Motore di Ricerca AI
Scopri cosa sono i motori di ricerca AI, come si differenziano dalla ricerca tradizionale e il loro impatto sulla visibilità del brand. Esplora piattaforme come...
14 min di lettura

Scopri come funzionano i motori di ricerca AI come ChatGPT, Perplexity e Google AI Overviews. Scopri LLM, RAG, ricerca semantica e meccanismi di recupero in tempo reale.
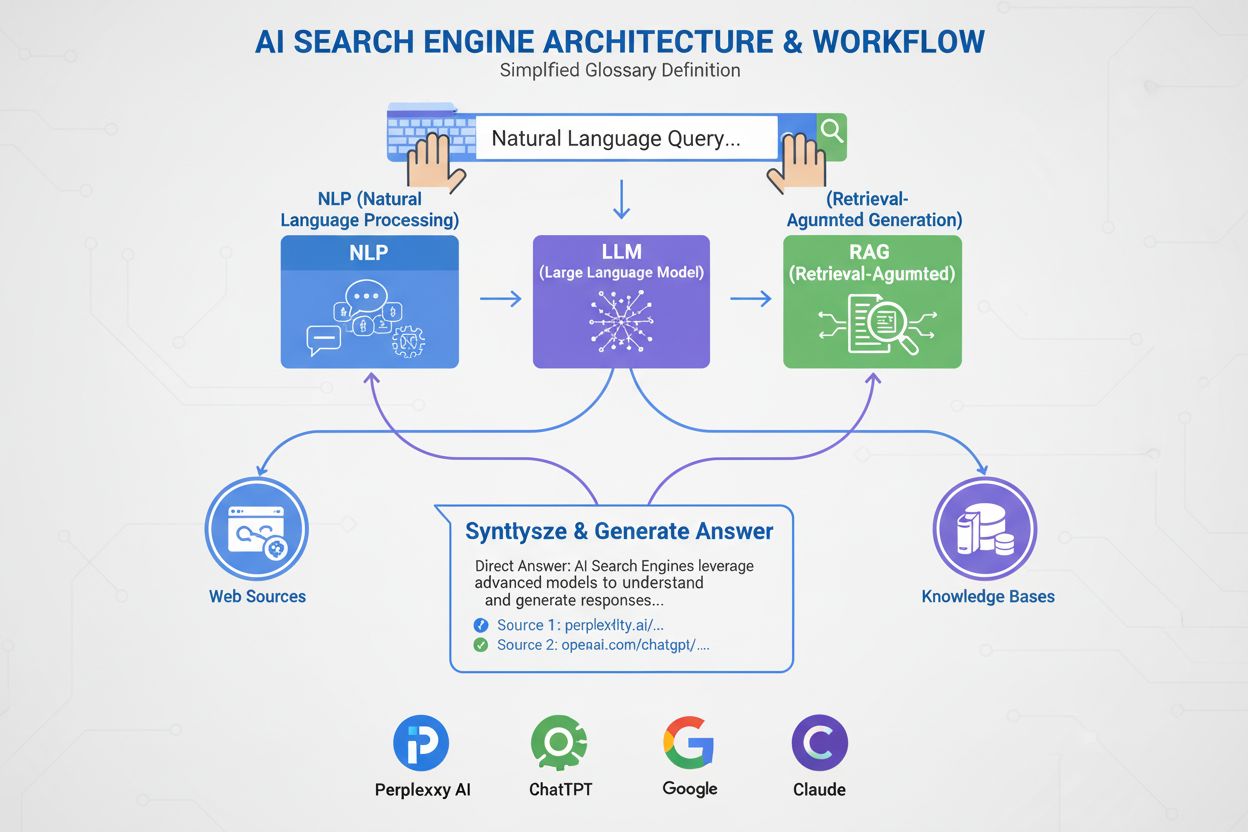
I motori di ricerca AI utilizzano grandi modelli linguistici (LLM) combinati con la generazione aumentata dal recupero (RAG) per comprendere l'intento dell'utente e recuperare informazioni rilevanti dal web in tempo reale. Elaborano le query attraverso la comprensione semantica, gli embedding vettoriali e i grafi della conoscenza per fornire risposte conversazionali con citazioni delle fonti, a differenza dei motori di ricerca tradizionali che restituiscono elenchi ordinati di siti web.
I motori di ricerca AI rappresentano un cambiamento fondamentale rispetto alla ricerca tradizionale basata sulle parole chiave, passando a un recupero informativo conversazionale e guidato dall’intento. Diversamente dal motore di ricerca tradizionale di Google che esegue il crawling, indicizza e classifica i siti web per restituire un elenco di link, motori di ricerca AI come ChatGPT, Perplexity, Google AI Overviews e Claude generano risposte originali combinando più tecnologie. Queste piattaforme comprendono ciò che gli utenti cercano realmente, recuperano informazioni rilevanti da fonti autorevoli e sintetizzano tali informazioni in risposte coerenti e citate. La tecnologia che alimenta questi sistemi sta trasformando il modo in cui le persone scoprono informazioni online, con ChatGPT che elabora 2 miliardi di query al giorno e AI Overviews che compaiono nel 18% delle ricerche Google a livello globale. Comprendere come funzionano questi sistemi è fondamentale per creatori di contenuti, marketer e aziende che cercano visibilità in questo nuovo panorama di ricerca.
I motori di ricerca AI funzionano attraverso tre sistemi interconnessi che collaborano per fornire risposte accurate e con fonti. Il primo componente è il Large Language Model (LLM), addestrato su enormi quantità di dati testuali per comprendere i modelli linguistici, la struttura e le sfumature del linguaggio. Modelli come GPT-4 di OpenAI, Gemini di Google e Claude di Anthropic sono addestrati tramite apprendimento non supervisionato su miliardi di documenti, permettendo loro di prevedere quali parole dovrebbero seguire in base ai modelli statistici appresi durante l’addestramento. Il secondo componente è il modello di embedding, che converte parole e frasi in rappresentazioni numeriche chiamate vettori. Questi vettori catturano il significato semantico e le relazioni tra concetti, consentendo al sistema di comprendere che “gaming laptop” e “computer ad alte prestazioni” sono semanticamente correlati anche se non condividono parole chiave esatte. Il terzo componente critico è la Retrieval-Augmented Generation (RAG), che integra i dati di addestramento dell’LLM recuperando informazioni aggiornate da basi di conoscenza esterne in tempo reale. Questo è essenziale perché gli LLM hanno una data di cutoff dell’addestramento e non possono accedere a informazioni aggiornate senza RAG. Insieme, questi tre componenti permettono ai motori di ricerca AI di fornire risposte aggiornate, accurate e citate, invece di informazioni inventate o obsolete.
La Retrieval-Augmented Generation è il processo che consente ai motori di ricerca AI di basare le proprie risposte su fonti autorevoli, invece di affidarsi esclusivamente ai dati di addestramento. Quando invii una query a un motore di ricerca AI, il sistema converte prima la tua domanda in una rappresentazione vettoriale utilizzando il modello di embedding. Questo vettore viene quindi confrontato con un database di contenuti web indicizzati, anch’essi convertiti in vettori, utilizzando tecniche come la similarità coseno per identificare i documenti più rilevanti. Il sistema RAG recupera questi documenti e li passa all’LLM insieme alla tua query originale. L’LLM utilizza quindi sia le informazioni recuperate sia i dati di addestramento per generare una risposta che fa riferimento diretto alle fonti consultate. Questo approccio risolve diversi problemi critici: garantisce risposte aggiornate e fattuali, permette agli utenti di verificare le informazioni tramite le citazioni delle fonti e offre ai creatori di contenuti l’opportunità di essere citati nelle risposte AI. Azure AI Search e AWS Bedrock sono implementazioni enterprise di RAG che dimostrano come le organizzazioni possano costruire sistemi di ricerca AI personalizzati. La qualità di RAG dipende fortemente da quanto il sistema di recupero identifica documenti rilevanti, motivo per cui ranking semantico e ricerca ibrida (che combina ricerca per parola chiave e vettoriale) sono diventate tecniche essenziali per migliorare l’accuratezza.
La ricerca semantica è la tecnologia che permette ai motori di ricerca AI di comprendere il significato invece di limitarsi a corrispondere le parole chiave. I motori di ricerca tradizionali cercano corrispondenze esatte di parole chiave, ma la ricerca semantica analizza l’intento e il significato contestuale di una query. Quando cerchi “smartphone economici con buone fotocamere”, un motore di ricerca semantico comprende che desideri telefoni economici con ottime capacità fotografiche, anche se i risultati non contengono esattamente quelle parole. Questo è reso possibile dagli embedding vettoriali, che rappresentano il testo come array numerici ad alta dimensionalità. Modelli avanzati come BERT (Bidirectional Encoder Representations from Transformers) e text-embedding-3-small di OpenAI convertono parole, frasi e documenti interi in vettori dove i contenuti semanticamente simili sono posizionati vicini nello spazio vettoriale. Il sistema calcola quindi la similarità vettoriale usando tecniche matematiche come la similarità coseno per trovare i documenti più allineati all’intento della query. Questo approccio è molto più efficace della corrispondenza per parola chiave perché cattura le relazioni tra concetti. Ad esempio, il sistema comprende che “gaming laptop” e “computer ad alte prestazioni con GPU” sono correlati anche se non condividono parole chiave. I grafi della conoscenza aggiungono un ulteriore livello creando reti strutturate di relazioni semantiche, collegando concetti come “laptop” a “processore”, “RAM” e “GPU” per migliorare la comprensione. Questo approccio multilivello alla comprensione semantica è il motivo per cui i motori di ricerca AI possono offrire risultati rilevanti per query complesse e conversazionali che mettono in difficoltà i motori di ricerca tradizionali.
| Tecnologia di Ricerca | Come Funziona | Punti di Forza | Limitazioni |
|---|---|---|---|
| Ricerca per Parole Chiave | Corrisponde parole o frasi esatte della query ai contenuti indicizzati | Veloce, semplice, prevedibile | Non gestisce sinonimi, errori di battitura e intenti complessi |
| Ricerca Semantica | Comprende significato e intento usando NLP ed embedding | Gestisce sinonimi, contesto e query complesse | Richiede più risorse computazionali |
| Ricerca Vettoriale | Converte testo in vettori numerici e calcola la similarità | Corrispondenza precisa di similarità, scalabile | Si concentra sulla distanza matematica, non sul contesto |
| Ricerca Ibrida | Combina ricerca per parola chiave e vettoriale | Il meglio di entrambi per accuratezza e richiamo | Più complessa da implementare e ottimizzare |
| Ricerca con Grafo della Conoscenza | Usa relazioni strutturate tra concetti | Aggiunge ragionamento e contesto ai risultati | Richiede cura e manutenzione manuale |
Uno dei maggiori vantaggi dei motori di ricerca AI rispetto agli LLM tradizionali è la loro capacità di accedere a informazioni in tempo reale dal web. Quando chiedi a ChatGPT una domanda su eventi attuali, utilizza un bot chiamato ChatGPT-User per eseguire il crawling dei siti web in tempo reale e recuperare informazioni aggiornate. Perplexity effettua anch’esso ricerche in tempo reale su Internet per raccogliere dati da fonti di alto livello, motivo per cui può rispondere su eventi avvenuti dopo il cutoff dei suoi dati di addestramento. Google AI Overviews sfrutta l’indice web e l’infrastruttura di crawling di Google per recuperare informazioni aggiornate. Questa capacità di recupero in tempo reale è essenziale per mantenere accuratezza e rilevanza. Il processo di recupero prevede diversi passaggi: innanzitutto, il sistema suddivide la tua query in più sottoquery correlate tramite un processo chiamato query fan-out, che aiuta a recuperare informazioni più complete. Successivamente, il sistema ricerca nei contenuti web indicizzati utilizzando sia la corrispondenza per parola chiave sia quella semantica per identificare le pagine rilevanti. I documenti recuperati vengono classificati per rilevanza tramite algoritmi di ranking semantico che riclassificano i risultati in base al significato e non solo alla frequenza delle parole chiave. Infine, il sistema estrae i passaggi più rilevanti da questi documenti e li passa all’LLM per la generazione della risposta. Questo intero processo avviene in pochi secondi, motivo per cui gli utenti si aspettano risposte AI entro 3-5 secondi. La velocità e l’accuratezza di questo recupero incidono direttamente sulla qualità della risposta finale, rendendo il recupero efficiente delle informazioni un componente critico dell’architettura dei motori di ricerca AI.
Una volta che il sistema RAG ha recuperato le informazioni rilevanti, il Large Language Model le utilizza per generare una risposta. Gli LLM non “comprendono” il linguaggio come un essere umano; utilizzano invece modelli statistici per prevedere quali parole dovrebbero seguire, basandosi su modelli appresi durante l’addestramento. Quando inserisci una query, l’LLM la converte in una rappresentazione vettoriale e la elabora tramite una rete neurale composta da milioni di nodi interconnessi. Questi nodi hanno appreso i pesi delle connessioni durante l’addestramento, determinando quanto ciascuna connessione influisca sulle altre. L’LLM non restituisce una singola previsione per la parola successiva; invece, restituisce una lista classificata di probabilità. Ad esempio, potrebbe prevedere una probabilità del 4,5% che la parola successiva sia “imparare” e del 3,5% che sia “prevedere”. Il sistema non sceglie sempre la parola con la probabilità più alta; a volte seleziona parole con probabilità inferiore per rendere le risposte più naturali e creative. Questa casualità è controllata dal parametro di temperatura, che va da 0 (deterministico) a 1 (molto creativo). Dopo aver generato la prima parola, il sistema ripete questo processo per la successiva, e così via, fino a generare una risposta completa. Questo processo di generazione token per token è il motivo per cui le risposte AI spesso appaiono conversazionali e naturali: il modello sta essenzialmente prevedendo la continuazione più probabile di una conversazione. La qualità della risposta generata dipende sia dalla qualità delle informazioni recuperate sia dalla sofisticazione dell’addestramento dell’LLM.
Diverse piattaforme di ricerca AI implementano queste tecnologie fondamentali con approcci e ottimizzazioni differenti. ChatGPT, sviluppato da OpenAI, detiene l'81% della quota di mercato dei chatbot AI ed elabora 2 miliardi di query al giorno. ChatGPT utilizza i modelli GPT di OpenAI combinati con l’accesso web in tempo reale tramite ChatGPT-User per recuperare informazioni aggiornate. È particolarmente efficace nella gestione di query complesse e multi-step e nel mantenere il contesto della conversazione. Perplexity si distingue per le citazioni trasparenti delle fonti, mostrando agli utenti esattamente quali siti web hanno informato ciascuna parte della risposta. Le principali fonti citate da Perplexity includono Reddit (6,6%), YouTube (2%) e Gartner (1%), riflettendo la sua attenzione nel trovare fonti autorevoli e diversificate. Google AI Overviews si integra direttamente nei risultati di Google Search, apparendo in cima alla pagina per molte query. Questi overviews sono presenti nel 18% delle ricerche Google a livello globale e sono alimentati dal modello Gemini di Google. Google AI Overviews è particolarmente efficace per le query informative, con l'88% delle query che le attivano di natura informativa. Google AI Mode, un’esperienza di ricerca separata lanciata nel maggio 2024, ristruttura l’intera pagina dei risultati attorno a risposte AI e ha raggiunto 100 milioni di utenti attivi mensili negli Stati Uniti e in India. Claude, sviluppato da Anthropic, pone l’accento su sicurezza e accuratezza, con utenti che riportano alta soddisfazione per la sua capacità di fornire risposte sfumate e ben ragionate. Ogni piattaforma fa scelte diverse tra velocità, accuratezza, trasparenza delle fonti ed esperienza utente, ma tutte si basano sull’architettura fondamentale di LLM, embedding e RAG.
Quando invii una query a un motore di ricerca AI, questa passa attraverso una sofisticata pipeline di elaborazione multi-stage. La prima fase è l’analisi della query, in cui il sistema suddivide la domanda in componenti fondamentali come parole chiave, entità e frasi. Tecniche di elaborazione del linguaggio naturale come tokenizzazione, part-of-speech tagging e riconoscimento delle entità nominate identificano di cosa stai chiedendo. Ad esempio, nella query “migliori laptop per gaming”, il sistema identifica “laptop” come entità principale e “gaming” come driver d’intento, poi deduce che hai bisogno di molta memoria, potenza di elaborazione e capacità GPU. La seconda fase è l’espansione e fan-out della query, dove il sistema genera query correlate per recuperare informazioni più complete. Invece di cercare solo “migliori laptop da gaming”, il sistema potrebbe anche cercare “specifiche laptop da gaming”, “laptop ad alte prestazioni” e “requisiti GPU per laptop”. Queste ricerche parallele avvengono simultaneamente, migliorando notevolmente la completezza delle informazioni recuperate. La terza fase è il recupero e ranking, in cui il sistema cerca nei contenuti indicizzati sia per parola chiave che semanticamente, poi classifica i risultati per rilevanza. La quarta fase è l’estrazione di passaggi, dove il sistema identifica i passaggi più rilevanti dai documenti recuperati invece di passarli interamente all’LLM. Questo è fondamentale perché gli LLM hanno limiti di token—GPT-4 accetta circa 128.000 token, ma potresti avere 10.000 pagine di documentazione. Estraendo solo i passaggi più pertinenti, il sistema massimizza la qualità delle informazioni passate all’LLM rimanendo entro i vincoli di token. L’ultima fase è la generazione della risposta e citazione, in cui l’LLM genera una risposta e include le citazioni delle fonti consultate. L’intera pipeline deve concludersi in pochi secondi per soddisfare le aspettative degli utenti sui tempi di risposta.
La differenza fondamentale tra i motori di ricerca AI e quelli tradizionali come Google risiede negli obiettivi principali e nelle metodologie. I motori di ricerca tradizionali sono progettati per aiutare gli utenti a trovare informazioni esistenti eseguendo il crawling del web, indicizzando le pagine e classificandole in base a segnali di rilevanza come link, parole chiave e interazione degli utenti. Il processo di Google prevede tre fasi principali: crawling (scoperta delle pagine), indicizzazione (analisi e memorizzazione delle informazioni delle pagine) e ranking (determinazione delle pagine più rilevanti per una query). L’obiettivo è restituire un elenco di siti web, non generare nuovo contenuto. I motori di ricerca AI, al contrario, sono progettati per generare risposte originali e sintetizzate in base ai modelli appresi dai dati di addestramento e dalle informazioni aggiornate recuperate dal web. Sebbene i motori di ricerca tradizionali utilizzino algoritmi AI come RankBrain e BERT per migliorare il ranking, non tentano di creare nuovo contenuto. I motori di ricerca AI generano fondamentalmente nuovo testo prevedendo sequenze di parole. Questa distinzione ha profonde implicazioni per la visibilità. Con la ricerca tradizionale, devi posizionarti tra i primi 10 per ottenere clic. Con la ricerca AI, il 40% delle fonti citate negli AI Overviews si posiziona oltre i primi 10 risultati nella ricerca Google tradizionale, e solo il 14% degli URL citati da Google AI Mode si trova nella top 10 tradizionale per le stesse query. Ciò significa che il tuo contenuto può essere citato nelle risposte AI anche se non si posiziona bene nella ricerca tradizionale. Inoltre, le menzioni web del brand hanno una correlazione di 0,664 con la presenza nei Google AI Overviews, molto superiore ai backlink (0,218), suggerendo che la visibilità e la reputazione del marchio contano più dei classici parametri SEO nella ricerca AI.
Il panorama della ricerca AI si sta evolvendo rapidamente, con implicazioni significative per il modo in cui le persone scoprono informazioni e le aziende mantengono la visibilità. Il traffico da ricerca AI è previsto superare quello della ricerca tradizionale entro il 2028, e i dati attuali mostrano che le piattaforme AI hanno generato 1,13 miliardi di visite da referral a giugno 2025, con un aumento del 357% rispetto a giugno 2024. Fondamentale, il traffico da ricerca AI converte al 14,2% rispetto al 2,8% di Google, rendendo questo traffico molto più prezioso nonostante rappresenti attualmente solo l'1% del traffico globale. Il mercato si sta consolidando attorno a poche piattaforme dominanti: ChatGPT detiene l'81% della quota di mercato dei chatbot AI, Gemini di Google conta 400 milioni di utenti attivi mensili e Perplexity ha oltre 22 milioni di utenti attivi mensili. Nuove funzionalità stanno ampliando le capacità della ricerca AI—Agent Mode di ChatGPT consente agli utenti di delegare compiti complessi come prenotare voli direttamente all’interno della piattaforma, mentre Instant Checkout permette acquisti di prodotti direttamente dalla chat. ChatGPT Atlas, lanciato nell’ottobre 2025, porta ChatGPT su tutto il web per risposte e suggerimenti istantanei. Questi sviluppi suggeriscono che la ricerca AI sta diventando non solo un’alternativa alla ricerca tradizionale, ma una piattaforma completa per la scoperta di informazioni, il decision-making e il commercio. Per i creatori di contenuti e i marketer, questo cambiamento richiede una trasformazione radicale della strategia. Invece di ottimizzare per il ranking delle parole chiave, il successo nella ricerca AI richiede la creazione di pattern rilevanti nei materiali di addestramento, la costruzione dell’autorità del brand tramite menzioni e citazioni, e l’assicurare che i contenuti siano freschi, completi e ben strutturati. Strumenti come AmICited permettono alle aziende di monitorare dove appare il proprio contenuto sulle piattaforme AI, tracciare i pattern di citazione e misurare la visibilità nella ricerca AI—capacità essenziali per affrontare questo nuovo scenario.
Traccia dove appare il tuo contenuto su ChatGPT, Perplexity, Google AI Overviews e Claude. Ricevi avvisi in tempo reale quando il tuo dominio viene citato nelle risposte generate dall'AI.
Scopri cosa sono i motori di ricerca AI, come si differenziano dalla ricerca tradizionale e il loro impatto sulla visibilità del brand. Esplora piattaforme come...

Scopri i primi passi essenziali per ottimizzare i tuoi contenuti per i motori di ricerca AI come ChatGPT, Perplexity e Google AI Overviews. Scopri come struttur...
Scopri come inviare e ottimizzare i tuoi contenuti per i motori di ricerca AI come ChatGPT, Perplexity e Gemini. Approfondisci strategie di indicizzazione, requ...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.