
Crawler AI spiegati: GPTBot, ClaudeBot e altri
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...
15 min di lettura

La pratica strategica di consentire o bloccare selettivamente i crawler AI per controllare come i contenuti vengono utilizzati per l’addestramento rispetto al recupero in tempo reale. Ciò comporta l’uso di file robots.txt, controlli a livello di server e strumenti di monitoraggio per gestire quali sistemi AI possono accedere ai tuoi contenuti e per quali scopi.
La pratica strategica di consentire o bloccare selettivamente i crawler AI per controllare come i contenuti vengono utilizzati per l’addestramento rispetto al recupero in tempo reale. Ciò comporta l’uso di file robots.txt, controlli a livello di server e strumenti di monitoraggio per gestire quali sistemi AI possono accedere ai tuoi contenuti e per quali scopi.
La Gestione dei Crawler AI si riferisce alla pratica di controllare e monitorare come i sistemi di intelligenza artificiale accedono e utilizzano i contenuti dei siti web a fini di addestramento e ricerca. A differenza dei tradizionali crawler dei motori di ricerca che indicizzano i contenuti per i risultati web, i crawler AI sono specificamente progettati per raccogliere dati per l’addestramento di grandi modelli linguistici o per alimentare funzionalità di ricerca basate su AI. L’entità di questa attività varia notevolmente tra le organizzazioni: i crawler di OpenAI operano con un rapporto crawl-to-refer di 1.700:1, cioè accedono ai contenuti 1.700 volte per ogni riferimento fornito, mentre il rapporto di Anthropic arriva a 73.000:1, evidenziando il massiccio consumo di dati necessario per addestrare i moderni sistemi AI. Una gestione efficace dei crawler consente ai proprietari di siti web di decidere se i loro contenuti contribuiscono all’addestramento AI, compaiono nei risultati di ricerca AI o rimangono protetti dall’accesso automatizzato.
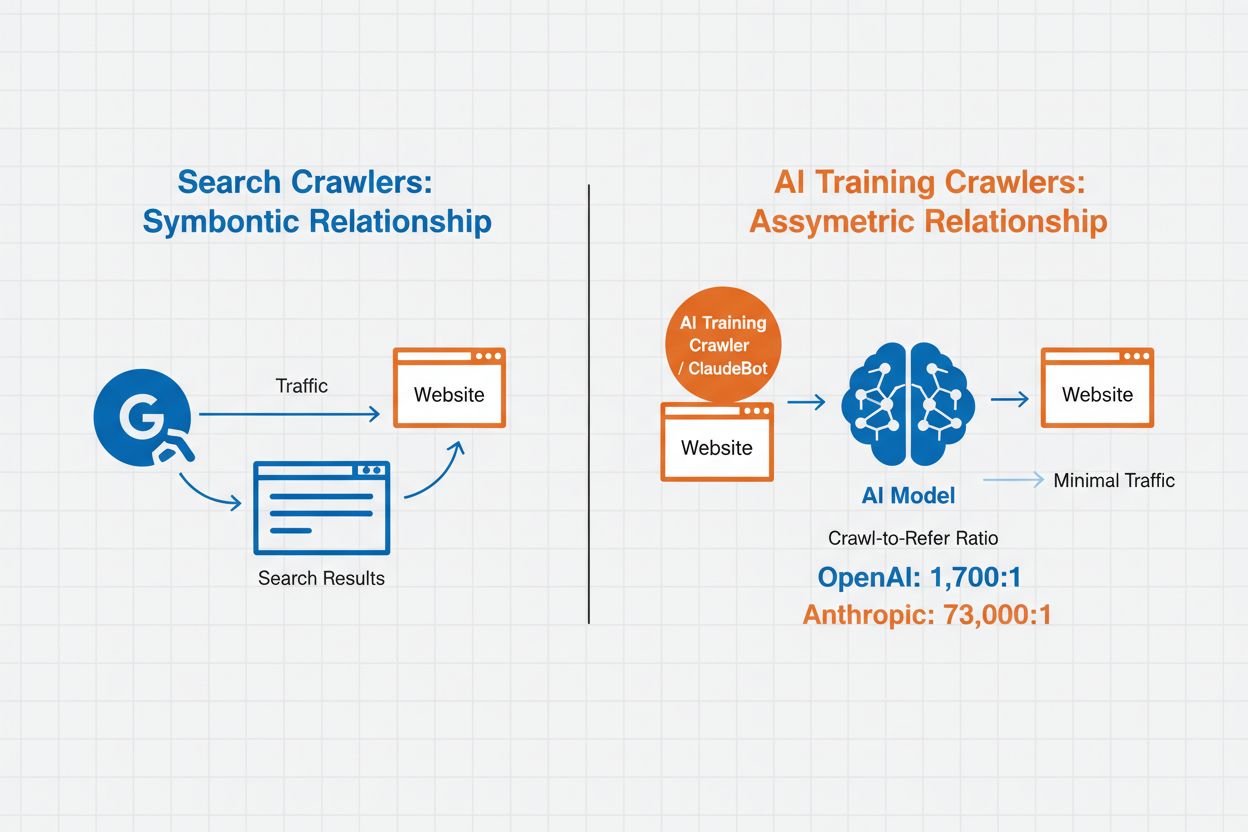
I crawler AI si dividono in tre categorie distinte in base allo scopo e ai pattern di utilizzo dei dati. I crawler di addestramento sono progettati per raccogliere dati finalizzati allo sviluppo di modelli di machine learning, consumando enormi quantità di contenuti per migliorare le capacità AI. I crawler di ricerca e citazione indicizzano i contenuti per alimentare funzionalità di ricerca AI e fornire attribuzione nelle risposte generate, permettendo agli utenti di scoprire i tuoi contenuti tramite interfacce AI. I crawler attivati dall’utente operano su richiesta quando gli utenti interagiscono con strumenti AI, ad esempio quando un utente ChatGPT carica un documento o richiede l’analisi di una pagina web specifica. Comprendere queste categorie ti aiuta a prendere decisioni informate su quali crawler consentire o bloccare in base alla tua strategia di contenuto e agli obiettivi di business.
| Tipo di Crawler | Scopo | Esempi | Dati di Addestramento Utilizzati |
|---|---|---|---|
| Addestramento | Sviluppo e miglioramento modelli | GPTBot, ClaudeBot | Sì |
| Ricerca/Citazione | Risultati ricerca AI e attribuzione | Google-Extended, OAI-SearchBot, PerplexityBot | Variabile |
| Attivato dall’Utente | Analisi contenuti su richiesta | ChatGPT-User, Meta-ExternalAgent, Amazonbot | Contestuale |
La gestione dei crawler AI ha un impatto diretto su traffico, ricavi e valore dei tuoi contenuti. Quando i crawler consumano i tuoi contenuti senza compenso, perdi l’opportunità di trarre beneficio da quel traffico tramite referral, impression pubblicitarie o coinvolgimento degli utenti. Alcuni siti hanno segnalato riduzioni significative di traffico poiché gli utenti trovano risposte direttamente nelle risposte AI invece di cliccare sulla fonte originale, tagliando di fatto il traffico di referral e i relativi ricavi pubblicitari. Oltre alle implicazioni finanziarie, ci sono considerazioni legali ed etiche—i tuoi contenuti rappresentano proprietà intellettuale e hai il diritto di controllare come vengono usati e se ricevi attribuzione o compenso. Inoltre, consentire un accesso illimitato dei crawler può aumentare il carico del server e i costi di banda, soprattutto da parte di crawler con tassi di scansione aggressivi che non rispettano le direttive di limitazione del ritmo.
Il file robots.txt è lo strumento base per gestire l’accesso dei crawler, da posizionare nella directory root del sito per comunicare le preferenze di scansione agli agenti automatici. Questo file usa direttive User-agent per indirizzare specifici crawler e regole Disallow o Allow per consentire o limitare l’accesso a determinati percorsi e risorse. Tuttavia, robots.txt presenta importanti limitazioni—è uno standard volontario che si basa sulla conformità del crawler e bot malevoli o mal progettati possono ignorarlo completamente. Inoltre, robots.txt non impedisce ai crawler di accedere a contenuti pubblicamente disponibili; si limita a richiedere il rispetto delle tue preferenze. Per questo motivo, robots.txt dovrebbe essere parte di un approccio stratificato alla gestione dei crawler e non la tua unica difesa.
# Blocca i crawler AI di addestramento
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Consenti i motori di ricerca
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Regola di default per altri crawler
User-agent: *
Allow: /
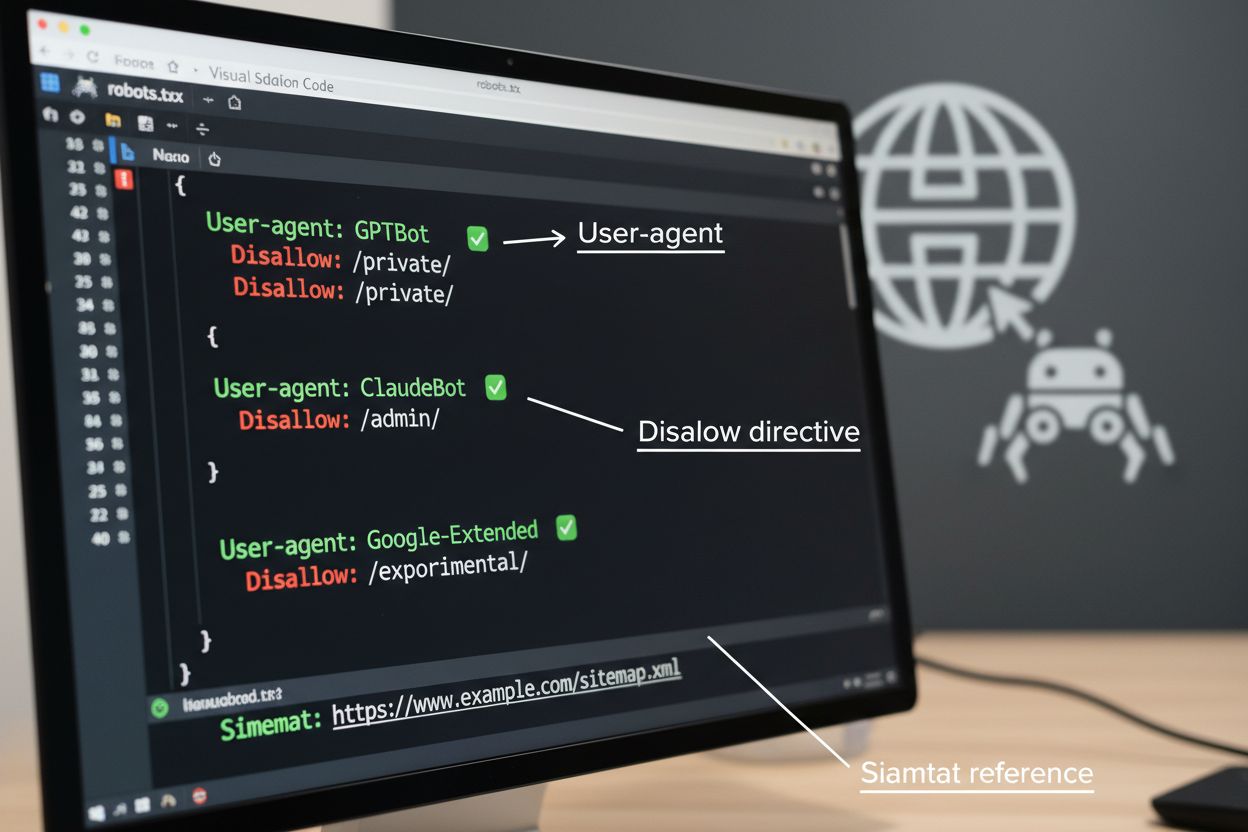
Oltre al robots.txt, diverse tecniche avanzate offrono un’applicazione più forte e un controllo più granulare sull’accesso dei crawler. Questi metodi operano a diversi livelli della tua infrastruttura e possono essere combinati per una protezione completa:
La decisione di bloccare i crawler AI comporta importanti compromessi tra protezione dei contenuti e visibilità. Bloccare tutti i crawler AI elimina la possibilità che i tuoi contenuti compaiano nei risultati di ricerca AI, nei riassunti AI o vengano citati dagli strumenti AI—potenzialmente riducendo la visibilità presso utenti che scoprono contenuti tramite questi nuovi canali. Al contrario, consentire un accesso illimitato significa che i tuoi contenuti alimentano l’addestramento AI senza compenso e può ridurre il traffico di referral, poiché gli utenti ottengono risposte direttamente dai sistemi AI. Un approccio strategico prevede il blocco selettivo: permettere crawler di citazione come OAI-SearchBot e PerplexityBot che generano traffico di riferimento e bloccare i crawler di addestramento come GPTBot e ClaudeBot che consumano dati senza attribuzione. Potresti anche considerare di consentire Google-Extended per mantenere la visibilità nei Google AI Overviews, che possono generare traffico rilevante, mentre blocchi i crawler di addestramento dei concorrenti. La strategia ottimale dipende dal tipo di contenuto, modello di business e pubblico: siti di notizie ed editori possono preferire il blocco, mentre chi crea contenuti educativi potrebbe beneficiare di una maggiore visibilità AI.
Implementare controlli sui crawler è efficace solo se verifichi che i crawler rispettino realmente le tue direttive. L’analisi dei log del server è il metodo principale per monitorare l’attività dei crawler: esamina i log di accesso per le stringhe User-Agent e i pattern di richiesta per identificare quali crawler stanno accedendo al tuo sito e se rispettano le regole di robots.txt. Molti crawler dichiarano conformità ma continuano ad accedere ai percorsi bloccati, rendendo essenziale il monitoraggio continuo. Strumenti come Cloudflare Radar offrono visibilità in tempo reale sui pattern di traffico e possono aiutare a identificare comportamenti sospetti o crawler non conformi. Imposta alert automatici per i tentativi di accesso a risorse bloccate e controlla periodicamente i log per individuare nuovi crawler o cambi di pattern che possano indicare tentativi di elusione.
Implementare una gestione efficace dei crawler AI richiede un approccio sistematico che bilanci protezione e visibilità strategica. Segui questi otto passaggi per stabilire una strategia di gestione dei crawler completa:
AmICited.com offre una piattaforma specializzata per monitorare come i sistemi AI citano e utilizzano i tuoi contenuti tra diversi modelli e applicazioni. Il servizio offre tracciamento in tempo reale delle tue citazioni nelle risposte generate dall’AI, aiutandoti a capire quali crawler utilizzano maggiormente i tuoi contenuti e con quale frequenza il tuo lavoro compare nei risultati AI. Analizzando pattern dei crawler e dati sulle citazioni, AmICited.com ti permette di prendere decisioni informate sulla tua strategia di gestione dei crawler—puoi vedere esattamente quali crawler portano valore attraverso citazioni e referral e quali invece consumano contenuti senza attribuzione. Questa intelligence trasforma la gestione dei crawler da pratica difensiva a strumento strategico per ottimizzare la visibilità e l’impatto dei tuoi contenuti nel web potenziato dall’AI.
I crawler di addestramento come GPTBot e ClaudeBot raccolgono contenuti per creare dataset per lo sviluppo di modelli linguistici di grandi dimensioni, consumando i tuoi contenuti senza fornire traffico di riferimento. I crawler di ricerca come OAI-SearchBot e PerplexityBot indicizzano i contenuti per risultati di ricerca AI e possono rimandare visitatori al tuo sito tramite citazioni. Bloccare i crawler di addestramento protegge i tuoi contenuti dall’essere incorporati nei modelli AI, mentre bloccare i crawler di ricerca può ridurre la tua visibilità sulle piattaforme di scoperta AI.
No. Bloccare i crawler AI di addestramento come GPTBot, ClaudeBot e CCBot non influisce sul posizionamento su Google o Bing. I motori di ricerca tradizionali usano crawler diversi (Googlebot, Bingbot) che operano indipendentemente dai bot di addestramento AI. Blocca i crawler di ricerca tradizionali solo se vuoi scomparire completamente dai risultati di ricerca, il che danneggerebbe la tua SEO.
Analizza i log di accesso del tuo server per identificare le stringhe User-Agent dei crawler. Cerca voci che contengano 'bot', 'crawler' o 'spider' nel campo User-Agent. Strumenti come Cloudflare Radar offrono visibilità in tempo reale su quali crawler AI accedono al tuo sito e sui loro pattern di traffico. Puoi anche utilizzare piattaforme di analisi che distinguono il traffico dei bot da quello umano.
Sì. robots.txt è uno standard consultivo che si basa sulla conformità del crawler—non è vincolante. I crawler corretti delle grandi aziende come OpenAI, Anthropic e Google generalmente rispettano le direttive robots.txt, ma alcuni crawler le ignorano completamente. Per una protezione più forte, implementa il blocco a livello di server tramite .htaccess, regole firewall o restrizioni basate su IP.
Dipende dalle tue priorità aziendali. Bloccare tutti i crawler di addestramento protegge i tuoi contenuti dall’essere incorporati nei modelli AI, consentendo eventualmente i crawler di ricerca che possono generare traffico di riferimento. Molti editori usano un blocco selettivo che mira ai crawler di addestramento, consentendo invece quelli di ricerca e citazione. Considera il tipo di contenuto, le fonti di traffico e il modello di monetizzazione quando definisci la tua strategia.
Rivedi e aggiorna la tua policy di gestione crawler almeno trimestralmente. Nuovi crawler AI emergono regolarmente ed esistenti aggiornano i loro user agent senza preavviso. Tieni traccia di risorse come il progetto ai.robots.txt su GitHub per elenchi mantenuti dalla community e controlla mensilmente i log del server per identificare nuovi crawler che visitano il tuo sito.
I crawler AI possono avere un impatto significativo su traffico e ricavi. Quando gli utenti ottengono risposte direttamente dai sistemi AI invece di visitare il tuo sito, perdi traffico di riferimento e le relative impression pubblicitarie. La ricerca mostra rapporti crawl-to-refer fino a 73.000:1 per alcune piattaforme AI, cioè accedono ai tuoi contenuti migliaia di volte per ogni visitatore che inviano. Bloccare i crawler di addestramento può proteggere il traffico, mentre consentire quelli di ricerca può dare qualche beneficio di referral.
Controlla i log del server per vedere se i crawler bloccati compaiono ancora nei log di accesso. Usa strumenti di test come il tester robots.txt di Google Search Console o il tester di Merkle per validare la configurazione. Accedi direttamente al tuo file robots.txt su yoursite.com/robots.txt per verificare che il contenuto sia corretto. Monitora regolarmente i log per individuare crawler che dovrebbero essere bloccati ma che ancora compaiono.
AmICited.com traccia in tempo reale i riferimenti AI al tuo brand su ChatGPT, Perplexity, Google AI Overviews e altri sistemi AI. Prendi decisioni informate sulla tua strategia di gestione dei crawler.
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...

Scopri come identificare e monitorare i crawler AI come GPTBot, PerplexityBot e ClaudeBot nei log del tuo server. Scopri stringhe user-agent, metodi di verifica...
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...