Comment obtenir des produits recommandés par l’IA ?
Découvrez comment fonctionnent les recommandations de produits par l’IA, les algorithmes qui les sous-tendent et comment optimiser votre visibilité dans les sys...
10 min de lecture
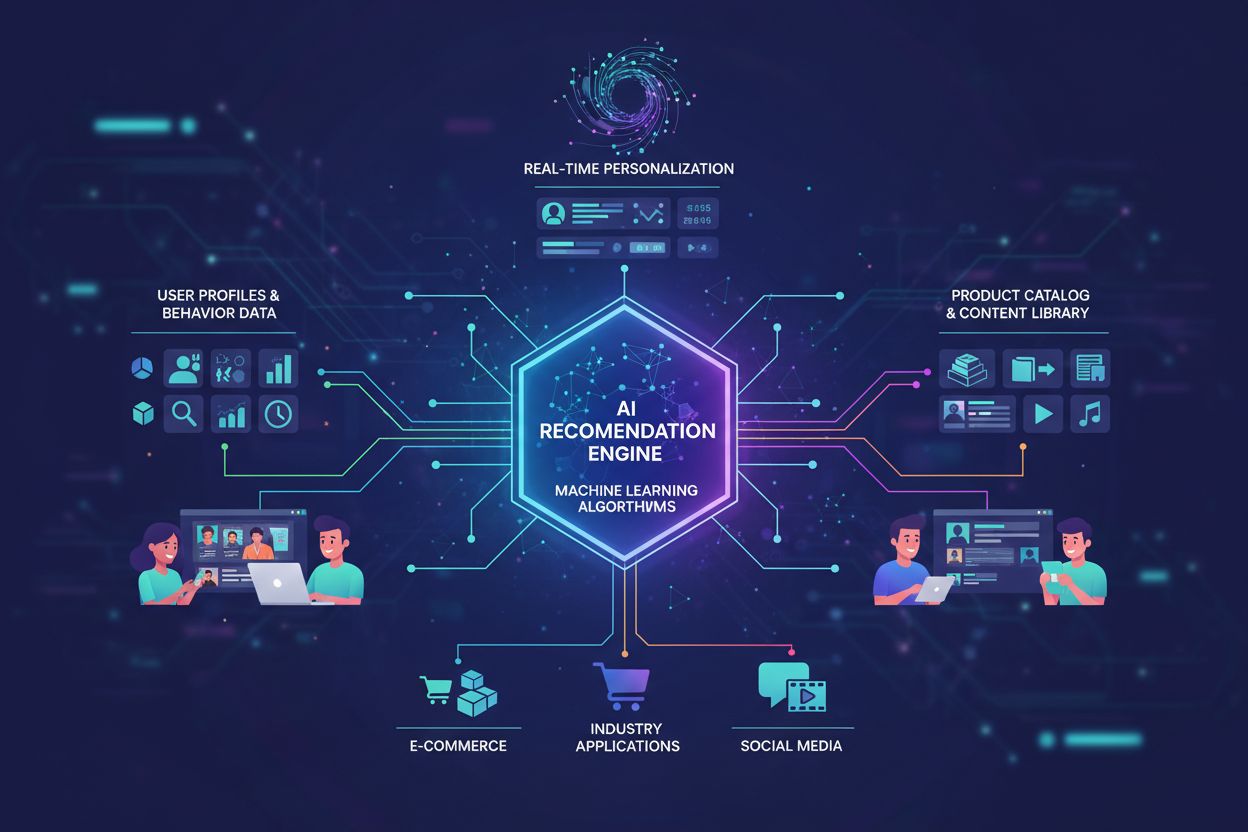
Systèmes d’apprentissage automatique qui analysent le comportement et les préférences des utilisateurs afin de fournir des suggestions personnalisées de produits et de contenus. Ces systèmes utilisent des algorithmes tels que le filtrage collaboratif et le filtrage basé sur le contenu pour prédire ce qui pourrait intéresser les utilisateurs, permettant ainsi aux entreprises d’accroître l’engagement, les ventes et la satisfaction client grâce à des recommandations sur mesure.
Systèmes d'apprentissage automatique qui analysent le comportement et les préférences des utilisateurs afin de fournir des suggestions personnalisées de produits et de contenus. Ces systèmes utilisent des algorithmes tels que le filtrage collaboratif et le filtrage basé sur le contenu pour prédire ce qui pourrait intéresser les utilisateurs, permettant ainsi aux entreprises d'accroître l'engagement, les ventes et la satisfaction client grâce à des recommandations sur mesure.
Les recommandations alimentées par l’IA représentent une technologie sophistiquée qui utilise des algorithmes de machine learning pour analyser le comportement et les préférences des utilisateurs, fournissant des suggestions personnalisées adaptées aux besoins et intérêts individuels. Un moteur de recommandation est le composant central de ce système, agissant comme un intermédiaire intelligent entre d’immenses catalogues de produits et les utilisateurs individuels, permettant des niveaux de personnalisation sans précédent à grande échelle. Le marché mondial des moteurs de recommandation a connu une croissance explosive, évalué à environ 2,8 milliards de dollars en 2023 et estimé à 8,5 milliards de dollars d’ici 2030, reflétant l’importance cruciale de cette technologie dans l’économie numérique. Ces recommandations alimentées par l’IA sont devenues indispensables dans de nombreux secteurs, avec des applications majeures sur les plateformes de e-commerce comme Amazon et eBay, les services de streaming tels que Netflix et Spotify, les réseaux sociaux et les plateformes de contenus. Le principe fondamental de ces systèmes est que les algorithmes de machine learning peuvent identifier des schémas dans le comportement utilisateur que les humains ne peuvent pas facilement détecter, permettant ainsi aux entreprises d’anticiper les besoins des clients avant même que les utilisateurs n’en prennent conscience. En exploitant de vastes ensembles de données et la puissance de calcul, les systèmes de recommandation ont transformé la manière dont les consommateurs découvrent des produits, des contenus et des services, remodelant fondamentalement les stratégies d’engagement client dans tous les secteurs.

Les systèmes de recommandation alimentés par l’IA fonctionnent selon un processus sophistiqué en cinq phases qui transforme des données brutes utilisateur en suggestions personnalisées exploitables. La première phase implique une collecte de données complète, où les systèmes recueillent des informations à partir de multiples points de contact, y compris les interactions utilisateur, l’historique de navigation, les achats et les mécanismes de retour explicite. Lors de la phase d’analyse, le système traite ces données collectées pour en dégager des schémas et relations significatifs, utilisant des algorithmes de machine learning comme le filtrage collaboratif, le filtrage basé sur le contenu et les réseaux neuronaux pour extraire des insights à partir de jeux de données complexes. La phase de reconnaissance de motifs constitue le cœur computationnel du système, où les algorithmes identifient des similitudes entre utilisateurs, éléments ou les deux, créant des représentations mathématiques des préférences et des caractéristiques des articles. La phase de prédiction utilise ces schémas identifiés pour anticiper avec quels éléments un utilisateur est le plus susceptible d’interagir, attribuant des scores de confiance aux recommandations potentielles. Enfin, la phase de diffusion présente ces prédictions à l’utilisateur via des interfaces personnalisées, garantissant que les recommandations apparaissent aux moments optimaux du parcours utilisateur. Les capacités de traitement en temps réel sont devenues cruciales : les systèmes modernes mettent à jour les recommandations instantanément à mesure que de nouvelles données comportementales arrivent, permettant une personnalisation dynamique qui s’adapte aux préférences changeantes. Les systèmes de recommandation avancés utilisent des méthodes d’ensemble qui combinent plusieurs algorithmes simultanément, chacun apportant ses prédictions pour générer des recommandations finales plus robustes et précises qu’une approche individuelle.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Les systèmes de recommandation s’appuient sur deux catégories distinctes de données utilisateur, chacune apportant des perspectives uniques sur les préférences et comportements :
Données explicites :
Données implicites :
Les données explicites offrent des signaux directs et non ambigus sur les préférences utilisateur, mais souffrent de rareté puisque la plupart des utilisateurs n’évaluent qu’une infime fraction des articles disponibles. Les données implicites, à l’inverse, sont abondantes et générées en continu lors des interactions normales, mais nécessitent une interprétation sophistiquée, car visualiser un produit n’indique pas nécessairement une préférence. Les systèmes de recommandation les plus efficaces intègrent les deux types de données, utilisant les retours explicites pour valider et calibrer les signaux implicites, créant des profils utilisateurs exhaustifs qui capturent à la fois les préférences déclarées et révélées.
Le filtrage collaboratif est l’une des approches fondamentales des systèmes de recommandation, reposant sur le principe que des utilisateurs ayant eu des préférences similaires par le passé apprécieront probablement des articles similaires à l’avenir. Cette méthodologie analyse les motifs à l’échelle de l’ensemble des utilisateurs pour identifier des points communs, se distinguant des approches qui examinent les caractéristiques individuelles des articles. Le filtrage collaboratif basé sur l’utilisateur identifie des utilisateurs aux historiques de préférences similaires à ceux d’un utilisateur cible, puis recommande des articles que ces utilisateurs similaires ont appréciés mais que l’utilisateur cible n’a pas encore découverts, exploitant ainsi la sagesse des utilisateurs comparables. Le filtrage collaboratif basé sur l’article, à l’inverse, se concentre sur les similarités entre articles, en recommandant des produits semblables à ceux que l’utilisateur a déjà appréciés, en fonction de la façon dont les autres utilisateurs ont noté ces articles entre eux. Les deux approches utilisent des métriques de similarité sophistiquées telles que la similarité cosinus, la corrélation de Pearson ou la distance euclidienne pour quantifier la ressemblance des utilisateurs ou des articles dans l’espace des préférences. Le filtrage collaboratif offre des avantages notables, notamment la capacité de recommander des articles sans métadonnées de contenu et de découvrir des suggestions inattendues que l’utilisateur n’aurait pas anticipées. Cependant, cette approche présente des limites, notamment le « problème du démarrage à froid » où les nouveaux utilisateurs ou articles manquent de données historiques pour des calculs de similarité précis, et les problèmes de rareté des données dans des domaines comprenant des millions d’articles où la plupart des interactions utilisateur-article restent non observées.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Le filtrage basé sur le contenu aborde la recommandation en analysant les caractéristiques intrinsèques et les attributs des articles eux-mêmes, en recommandant des produits similaires à ceux déjà appréciés par l’utilisateur sur la base de leurs attributs mesurables. Plutôt que de s’appuyer sur les tendances globales du comportement utilisateur, les systèmes de filtrage basé sur le contenu construisent des profils détaillés d’articles, englobant des attributs pertinents comme le genre, le réalisateur et le casting pour les films ; l’auteur, le sujet et la date de publication pour les livres ; ou la catégorie, la marque et les spécifications techniques pour les produits e-commerce. Le système calcule la similarité entre articles en comparant leurs vecteurs de caractéristiques avec des techniques mathématiques telles que la similarité cosinus ou la distance euclidienne, créant une mesure quantitative de la ressemblance des articles dans l’espace des caractéristiques. Lorsque l’utilisateur note ou interagit avec un article, le système identifie d’autres articles aux profils similaires et recommande ces alternatives, personnalisant ainsi les suggestions selon les préférences manifestées pour des caractéristiques spécifiques. Le filtrage basé sur le contenu excelle dans les scénarios où les métadonnées sont riches et bien structurées, et il gère naturellement le problème du démarrage à froid pour les nouveaux articles car les recommandations dépendent des attributs plutôt que de l’historique d’interactions. Cependant, cette approche présente des limites en matière de découverte et de surprise, car elle a tendance à recommander des articles très proches des préférences passées, créant potentiellement des bulles de filtre qui restreignent les utilisateurs à des catégories étroites. Comparé au filtrage collaboratif, le filtrage basé sur le contenu nécessite une ingénierie d’attributs explicite et rencontre des difficultés avec les articles sans frontière catégorielle nette, mais il offre une meilleure transparence puisque les recommandations peuvent être expliquées par les attributs spécifiques des articles.
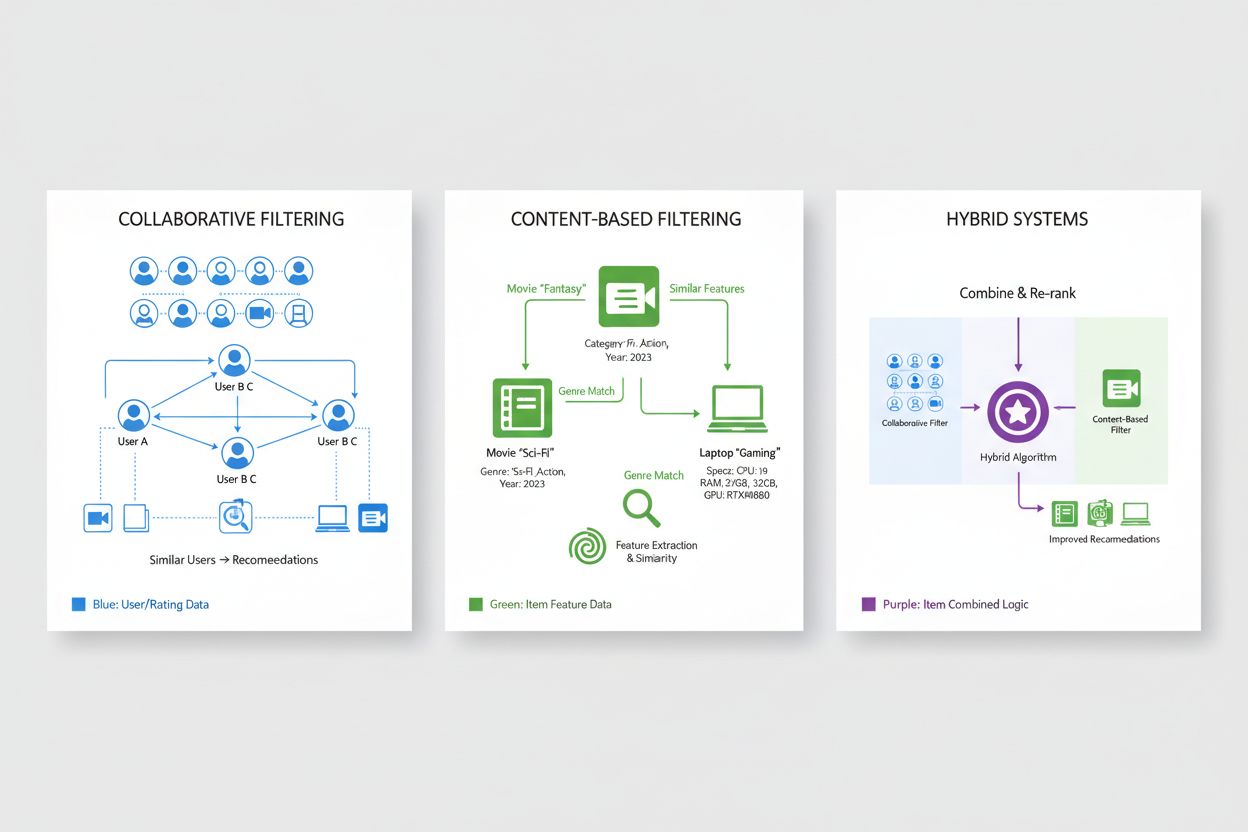
Les systèmes de recommandation hybrides combinent stratégiquement les approches de filtrage collaboratif et de filtrage basé sur le contenu, tirant parti des forces complémentaires de chaque méthodologie pour surmonter leurs limites respectives et offrir une précision de recommandation supérieure. Ces systèmes utilisent diverses stratégies d’intégration, notamment des combinaisons pondérées où les prédictions de plusieurs algorithmes sont fusionnées avec des poids prédéfinis ou appris, des mécanismes de commutation qui sélectionnent l’algorithme le plus approprié selon le contexte, ou des approches en cascade où la sortie d’un algorithme alimente un autre. En intégrant la capacité du filtrage collaboratif à proposer des recommandations inattendues et à saisir des motifs complexes avec celle du filtrage basé sur le contenu à gérer les nouveaux articles et à fournir des suggestions explicables, les systèmes hybrides atteignent des performances plus robustes dans des scénarios variés. Les grandes entreprises technologiques ont adopté les approches hybrides comme pratique industrielle standard ; Netflix combine le filtrage collaboratif avec des méthodes basées sur le contenu et des informations contextuelles pour fournir des recommandations équilibrant popularité, personnalisation et nouveauté. Le moteur de recommandation de Spotify utilise également des techniques hybrides, intégrant le filtrage collaboratif fondé sur les habitudes d’écoute à une analyse basée sur les caractéristiques audio et les métadonnées, enrichie par le traitement du langage naturel des playlists et avis générés par les utilisateurs. Les avantages des systèmes hybrides dépassent l’amélioration de la précision, incluant une couverture accrue du catalogue, une meilleure gestion des données clairsemées et une résilience renforcée face aux défis courants des recommandations. Ces systèmes représentent l’état de l’art actuel de la personnalisation, la plupart des plateformes de recommandation à l’échelle entreprise adoptant des architectures hybrides évoluant continuellement au gré des innovations algorithmiques.
Les recommandations alimentées par l’IA sont devenues centrales dans les modèles économiques des grandes entreprises technologiques et de distribution, transformant fondamentalement la manière dont les clients découvrent et achètent des produits. Amazon, pionnier du e-commerce, génère environ 35 % de son chiffre d’affaires total grâce aux achats induits par ses recommandations, avec un système sophistiqué analysant l’historique de navigation, les achats, les notes de produits et les comportements similaires pour suggérer des articles à des moments clés du parcours d’achat. Netflix exploite l’historique de visionnage, les notes, le comportement de recherche et les tendances temporelles pour suggérer des contenus, la société indiquant que les recommandations personnalisées représentent environ 80 % des heures de visionnage sur sa plateforme, démontrant ainsi l’impact majeur d’une personnalisation efficace sur l’engagement et la fidélisation. Spotify applique les recommandations alimentées par l’IA sur de nombreux aspects, notamment la fonctionnalité « Discover Weekly » qui combine filtrage collaboratif, analyse des caractéristiques audio et informations contextuelles, générant des recommandations musicales hautement personnalisées au cœur de l’engagement et de la rétention d’abonnés. Temu, plateforme e-commerce en forte croissance, utilise des systèmes de recommandation avancés analysant les schémas comportementaux, les requêtes de recherche et l’historique d’achat pour mettre en avant des produits adaptés aux préférences individuelles, contribuant largement à sa croissance explosive et à son engagement utilisateur. Ces exemples montrent que les systèmes de recommandation impactent directement des indicateurs clés comme la valeur vie client, le taux d’achat répété et la durée d’engagement, les entreprises investissant massivement dans cette technologie comme facteur de différenciation dans des marchés numériques de plus en plus saturés.
Les recommandations alimentées par l’IA offrent une valeur considérable aux entreprises comme aux utilisateurs, créant un écosystème gagnant-gagnant stimulant l’engagement et la satisfaction :
Bénéfices pour les entreprises :
Bénéfices pour les utilisateurs :
L’impact cumulé de ces bénéfices fait des systèmes de recommandation une infrastructure essentielle du commerce et des plateformes de contenus numériques, les utilisateurs attendant de plus en plus la personnalisation comme une caractéristique de base plutôt qu’un service premium.
En dépit de leur succès généralisé, les systèmes de recommandation alimentés par l’IA font face à des défis majeurs que chercheurs et praticiens s’efforcent de relever. Les préoccupations liées à la vie privée se sont accrues avec des réglementations comme le RGPD et la CCPA imposant des exigences strictes sur la collecte et l’utilisation des données, obligeant les entreprises à trouver un équilibre entre efficacité de la personnalisation et protection des droits des utilisateurs. Le problème du démarrage à froid demeure aigu pour les nouveaux utilisateurs et articles, l’absence de données historiques empêchant des recommandations précises, ce qui nécessite des approches hybrides ou alternatives pour amorcer la personnalisation. Le biais algorithmique est également un enjeu critique, les systèmes de recommandation pouvant perpétuer et amplifier des biais existants dans les données d’entraînement, discriminant certains groupes ou créant des bulles filtrantes limitant l’accès à la diversité des contenus et perspectives.
De nouvelles tendances redéfinissent le paysage de la recommandation, la personnalisation en temps réel devenant de plus en plus sophistiquée grâce au edge computing et au traitement de données en streaming permettant une adaptation instantanée au comportement utilisateur. L’intégration de données multimodales va au-delà des signaux comportementaux classiques pour inclure des caractéristiques visuelles, audio, textuelles et contextuelles, offrant une compréhension plus riche et nuancée des préférences. Les recommandations émotionnelles représentent un nouveau front de la personnalisation, les systèmes intégrant progressivement le contexte émotionnel et l’analyse de sentiment pour proposer des suggestions alignées non seulement sur les préférences passées mais aussi sur l’état émotionnel actuel. Les développements futurs devraient renforcer l’explicabilité et la transparence, permettant aux utilisateurs de comprendre pourquoi certaines recommandations apparaissent et de disposer de leviers pour façonner leur profil de recommandation. La convergence de ces tendances laisse présager des systèmes de recommandation de nouvelle génération plus respectueux de la vie privée, transparents, émotionnellement intelligents et capables d’offrir des expériences de personnalisation réellement transformatrices tout en respectant l’autonomie et les droits des utilisateurs.
AmICited suit comment des systèmes d'IA comme ChatGPT, Perplexity et Google AI Overviews mentionnent votre marque dans des recommandations personnalisées et des contenus générés par l'IA. Restez informé de la visibilité de votre marque dans les systèmes alimentés par l'intelligence artificielle.
Découvrez comment fonctionnent les recommandations de produits par l’IA, les algorithmes qui les sous-tendent et comment optimiser votre visibilité dans les sys...
Discussion communautaire sur le contenu sponsorisé et la publicité dans la recherche IA. Utilisateurs et marketeurs échangent sur les tendances observées dans C...
Discussion communautaire sur l'optimisation des décisions d'achat dans l'IA. Stratégies concrètes de marques ayant amélioré leur visibilité dans les recommandat...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.