
PerplexityBot: Cosa Deve Sapere Ogni Proprietario di Sito Web
Guida completa al crawler PerplexityBot: scopri come funziona, gestisci l'accesso, monitora le citazioni e ottimizza la visibilità su Perplexity AI. Approfondis...
9 min di lettura

Il web crawler di Amazon utilizzato per migliorare prodotti e servizi, tra cui Alexa, l’assistente per lo shopping Rufus e le funzionalità di ricerca basate sull’IA di Amazon. Rispetta il protocollo di esclusione dei robot e può essere gestito tramite le direttive nel file robots.txt. Può essere utilizzato per l’addestramento di modelli di IA.
Il web crawler di Amazon utilizzato per migliorare prodotti e servizi, tra cui Alexa, l'assistente per lo shopping Rufus e le funzionalità di ricerca basate sull'IA di Amazon. Rispetta il protocollo di esclusione dei robot e può essere gestito tramite le direttive nel file robots.txt. Può essere utilizzato per l'addestramento di modelli di IA.
Amazonbot è il web crawler ufficiale di Amazon progettato per migliorare prodotti e servizi dell’azienda raccogliendo e analizzando contenuti web. Questo sofisticato crawler alimenta funzionalità chiave di Amazon, tra cui l’assistente vocale Alexa, l’assistente per lo shopping IA Rufus e le esperienze di ricerca basate sull’intelligenza artificiale di Amazon. Amazonbot opera utilizzando la stringa user agent Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, che lo identifica ai server web. I dati raccolti da Amazonbot possono essere utilizzati per addestrare i modelli di intelligenza artificiale di Amazon, rendendolo una componente cruciale dell’infrastruttura IA e della strategia di sviluppo prodotti dell’azienda.
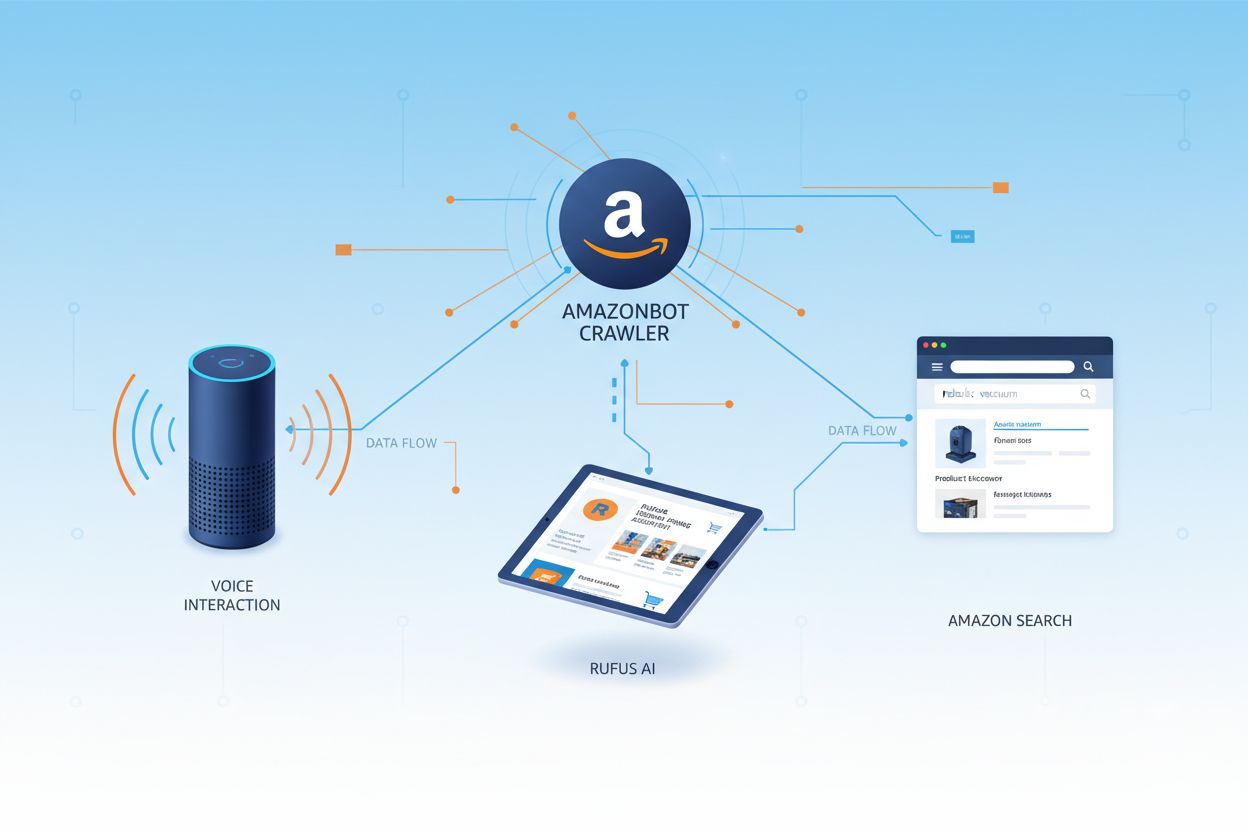
Amazon gestisce tre distinti web crawler, ciascuno con scopi specifici all’interno dell’ecosistema. Amazonbot è il crawler principale utilizzato per il miglioramento generale di prodotti e servizi e può essere impiegato per l’addestramento di modelli IA. Amzn-SearchBot è progettato specificamente per migliorare le esperienze di ricerca in prodotti Amazon come Alexa e Rufus, ma, cosa importante, NON esegue crawling di contenuti per l’addestramento di modelli IA generativi. Amzn-User supporta azioni avviate dall’utente, come il recupero di informazioni live quando i clienti pongono ad Alexa domande che richiedono dati web aggiornati, e anch’esso non effettua crawling per l’addestramento di IA. Tutti e tre i crawler rispettano il protocollo di esclusione dei robot e le direttive robots.txt, permettendo ai proprietari dei siti di controllare il loro accesso. Amazon pubblica gli indirizzi IP di ogni crawler sul suo portale sviluppatori, consentendo ai proprietari dei siti di verificare il traffico legittimo. Inoltre, tutti i crawler Amazon rispettano le direttive link-level rel=nofollow e i meta tag robots a livello di pagina, inclusi noarchive (impedisce l’uso per addestramento IA), noindex (impedisce l’indicizzazione) e none (impedisce entrambi).
| Nome Crawler | Scopo Primario | Addestramento Modelli IA | User Agent | Casi d’Uso Chiave |
|---|---|---|---|---|
| Amazonbot | Miglioramento generale prodotti/servizi | Sì | Amazonbot/0.1 | Potenziamento complessivo servizi Amazon, addestramento IA |
| Amzn-SearchBot | Miglioramento esperienza di ricerca | No | Amzn-SearchBot/0.1 | Ricerca Alexa, indicizzazione Rufus shopping assistant |
| Amzn-User | Recupero dati live su richiesta utente | No | Amzn-User/0.1 | Query Alexa in tempo reale, richieste informazioni aggiornate |
Amazon rispetta il protocollo di esclusione dei robot standard di settore (RFC 9309), il che significa che i proprietari dei siti possono controllare l’accesso di Amazonbot tramite il file robots.txt. Amazon recupera i file robots.txt a livello di host dalla root del dominio (es. example.com/robots.txt) e utilizzerà una copia in cache degli ultimi 30 giorni se il file non è accessibile. Le modifiche al file robots.txt vengono generalmente recepite nei sistemi Amazon in circa 24 ore. Il protocollo supporta le direttive standard user-agent e allow/disallow, permettendo un controllo granulare su quali crawler possono accedere a directory o file specifici. Tuttavia, è importante notare che i crawler Amazon NON supportano la direttiva crawl-delay, che verrà ignorata se presente nel file robots.txt.
Ecco un esempio su come controllare l’accesso di Amazonbot:
# Blocca Amazonbot dal fare crawling sull’intero sito
User-agent: Amazonbot
Disallow: /
# Consenti Amzn-SearchBot per la visibilità in ricerca
User-agent: Amzn-SearchBot
Allow: /
# Blocca una directory specifica ad Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Consenti tutti gli altri crawler
User-agent: *
Disallow: /admin/
I proprietari di siti preoccupati per il traffico dei bot dovrebbero verificare che i crawler che si presentano come Amazonbot siano effettivamente legittimi. Amazon fornisce una procedura di verifica tramite lookup DNS per confermare il traffico autentico di Amazonbot. Per verificare la legittimità di un crawler, individua prima l’indirizzo IP nei log del server, poi esegui una ricerca DNS inversa su quell’IP usando il comando host. Il nome di dominio ottenuto deve essere un sottodominio di crawl.amazonbot.amazon. Successivamente, esegui una ricerca DNS diretta sul dominio ottenuto per verificare che punti nuovamente all’IP originario. Questa verifica bidirezionale aiuta a prevenire attacchi di spoofing, dato che malintenzionati potrebbero configurare record DNS inversi per impersonare Amazonbot. Amazon pubblica anche gli indirizzi IP verificati di tutti i suoi crawler sul portale sviluppatori all’indirizzo developer.amazon.com/amazonbot/ip-addresses/, offrendo un ulteriore riferimento per la verifica.
Esempio di processo di verifica:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Se hai domande su Amazonbot o devi segnalare attività sospette, contatta direttamente Amazon all’indirizzo amazonbot@amazon.com includendo i nomi di dominio rilevanti nel messaggio.
Esiste una distinzione fondamentale tra i crawler di Amazon riguardo l’addestramento dei modelli IA. Amazonbot può essere utilizzato per addestrare i modelli di intelligenza artificiale di Amazon, rendendolo rilevante per i creatori di contenuti preoccupati dell’uso del proprio lavoro per l’intelligenza artificiale. Al contrario, Amzn-SearchBot e Amzn-User esplicitamente NON effettuano crawling di contenuti per l’addestramento di modelli IA generativi, ma si concentrano esclusivamente sul miglioramento delle esperienze di ricerca e sul supporto delle query utente. Se desideri impedire che i tuoi contenuti vengano utilizzati per l’addestramento IA, puoi utilizzare il meta tag robots noarchive nell’header HTML della tua pagina, che istruisce Amazonbot a non usare la pagina per scopi di addestramento modelli. Questa distinzione è importante per editori, creatori e proprietari di siti che vogliono mantenere il controllo su come i propri contenuti sono utilizzati nella pipeline di addestramento IA, pur consentendo la visualizzazione nei risultati di ricerca Amazon e nei suggerimenti Rufus.
Rufus è il sofisticato assistente per lo shopping IA di Amazon che sfrutta crawling web e tecnologia IA per offrire consigli d’acquisto e assistenza personalizzata. Mentre Amazonbot contribuisce all’infrastruttura IA generale di Amazon, Rufus utilizza specificamente Amzn-SearchBot per indicizzare informazioni sui prodotti e contenuti web rilevanti per le query di shopping. Rufus è costruito su Amazon Bedrock e utilizza avanzati large language model tra cui Claude Sonnet di Anthropic e Amazon Nova, combinati con un modello personalizzato addestrato sull’ampio catalogo prodotti di Amazon, recensioni clienti, domande e risposte della community e informazioni dal web. L’assistente aiuta i clienti a ricercare prodotti, confrontare opzioni, monitorare prezzi, trovare offerte e persino acquistare automaticamente articoli al raggiungimento di prezzi target. Dal suo lancio, Rufus è diventato estremamente popolare: oltre 250 milioni di clienti lo usano, gli utenti attivi mensili sono aumentati del 149% e le interazioni sono cresciute del 210% anno su anno. I clienti che utilizzano Rufus durante lo shopping hanno oltre il 60% di probabilità in più di effettuare un acquisto durante quella sessione, dimostrando l’impatto significativo dell’assistenza allo shopping alimentata dall’IA sul comportamento dei consumatori.
I proprietari di siti dovrebbero adottare un approccio strategico alla gestione dei crawler Amazon in base ai propri obiettivi di business e alle politiche sui contenuti:
noarchive o bloccalo completamente tramite robots.txtamazonbot@amazon.com fornendo il tuo dominio per ricevere indicazioni personalizzate se hai dubbi o domande su come i crawler Amazon interagiscono con il tuo sitoAmazonbot è il crawler generico di Amazon utilizzato per migliorare prodotti e servizi e può essere impiegato per l'addestramento di modelli IA. Amzn-SearchBot è progettato specificamente per le esperienze di ricerca su Alexa e Rufus e esplicitamente NON effettua crawling per l'addestramento di modelli di IA. Se vuoi impedire l'uso dei dati per addestramento IA, blocca Amazonbot ma consenti Amzn-SearchBot per la visibilità in ricerca.
Aggiungi le seguenti righe al tuo file robots.txt nella root del dominio: User-agent: Amazonbot seguito da Disallow: /. Questo impedirà ad Amazonbot di fare crawling sull’intero sito. Puoi anche usare Disallow: /specific-path/ per bloccare solo determinate directory.
Sì, Amazonbot può essere utilizzato per addestrare i modelli di intelligenza artificiale di Amazon. Se vuoi impedirlo, utilizza il meta tag robots nell’header HTML della tua pagina, che istruisce Amazonbot a non usare la pagina per l’addestramento dei modelli.
Esegui una ricerca DNS inversa sull’indirizzo IP del crawler e verifica che il dominio sia un sottodominio di crawl.amazonbot.amazon. Poi esegui una ricerca DNS diretta per confermare che il dominio risolva nuovamente sull’IP originale. Puoi anche consultare gli indirizzi IP pubblicati da Amazon su developer.amazon.com/amazonbot/ip-addresses/.
Usa la sintassi standard robots.txt: User-agent: Amazonbot per indirizzare il crawler, seguito da Disallow: / per bloccare tutto l’accesso o Disallow: /path/ per bloccare directory specifiche. Puoi anche utilizzare Allow: / per permettere esplicitamente l’accesso.
Amazon normalmente recepisce i cambiamenti del robots.txt entro circa 24 ore. Amazon recupera regolarmente il tuo file robots.txt e mantiene una copia in cache fino a 30 giorni, quindi le modifiche possono richiedere un giorno intero per propagarsi nei loro sistemi.
Sì, assolutamente. Puoi creare regole separate per ciascun crawler nel tuo file robots.txt. Ad esempio, consenti Amzn-SearchBot con User-agent: Amzn-SearchBot e Allow: /, mentre blocchi Amazonbot con User-agent: Amazonbot e Disallow: /.
Contatta direttamente Amazon all’indirizzo amazonbot@amazon.com. Includi sempre il nome del tuo dominio e qualsiasi dettaglio rilevante nella tua richiesta. Il team di supporto Amazon può offrire indicazioni personalizzate per la tua situazione specifica.
Traccia le menzioni del tuo brand tra sistemi di IA come Alexa, Rufus e Google AI Overviews con AmICited - la principale piattaforma per il monitoraggio delle risposte IA.
Guida completa al crawler PerplexityBot: scopri come funziona, gestisci l'accesso, monitora le citazioni e ottimizza la visibilità su Perplexity AI. Approfondis...

Scopri come i crawler AI influenzano le risorse del server, la banda e le prestazioni. Approfondisci statistiche reali, strategie di mitigazione e soluzioni inf...

Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.