
Gestione dei Crawler AI
Scopri come gestire l’accesso dei crawler AI ai contenuti del tuo sito web. Comprendi la differenza tra crawler di addestramento e di ricerca, implementa contro...
8 min di lettura
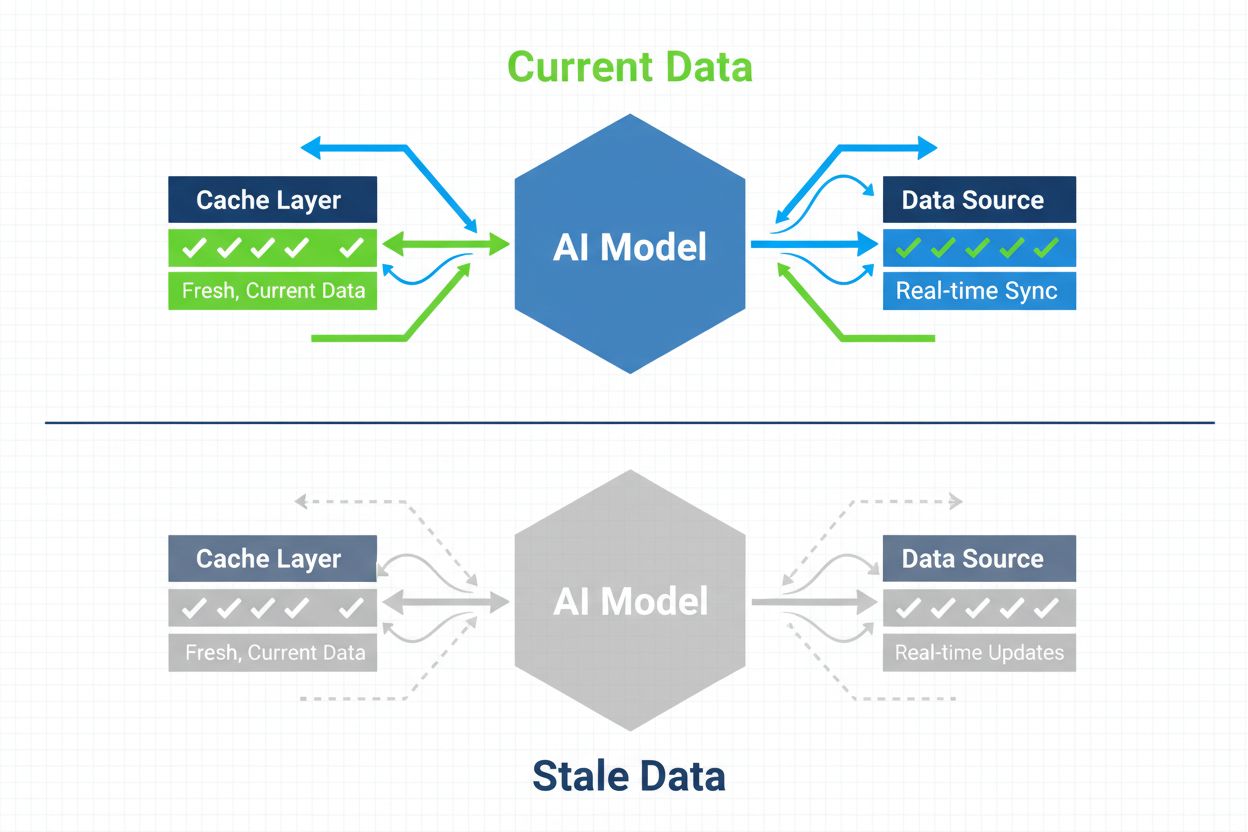
Strategie per garantire che i sistemi di intelligenza artificiale abbiano accesso a contenuti aggiornati invece di versioni obsolete in cache. La gestione della cache bilancia i vantaggi in termini di prestazioni derivanti dalla memorizzazione temporanea dei dati con il rischio di fornire informazioni non aggiornate, utilizzando strategie di invalidazione e monitoraggio per mantenere la freschezza dei dati riducendo al contempo latenza e costi.
Strategie per garantire che i sistemi di intelligenza artificiale abbiano accesso a contenuti aggiornati invece di versioni obsolete in cache. La gestione della cache bilancia i vantaggi in termini di prestazioni derivanti dalla memorizzazione temporanea dei dati con il rischio di fornire informazioni non aggiornate, utilizzando strategie di invalidazione e monitoraggio per mantenere la freschezza dei dati riducendo al contempo latenza e costi.
La gestione della cache AI si riferisce all’approccio sistematico di memorizzare e recuperare risultati precedentemente calcolati, output di modelli o risposte API per evitare elaborazioni ridondanti e ridurre la latenza nei sistemi di intelligenza artificiale. La sfida principale consiste nel bilanciare i vantaggi prestazionali dei dati in cache con il rischio di fornire informazioni obsolete o non più aggiornate rispetto allo stato attuale del sistema o ai bisogni dell’utente. Questo aspetto diventa particolarmente critico nei grandi modelli linguistici (LLM) e nelle applicazioni AI dove i costi di inferenza sono elevati e i tempi di risposta incidono direttamente sull’esperienza utente. I sistemi di gestione della cache devono determinare in modo intelligente quando i risultati in cache rimangono validi e quando è necessaria una nuova elaborazione, rendendo questo tema una considerazione architetturale fondamentale per le implementazioni AI in produzione.
L’impatto di una gestione efficace della cache sulle prestazioni dei sistemi AI è sostanziale e misurabile su più dimensioni. Implementare strategie di caching può ridurre la latenza delle risposte dell'80-90% per query ripetute e contemporaneamente abbattere i costi API dal 50% al 90%, a seconda del tasso di hit della cache e dell’architettura del sistema. Oltre ai parametri di performance, la gestione della cache influenza direttamente la coerenza dell’accuratezza e l’affidabilità del sistema: cache correttamente invalidate garantiscono che gli utenti ricevano informazioni aggiornate, mentre una cattiva gestione può introdurre problemi di obsolescenza dei dati. Questi miglioramenti diventano sempre più importanti man mano che i sistemi AI scalano per gestire milioni di richieste, dove l’efficienza cumulativa della cache determina direttamente i costi infrastrutturali e la soddisfazione degli utenti.
| Aspetto | Sistemi con Cache | Sistemi senza Cache |
|---|---|---|
| Tempo di Risposta | 80-90% più veloce | Base |
| Costi API | Riduzione 50-90% | Costo pieno |
| Accuratezza | Costante | Variabile |
| Scalabilità | Alta | Limitata |
Le strategie di invalidazione della cache determinano come e quando i dati in cache vengono aggiornati o rimossi dalla memorizzazione, rappresentando una delle decisioni più critiche nella progettazione dell’architettura della cache. Diversi approcci di invalidazione offrono compromessi specifici tra freschezza dei dati e prestazioni di sistema:
La scelta della strategia di invalidazione dipende fondamentalmente dai requisiti applicativi: sistemi che danno priorità all’accuratezza dei dati possono accettare costi di latenza più elevati tramite invalidazione aggressiva, mentre applicazioni critiche per le performance possono tollerare dati leggermente obsoleti per mantenere tempi di risposta inferiori al millisecondo.
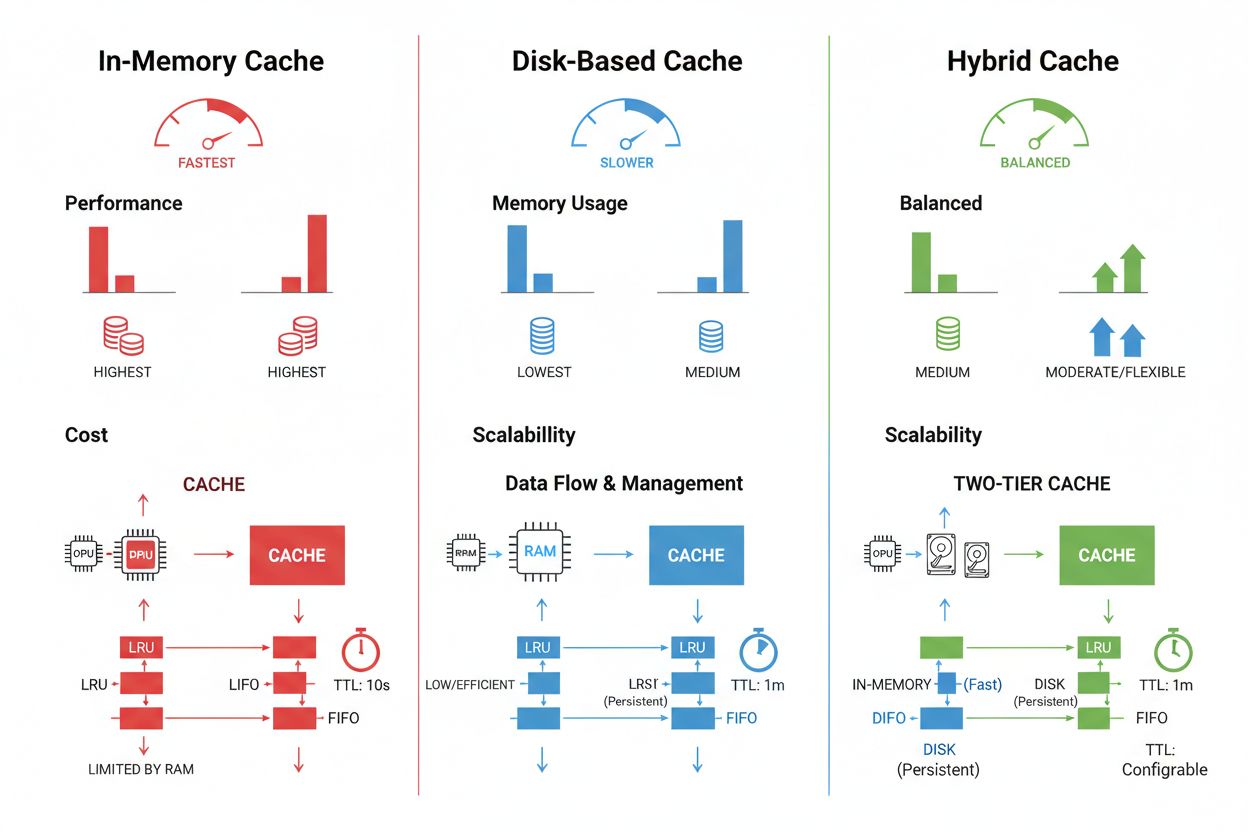
Il caching dei prompt nei grandi modelli linguistici rappresenta un’applicazione specializzata della gestione della cache che memorizza stati intermedi del modello e sequenze di token per evitare la rielaborazione di input identici o simili. Gli LLM supportano due principali approcci di caching: il caching esatto corrisponde ai prompt carattere per carattere, mentre il caching semantico identifica prompt funzionalmente equivalenti anche con formulazioni diverse. OpenAI implementa il caching automatico dei prompt con una riduzione del 50% dei costi sui token in cache, richiedendo segmenti minimi di 1024 token per attivare i vantaggi del caching. Anthropic offre caching manuale dei prompt con riduzioni dei costi ancora più aggressive (fino al 90%), ma richiede agli sviluppatori di gestire esplicitamente le chiavi e le durate della cache, con requisiti minimi di 1024-2048 token a seconda della configurazione del modello. La durata della cache nei sistemi LLM varia tipicamente da pochi minuti a diverse ore, bilanciando il risparmio computazionale derivante dal riutilizzo degli stati in cache con il rischio di fornire output obsoleti per applicazioni sensibili al tempo.
Le tecniche di memorizzazione e gestione della cache variano sensibilmente in base ai requisiti di prestazioni, ai volumi di dati e ai vincoli infrastrutturali, con ciascun approccio che offre vantaggi e limiti distinti. Soluzioni di caching in memoria come Redis forniscono velocità di accesso nell’ordine dei microsecondi, ideali per query ad alta frequenza, ma consumano molta RAM e richiedono una gestione accurata della memoria. Il caching su disco consente di gestire dataset più ampi e persiste attraverso i riavvii del sistema, ma introduce una latenza misurabile in millisecondi rispetto alle alternative in memoria. Gli approcci ibridi combinano entrambi i tipi di storage, indirizzando i dati più richiesti in memoria e mantenendo i dataset più ampi su disco:
| Tipo di Storage | Migliore per | Prestazioni | Utilizzo Memoria |
|---|---|---|---|
| In-Memory (Redis) | Query frequenti | Più veloce | Più alto |
| Su Disco | Grandi dataset | Moderato | Più basso |
| Ibrido | Carichi misti | Bilanciato | Bilanciato |
Una gestione efficace della cache richiede la configurazione di impostazioni TTL appropriate che riflettano la volatilità dei dati—TTL brevi (minuti) per dati che cambiano rapidamente contro TTL più lunghi (ore/giorni) per contenuti stabili—insieme a un monitoraggio continuo dei tassi di hit della cache, dei pattern di espulsione e dell’utilizzo della memoria per individuare opportunità di ottimizzazione.
Le applicazioni AI reali dimostrano sia il potenziale trasformativo che la complessità operativa della gestione della cache in diversi casi d’uso. I chatbot per il servizio clienti sfruttano la cache per fornire risposte coerenti alle domande frequenti, riducendo i costi di inferenza del 60-70% e consentendo uno scaling economico a migliaia di utenti simultanei. Gli assistenti alla programmazione memorizzano in cache pattern di codice comuni e frammenti di documentazione, permettendo agli sviluppatori di ricevere suggerimenti di completamento con latenze inferiori ai 100ms anche durante i picchi di utilizzo. I sistemi di elaborazione documentale memorizzano in cache embedding e rappresentazioni semantiche di documenti frequentemente analizzati, accelerando notevolmente ricerche di similarità e task di classificazione. Tuttavia, la gestione della cache in produzione introduce sfide significative: la complessità dell’invalidazione cresce esponenzialmente nei sistemi distribuiti dove la coerenza della cache deve essere mantenuta su più server, i vincoli di risorse impongono compromessi difficili tra dimensione e copertura della cache, emergono rischi di sicurezza quando i dati memorizzati in cache sono sensibili e richiedono crittografia e controlli di accesso, e la coordinazione degli aggiornamenti della cache tra microservizi introduce potenziali condizioni di race e incoerenze nei dati. Soluzioni di monitoraggio complete che tracciano freschezza della cache, tassi di hit ed eventi di invalidazione diventano essenziali per mantenere l’affidabilità del sistema e individuare quando è necessario modificare le strategie di cache in base a pattern di dati e comportamenti utente in evoluzione.
L'invalidazione della cache rimuove o aggiorna i dati obsoleti quando si verificano cambiamenti, offrendo freschezza immediata ma richiedendo trigger guidati dagli eventi. L'espirazione della cache imposta un limite di tempo (TTL) per la permanenza dei dati in cache, offrendo un'implementazione più semplice ma rischiando di fornire dati obsoleti se il TTL è troppo lungo. Molti sistemi combinano entrambi gli approcci per prestazioni ottimali.
Una gestione efficace della cache può ridurre i costi API dal 50% al 90% a seconda del tasso di hit della cache e dell'architettura di sistema. Il caching dei prompt di OpenAI offre una riduzione dei costi del 50% sui token in cache, mentre Anthropic fornisce fino al 90% di riduzione. Il risparmio effettivo dipende dai modelli di query e dalla quantità di dati che possono essere efficacemente memorizzati in cache.
Il caching dei prompt memorizza stati intermedi del modello e sequenze di token per evitare di rielaborare input identici o simili nei grandi modelli linguistici. Supporta il caching esatto (corrispondenza carattere per carattere) e il caching semantico (prompt funzionalmente equivalenti con formulazioni diverse). Questo riduce la latenza dell'80% e i costi dal 50% al 90% per query ripetute.
Le strategie principali sono: Espirazione Basata sul Tempo (TTL) per la rimozione automatica dopo una durata impostata, Invalidazione Basata su Evento per aggiornamenti immediati quando i dati cambiano, Invalidazione Semantica per query simili basate sul significato, e Approcci Ibridi che combinano più strategie. La scelta dipende dalla volatilità dei dati e dai requisiti di freschezza.
Il caching in memoria (come Redis) offre velocità di accesso nell'ordine dei microsecondi, ideale per query frequenti ma consuma molta RAM. Il caching su disco gestisce set di dati più grandi e persiste ai riavvii, ma introduce latenza a livello di millisecondi. Gli approcci ibridi combinano entrambi, indirizzando i dati più richiesti alla memoria e mantenendo i dataset più grandi su disco.
Il TTL è un timer che determina per quanto tempo i dati in cache restano validi prima della scadenza. TTL brevi (minuti) sono adatti a dati che cambiano rapidamente, mentre TTL più lunghi (ore/giorni) funzionano per contenuti stabili. Una configurazione corretta del TTL bilancia la freschezza dei dati con la necessità di evitare aggiornamenti inutili e carico sul server.
Una gestione efficace della cache consente ai sistemi AI di gestire molte più richieste senza espandere proporzionalmente l'infrastruttura. Riducendo il carico computazionale per richiesta tramite caching, è possibile servire milioni di utenti in modo più conveniente. I tassi di hit della cache determinano direttamente i costi infrastrutturali e la soddisfazione degli utenti nei deployment di produzione.
La memorizzazione in cache di dati sensibili comporta vulnerabilità di sicurezza se non viene adeguatamente crittografata e controllata negli accessi. I rischi includono accessi non autorizzati alle informazioni in cache, esposizione dei dati durante l'invalidazione della cache e memorizzazione accidentale di contenuti riservati. Crittografia completa, controlli di accesso e monitoraggio sono essenziali per proteggere i dati sensibili in cache.
AmICited tiene traccia di come i sistemi AI fanno riferimento al tuo brand e assicura che i tuoi contenuti restino aggiornati nelle cache AI. Ottieni visibilità sulla gestione della cache AI e sulla freschezza dei contenuti su GPT, Perplexity e Google AI Overviews.
Scopri come gestire l’accesso dei crawler AI ai contenuti del tuo sito web. Comprendi la differenza tra crawler di addestramento e di ricerca, implementa contro...

Scopri come rilevare, rispondere e prevenire crisi generate dall'AI che minacciano la reputazione del marchio. Scopri strategie di monitoraggio in tempo reale, ...

Scopri come gestire le crisi reputazionali del tuo marchio nelle risposte generate da ChatGPT, Perplexity e altri motori di ricerca AI. Scopri strategie per mon...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.