
Individuare i siti fonte LLM per backlink strategici
Scopri come individuare e mirare i siti fonte LLM per backlink strategici. Scopri quali piattaforme AI citano più spesso le fonti e ottimizza la tua strategia d...
11 min di lettura

Scopri come i Large Language Model selezionano e citano le fonti attraverso la ponderazione delle evidenze, il riconoscimento delle entità e i dati strutturati. Impara il processo decisionale di citazione in 7 fasi e ottimizza i tuoi contenuti per la visibilità AI.
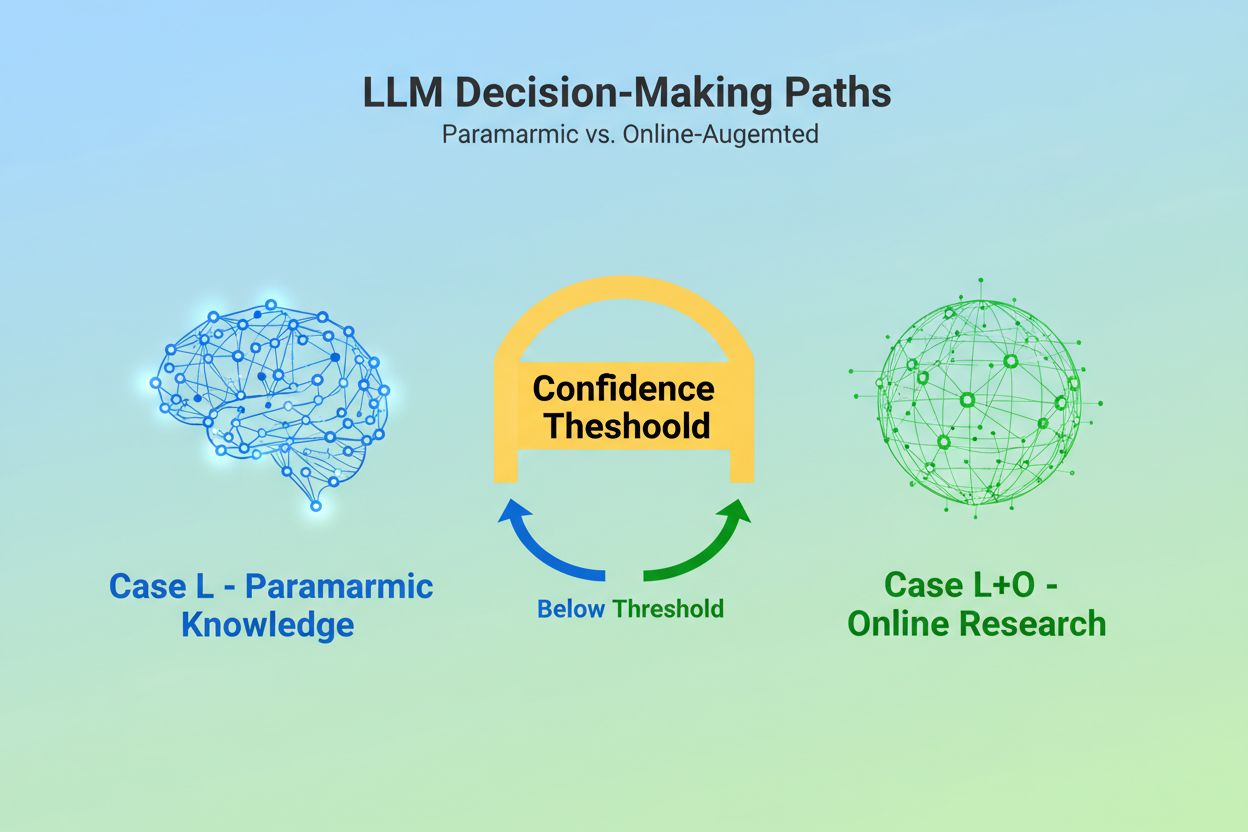
Quando un Large Language Model riceve una query, si trova di fronte a una decisione fondamentale: deve affidarsi solo alla conoscenza incorporata durante l’addestramento o deve cercare informazioni aggiornate sul web? Questa scelta binaria—quella che i ricercatori chiamano Caso L (solo dati di apprendimento) contro Caso L+O (dati di apprendimento più ricerca online)—determina se un LLM citerà fonti esterne. In modalità Caso L, il modello attinge esclusivamente dalla propria base di conoscenza parametrica, una rappresentazione condensata dei pattern appresi durante l’addestramento che tipicamente riflette informazioni risalenti a diversi mesi o più di un anno prima della pubblicazione del modello. In modalità Caso L+O, il modello attiva una soglia di fiducia che fa scattare la ricerca esterna, aprendo quello che i ricercatori chiamano lo “spazio candidato” di URL e fonti. Questo punto decisionale è invisibile alla maggior parte degli strumenti di monitoraggio, eppure è qui che ha inizio l’intero meccanismo di citazione—perché senza l’attivazione della fase di ricerca, nessuna fonte esterna può essere valutata o citata.
Nel momento in cui un LLM decide di cercare fonti esterne, entra nella fase più critica per la selezione delle citazioni: la ponderazione delle evidenze. Qui si decide la differenza tra una semplice menzione e una raccomandazione autorevole. Il modello non si limita a contare quante volte appare una fonte o a quanto sia alta nei risultati di ricerca; valuta invece l’integrità strutturale dell’evidenza stessa. Analizza l’architettura del documento—se le fonti contengono relazioni dati chiare, identificativi ricorrenti e link di riferimento—interpretando questi elementi come segnali di affidabilità. Il modello costruisce quello che i ricercatori chiamano “grafo delle evidenze”, dove i nodi rappresentano entità e gli archi rappresentano le relazioni tra documenti. Ogni fonte viene ponderata non solo per la rilevanza del contenuto, ma anche per la coerenza delle conferme tra più documenti, la pertinenza tematica delle informazioni e l’autorevolezza del dominio. Questa valutazione multidimensionale crea quella che viene definita matrice delle evidenze, una valutazione complessiva che stabilisce quali fonti sono abbastanza affidabili da essere citate. Criticamente, questa fase opera nello strato di ragionamento dell’LLM, rendendola invisibile agli strumenti GEO tradizionali che misurano solo i segnali di recupero.
I dati strutturati—soprattutto JSON-LD, markup Schema.org e RDFa—funzionano da moltiplicatore nel processo di ponderazione delle evidenze. Le fonti che implementano correttamente i dati strutturati ricevono un peso 2-3 volte superiore nella matrice delle evidenze rispetto ai contenuti non strutturati. Non è una questione estetica: i dati strutturati abilitano il collegamento delle entità, ovvero la capacità di collegare menzioni su documenti diversi tramite identificativi leggibili dalla macchina come @id, sameAs e Q-ID (identificativi Wikidata). Quando un LLM incontra una fonte con un Q-ID per un’organizzazione, può verificarne immediatamente l’identità su più documenti, creando quello che i ricercatori chiamano “coreferenza d’entità cross-documentale”. Questo processo di verifica aumenta drasticamente la fiducia nell’affidabilità della fonte.
| Formato Dati | Accuratezza Citazione | Collegamento Entità | Verifica Cross-Documentale |
|---|---|---|---|
| Testo Non Strutturato | 62% | Nessuno | Inferenza manuale |
| Markup HTML Base | 71% | Limitato | Corrispondenza parziale |
| RDFa/Microdata | 81% | Buono | Basato su pattern |
| JSON-LD con Q-ID | 94% | Eccellente | Link verificati |
| Formato Knowledge Graph | 97% | Perfetto | Verifica automatica |
L’impatto dei dati strutturati si manifesta su due assi temporali. Transitoriamente, quando un LLM cerca online, legge in tempo reale JSON-LD e markup Schema.org, integrando immediatamente queste informazioni strutturate nella ponderazione delle evidenze per la risposta corrente. In modo persistente, i dati strutturati che restano coerenti nel tempo vengono integrati nella base di conoscenza parametrica del modello durante i cicli di addestramento futuri, influenzando il modo in cui il modello riconosce e valuta le entità anche senza ricerca online. Questo doppio meccanismo fa sì che i brand che implementano dati strutturati corretti ottengano sia visibilità immediata nelle citazioni sia autorevolezza a lungo termine nello spazio di conoscenza interno del modello.
Prima che un LLM possa citare una fonte, deve prima capire di cosa tratta quella fonte e chi rappresenta. Questo è il compito del riconoscimento delle entità, un processo che trasforma il linguaggio umano ambiguo in entità leggibili dalle macchine. Quando un documento menziona “Apple”, l’LLM deve determinare se si riferisce ad Apple Inc., al frutto o a qualcos’altro. Il modello risolve ciò attraverso pattern di entità addestrati su Wikipedia, Wikidata e Common Crawl, insieme all’analisi contestuale del testo circostante. In modalità Caso L+O, il processo si fa ancora più sofisticato: il modello verifica le entità rispetto a dati strutturati esterni, controllando attributi @id, collegamenti sameAs e Q-ID che forniscono identificazione definitiva. Questo passaggio di verifica è fondamentale perché riferimenti ambigui o incoerenti alle entità si perdono nel rumore del ragionamento del modello. Un brand che utilizza convenzioni di denominazione incoerenti, non istituisce identificativi chiari per le entità o non implementa il markup Schema.org risulta semanticamente poco chiaro alla macchina—apparendo come entità diverse invece che come una fonte unica e coerente. Al contrario, organizzazioni con entità stabili e referenziate coerentemente su più documenti vengono riconosciute come nodi affidabili nel knowledge graph dell’LLM, aumentando significativamente la probabilità di citazione.
Il percorso che va dalla query alla citazione segue un processo strutturato in sette fasi che i ricercatori hanno tracciato analizzando il comportamento degli LLM. Fase 0: Analisi dell’Intento inizia quando il modello tokenizza l’input dell’utente, esegue un’analisi semantica e crea un vettore di intento—una rappresentazione astratta di ciò che l’utente sta effettivamente chiedendo. Questa fase determina quali argomenti, entità e relazioni siano pertinenti da considerare. Fase 1: Recupero della Conoscenza Interna accede alla conoscenza parametrica del modello e calcola un punteggio di fiducia. Se questo supera una certa soglia, il modello resta in modalità Caso L; in caso contrario, passa alla ricerca esterna. Fase 2: Generazione di Query Fan-Out (solo Caso L+O) crea più query di ricerca semanticamente diverse—tipicamente da 1 a 6 token ciascuna—per aprire lo spazio candidato il più possibile. Fase 3: Estrazione delle Evidenze recupera URL e snippet dai risultati di ricerca, analizza l’HTML ed estrae JSON-LD, RDFa e microdati. Qui i dati strutturati diventano visibili per la prima volta al meccanismo di citazione. Fase 4: Collegamento delle Entità identifica le entità nei documenti recuperati e le verifica rispetto agli identificativi esterni, creando un knowledge graph temporaneo di relazioni. Fase 5: Ponderazione delle Evidenze valuta la forza delle evidenze da tutte le fonti, considerando l’architettura dei documenti, la diversità delle fonti, la frequenza di conferma e la coerenza tra le fonti. Fase 6: Ragionamento e Sintesi combina evidenze interne ed esterne, risolve le contraddizioni e determina se ogni fonte meriti una menzione o una raccomandazione. Fase 7: Costruzione della Risposta Finale traduce le evidenze ponderate in linguaggio naturale, integrando citazioni dove appropriato. Ogni fase alimenta la successiva, con loop di feedback che consentono al modello di affinare la ricerca o rivalutare le evidenze se emergono incongruenze.
Gli LLM moderni adottano sempre più spesso la Retrieval-Augmented Generation (RAG), una tecnica che cambia radicalmente il modo in cui le citazioni vengono selezionate e giustificate. Invece di affidarsi solo alla conoscenza parametrica, i sistemi RAG recuperano attivamente documenti rilevanti, estraggono evidenze e fondano le risposte su fonti specifiche. Questo approccio trasforma la citazione da sottoprodotto implicito dell’addestramento a processo esplicito e tracciabile. Le implementazioni RAG usano tipicamente la ricerca ibrida, combinando recupero basato su keyword con ricerca per similarità vettoriale per massimizzare il richiamo. Una volta recuperati i documenti candidati, il ranking semantico riordina i risultati in base al significato, non solo alla corrispondenza delle parole chiave, assicurando che le fonti più rilevanti emergano in cima. Questo meccanismo di recupero esplicito rende il processo di citazione più trasparente e verificabile—ogni fonte citata può essere ricondotta a passaggi specifici che ne hanno giustificato l’inclusione. Per le organizzazioni che monitorano la propria visibilità AI, i sistemi basati su RAG sono particolarmente importanti perché generano pattern di citazione misurabili. Strumenti come AmICited tracciano come i sistemi RAG fanno riferimento al tuo brand su varie piattaforme AI, offrendo insight su se appari come fonte citata o solo come materiale di background nella fase di recupero delle evidenze.
Non tutte le citazioni sono uguali. Un LLM può menzionare una fonte come contesto di background mentre ne raccomanda un’altra come evidenza autorevole—e questa distinzione dipende interamente dalla ponderazione delle evidenze, non dal semplice recupero. Una fonte può comparire nello spazio candidato (Fase 2-3) ma non raggiungere lo status di raccomandazione se il suo punteggio di evidenza è insufficiente. Questa separazione tra menzione e raccomandazione è il punto in cui le metriche GEO tradizionali falliscono. Gli strumenti di monitoraggio standard misurano il fan-out—cioè se il tuo contenuto appare nei risultati di ricerca—ma non possono misurare se l’LLM considera realmente il tuo contenuto abbastanza affidabile da raccomandare. Una menzione potrebbe suonare come “Alcune fonti suggeriscono…”, mentre una raccomandazione come “Secondo [Fonte], le evidenze mostrano…”. La differenza sta nel punteggio della matrice delle evidenze della Fase 5. Le fonti con Q-ID coerenti, architettura documentale ben strutturata e conferme su più fonti indipendenti raggiungono lo status di raccomandazione. Fonti con riferimenti ambigui alle entità, scarsa coerenza strutturale o affermazioni isolate restano menzioni. Per i brand, questa distinzione è cruciale: essere recuperati non equivale a essere citati come autorevoli. Il passaggio dal recupero alla raccomandazione richiede chiarezza semantica, integrità strutturale e densità di evidenze—fattori che la SEO tradizionale non affronta.
Comprendere come gli LLM selezionano le fonti ha implicazioni immediate e concrete per la strategia dei contenuti. Primo, implementa in modo coerente il markup Schema.org sul tuo sito, in particolare per informazioni organizzative, articoli e entità chiave. Usa il formato JSON-LD con attributi @id e collegamenti sameAs a Wikidata, Wikipedia o altre fonti autorevoli. Questi dati strutturati aumentano direttamente il peso della tua evidenza nella Fase 5. Secondo, stabilisci identificativi chiari per le entità della tua organizzazione, prodotti e concetti chiave. Usa convenzioni di denominazione coerenti, evita abbreviazioni che creano ambiguità e collega entità correlate tramite relazioni gerarchiche (isPartOf, about, mentions). Terzo, crea evidenze leggibili dalle macchine pubblicando dati strutturati su affermazioni, credenziali e relazioni. Non scrivere solo “Siamo il principale fornitore di X”—struttura questa affermazione con dati di supporto, citazioni e relazioni verificabili. Quarto, mantieni la coerenza dei contenuti su più piattaforme e nel tempo. Gli LLM valutano la densità delle evidenze verificando se le affermazioni sono confermate su fonti indipendenti; affermazioni isolate su una sola piattaforma pesano meno. Quinto, comprendi che le metriche SEO tradizionali non predicono la citazione AI. Alti posizionamenti nei motori di ricerca non garantiscono raccomandazioni LLM; concentrati invece su chiarezza semantica e integrità strutturale. Sesto, monitora i tuoi pattern di citazione usando strumenti come AmICited, che tracciano come i diversi sistemi AI fanno riferimento al tuo brand. Questo ti permette di capire se raggiungi lo status di menzione o raccomandazione, e quali tipi di contenuto attivano citazioni. Infine, ricorda che la visibilità AI è un investimento a lungo termine. I dati strutturati che implementi oggi influenzano sia la probabilità immediata di citazione (effetto transitorio) sia la base di conoscenza interna del modello nei futuri cicli di addestramento (effetto persistente).
Man mano che gli LLM evolvono, i meccanismi di citazione diventano sempre più sofisticati e trasparenti. I modelli futuri probabilmente implementeranno veri e propri grafi di citazione—mappe esplicite che mostrano non solo quali fonti sono state citate, ma anche come hanno influenzato affermazioni specifiche della risposta. Alcuni sistemi avanzati stanno già sperimentando punteggi probabilistici di fiducia associati alle citazioni, indicando quanto il modello sia certo della rilevanza e affidabilità della fonte. Un’altra tendenza emergente è la verifica con l’intervento umano, dove gli utenti possono contestare le citazioni e fornire feedback che affina la ponderazione delle evidenze del modello per le query future. L’integrazione dei dati strutturati nei cicli di addestramento significa che le organizzazioni che oggi costruiscono una solida infrastruttura semantica stanno, di fatto, consolidando la propria autorevolezza nel tempo nei sistemi AI. A differenza dei ranking dei motori di ricerca, che possono oscillare in base agli aggiornamenti degli algoritmi, l’effetto persistente dei dati strutturati crea basi più stabili per la visibilità AI. Questo passaggio dalla visibilità tradizionale (essere trovati) all’autorità semantica (essere ritenuti affidabili) rappresenta un cambiamento fondamentale nell’approccio alla comunicazione digitale. I vincitori in questo nuovo panorama non saranno coloro che hanno più contenuti o i ranking più alti sui motori di ricerca, ma chi struttura le proprie informazioni in modo che le macchine possano comprenderle, verificarle e raccomandarle con affidabilità.
Il Caso L utilizza solo i dati di addestramento della base di conoscenza parametrica del modello, mentre il Caso L+O li integra con ricerche web in tempo reale. La soglia di fiducia del modello determina quale percorso viene seguito. Questa distinzione è fondamentale perché stabilisce se le fonti esterne possano essere valutate e citate o meno.
La ponderazione delle evidenze determina questa distinzione. Le fonti con dati strutturati, identificativi coerenti e conferme cross-documentali vengono elevate a 'raccomandazioni' anziché semplici menzioni. Una fonte può apparire nei risultati di ricerca ma non raggiungere lo status di raccomandazione se il suo punteggio di evidenza è insufficiente.
I dati strutturati (JSON-LD, @id, sameAs, Q-ID) ricevono un peso 2-3 volte superiore nelle matrici di evidenza. Questo markup abilita il collegamento delle entità e la verifica cross-documentale, aumentando notevolmente il punteggio di affidabilità della fonte. Le fonti con una corretta implementazione Schema.org hanno molte più probabilità di essere citate come autorevoli.
Il riconoscimento delle entità è il modo in cui gli LLM identificano e distinguono tra entità diverse (organizzazioni, persone, concetti). Un’identificazione chiara tramite denominazioni coerenti e identificativi strutturati previene ambiguità e aumenta la probabilità di citazione. I riferimenti ambigui alle entità si perdono nel processo di ragionamento del modello.
I sistemi RAG recuperano e classificano attivamente le fonti in tempo reale, rendendo la selezione delle citazioni più trasparente e basata sulle evidenze rispetto alla sola conoscenza parametrica. Questo meccanismo di recupero esplicito genera pattern di citazione misurabili che possono essere tracciati e analizzati tramite strumenti di monitoraggio come AmICited.
Sì. Implementa in modo coerente il markup Schema.org, stabilisci identificativi chiari per le entità, crea evidenze leggibili dalle macchine, mantieni la coerenza dei contenuti sulle piattaforme e monitora i tuoi pattern di citazione. Questi fattori influenzano direttamente se i tuoi contenuti raggiungono lo status di menzione o raccomandazione nelle risposte degli LLM.
La visibilità tradizionale misura la portata e il posizionamento nei risultati di ricerca. La visibilità AI misura se i tuoi contenuti sono riconosciuti come evidenze autorevoli nei processi di ragionamento degli LLM. Essere recuperati non è lo stesso che essere citati come affidabili—questo richiede chiarezza semantica e integrità strutturale.
AmICited traccia come i sistemi AI fanno riferimento al tuo brand su GPT, Perplexity e Google AI Overviews. Mostra se raggiungi lo status di menzione o raccomandazione, quali tipi di contenuto attivano citazioni e come i tuoi pattern di citazione si confrontano sulle diverse piattaforme AI.
Comprendi come gli LLM fanno riferimento al tuo brand su ChatGPT, Perplexity e Google AI Overviews. Traccia i pattern di citazione e ottimizza per la visibilità AI con AmICited.
Scopri come individuare e mirare i siti fonte LLM per backlink strategici. Scopri quali piattaforme AI citano più spesso le fonti e ottimizza la tua strategia d...

Scopri come il grounding degli LLM e la ricerca sul web consentono ai sistemi AI di accedere a informazioni in tempo reale, ridurre le allucinazioni e fornire c...

Scopri cos'è l'LLMO, come funziona e perché è importante per la visibilità nell'IA. Scopri tecniche di ottimizzazione per far menzionare il tuo brand in ChatGPT...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.