
Cos'è il Content Decay nella Ricerca AI? Definizione e Impatto
Scopri cosa significa content decay nella ricerca AI, come differisce dal decadimento SEO tradizionale e perché i sistemi AI danno priorità a contenuti freschi ...
9 min di lettura

Scopri cos’è il content pruning per l’IA, come funziona, i diversi metodi di pruning e perché è essenziale per distribuire modelli di IA efficienti su dispositivi edge e in ambienti con risorse limitate.
Il content pruning per l'IA è una tecnica che rimuove selettivamente parametri, pesi o token ridondanti o meno importanti dai modelli di IA per ridurne le dimensioni, migliorare la velocità di inferenza e abbassare il consumo di memoria mantenendo la qualità delle prestazioni.
Il content pruning per l’IA è una tecnica di ottimizzazione fondamentale utilizzata per ridurre la complessità computazionale e l’impronta di memoria dei modelli di intelligenza artificiale senza compromettere significativamente le prestazioni. Questo processo consiste nell’identificare e rimuovere sistematicamente componenti ridondanti o meno importanti dalle reti neurali, inclusi singoli pesi, interi neuroni, filtri o persino token nei modelli linguistici. L’obiettivo principale è creare modelli più snelli, veloci ed efficienti che possano essere distribuiti efficacemente su dispositivi con risorse limitate come smartphone, sistemi di edge computing e dispositivi IoT.
Il concetto di pruning trae ispirazione dai sistemi biologici, in particolare dalla potatura sinaptica nel cervello umano, dove durante lo sviluppo vengono eliminate le connessioni neurali non necessarie. Analogamente, il pruning nell’IA riconosce che le reti neurali addestrate spesso contengono molti parametri che contribuiscono minimamente al risultato finale. Rimuovendo questi componenti ridondanti, gli sviluppatori possono ottenere riduzioni sostanziali nelle dimensioni del modello mantenendo o addirittura migliorando l’accuratezza tramite processi di fine-tuning accurati.
Il content pruning si basa sul principio che non tutti i parametri di una rete neurale sono ugualmente importanti per fare previsioni. Durante il processo di addestramento, le reti neurali sviluppano interconnessioni complesse, molte delle quali diventano ridondanti o contribuiscono in modo trascurabile al processo decisionale del modello. Il pruning identifica questi componenti meno critici e li rimuove, dando come risultato una rete più sparsa che richiede meno risorse computazionali per funzionare.
L’efficacia del pruning dipende da diversi fattori, tra cui il metodo di pruning adottato, l’aggressività della strategia e il successivo processo di fine-tuning. Diversi approcci di pruning mirano a vari aspetti delle reti neurali: alcuni si concentrano su singoli pesi (pruning non strutturato), altri rimuovono interi neuroni, filtri o canali (pruning strutturato). La scelta del metodo impatta significativamente sia sull’efficienza del modello risultante sia sulla compatibilità con i moderni acceleratori hardware.
| Tipo di Pruning | Target | Vantaggi | Sfide |
|---|---|---|---|
| Weight Pruning | Connessioni/pesi individuali | Massima compressione, reti sparse | Potrebbe non accelerare l’esecuzione hardware |
| Structured Pruning | Neuroni, filtri, canali | Compatibile con l’hardware, inferenza più veloce | Meno compressione rispetto a quello non strutturato |
| Dynamic Pruning | Parametri dipendenti dal contesto | Efficienza adattiva, aggiustamento in tempo reale | Implementazione complessa, maggiore overhead |
| Layer Pruning | Interi layer o blocchi | Riduzione significativa della dimensione | Rischio di perdita di accuratezza, richiede validazione attenta |
Il pruning non strutturato, noto anche come weight pruning, opera a livello granulare eliminando pesi individuali dalle matrici di pesi della rete. Questo approccio utilizza solitamente criteri basati sulla magnitudine, dove i pesi con valori prossimi allo zero sono considerati meno importanti e vengono eliminati. La rete risultante diventa sparsa, cioè solo una frazione delle connessioni originali rimane attiva durante l’inferenza. Mentre il pruning non strutturato può ottenere rapporti di compressione notevoli—talvolta riducendo il numero di parametri del 90% o più—le reti sparse risultanti potrebbero non tradursi sempre in miglioramenti proporzionali della velocità su hardware standard senza supporti specifici alle computazioni sparse.
Il pruning strutturato adotta un approccio differente eliminando interi gruppi di parametri contemporaneamente, come filtri completi in layer convoluzionali, interi neuroni in layer completamente connessi o interi canali. Questo metodo è particolarmente prezioso per la distribuzione pratica poiché i modelli risultanti sono naturalmente compatibili con i moderni acceleratori hardware come GPU e TPU. Quando interi filtri vengono rimossi dai layer convoluzionali, il risparmio computazionale si realizza subito senza richiedere operazioni di matrice sparse specializzate. La ricerca ha dimostrato che il pruning strutturato può ridurre la dimensione del modello dal 50 al 90% mantenendo un’accuratezza comparabile a quella dei modelli originali.
Il pruning dinamico rappresenta un approccio più sofisticato in cui il processo di pruning si adatta durante l’inferenza del modello in base allo specifico input elaborato. Questa tecnica sfrutta contesti esterni come embedding del parlante, segnali di evento o informazioni specifiche della lingua per regolare dinamicamente quali parametri restano attivi. Nei sistemi di generazione aumentata dal recupero, il pruning dinamico può ridurre la dimensione del contesto di circa l'80% migliorando contemporaneamente l’accuratezza delle risposte filtrando le informazioni irrilevanti. Questo approccio adattivo è particolarmente prezioso per i sistemi IA multimodali che devono processare in modo efficiente tipologie di input diverse.
Il pruning iterativo con fine-tuning rappresenta uno degli approcci più diffusi nella pratica. Questo metodo prevede un processo ciclico: si pota una parte della rete, si effettua il fine-tuning dei parametri rimanenti per recuperare l’accuratezza persa, si valuta la prestazione e si ripete. La natura iterativa di questo approccio consente agli sviluppatori di bilanciare con attenzione la compressione del modello con il mantenimento delle prestazioni. Invece di rimuovere tutti i parametri non necessari in una sola volta—il che potrebbe compromettere seriamente le prestazioni—il pruning iterativo riduce gradualmente la complessità della rete consentendo al modello di adattarsi e apprendere quali parametri restanti sono più critici.
Il pruning one-shot offre un’alternativa più rapida in cui l’intera operazione di pruning avviene in un unico passaggio dopo l’addestramento, seguito da una fase di fine-tuning. Sebbene questo approccio sia computazionalmente più efficiente rispetto ai metodi iterativi, comporta un rischio maggiore di degradazione dell’accuratezza se vengono rimossi troppi parametri contemporaneamente. Il pruning one-shot è particolarmente utile quando le risorse computazionali per processi iterativi sono limitate, anche se in genere richiede un fine-tuning più intensivo per recuperare le prestazioni.
Il pruning basato su analisi di sensibilità utilizza un meccanismo di ranking più sofisticato misurando quanto la funzione di perdita del modello aumenta quando vengono rimossi specifici pesi o neuroni. I parametri che hanno un impatto minimo sulla funzione di perdita vengono identificati come candidati sicuri per il pruning. Questo approccio guidato dai dati fornisce decisioni di pruning più raffinate rispetto ai semplici metodi basati sulla magnitudine, spesso portando a una migliore preservazione dell’accuratezza a parità di livello di compressione.
L’Ipotesi del Biglietto Vincente (Lottery Ticket Hypothesis) presenta un interessante quadro teorico secondo cui all’interno di grandi reti neurali esiste una sotto-rete più piccola e sparsa—il “biglietto vincente”—che può raggiungere un’accuratezza paragonabile a quella della rete originale se addestrata dalla stessa inizializzazione. Questa ipotesi ha profonde implicazioni per la comprensione della ridondanza delle reti e ha ispirato nuove metodologie di pruning volte a identificare e isolare queste sotto-reti efficienti.
Il content pruning è diventato indispensabile in numerose applicazioni di IA dove l’efficienza computazionale è fondamentale. La distribuzione su dispositivi mobili e embedded rappresenta uno dei casi d’uso più significativi, in cui i modelli potati abilitano funzionalità IA sofisticate su smartphone e dispositivi IoT con potenza di calcolo e capacità di batteria limitate. Applicazioni di riconoscimento immagini, assistenti vocali e traduzione in tempo reale traggono tutti vantaggio da modelli potati che mantengono l’accuratezza consumando poche risorse.
I sistemi autonomi, inclusi veicoli a guida autonoma e droni, richiedono decisioni in tempo reale con latenza minima. Le reti neurali potate consentono a questi sistemi di processare dati sensoriali e prendere decisioni critiche entro vincoli di tempo stringenti. La riduzione dell’overhead computazionale si traduce direttamente in tempi di risposta più rapidi, essenziali per applicazioni dove la sicurezza è cruciale.
Negli ambienti cloud e edge computing, il pruning riduce sia i costi computazionali sia i requisiti di storage per la distribuzione di modelli su larga scala. Le organizzazioni possono servire più utenti con la stessa infrastruttura, oppure ridurre sensibilmente le spese computazionali. Gli scenari di edge computing beneficiano particolarmente dei modelli potati, poiché abilitano elaborazione IA avanzata su dispositivi lontani dai data center centralizzati.
La valutazione dell’efficacia del pruning richiede un’attenta considerazione di molteplici metriche oltre la semplice riduzione del numero di parametri. La latenza di inferenza—il tempo necessario affinché un modello generi output a partire da un input—è una metrica critica che incide direttamente sull’esperienza utente nelle applicazioni in tempo reale. Un pruning efficace dovrebbe ridurre sensibilmente la latenza di inferenza, consentendo tempi di risposta più rapidi per l’utente finale.
Accuratezza del modello e F1 score devono essere mantenuti durante l’intero processo di pruning. La sfida principale è ottenere una compressione significativa senza sacrificare le prestazioni predittive. Strategie di pruning ben progettate mantengono l’accuratezza entro l'1-5% rispetto al modello originale raggiungendo una riduzione dei parametri del 50-90%. La riduzione dell’impronta di memoria è altrettanto importante, poiché determina se i modelli possono essere distribuiti su dispositivi con risorse limitate.
Studi che confrontano modelli grandi ma sparsi (reti di grandi dimensioni con molti parametri rimossi) con modelli piccoli ma densi (reti più piccole addestrate da zero) con identica impronta di memoria dimostrano costantemente che i modelli grandi e sparsi superano le controparti piccole e dense. Questo risultato sottolinea il valore di partire da reti grandi e ben addestrate per poi potarle strategicamente, anziché tentare di addestrare reti piccole sin dall’inizio.
La degradazione dell’accuratezza rimane la principale sfida nel content pruning. Un pruning aggressivo può ridurre notevolmente le prestazioni del modello, richiedendo un’attenta calibrazione dell’intensità del pruning. Gli sviluppatori devono trovare il punto di equilibrio ottimale in cui i vantaggi di compressione vengono massimizzati senza una perdita di accuratezza inaccettabile. Questo punto di equilibrio varia in base all’applicazione specifica, all’architettura del modello e alle soglie di prestazione accettabili.
Problemi di compatibilità hardware possono limitare i benefici pratici del pruning. Mentre il pruning non strutturato genera reti sparse con meno parametri, l’hardware moderno è ottimizzato per le operazioni di matrice densa. Le reti sparse potrebbero non eseguire in modo significativamente più rapido su GPU standard senza librerie e supporti hardware specifici per il calcolo sparso. Il pruning strutturato supera questa limitazione mantenendo pattern di calcolo densi, anche se a fronte di una compressione meno aggressiva.
L’overhead computazionale dei metodi di pruning può essere considerevole. I metodi iterativi e quelli basati su analisi di sensibilità richiedono molteplici passaggi di addestramento e valutazioni attente, consumando risorse computazionali significative. Gli sviluppatori devono bilanciare il costo una tantum del pruning con il risparmio continuo derivante dall’impiego di modelli più efficienti.
Preoccupazioni di generalizzazione sorgono quando il pruning è troppo aggressivo. Modelli eccessivamente potati possono funzionare bene su dati di addestramento e validazione ma generalizzare male su dati nuovi e non visti. Strategie di validazione adeguate e test accurati su dataset diversificati sono essenziali per garantire che i modelli potati mantengano prestazioni solide negli ambienti di produzione.
Un content pruning di successo richiede un approccio sistematico basato su best practice sviluppate attraverso ricerche e esperienze pratiche. Parti da reti grandi e ben addestrate invece di tentare di addestrare reti piccole da zero. Le reti grandi offrono più ridondanza e flessibilità per il pruning, e la ricerca dimostra costantemente che le reti grandi potate superano quelle piccole addestrate dall’inizio.
Utilizza il pruning iterativo con fine-tuning accurato per ridurre gradualmente la complessità del modello mantenendo le prestazioni. Questo approccio offre un migliore controllo sul compromesso tra accuratezza ed efficienza e consente al modello di adattarsi alla rimozione dei parametri. Adotta il pruning strutturato per la distribuzione pratica quando l’accelerazione hardware è importante, poiché produce modelli che vengono eseguiti in modo efficiente sull’hardware standard senza necessità di supporti per il calcolo sparso.
Valida estesamente su dataset diversificati per assicurarti che i modelli potati generalizzino bene oltre i dati di addestramento. Monitora molteplici metriche di prestazione tra cui accuratezza, latenza di inferenza, uso della memoria e consumo energetico per valutare in modo completo l’efficacia del pruning. Considera l’ambiente di distribuzione target nella scelta delle strategie di pruning, poiché diversi dispositivi e piattaforme hanno caratteristiche di ottimizzazione differenti.
Il campo del content pruning continua ad evolversi con tecniche e metodologie emergenti. Il Contextually Adaptive Token Pruning (CATP) rappresenta un approccio all’avanguardia che utilizza l’allineamento semantico e la diversità delle feature per trattenere selettivamente solo i token più rilevanti nei modelli linguistici. Questa tecnica è particolarmente preziosa per i grandi modelli linguistici e i sistemi multimodali dove la gestione del contesto è critica.
L’integrazione con database vettoriali come Pinecone e Weaviate permette strategie di pruning del contesto più sofisticate tramite l’archiviazione e il recupero efficiente di informazioni rilevanti. Queste integrazioni supportano decisioni di pruning dinamiche basate su similarità semantica e scoring di rilevanza, migliorando sia l’efficienza sia l’accuratezza.
La combinazione con altre tecniche di compressione come quantizzazione e distillazione della conoscenza crea effetti sinergici, consentendo una compressione dei modelli ancora più aggressiva. Modelli contemporaneamente potati, quantizzati e distillati possono raggiungere rapporti di compressione di 100x o superiori mantenendo livelli di prestazione accettabili.
Man mano che i modelli di IA crescono in complessità e gli scenari di distribuzione diventano sempre più diversificati, il content pruning resterà una tecnica fondamentale per rendere l’IA avanzata accessibile e pratica in tutto lo spettro degli ambienti di calcolo, dai potenti data center ai dispositivi edge con risorse limitate.
Scopri come AmICited ti aiuta a tracciare quando i tuoi contenuti compaiono nelle risposte generate dall'IA su ChatGPT, Perplexity e altri motori di ricerca basati sull'IA. Garantisciti visibilità per il tuo brand nel futuro alimentato dall'IA.
Scopri cosa significa content decay nella ricerca AI, come differisce dal decadimento SEO tradizionale e perché i sistemi AI danno priorità a contenuti freschi ...
Scopri come consolidare e ottimizzare i tuoi contenuti per i motori di ricerca IA come ChatGPT, Perplexity e Gemini. Scopri le best practice per la struttura, l...
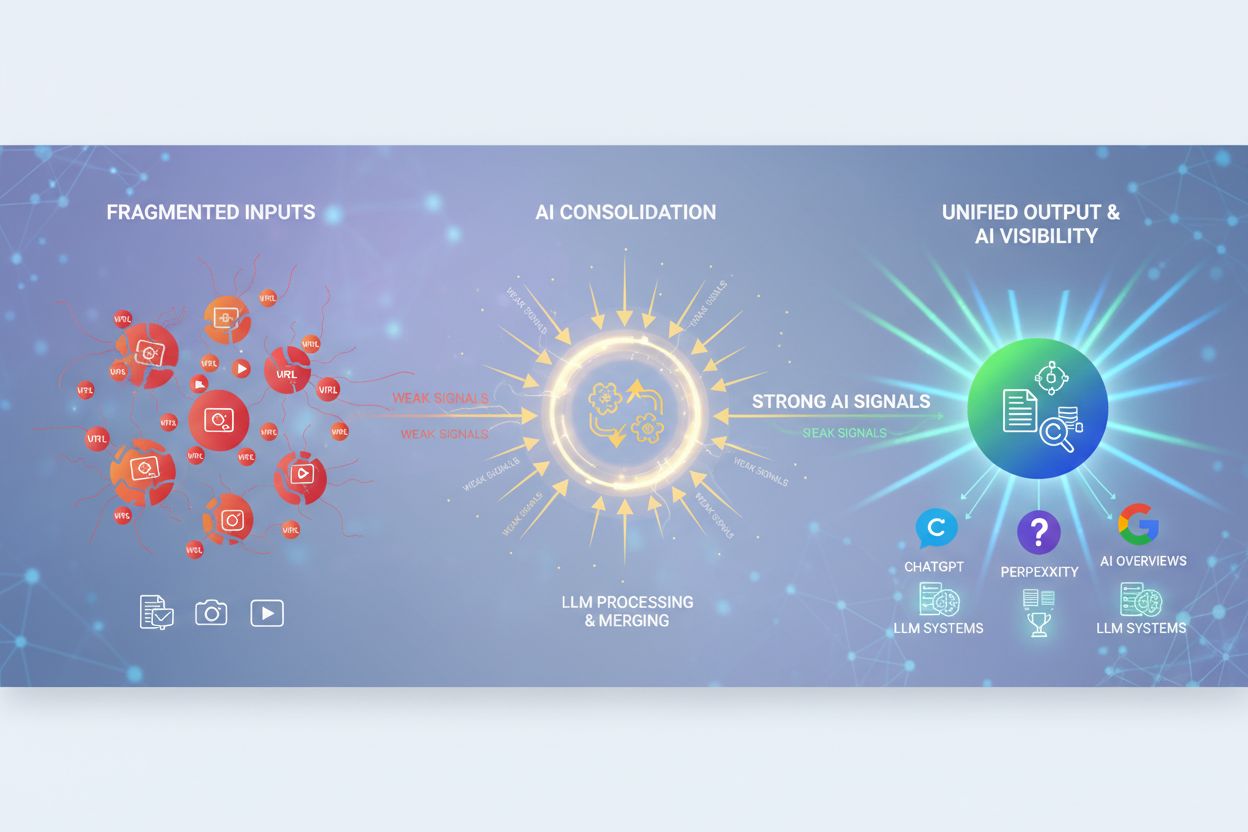
Scopri cos'è il Consolidamento dei Contenuti AI e come unire contenuti simili rafforza i segnali di visibilità per ChatGPT, Perplexity e Google AI Overviews. Es...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.