Come Ottenere Prodotti Raccomandati dall'IA?
Scopri come funzionano le raccomandazioni di prodotti tramite IA, gli algoritmi che le guidano, e come ottimizzare la visibilità nei sistemi di raccomandazione ...
9 min di lettura
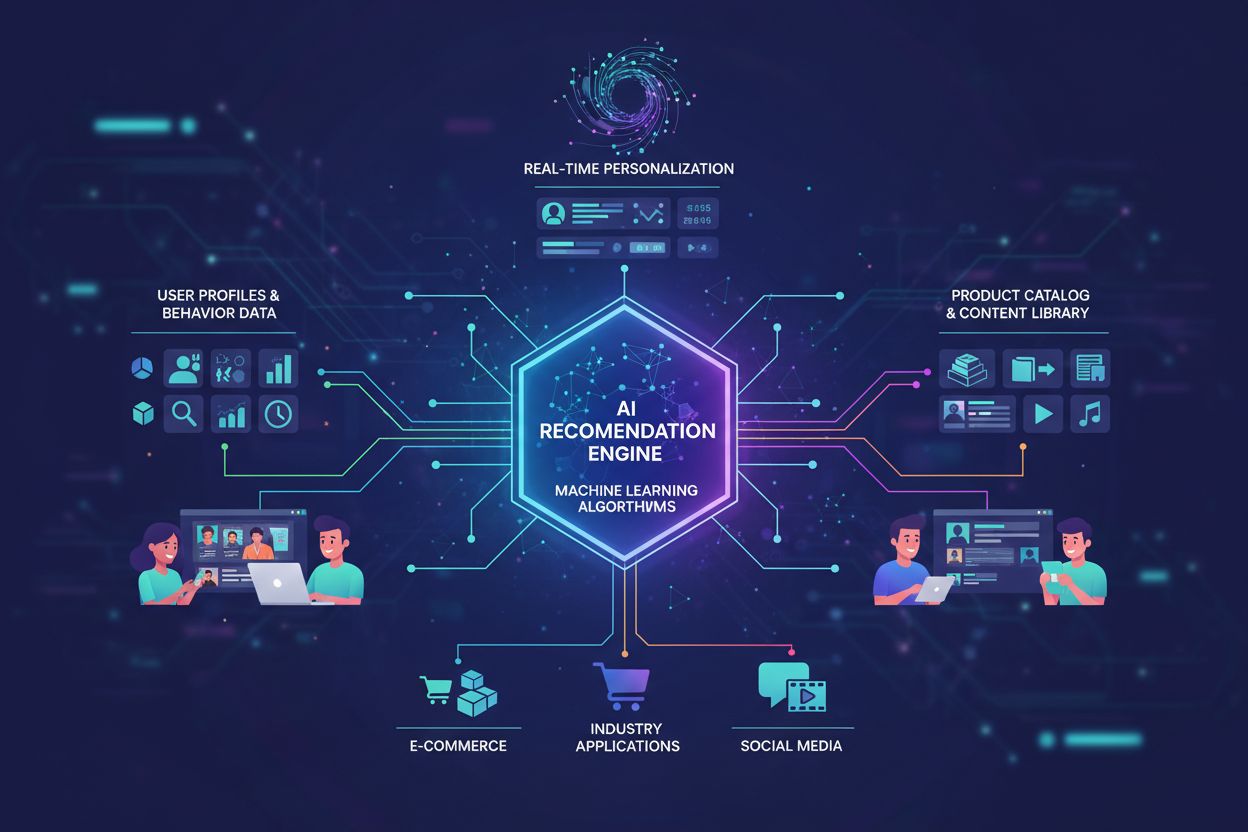
Sistemi di apprendimento automatico che analizzano il comportamento e le preferenze degli utenti per offrire suggerimenti personalizzati su prodotti e contenuti. Questi sistemi utilizzano algoritmi come il filtraggio collaborativo e il filtraggio basato sui contenuti per prevedere cosa potrebbe interessare agli utenti, consentendo alle aziende di aumentare il coinvolgimento, le vendite e la soddisfazione dei clienti attraverso raccomandazioni su misura.
Sistemi di apprendimento automatico che analizzano il comportamento e le preferenze degli utenti per offrire suggerimenti personalizzati su prodotti e contenuti. Questi sistemi utilizzano algoritmi come il filtraggio collaborativo e il filtraggio basato sui contenuti per prevedere cosa potrebbe interessare agli utenti, consentendo alle aziende di aumentare il coinvolgimento, le vendite e la soddisfazione dei clienti attraverso raccomandazioni su misura.
Le raccomandazioni basate sull’IA rappresentano una tecnologia sofisticata che utilizza algoritmi di apprendimento automatico per analizzare il comportamento e le preferenze degli utenti, offrendo suggerimenti personalizzati su misura per le esigenze e gli interessi individuali. Un motore di raccomandazione è il componente centrale di questo sistema, funzionando come un intermediario intelligente tra vasti cataloghi di prodotti e utenti singoli, consentendo livelli di personalizzazione senza precedenti su larga scala. Il mercato globale dei motori di raccomandazione ha registrato una crescita esplosiva, con un valore di circa 2,8 miliardi di dollari nel 2023 e una previsione di raggiungere gli 8,5 miliardi entro il 2030, a testimonianza dell’importanza di questa tecnologia nell’economia digitale. Queste raccomandazioni sono diventate indispensabili in settori molto diversi, con applicazioni di rilievo su piattaforme di e-commerce come Amazon ed eBay, servizi di streaming come Netflix e Spotify, social network e piattaforme di contenuti. Il principio fondamentale alla base di questi sistemi è che gli algoritmi di apprendimento automatico possono individuare schemi nel comportamento degli utenti che gli esseri umani non riescono facilmente a rilevare, consentendo alle aziende di anticipare le esigenze dei clienti prima ancora che questi le riconoscano. Sfruttando vasti dataset e potenza computazionale, i sistemi di raccomandazione hanno trasformato il modo in cui i consumatori scoprono prodotti, contenuti e servizi, ridefinendo radicalmente le strategie di coinvolgimento dei clienti in ogni settore.

I sistemi di raccomandazione basati sull’IA operano attraverso un sofisticato processo in cinque fasi che trasforma i dati grezzi degli utenti in suggerimenti personalizzati e azionabili. La prima fase prevede una raccolta dati completa, in cui i sistemi acquisiscono informazioni da molteplici touchpoint tra cui interazioni, cronologia di navigazione, registri di acquisto e meccanismi di feedback esplicito. Durante la fase di analisi, il sistema elabora questi dati per identificare schemi e relazioni significative, utilizzando algoritmi di apprendimento automatico come il filtraggio collaborativo, il filtraggio basato sui contenuti e le reti neurali per estrarre insight da dataset complessi. La fase di riconoscimento degli schemi rappresenta il cuore computazionale del sistema, dove gli algoritmi identificano somiglianze tra utenti, articoli o entrambi, creando rappresentazioni matematiche delle preferenze e delle caratteristiche degli oggetti. La fase di previsione sfrutta questi schemi per prevedere con quali elementi un utente è più propenso a interagire, assegnando punteggi di affidabilità alle raccomandazioni potenziali. Infine, la fase di delivery presenta queste previsioni agli utenti tramite interfacce personalizzate, assicurando che le raccomandazioni emergano nei momenti ottimali lungo il percorso utente. Le capacità di elaborazione in tempo reale sono diventate sempre più critiche, con i sistemi moderni che aggiornano le raccomandazioni istantaneamente al variare dei dati comportamentali, permettendo una personalizzazione dinamica che si adatta alle preferenze in evoluzione. I sistemi di raccomandazione avanzati utilizzano metodi ensemble che combinano simultaneamente più algoritmi, ciascuno dei quali contribuisce alle previsioni finali per ottenere risultati più robusti e accurati rispetto a qualsiasi approccio singolo.
I sistemi di raccomandazione si basano su due categorie distinte di dati utente, ognuna delle quali fornisce insight unici su preferenze e comportamenti:
Dati espliciti:
Dati impliciti:
I dati espliciti offrono segnali diretti e inequivocabili delle preferenze, ma soffrono di scarsità poiché la maggior parte degli utenti valuta solo una piccola frazione degli elementi disponibili. I dati impliciti, al contrario, sono abbondanti e generati continuamente nelle interazioni quotidiane, ma richiedono interpretazioni sofisticate poiché, ad esempio, la semplice visualizzazione di un prodotto non indica necessariamente una preferenza. I sistemi di raccomandazione più efficaci integrano entrambi i tipi di dati, utilizzando il feedback esplicito per validare e calibrare i segnali impliciti, creando profili utente completi che catturano sia le preferenze dichiarate che quelle rivelate.
Il filtraggio collaborativo rappresenta uno degli approcci fondamentali nei sistemi di raccomandazione, basandosi sul principio che utenti con preferenze simili in passato probabilmente apprezzeranno elementi simili in futuro. Questa metodologia analizza i pattern di preferenza dell’intera popolazione di utenti per individuare affinità, distinguendosi dagli approcci che esaminano le caratteristiche dei singoli articoli. Il filtraggio collaborativo user-based identifica utenti con storie di preferenza simili a quelle dell’utente target e propone elementi già apprezzati da questi utenti ma non ancora scoperti dall’utente target, sfruttando così la saggezza degli utenti comparabili. Il filtraggio collaborativo item-based, al contrario, si concentra sulle somiglianze tra articoli, raccomandando prodotti simili a quelli già valutati positivamente dall’utente, basandosi su come altri utenti hanno valutato tali elementi in relazione tra loro. Entrambi gli approcci utilizzano metriche di similarità sofisticate come la similarità coseno, la correlazione di Pearson o la distanza euclidea per quantificare quanto utenti o articoli siano simili nello spazio delle preferenze. Il filtraggio collaborativo offre vantaggi significativi, tra cui la possibilità di suggerire elementi privi di metadati descrittivi e la capacità di scoprire raccomandazioni inattese che l’utente non avrebbe previsto. Tuttavia, presenta limiti notevoli, in particolare il “problema del cold start”, in cui nuovi utenti o elementi non dispongono di dati storici sufficienti per un calcolo accurato delle similarità, e problemi di scarsità dati in domini con milioni di articoli dove la maggior parte delle interazioni rimane non osservata.
L’approccio di filtraggio basato sui contenuti elabora le raccomandazioni analizzando le caratteristiche intrinseche e le proprietà degli articoli stessi, suggerendo prodotti simili a quelli già preferiti dall’utente in base ai loro attributi misurabili. Invece di affidarsi ai pattern comportamentali collettivi, i sistemi content-based costruiscono profili dettagliati degli articoli includendo caratteristiche rilevanti come genere, regista e cast per i film; autore, argomento e data di pubblicazione per i libri; oppure categoria prodotto, marca e specifiche tecniche per l’e-commerce. Il sistema calcola la similarità tra articoli confrontando i loro vettori di attributi tramite tecniche matematiche come la similarità coseno o la distanza euclidea, creando una misura quantitativa di quanto gli articoli si assomiglino nello spazio delle caratteristiche. Quando un utente valuta o interagisce con un elemento, il sistema individua altri articoli con profili simili e li raccomanda, personalizzando così i suggerimenti in base alle preferenze dimostrate per specifiche caratteristiche. Il filtraggio basato sui contenuti eccelle in contesti dove i metadati degli articoli sono ricchi e ben strutturati, e gestisce naturalmente il problema del cold start per i nuovi articoli poiché le raccomandazioni dipendono dagli attributi e non dalle interazioni storiche. Tuttavia, questo approccio ha limiti in termini di serendipità e scoperta, tendendo a proporre articoli altamente simili alle preferenze passate e creando potenzialmente “filter bubble” che restringono l’utente a categorie limitate. Rispetto al filtraggio collaborativo, i sistemi content-based richiedono un’accurata ingegneria delle caratteristiche e trovano difficoltà con articoli privi di confini categoriali chiari, ma offrono maggiore trasparenza poiché le raccomandazioni possono essere spiegate facendo riferimento agli attributi specifici degli elementi.
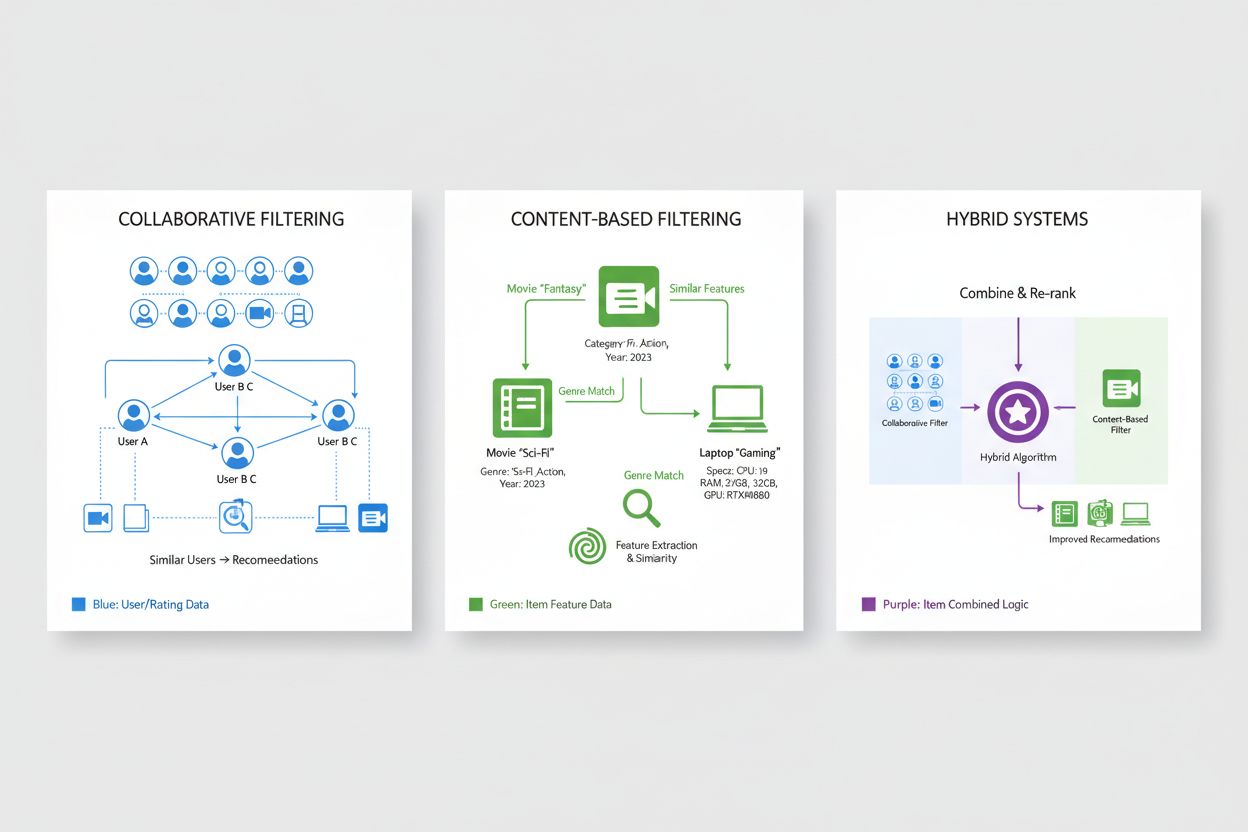
I sistemi di raccomandazione ibridi combinano strategicamente gli approcci di filtraggio collaborativo e basato sui contenuti, sfruttando i punti di forza complementari di ciascuna metodologia per superare i limiti individuali e offrire raccomandazioni più accurate. Questi sistemi utilizzano diverse strategie di integrazione, tra cui combinazioni pesate in cui le previsioni di più algoritmi vengono fuse tramite pesi predefiniti o appresi, meccanismi di switching che selezionano l’algoritmo più adatto in base al contesto, oppure approcci a cascata in cui l’output di un algoritmo alimenta quello successivo. Integrando la capacità del filtraggio collaborativo di individuare raccomandazioni sorprendenti e cogliere pattern complessi di preferenza con la capacità del filtraggio basato sui contenuti di gestire nuovi articoli e fornire raccomandazioni spiegabili, i sistemi ibridi raggiungono prestazioni più robuste in scenari diversi. Le principali aziende tecnologiche hanno adottato approcci ibridi come prassi industriale; Netflix combina filtraggio collaborativo con metodi content-based e informazioni contestuali per proporre raccomandazioni che bilanciano popolarità, personalizzazione e novità. Anche il motore di raccomandazione di Spotify utilizza tecniche ibride, integrando filtraggio collaborativo basato sui pattern di ascolto con l’analisi delle caratteristiche audio e dei metadati, supportato dall’elaborazione del linguaggio naturale applicata a playlist generate dagli utenti e recensioni. I vantaggi dei sistemi ibridi vanno oltre il miglioramento dell’accuratezza, includendo una maggiore copertura del catalogo, una gestione ottimale dei dati scarsi e una resilienza superiore alle sfide tipiche delle raccomandazioni. Questi sistemi rappresentano lo stato dell’arte della tecnologia di personalizzazione, con la maggior parte delle piattaforme di raccomandazione enterprise che utilizzano architetture ibride in continua evoluzione grazie alle nuove innovazioni algoritmiche.
Le raccomandazioni basate sull’IA sono diventate centrali nei modelli di business delle principali aziende tecnologiche e retail, trasformando profondamente il modo in cui i clienti scoprono e acquistano prodotti. Amazon, pioniere dell’e-commerce, genera circa il 35% del suo fatturato totale grazie agli acquisti guidati dalle raccomandazioni, con un sistema sofisticato che analizza cronologia di navigazione, modelli di acquisto, valutazioni di prodotti e comportamenti di clienti simili per suggerire articoli nei momenti chiave del processo d’acquisto. Netflix elabora cronologia delle visualizzazioni, valutazioni, ricerche e pattern temporali per suggerire contenuti, riportando che le raccomandazioni personalizzate rappresentano circa l’80% delle ore guardate sulla piattaforma, a dimostrazione dell’impatto della personalizzazione su coinvolgimento e fidelizzazione. Spotify sfrutta le raccomandazioni basate sull’IA su molteplici superfici, inclusa la funzione “Discover Weekly”, che combina filtraggio collaborativo con analisi delle caratteristiche audio e informazioni contestuali, generando suggerimenti musicali altamente personalizzati diventati centrali per il coinvolgimento degli utenti e la retention degli abbonamenti. Temu, piattaforma e-commerce in rapida crescita, impiega sistemi di raccomandazione avanzati che analizzano pattern comportamentali, query di ricerca e cronologia acquisti per proporre prodotti in linea con le preferenze individuali, contribuendo in modo significativo alla sua crescita esplosiva e alle metriche di engagement. Queste implementazioni dimostrano che i sistemi di raccomandazione incidono direttamente su metriche chiave di business come il valore del cliente nel tempo, il tasso di riacquisto e la durata dell’engagement, con le aziende che investono pesantemente nella tecnologia di raccomandazione come fattore competitivo differenziante in mercati digitali sempre più affollati.
Le raccomandazioni basate sull’IA apportano valore significativo sia alle aziende che agli utenti, creando un ecosistema reciprocamente vantaggioso che favorisce coinvolgimento e soddisfazione:
Benefici per le aziende:
Benefici per gli utenti:
L’impatto cumulativo di questi benefici ha reso i sistemi di raccomandazione infrastrutture essenziali nel commercio e nei contenuti digitali, con gli utenti che si aspettano sempre più esperienze personalizzate come requisito di base e non più come funzionalità premium.
Nonostante il loro successo diffuso, i sistemi di raccomandazione basati sull’IA affrontano sfide significative che ricercatori e professionisti stanno ancora affrontando. Le preoccupazioni sulla privacy dei dati sono aumentate con l’entrata in vigore di normative come GDPR e CCPA, che impongono requisiti stringenti sulla raccolta e l’uso dei dati, costringendo le aziende a bilanciare l’efficacia della personalizzazione con i diritti degli utenti e gli obblighi di protezione dei dati. Il problema del cold start rimane particolarmente acuto per nuovi utenti ed elementi, dove la mancanza di dati storici impedisce raccomandazioni accurate, richiedendo approcci ibridi o strategie alternative per avviare la personalizzazione. Il bias algoritmico rappresenta una sfida critica, poiché i sistemi di raccomandazione possono perpetuare e amplificare i bias presenti nei dati di addestramento, potenzialmente discriminando determinati gruppi di utenti o creando filter bubble che limitano l’esposizione a prospettive e contenuti diversi.
Le tendenze emergenti stanno ridefinendo il panorama delle raccomandazioni, con la personalizzazione in tempo reale che diventa sempre più sofisticata grazie all’edge computing e all’elaborazione di dati in streaming, consentendo un adattamento istantaneo ai comportamenti degli utenti. L’integrazione di dati multimodali sta andando oltre i segnali comportamentali tradizionali per includere caratteristiche visive, audio, contenuti testuali e informazioni contestuali, permettendo una comprensione più ricca e sfumata delle preferenze. Le raccomandazioni guidate dall’emozione rappresentano una frontiera della personalizzazione, con sistemi che iniziano a integrare il contesto emotivo e l’analisi del sentiment per suggerire elementi in linea non solo con le preferenze storiche, ma anche con lo stato emotivo e i bisogni attuali. Gli sviluppi futuri probabilmente enfatizzeranno spiegabilità e trasparenza, consentendo agli utenti di comprendere perché determinate raccomandazioni vengono mostrate e offrendo meccanismi di controllo per modellare il proprio profilo di raccomandazione. La convergenza di queste tendenze suggerisce che i sistemi di raccomandazione di nuova generazione saranno più attenti alla privacy, trasparenti, emotivamente intelligenti e in grado di offrire esperienze di personalizzazione realmente trasformative nel pieno rispetto dell’autonomia e dei diritti degli utenti sui dati.
Le raccomandazioni basate sull'IA suggeriscono proattivamente elementi in base al comportamento e alle preferenze dell'utente senza richiedere ricerche esplicite, mentre la ricerca tradizionale richiede agli utenti di cercare attivamente i prodotti. Le raccomandazioni utilizzano l'apprendimento automatico per prevedere gli interessi, mentre la ricerca si basa sull'abbinamento delle parole chiave. Le raccomandazioni sono personalizzate per ogni utente, mentre i risultati della ricerca sono generalmente più generici. I sistemi moderni spesso combinano entrambi gli approcci per offrire la migliore esperienza utente.
I nuovi utenti affrontano il 'problema del cold start', in cui i sistemi non dispongono di dati storici per fornire raccomandazioni accurate. Le soluzioni includono l'utilizzo di informazioni demografiche, la visualizzazione di elementi popolari, l'impiego di filtraggio basato sui contenuti in base alle caratteristiche degli articoli o la richiesta di preferenze esplicite. I sistemi ibridi combinano diversi approcci per avviare le raccomandazioni per i nuovi utenti. Alcune piattaforme utilizzano il filtraggio collaborativo con profili di utenti simili o informazioni contestuali come il tipo di dispositivo e la posizione per fornire suggerimenti iniziali.
I sistemi di raccomandazione raccolgono dati espliciti come valutazioni, recensioni e feedback degli utenti, oltre a dati impliciti come cronologia di navigazione, registri di acquisto, tempo trascorso sugli elementi, query di ricerca e modelli di click. Possono anche raccogliere informazioni contestuali come tipo di dispositivo, posizione, ora del giorno e fattori stagionali. I sistemi avanzati integrano dati demografici, connessioni sociali e segnali comportamentali. Tutta la raccolta dati deve rispettare normative sulla privacy come GDPR e CCPA, richiedendo il consenso dell'utente e politiche di utilizzo dei dati trasparenti.
Sì, i sistemi di raccomandazione possono perpetuare e amplificare i bias presenti nei dati di addestramento, potenzialmente discriminando alcuni gruppi di utenti o limitando l’esposizione a contenuti diversificati. Il bias algoritmico può derivare da dati storici distorti, sotto-rappresentazione di gruppi minoritari o meccanismi di feedback che rafforzano i modelli esistenti. Affrontare il bias richiede dati di addestramento diversificati, audit regolari, metriche di equità e progettazione algoritmica trasparente. Le aziende devono monitorare attivamente il bias e implementare strategie di mitigazione per garantire raccomandazioni eque per tutti i segmenti di utenti.
I sistemi ibridi combinano la capacità del filtraggio collaborativo di identificare raccomandazioni sorprendenti con quella del filtraggio basato sui contenuti di gestire nuovi elementi e fornire suggerimenti spiegabili. Questa combinazione supera i limiti dei singoli approcci: il filtraggio collaborativo ha difficoltà con i nuovi elementi, mentre il filtraggio basato sui contenuti manca di serendipità. Gli approcci ibridi utilizzano combinazioni pesate, meccanismi di switching o metodi a cascata per sfruttare i punti di forza di ciascun algoritmo. Il risultato è una maggiore accuratezza, una migliore copertura dei cataloghi di elementi, una gestione ottimale dei dati scarsi e prestazioni più robuste in scenari diversi.
Le preoccupazioni sulla privacy includono la vasta raccolta di dati necessaria per raccomandazioni accurate, il potenziale utilizzo non autorizzato dei dati, i rischi di violazione dei dati e le sfide di conformità normativa secondo GDPR, CCPA e leggi simili. Gli utenti possono sentirsi a disagio per il livello di tracciamento comportamentale richiesto per la personalizzazione. Le aziende devono implementare una forte sicurezza dei dati, ottenere il consenso esplicito, fornire trasparenza sull'uso dei dati e permettere agli utenti di controllare i propri dati. Bilanciare l’efficacia della personalizzazione con la protezione della privacy rimane una sfida continua nel settore.
Le raccomandazioni in tempo reale elaborano i dati sul comportamento degli utenti istantaneamente man mano che si verificano, aggiornando i suggerimenti immediatamente in base alle interazioni correnti. I sistemi utilizzano l'elaborazione di dati in streaming e il computing edge per analizzare azioni come click, visualizzazioni o acquisti in pochi millisecondi. Ciò consente una personalizzazione dinamica che si adatta alle preferenze che cambiano durante la sessione utente. I sistemi in tempo reale richiedono un'infrastruttura robusta, algoritmi efficienti e pipeline di dati a bassa latenza. Esempi includono Netflix che aggiorna le raccomandazioni mentre navighi o Amazon che mostra nuovi suggerimenti mentre aggiungi articoli al carrello.
Le tendenze future includono raccomandazioni guidate dall’emozione che considerano lo stato emotivo dell’utente, integrazione di dati multimodali che combinano informazioni visive, audio e testuali, tecniche avanzate di preservazione della privacy, maggiore spiegabilità e trasparenza, e personalizzazione in tempo reale su larga scala. Tecnologie emergenti come il federated learning permettono raccomandazioni senza centralizzare i dati degli utenti. I sistemi saranno più consapevoli del contesto, incorporando fattori temporali e situazionali. La convergenza di queste tendenze offrirà personalizzazione più sofisticata, trasparente e attenta alla privacy nel rispetto dell’autonomia e dei diritti sui dati degli utenti.
AmICited traccia come sistemi di IA come ChatGPT, Perplexity e Google AI Overviews citano il tuo brand nelle raccomandazioni personalizzate e nei contenuti generati dall'IA. Rimani aggiornato sulla visibilità del tuo brand nei sistemi basati sull'IA.
Scopri come funzionano le raccomandazioni di prodotti tramite IA, gli algoritmi che le guidano, e come ottimizzare la visibilità nei sistemi di raccomandazione ...
Scopri come le recensioni dei clienti influenzano gli algoritmi di raccomandazione dell'IA, migliorano l'accuratezza delle raccomandazioni e aumentano la person...
Discussione della community sui contenuti sponsorizzati e la pubblicità nella ricerca AI. Utenti e marketer discutono dei modelli osservati in ChatGPT, Perplexi...