “Perplexity”. Imposta avvisi per aumenti improvvisi di traffico bot che potrebbero indicare nuovi crawler o comportamenti aggressivi da parte di bot esistenti. Google Search Console mostra statistiche di scansione per i bot Google, aiutandoti a monitorare le attività di Googlebot e Google-Extended. Cloudflare Radar offre approfondimenti globali sui pattern di traffico dei crawler AI e può aiutare a identificare crawler emergenti che visitano il tuo sito.
Per verificare che i blocchi robots.txt funzionino, accedi direttamente al tuo file robots.txt su iltuosito.com/robots.txt e verifica che tutti gli user agent e le direttive siano corretti. Per i blocchi a livello server, monitora i log di accesso per richieste da crawler bloccati. Se noti richieste da crawler che hai bloccato, stanno ignorando le direttive o falsificando gli user agent. Testa le implementazioni controllando gli accessi dei crawler tramite analytics e log server. Revisioni trimestrali sono essenziali perché il panorama dei crawler AI evolve rapidamente. Emergono regolarmente nuovi crawler, quelli esistenti aggiornano gli user agent e le aziende introducono nuovi bot senza preavviso. Pianifica revisioni regolari della blocklist per intercettare nuove aggiunte e assicurare che la tua implementazione sia aggiornata.
Gestire l’accesso dei crawler è importante, ma capire come i sistemi AI citano e fanno riferimento ai tuoi contenuti è altrettanto fondamentale. AmICited.com offre un monitoraggio completo di come il tuo brand e i tuoi contenuti appaiono nelle risposte generate da AI su ChatGPT, Perplexity, Google Gemini e altre piattaforme AI. Invece di limitarti a bloccare i crawler, AmICited.com ti aiuta a comprendere il reale impatto dei crawler AI sulla tua visibilità e autorità. La piattaforma traccia quali sistemi AI citano i tuoi contenuti, con quale frequenza il tuo brand appare nelle risposte AI e come questa visibilità si traduce in traffico e autorevolezza. Monitorando le citazioni AI, puoi prendere decisioni informate su quali crawler consentire in base a dati reali e non ad assunzioni. AmICited.com si integra nella tua strategia di contenuto complessiva, mostrandoti quali argomenti e tipologie di contenuti generano più citazioni AI. Questo approccio guidato dai dati ti aiuta a ottimizzare i tuoi contenuti per la scoperta AI proteggendo al contempo la proprietà intellettuale più preziosa. Comprendere le metriche di citazione AI ti consente di prendere decisioni strategiche sull’accesso dei crawler allineate agli obiettivi aziendali.
I crawler AI come GPTBot e ClaudeBot raccolgono contenuti specificamente per addestrare grandi modelli linguistici, mentre i crawler dei motori di ricerca come Googlebot indicizzano i contenuti affinché le persone possano trovarli tramite i risultati di ricerca. I crawler AI alimentano le basi di conoscenza dei sistemi di intelligenza artificiale, mentre i crawler di ricerca aiutano gli utenti a scoprire i tuoi contenuti. La differenza chiave è lo scopo: addestramento contro recupero.
No, bloccare i crawler AI non danneggerà il tuo posizionamento tradizionale nei motori di ricerca. I crawler AI come GPTBot e ClaudeBot sono completamente separati dai crawler dei motori di ricerca come Googlebot. Puoi bloccare Google-Extended (per l'addestramento AI) continuando a consentire Googlebot (per la ricerca). Ogni crawler ha uno scopo diverso e bloccarne uno non influisce sull'altro.
Controlla i log di accesso del server per vedere quali user agent stanno visitando il tuo sito. Cerca nomi di bot come GPTBot, ClaudeBot, CCBot e Bytespider nelle stringhe degli user agent. La maggior parte dei pannelli di controllo di hosting fornisce strumenti di analisi dei log. Puoi anche utilizzare Google Search Console per monitorare l'attività di scansione, anche se mostra solo i crawler di Google.
Non tutti i crawler AI rispettano allo stesso modo robots.txt. GPTBot di OpenAI, ClaudeBot di Anthropic e Google-Extended generalmente seguono le regole di robots.txt. Bytespider e PerplexityBot hanno ricevuto segnalazioni che suggeriscono che potrebbero non rispettare sempre le direttive di robots.txt. Per i crawler che non rispettano robots.txt, dovrai implementare il blocco basato su IP a livello di server tramite il firewall o il file .htaccess.
La decisione dipende dai tuoi obiettivi. Blocca i crawler di addestramento se hai contenuti proprietari o risorse server limitate. Consenti i crawler di ricerca se vuoi visibilità nei risultati di ricerca AI e chatbot, che possono generare traffico e stabilire autorità. Molte aziende adottano un approccio selettivo consentendo determinati crawler e bloccando quelli aggressivi come Bytespider.
Nuovi crawler AI emergono regolarmente, quindi rivedi e aggiorna la tua blocklist almeno ogni trimestre. Tieni traccia di risorse come il progetto ai.robots.txt su GitHub per liste mantenute dalla comunità. Controlla i log del server mensilmente per identificare nuovi crawler che visitano il tuo sito e che non sono nella tua configurazione attuale. Il panorama dei crawler AI evolve rapidamente e la tua strategia dovrebbe evolversi di conseguenza.
Sì, controlla l'indirizzo IP della richiesta rispetto alle liste IP ufficiali pubblicate dalle principali aziende. OpenAI pubblica IP verificati su https://openai.com/gptbot.json, Amazon su https://developer.amazon.com/amazonbot/ip-addresses/ e altri mantengono elenchi simili. Un crawler che falsifica uno user agent legittimo da un IP non verificato deve essere bloccato immediatamente poiché probabilmente rappresenta uno scraping dannoso.
I crawler AI possono consumare larghezza di banda e risorse del server significative. Bytespider e Meta-ExternalAgent sono tra i crawler più aggressivi. Alcuni editori riferiscono di aver ridotto il consumo di banda da 800GB a 200GB al giorno bloccando i crawler AI, risparmiando circa 1.500 dollari al mese. Monitora le risorse del server durante i picchi di scansione e implementa limiti di velocità per i bot aggressivi se necessario.
Monitora quali crawler AI citano i tuoi contenuti e ottimizza la tua visibilità su ChatGPT, Perplexity, Google Gemini e altri ancora.
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...

Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...

Guida completa ai crawler AI nel 2025. Identifica GPTBot, ClaudeBot, PerplexityBot e oltre 20 altri bot AI. Scopri come bloccare, consentire o monitorare i craw...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.